回文自动机小记
一周前学的东西终于来填坑了(
回文自动机是一个能够高效处理回文字符串匹配的结构,常用于动态处理回文匹配问题,有着优秀的线性的复杂度。不过由于其空间复杂度达到了 \(n|\Sigma|\),其在某些场合下并不能完全代替 manacher(当然类比 SAM 空间的优化,使用哈希表也可达到线性的空间复杂度)。
那么怎么构建回文自动机呢?说到回文自动机就要说到一个与其紧密相连的结构——回文树了。做过这道题的同学应该非常清楚一个结论:一个字符串本质不同回文子串个数是 \(\mathcal O(n)\) 级别的,因此我们考虑将这些本质不同的回文串拎出来建一个类似于 trie 树的结构,不过既然是回文串,从中间切开来肯定有一些比较好的性质,因此我们考虑不像传统的 trie 那样从头至尾插入,而是从中间劈开来向两端插入。又因为回文串分为奇数和偶数长度两种类型,因此我们要对这两种字符串分开来考虑。我们考虑建立两个根,一个叫奇根,编号为 \(1\),一个叫偶根,编号为 \(0\)。对于奇根所在 trie 树中的节点 \(x\),我们假设奇根到点 \(x\) 路径上的边上字母按照顺序分别是 \(c_1,c_2,\cdots,c_m\),那么 \(x\) 这个节点表示的回文串就是 \(c_mc_{m-1}\cdots c_2c_1c_2\cdots c_{m-1}c_m\),同理对于偶根所在 trie 树中的节点 \(x\),我们也假设根到 \(x\) 路径上的边按照顺序分别是 \(c_1,c_2,\cdots,c_m\),那么与奇根不同的一点是,\(x\) 这个节点表示的回文串变成了 \(c_mc_{m-1}\cdots c_2c_1c_1c_2\cdots c_{m-1}c_m\),也就是 \(c_1\) 出现了两次。同时对于每个节点我们记一个 \(len_x\) 表示 \(x\) 节点表示的回文串的长度,其中 \(len_0=0,len_1=-1\)。同时我们再记一个 \(fail_x\) 表示 \(x\) 节点最长回文后缀表示的节点编号,如果不存在则 \(fail_x=0\),而对于 \(fail_0\) 则有 \(fail_0=1\),\(fail_1\) 则有 \(fail_1=0\),至于为什么将会在后面提到。
由于一个字符串本质不同回文子串个数是 \(\mathcal O(n)\) 级别的,因此 PAM 的节点个数也是 \(\mathcal O(n)\) 级别的。
譬如 \(s=\text{"abbaaa"}\) 建出回文自动机来就如下图所示,其中绿色边表示 fail 指针:
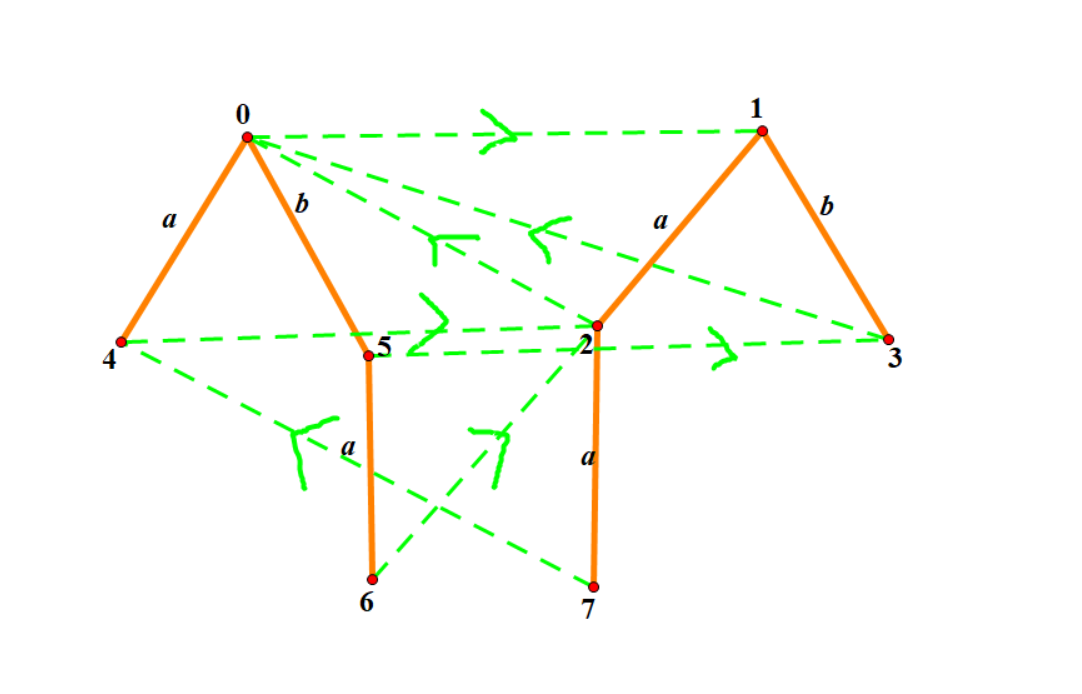
那么怎么构造回文自动机呢?考虑借鉴 SAM 的构造方法:增量构造法,具体来说我们假设我们已经构造出了前 \(i-1\) 个点的 PAM,并且已经求得了以 \(s_{i-1}\) 结尾的最长回文后缀表示的节点 \(x\),考虑怎样构造出前 \(i\) 个点的 PAM。首先我们假设以 \(s_i\) 结尾的最长回文后缀为 \(s[l...i]\),那么必然有 \(s[l+1...i-1]\) 也是回文串并且 \(s_l=s_i\)(如果 \(i-l\le 1\) 那我们也可以把 \(s[l+1...i-1]\) 算作回文自动机上节点 \(0\) 或 \(1\) 表示的字符串),而根据类似于 KMP 的 fail 树那一套理论,一个回文字符串的回文后缀都可以通过从该回文串所表示的节点不断跳 fail 得到,因此我们考虑从 \(x\) 开始,不断跳 fail,即 \(x\leftarrow fail_x\),直到 \(s_{i-len_x-1}=s_i\) 为止。那么此时 \(x\) 节点的 \(s_i\) 儿子就是新的最长的以 \(s_i\) 结尾的最长回文后缀,因为此时 \(x\) 是符合条件的 \(s[l+1...i-1]\) 表示的字符串,而在回文自动机沿有字符的边向下走等价于在头尾添加字符,因此 \(x\) 的 \(s_i\) 字符相当于在 \(s[l+1...i-1]\) 后面添加了 \(s_i\),直接令 \(x\) 等于 \(x\) 的 \(s_i\) 儿子即可。
