
SVC数据集准备及预处理
此文档主要为SVC数据集预处理的详细步骤。
- 音源准备
- 时长要求:训练音源需准备至少20min以上,最好是1-2小时的数据。注:由于歌曲中歌手并不会整首歌都在演唱,因此这里的时长说的是歌手实际演唱的时长,不包括前奏、间奏等无歌声的部分。
- 质量要求:训练音源尽量使用高保真及以上品质的音频。高质量音频会保留更多高低音域的数据,使得训练效果更好;低质量音频为了节省存储空间,会舍弃高低音域的部分数据。
- 人声分离(以下简称VR)
- 推荐使用在线网站EaseUs Vocal Remover进行人声分离,具体操作步骤就不赘述了
- 如有其他分离工具,也可使用,若能直接去掉和声就更好。
- 第一次切分(0~5s为短时片段、5~15s为正常片段、15+为超长片段)
- 切分使用audio-slicer-GUI或audio-slicer-CLI进行。其主要功能为根据设置的参数将歌声从VR后的wav中切出来。
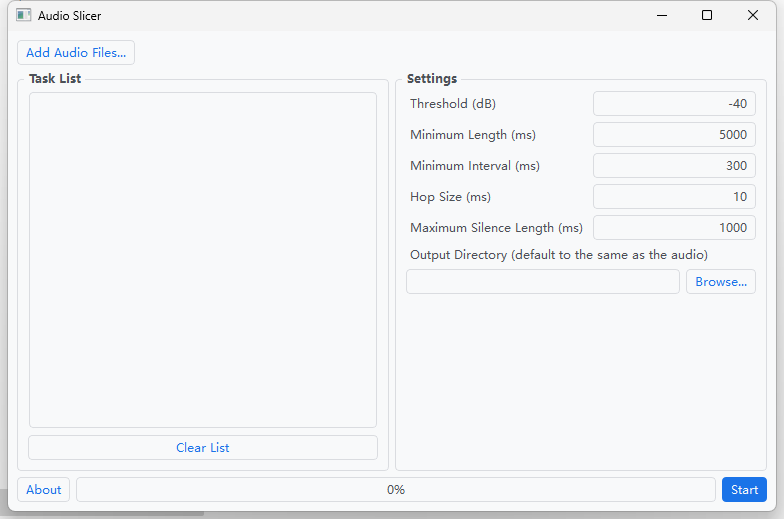
audio-slicer使用RMS(根平均分数)来测量音频的安静度并检测沉默的部分。计算每帧的RMS值(帧长度设置为Hop Size),RMS值低于阈值的帧将被视为静默帧。
- 参数说明:
Threshold(dB) -- 音量低于阈值的帧会被当做静默帧去掉,如果音源较为嘈杂,可以增加该值抑制噪声,默认为-40dB。通常VR之后,可能会带有和声,也可利用该参数来切掉和声。
Minimum Length(ms) -- 每个音频切片的最小长度,单位为ms,默认值为5000。
Minimum Interval(ms) -- 切分时每个静音片段的最小长度,单位为ms,默认值为300。若原音频中只包含非常短暂的停顿,建议将该值设小一些。该值越小,获得的切片数量越多。注意:该值必须小于Minimum Length,大于Hop Size。
Hop Size(ms) -- 每个RMS帧的长度,单位为ms。增加这个值将提高切片的精度,但会减慢过程。默认为10。
Maximum Silence Length(ms) -- 音频切片时的最大静默长度,单位为ms,默认为1000,简单理解为当静默超过该值时即为合适的切片时间点。需要根据需要调整此值。注意,该值并不以为切片后音频中的连续静默时长会有如此长度。算法会根据需要自动寻找合适的切片点(其可能的静默长度会<=该值)
Output Directory -- 输出目录,即切分后的wav保存位置
- 参数设置完毕后,只需要点击Add Audio Files->选择所有需要切分的wav->start即可。等待完成后,进入Output Directory即可查看。
- 二次切分
- 在Output Directory中按照时长排序,将超长片段重新使用slicer进行二次切分。否则,超长片段在预处理或训练时,容易爆显存。
- 若二次切分后无变化的片段,可通过调整Maximum Slience Length、Minimum Interval等参数使其能切分成功。
