
从语音通话和视频通话两个方面搭建专属于自己的私有化部署的视频会议通话系统
召开远程视频会议,可大大提高工作效率,节省与会人员的工作时间和会议费用。视频会议通话系统应用在政府、军队、教育、金融、交通、能源、医疗等行业及跨国、跨地区的企业中逐步普及。
EasyRTC视频通话系统
EasyRTC视频通话系统(以下简称EasyRTC)是一款覆盖全球的实时音视频通话与会议软件,结合了智能视频、智能语音、窄带传输、通道加密、数据加密等技术,可通过微信小程序、H5页面、APP、PC客户端等接入方式之间互通,快速从零开始搭建实时音视频通信,支持一对一、一对多等视频通话,满足语音视频社交、在线教育和培训、视频会议和远程医疗等场景;支持多终端接入方式之间互通,快速从零开始搭建实时音视频通信平台。
EasyRTC视频通话系统具有实时音视频通话,支持视频会议(单路、多路)、会议录像、会议回放、旁路直播等技术特点。(演示地址:https://demo.easyrtc.cn)
今天通过从语音通话和视频通话两个方面全面解读视频会议系统的功能架构。
一、语音通话
1、基础模型
在视频会议中,网络语音通话通常多对多的的,但就模型层面来说,我们讨论一个方向的通道就可以了。一方说话,另一方则听到声音。看似简单而迅捷,但是其背后的流程却是相当复杂的。我们将其经过的各个主要环节简化成下图所示的概念模型:
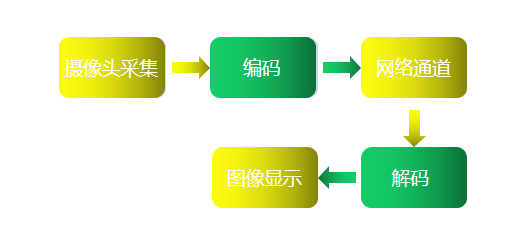
这是一个最基础的模型,由五个重要的环节构成:采集、编码、传送、解码、播放。
语音采集指的是从麦克风采集音频数据,即声音样本转换成数字信号。其涉及到几个重要的参数:采样频率、采样位数、声道数。
假设我们将采集到的音频帧不经过编码,而直接发送,那么我们可以计算其所需要的带宽要求,仍以上例:320*100 =32KBytes/s,如果换算为bits/s,则为256kb/s。这是个很大的带宽占用。而通过网络流量监控工具,我们可以发现采用类似QQ等IM软件进行语音通话时,流量为3-5KB/s,这比原始流量小了一个数量级。而这主要得益于音频编码技术。 所以,在实际的语音通话应用中,编码这个环节是不可缺少的。目前有很多常用的语音编码技术,像G.729、iLBC、AAC、SPEEX等等。
当一个音频帧完成编码后,即可通过网络发送给通话的对方。对于语音对话这样Realtime应用,低延迟和平稳是非常重要的,这就要求我们的网络传送非常顺畅。
当对方接收到编码帧后,会对其进行解码,以恢复成为可供声卡直接播放的数据。 完成解码后,即可将得到的音频帧提交给声卡进行播放。
2、高级功能
如果仅仅依靠上述的技术就能实现一个效果良好的应用于广域网上的语音对话系统,那就太easy了。正是由于很多现实的因素为上述的概念模型引入了众多挑战,使得网络语音系统的实现不是那么简单,其涉及到很多专业技术。一个“效果良好”的语音对话系统应该达到如下几点:低延迟,背景噪音小,声音流畅、没有卡、停顿的感觉,没有回音。
对于低延迟,只有在低延迟的情况下,才能让通话的双方有很强的Realtime的感觉。当然,这个主要取决于网络的速度和通话双方的物理位置的距离,就单纯软件的角度,优化的可能性很小。
(1)回音消除
现在大家几乎都已经都习惯了在语音聊天时,直接用PC、手机的声音外放功能。当使用外放功能时,扬声器播放的声音会被麦克风再次采集,传回给对方,这样对方就听到了自己的回音。
