
SVC推理参数说明
- WebUI参数说明
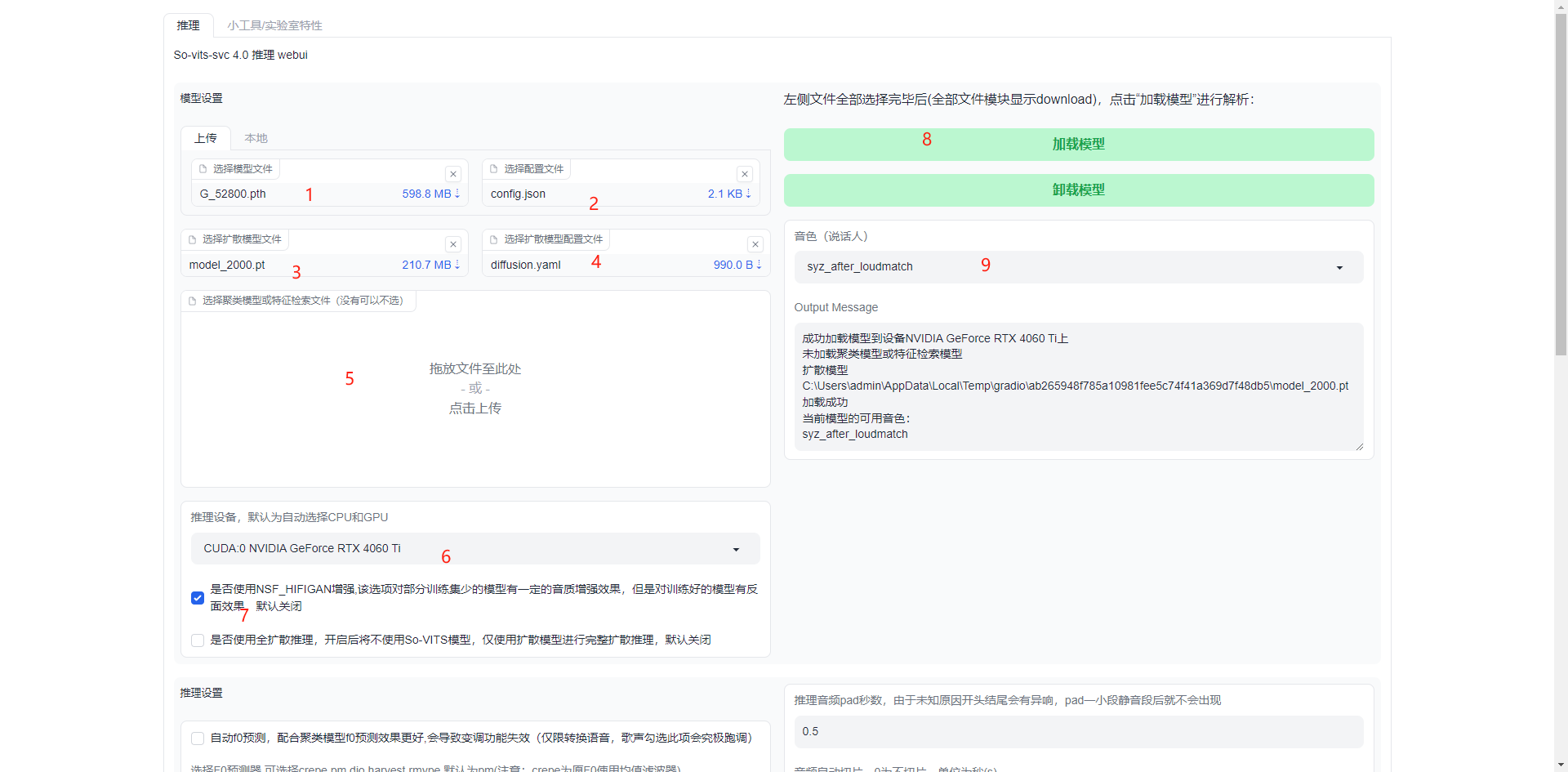
- 选择主模型文件
- 主模型配套的配置文件
- 主模型配套的扩散模型
- 扩散模型配套的配置文件
- 聚类模型或特征检索。(可选)
聚类模型:需单独训练聚类模型,其可以减小音色泄露,使得音色更接近于原声(效果不是很明显)。单纯的完全使用聚类模型,会导致出现口齿不清,降低咬字的情况。因此,需要设置好混合比例。
特征检索:同样可以减小音色泄露,但会增加推理时间,咬字比聚类稍好。同样需要设置混合比例。
以上两种模型,若需要择一加载即可。
- 选择推理设备,建议使用GPU(速度快一些)
- NSF-HIFIGAN增强在训练集较少时建议开启,有明显增强作用
全扩散推理开启后将不会使用主模型,而是只使用扩散模型推理
- 1和2选择完毕,3、4、5可选。点击按钮即可加载模型。加载结束后,信息会显示在下面的Output Message中
- 模型加载完毕后,训练时指定的说话人名单会在此处罗列出来。选择说话人,即选择用谁的训练集来推理。
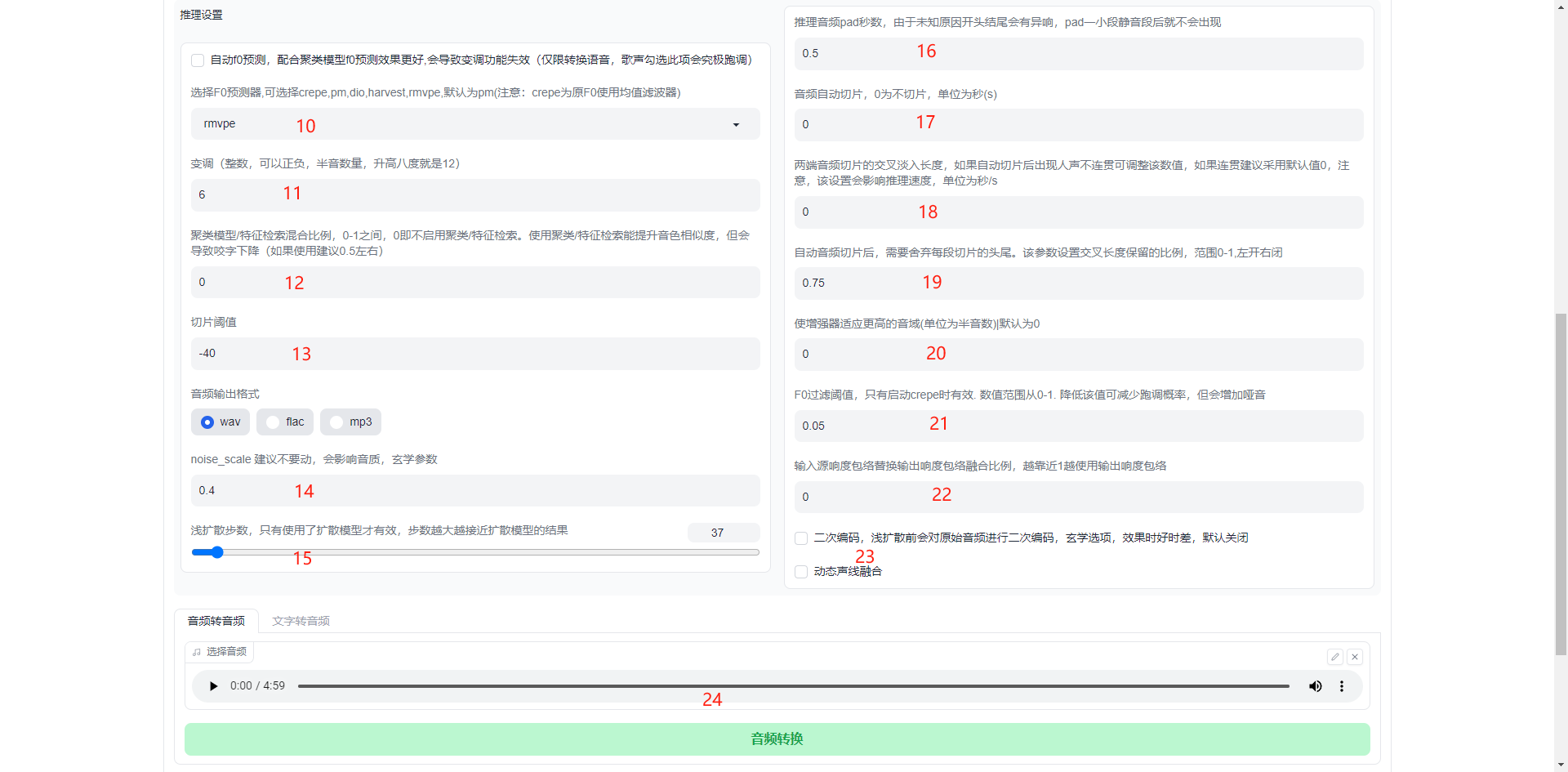
- f0预测器,最好是与模型训练时使用的预测器一致。目前推荐的是rmvpe
- 变调:-24~+24,通常男变女用+12,女变男用-12。此处,值越大声调越高,值越低声调越低沉。注意:声调高低始终有个范围,若过高容易出现静音、破音等情况,过低同理。
- 聚类模型/特征检索混合比例,范围0~1,若启用建议0.5