- 数据清洗
- 二次切分后,Output Directory中就只有短时和正常片段。数据清洗流程较为枯燥繁琐,需要用自己的耳朵去判断哪些数据可用,哪些不可用,同时还需要将时长不足的片段拼接起来。
- 对二次切分后的片段按时长升序排列,圈出所有短时片段并逐一试听。非主声或无法判断声音归属的片段可直接删掉。对于主声中的气音、尾音等可能会被单独切成片段,需要保留并拼接到前后歌声中。
- 部分短时片段可能是和声,或和声接一点点主声,需要使用工具Glodwave进行裁剪(其他工具亦可,只是我习惯用这个)。对于本为一句歌词却被切分为多个短片段的,亦可使用该工具进行拼接,可视化的剪切、粘贴以及ctrl+s的保存相当方便。
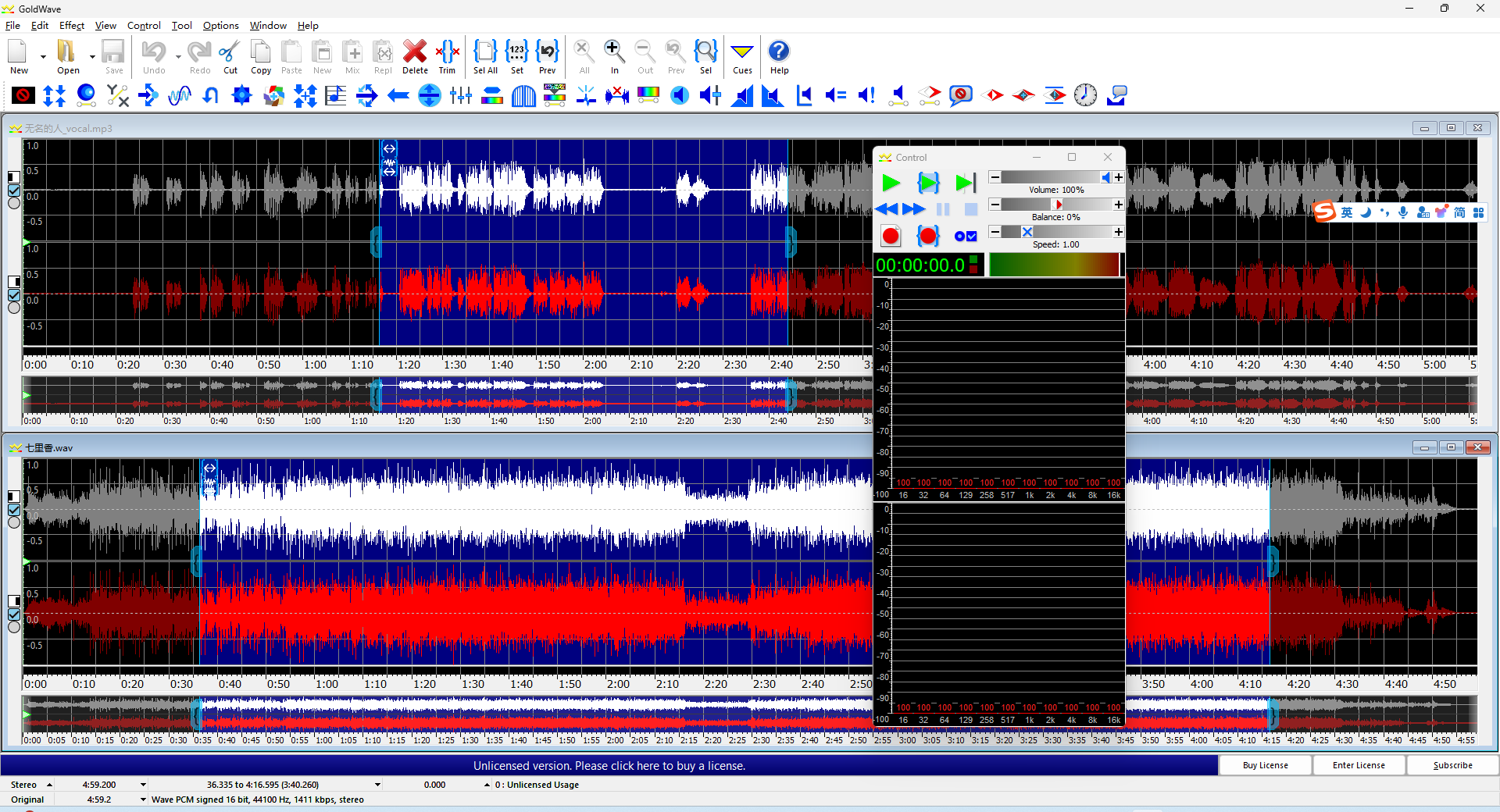
- 短时片段清洗干净后,接下来对正常片段(即剩余的片段)逐一试听,视情况将短时片段贴到前后片段的头部或尾部,亦或几个连续短时片段合并为一个片段。
- 若试听正常片段时发现存在和声或较长静默片段,也可使用Goldwave对其进行手动切分以及再拼接。最终使得Output Directory中只存在正常片段且都经过了清洗。
- 对于翻唱模型来说,即便是占比非常小的错误数据也会导致模型质量的大幅下降,因此在清洗过程中需要细心、耐心并适时总结一些技巧。
- 响度匹配
- 规整好片段后,需要对数据集进行响度匹配。由于数据集由多首歌组成,不同歌之间音量听感是不一致的,因此响度匹配的目的即为让数据集整体达到一致的音量听感。
- SVC提供的脚本resample.py中虽然有这个功能,但其是按照固定的0dB来对数据集进行听感统一,这可能造成音质的损失,从而降低数据集质量。
- SVC作者提供了一个专门的响度匹配工具Loudness Matching Tool,若无其他选择时可以使用该工具进行操作。
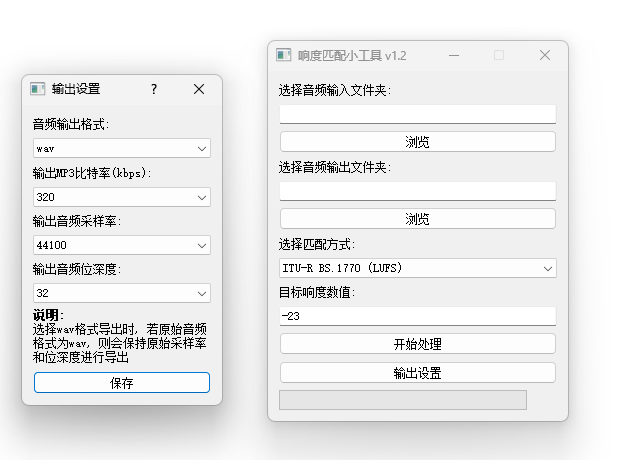
- 参数说明:
输入输出 -- 只需提供目录路径即可,工具会读取输入目录下的所有音频文件,并在处理完毕后放到输出目录中
匹配方式 -- 选择响度匹配的算法,其中括弧中的单位用于指导“目标响度数值”的值的意义
目标响度数值 -- 匹配时的标准,其意义由匹配方式中的算法及其单位定义
输出设置 -- 设置输出格式,建议与输入音频一致
- 数据集中只保留匹配后的音频切片。
- 重采样
- 响度匹配后,需要执行resample.py对数据集进行规整。由于不使用SVC自带的响度匹配,因此需要带上参数--skip_loudnorm。
python resample.py --skip_loudnorm
- 注意:resample.py会将重采样后的数据拷贝到dataset/44k之下,并形成对应的目录格式,因此即便原数据集已经是44100kHz、单声道,也建议执行一次该脚本。
- 自动划分训练集、验证集,以及配置文件生成
- 使用如下命令生成:
python preprocess_flist_config.py --speech_encoder vec768l12 --vol_aug