回音消除的原理简单地来说就是,回音消除模块依据刚播放的音频帧,在采集的音频帧中做一些类似抵消的运算,从而将回声从采集帧中清除掉。这个过程是相当复杂的,因为它还与你聊天时所处的房间的大小、以及你在房间中的位置有关,因为这些信息决定了声波反射的时长。智能的回音消除模块,能动态调整内部参数,以最佳适应当前的环境。
(2)噪声抑制
噪声抑制又称为降噪处理,是根据语音数据的特点,将属于背景噪音的部分识别出来,并从音频帧中过滤掉。
(3)抖动缓冲区
抖动缓冲区(JitterBuffer)用于解决网络抖动的问题。所谓网络抖动,就是网络延迟一会大一会小,在这种情况下,即使发送方是定时发送数据包的(比如每100ms发送一个包),而接收方的接收就无法同样定时了,有时一个周期内一个包都接收不到,有时一个周期内接收到好几个包。如此,导致接收方听到的声音就是一卡一卡的。
JitterBuffer工作于解码器之后,语音播放之前的环节。即语音解码完成后,将解码帧放入JitterBuffer,声卡的播放回调到来时,从JitterBuffer中取出最老的一帧进行播放。
JitterBuffer的缓冲深度取决于网络抖动的程度,网络抖动越大,缓冲深度越大,播放音频的延迟就越大。所以,JitterBuffer是利用了较高的延迟来换取声音的流畅播放的,因为相比声音一卡一卡来说,稍大一点的延迟但更流畅的效果,其主观体验要更好。
当然,JitterBuffer的缓冲深度不是一直不变的,而是根据网络抖动程度的变化而动态调整的。当网络恢复到非常平稳通畅时,缓冲深度会非常小,这样因为JitterBuffer而增加的播放延迟就可以忽略不计了。
(4)混音
在视频会议中,多人同时发言时,我们需要同时播放来自于多个人的语音数据,而声卡播放的缓冲区只有一个,所以,需要将多路语音混合成一路,这就是混音算法要做的事情。
二、视频通话
1、基础模型
视频通话的概念模型与语音完全一致:
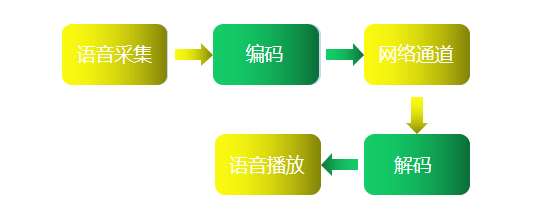
摄像头采集指的是从捕捉摄像头采集到的每一帧视频图像。
一般而言,一个摄像头可以支持多种不同的采集分辨率和采集帧频,而不同的摄像头支持的分辨率的集合不一样。比如现在有很多高清摄像头可以支持30fps的1920*1080的图像采集。
编码用于压缩视频图像,同时也决定了图像的清晰度。视频编码常用的技术是H.264、H.265、MPEG-4、XVID等。
当对方接收到编码的视频帧后,会对其进行解码,以恢复成一帧图像,然后在UI的界面上绘制出来。
2、高级功能
相比于语音,视频的相关处理要简单一些。
(1)动态调整视频的清晰度
在Internet上,网络速度是实时动态变化的,所以,在视频会议中,为了优先保证语音的通话质量,需要实时调整视频的相关参数,其最主要的就是调整编码的清晰度,因为清晰度越高,对带宽要求越高,反之亦然。
比如,当检测网络繁忙时,就自动降低编码的清晰度,以降低对带宽的占用。
(2)自动丢弃视频帧
同样网络繁忙时,还有一个方法,就是发送方是主动丢弃要发送的视频帧,这样在接收方看来,就是帧频fps降低了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号