那如果 \(x\) 节点没有 \(s_i\) 儿子怎么办呢?此时我们肯定要新建节点。显然新建的节点的 \(len\) 就是原来的 \(x\) 的 \(len\) 加二。那么新建节点的 \(fail\) 怎么求呢?我们还是假设新建节点的最长回文后缀在原字符串中是 \(s[l'...i]\),那么依然有 \(s[l'+1...i-1]\) 为回文串并且 \([l'+1,i-1]\) 包含于原来的 \([l+1,i-1]\),也就是说 \(s[l'+1...i-1]\) 是 \(s[l+1...i-1]\) 的真回文后缀,因此我们新建一个变量 \(fa\),初始值为 \(fail_x\)(因为是真包含,所以不能直接从 \(x\) 开始跳 fail),然后不断跳 fail,直到 \(s_{i-len_{fa}-1}=s_i\),此时再往 \(fa\) 下添个 \(s_i\) 儿子就是我们要求的 \(fail\)。如果不存在 \(s_i\) 儿子怎么办呢?显然如果跳的节点不存在 \(s_i\) 儿子,那么意味着新的节点不存在真回文后缀,它的 \(fail\) 值也应当是 \(0\),而由于我们儿子数组的默认值就是 \(0\),因此直接调用儿子数组 ch[fa][s[i]-'a'] 得到的值也是 \(0\),不会出现问题。
最后稍微解释一下为什么 \(fail_0=1\),因为我们在跳 \(fail\) 的过程中,如果它连长度大于等于 \(2\) 的回文后缀都不存在,那么它只可能存在长度为 \(1\) 的回文后缀,并且我们跳到 \(0\) 时也无法匹配上,这时候我们就要用到 \(fail_0\),我们会将指针指到 \(fail_0\) 并跳到 \(1\) 节点,而显然 \(1\) 节点可以匹配上,因为 \(i-len_1-1=i\),这时我们就会选择将 \(s_i\) 接到 \(1\) 上作为长度为 \(1\) 的回文串。而 \(fail_1=0\)……是为了当 \(x=1\) 且不存在 \(s_i\) 儿子时,求新建的儿子的 \(fail\) 时 \(fail\) 从 \(0\) 开始跳。
时间复杂度 \(\mathcal O(n)\)。
模板题代码:
const int MAXN=5e5;
int n;char s[MAXN+5];
int ch[MAXN+5][26],fail[MAXN+5],len[MAXN+5],ncnt,dep[MAXN+5],cur,num[MAXN+5];
void init(){ncnt=2;fail[1]=0;fail[0]=1;len[0]=0;len[1]=-1;cur=0;}
int getfail(int x,int ps){
while(s[ps-len[x]-1]!=s[ps]) x=fail[x];
return x;
}
void insert(int ps){
cur=getfail(cur,ps);
if(!ch[cur][s[ps]-'a']){
fail[++ncnt]=ch[getfail(fail[cur],ps)][s[ps]-'a'];