- 上述命令中,speech_encoder可选的有如下集中:
vec768l12
vec256l9
hubertsoft
whisper-ppg
whisper-ppg-large
cnhubertlarge
dphubert- --vol_aug则表示开启响度嵌入,开启后在推理时会匹配输入源响度;去掉该参数则推理时会完全使用模型的响度。
体感就是,开启后推理出来的翻唱歌声与原歌声音量差不多,关闭时翻唱歌声则取决于模型训练时数据集的整体音量。
- 配置文件修改
- 配置文件生成后,可按需进行调整,其中主模型配置文件为SVC/config/config.json,扩散模型配置文件为SVC/config/diffusion.yaml。
- 主模型配置文件
config.json
vocoder_name: 选择一种声码器,默认为nsf-hifiganlog_interval:多少步输出一次日志,默认为200eval_interval:多少步进行一次验证并保存一次模型,默认为800epochs:训练总轮数,默认为10000,达到此轮数后将自动停止训练learning_rate:学习率,建议保持默认值不要改batch_size:单次训练加载到 GPU 的数据量,调整到低于显存容量的大小即可all_in_mem:加载所有数据集到内存中,某些平台的硬盘 IO 过于低下、同时内存容量 远大于 数据集体积时可以启用keep_ckpts:训练时保留最后几个模型,0为保留所有,默认只保留最后3个
- 扩散模型配置文件
diffusion.yaml
cache_all_data:加载所有数据集到内存中,某些平台的硬盘 IO 过于低下、同时内存容量 远大于 数据集体积时可以启用duration:训练时音频切片时长,可根据显存大小调整,注意,该值必须小于训练集内音频的最短时间!batch_size:单次训练加载到 GPU 的数据量,调整到低于显存容量的大小即可timesteps: 扩散模型总步数,默认为 1000。完整的高斯扩散一共 1000 步k_step_max: 训练时可仅训练k_step_max步扩散以节约训练时间,注意,该值必须小于timesteps,0 为训练整个扩散模型,注意,如果不训练整个扩散模型将无法使用仅扩散模型推理!
- 生成F0预测器
- 前面步骤完全完成后,即可开始预处理的最后一步。生成预测器,生成的文件将会和dataset/44k/中的数据集放在一起。
- 使用以下命令
python preprocess_hubert_f0.py --f0_predictor rmvpe --use_diff
- 这里f0_predictor推荐只用rmvpe即可,--use_diff为开启扩散训练。
- 此处命令执行需要花费一点时间,若出错爆显存,则需排查数据集是否存在时长较长的片段,需要进行部分重切分重拼接等操作。然后再从第六步重新来一遍。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号