flask-蓝图、g对象、数据库连接池
1.蓝图的使用
蓝图是由blueprint翻译过来的,作用是之前在一个py文件中写的flask项目,后期划分目录,不用蓝图同样可以划分项目
1.1 不用蓝图划分项目
不使用蓝图划分也可以完成项目需求,但是随着项目深入导入情况越来越多可能会出现导入错误
1.项目目录结构:
根目录:
src
init.py
models.py
views.py
static
templates
home.html
manage.py
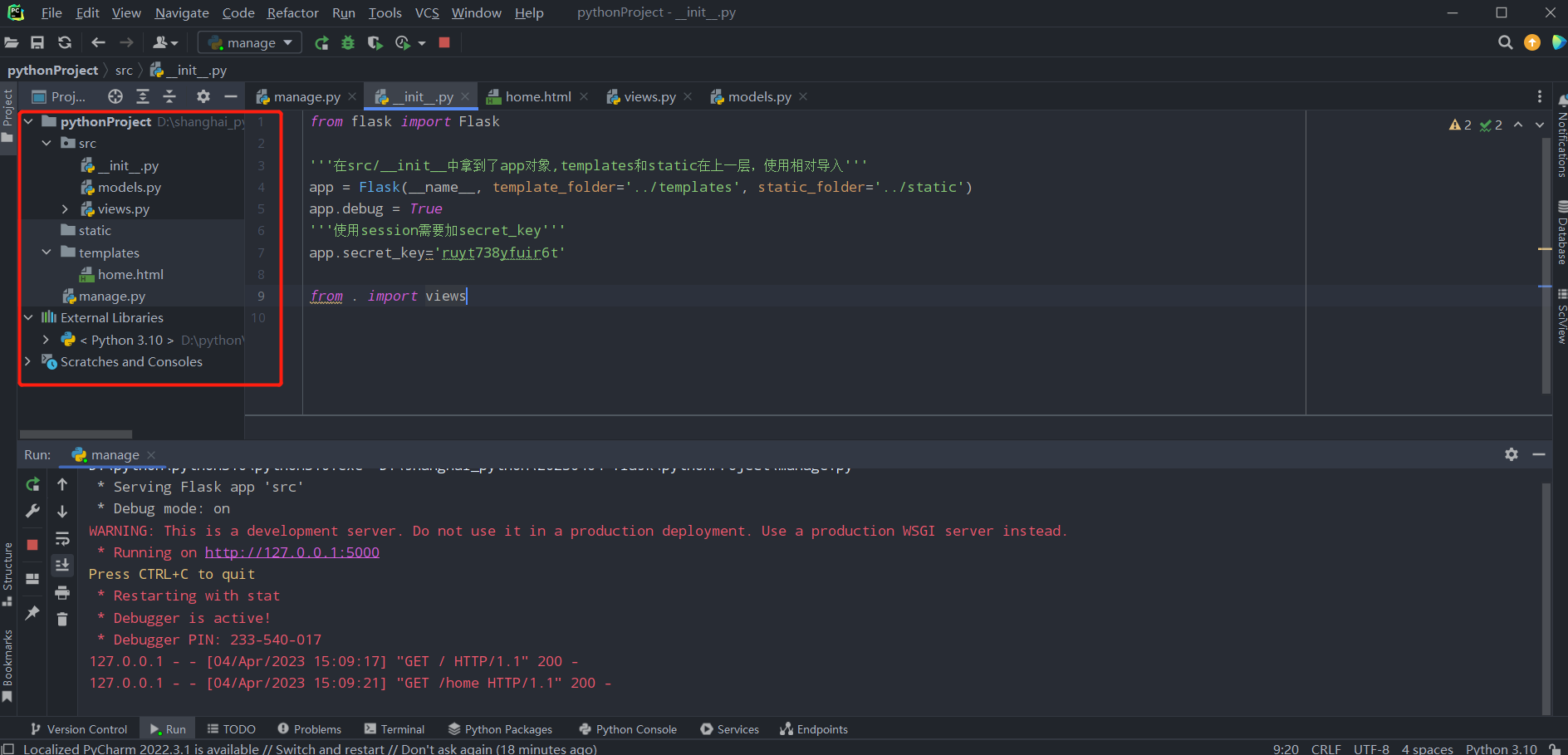
2.项目代码
src/init.py
from flask import Flask
'''在src/__init__中拿到了app对象,templates和static在上一层,使用相对导入'''
app = Flask(__name__, template_folder='../templates', static_folder='../static')
app.debug = True
'''使用session需要加secret_key'''