- 切片阈值:推理时,会根据该阈值对输入音频进行切片。同训练集切片时用的阈值作用相同。
- noise_scale:建议不动
- 浅扩散步数:即扩散推理时的步数,完整的高斯扩散共1000步。步数越多越接近扩散结果,主模型的推理结果则会被抑制。若只是想去掉噪音、电音,建议30-50步即可。
- pad:开头结尾自动填静音的时间。官方给的解释是,未知原因导致开头结尾会有异响,所以直接填一段静音即可解决
- 音频自动切片:即切片长度,单位s。0为不切片。切片的好处是,可以将多个片段同时进行推理,再融合。减少推理时间,但相应的也会增加资源占用,尤其是显存。
- 音频切片的交叉淡入长度,单位为s。如果切片后人声不连续,可调整该值。可以理解为前切片的片尾与后切片的片头重叠一部分(即交叉),然后做淡入处理。
- 切片需要舍弃的片尾比例,即为18中交叉长度的保留比例。范围0~1,左开右闭。
- 增强器基础音域,单位半音。+1表示升高一个半音,-1表示降低一个半音。
- F0过滤阈值,使用crepe预测器时,该值才有效。目前推荐使用rmvpe,所以该参数基本无用。
- 输入源响度与输出响度占比,1为完全使用输出响度。输出响度则取决于训练时的响度嵌入等操作。
- 二次编码:官方未详细解释,建议不开。
动态声线融合:该选项无法使用。默认关闭。声线融合主要是将输入源中(模型声线、输入音频声线)所有声线融合到一起,生成一个不存在的声线。
- 添加待推理的人声,并点击音频转换,即可开始推理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号