ch[cur][s[ps]-'a']=ncnt;len[ncnt]=len[cur]+2;
num[ncnt]=num[fail[ncnt]]+1;
} cur=ch[cur][s[ps]-'a'];
}
int main(){
scanf("%s",s+1);n=strlen(s+1);
int pre=0;init();
for(int i=1;i<=n;i++){
s[i]=(s[i]-97+pre)%26+97;insert(i);
printf("%d%c",pre=num[cur]," \n"[i==n]);
}
return 0;
}
例题:
1. P5685 [JSOI2013]快乐的 JYY
近乎模板的题,注意到两个串的公共回文串个数是 \(\mathcal O(n)\) 级别的,因此考虑枚举每个本质不同的公共回文串,答案加上它们在 \(s,t\) 中出现次数的乘积,这个求出每个回文子串的出现次数后,建出两串的 PAM 后瞎 DFS 一下就可以了。那么怎么求出每个回文子串的出现次数呢?考虑在每次找出每个前缀最长的回文后缀后在其对应的节点上打一个 \(+1\) 的标记,然后类比 AC 自动机,建出 fail 树后一遍 DFS 上推即可。
2. P5555 秩序魔咒
yet another mol ban tea……
还是建出两串的 PAM,还是在两个 PAM 上瞎 DFS,然鹅与上一题不同的是这题连 fail 树都不用建,直接 DFS 到一个节点就更新答案即可。
3. P4287 [SHOI2011]双倍回文
注意到一个回文串是双倍回文串的充要条件是它的长度是 \(4\) 的倍数,并且它存在一个长度为其一半的回文后缀,还是按照套路建出回文自动机的 fail 树,然后在 fail 树上 DFS 的过程中开一个桶记录它有哪些长度的回文后缀即可判断一个字符串是否满足条件。
4. CF17E Palisection
考虑容斥,拿总回文串的对数减去不相交的回文串的对数。总回文串对数套用模板题的做法即可。对于不相交的回文串,我们假设两个回文串分别为 \([l_1,r_1],[l_2,r_2](l_1\le r_1<l_2\le r_2)\),那么我们考虑在 \(r_1\) 处统计答案,那么 \(s[l_1...r_1]\) 应是 \(s[1...r_1]\) 的回文后缀,\(s[l_2...r_2]\) 应是 \(s[r_1+1...n]\) 的回文子串。对正反串分别建一遍回文自动机即可计算它们的贡献。
非常 sb 的一点是这题异常卡空间,需用邻接表维护儿子数组才能卡得过空间限制。。。。。。
5. P4762 [CERC2014]Virus synthesis
最优策略肯定是先造出一个回文串,再用若干次 \(1\) 操作。
考虑 \(dp_x\) 表示造出 \(x\) 节点表示的回文串的最小代价。考虑如何转移,显然我们要么在回文串两侧添加字符,要么在中间添加字符,如果在两侧添加字符,那么有 \(dp_x\leftarrow dp_{fa_x}+1\),因为我们可以在形成 \(fa_x\) 的前一个时刻插入中间的字符,而如果在中间添加字符,那么设 \(y\) 表示 \(x\) 的长度 \(<\lfloor\dfrac{len_x}{2}\rfloor\) 的最长回文后缀,那么有 \(dp_x\leftarrow dp_y+\lfloor\dfrac{len_x}{2}\rfloor-len_y+1\),这里的 \(y\) 可以在回文自动机求 \(fail\) 的过程中求得,故总复杂度也是线性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号