app.secret_key='ruyt738yfuir6t'
'''manage.py中只导入了__init__中的内容,如果不把views放在这里,那么views中的代码就始终无法执行'''
from . import views
'''并且只能放在app产生之后,如果这行代码放在最上面app还没生成就开始使用,会报错'''
src/views.py:
from . import app
from flask import render_template
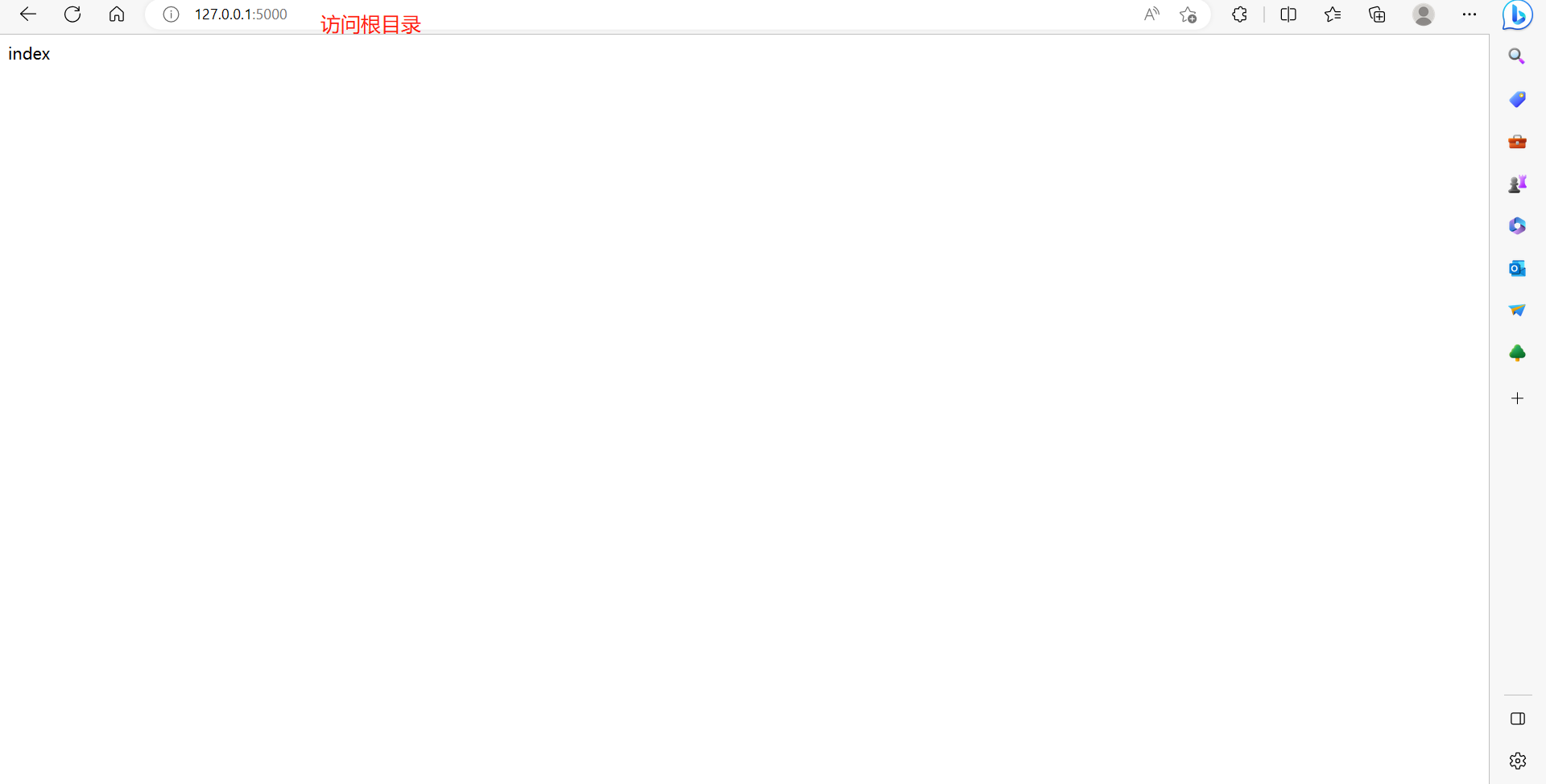
@app.route('/')
def index():
return 'index'
@app.route('/home')
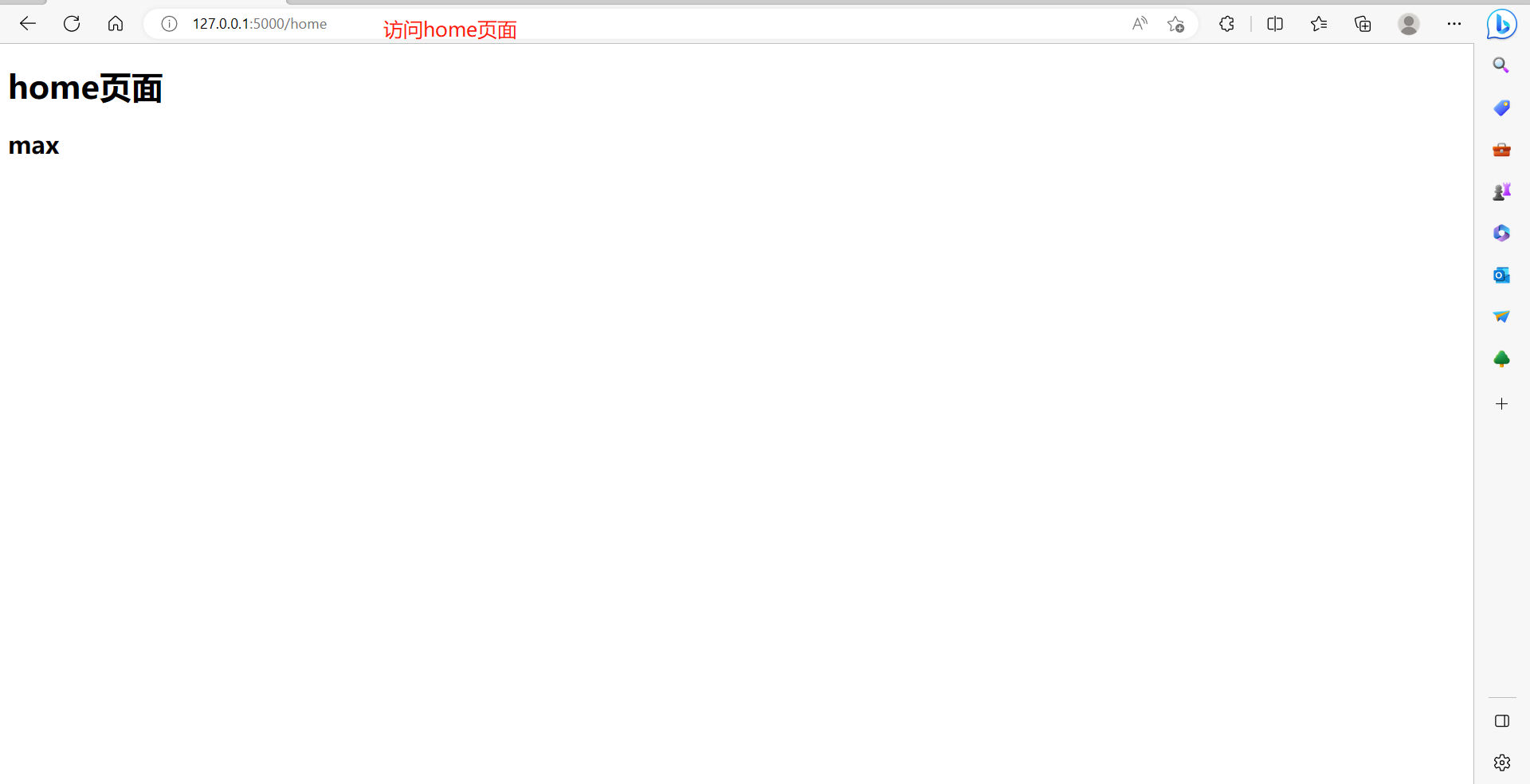
def home():
return render_template('home.html',name='max')
src/models.py:
# 这里以后写表模型代码
templates/home.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>home页面</h1>
<h2>{{name}}</h2>
</body>
</html>
manage.py:
from src import app
if __name__ == '__main__':
app.run()
1.2 使用蓝图划分项目
1.蓝图的使用步骤:
步骤一:导入蓝图类
from flask import Blueprint
# 在views目录下的相应的视图py文件中
步骤二:实例化得到蓝图对象
us=Blueprint('user',__name__)
# 在views目录下的相应的视图py文件中
步骤三:在app中注册蓝图
app.register_blueprint(us)
# 在src/__init__.py中
步骤四:在不同的views.py(order.py,user.py)中使用蓝图注册路由,此后就不用app注册路由而是用蓝图对象注册路由
@us.route('/login')
# 在视图函数上
2.目录结构:
根目录
src
static
banner.jpg
templates
user.html
views
orders.py
user.py
init.py
models.py
manage.py
3.代码
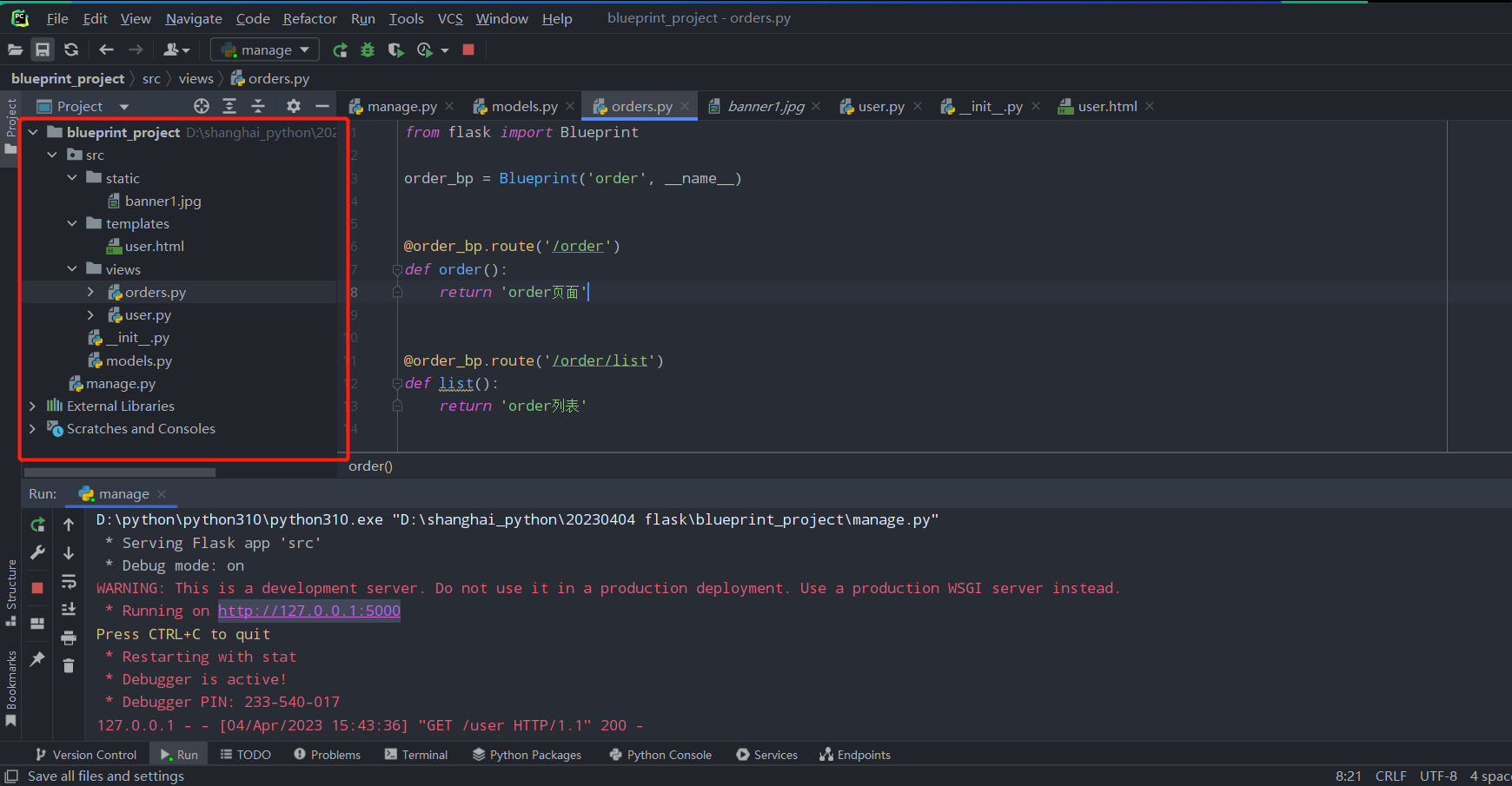
src/views/orders.py:
from flask import Blueprint
'''生成蓝图对象'''
order_bp = Blueprint('order', __name__)
@order_bp.route('/order')
def order():
return 'order页面'
@order_bp.route('/order/list')
def list():
return 'order列表'
src/views/user.py:
from flask import Blueprint, render_template
user_bp = Blueprint('user', __name__)
@user_bp.route('/user')
def user_detail():
return render_template('user.html',name='max')
src/init.py:
from flask import Flask
app = Flask(__name__)
app.debug = True
app.secret_key = 'yf7rewt6y374g'
'''manage.py中的这行代码执行:from src import app,src/__init__下的所有代码都会执行'''
from .views.user import user_bp
'''执行这两句,views下两个py文件就会执行'''
from .views.orders import order_bp
app.register_blueprint(user_bp)
app.register_blueprint(order_bp)
src/models.py:
# 这里以后写表模型
manage.py:
from src import app
if __name__ == '__main__':
app.run()
1.3 蓝图的请求扩展
蓝图也有自己的请求扩展,并且在哪个视图函数中生成的蓝图对象,只对该文件中的视图函数生效。而是用app注册的请求扩展则是对所有视图函数生效
src/views/order.py:
from flask import Blueprint
order_bp = Blueprint('order', __name__)
'''用蓝图对象点请求扩展装饰器,只要访问了/orde或者/order/list都会会走请求扩展,而执行user.py中的视图函数则不会执行该请求扩展'''
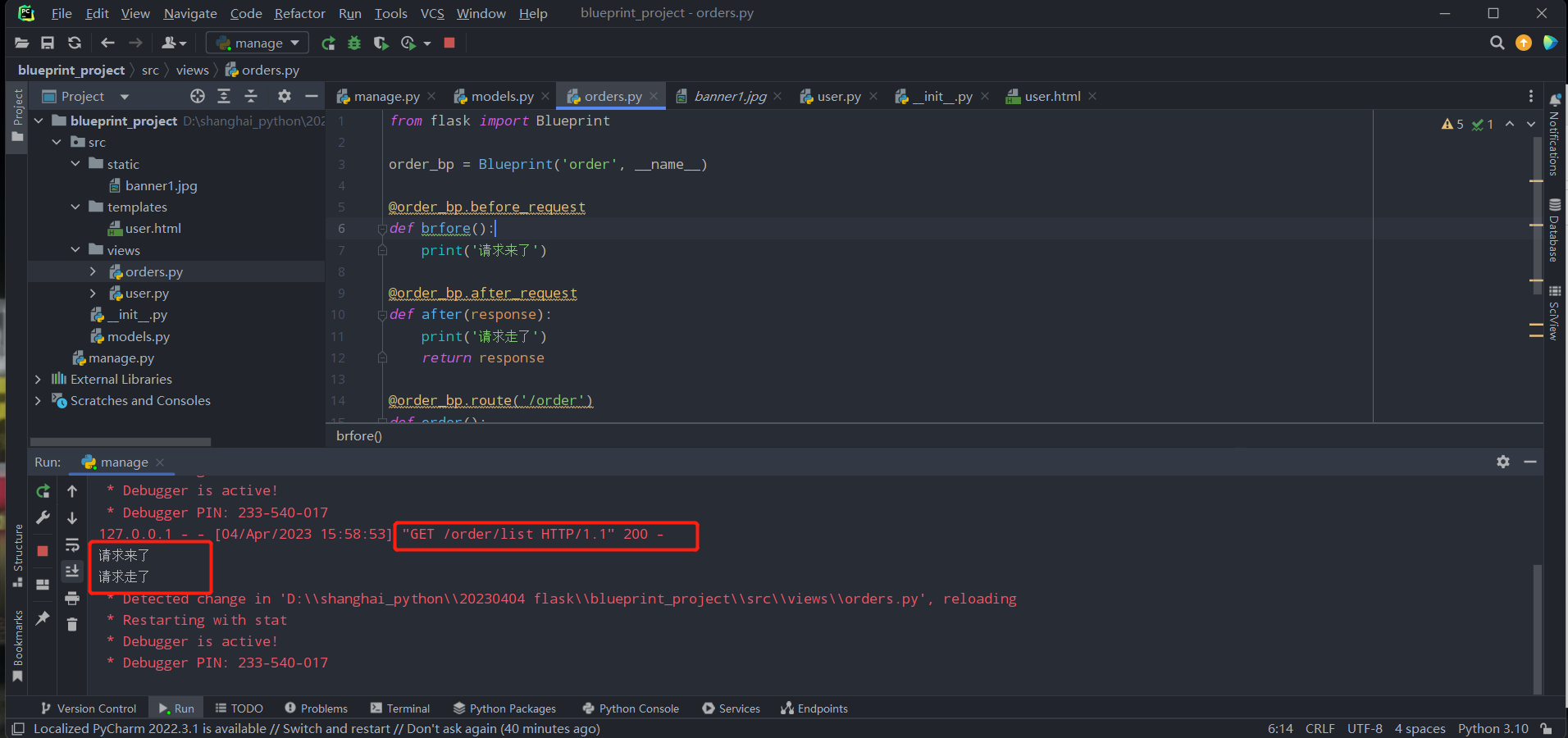
@order_bp.before_request
def brfore():
print('请求来了')
@order_bp.after_request
def after(response):
print('请求走了')
return response
@order_bp.route('/order')
def order():
return 'order页面'
@order_bp.route('/order/list')
def list():
return 'order列表'
1.4 大型项目使用蓝图
1.目录结构
根目录
src
admin # 可以看成一个app
static
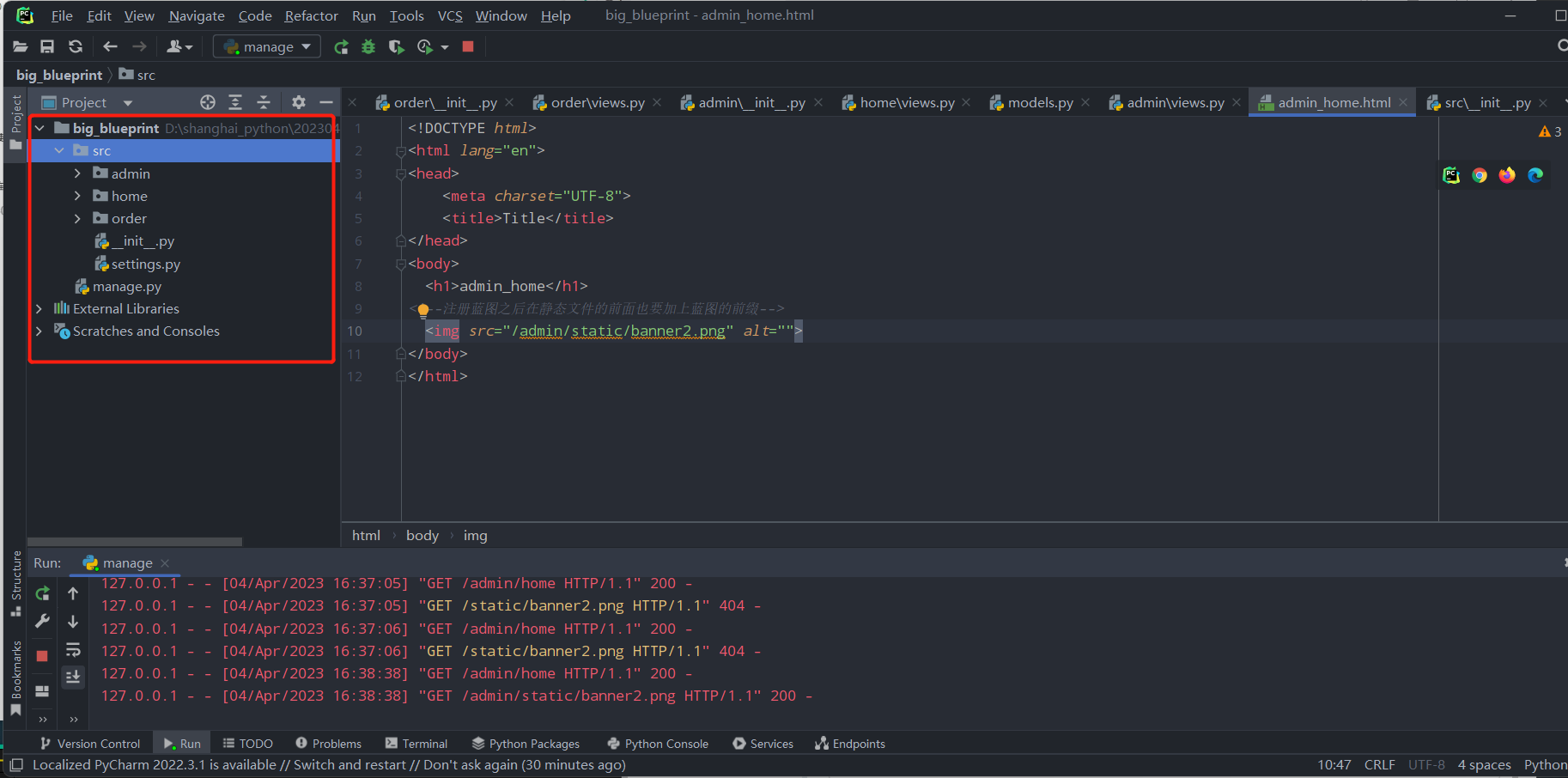
banner2.png
templates
admin_home.html
init.py
models.py
views.py
home # 可以看成一个app
static
templates
init.py
models.py
views.py
order # 可以看成一个app
static
templates
init.py
models.py
views.py
init.py
settings.py
manage.py
2.代码
src/admin/init.py:
from flask import Blueprint
admin_bp = Blueprint('admin',__name__,static_folder='static',template_folder='templates')
from . import views
src/admin/models.py:
# 这里写模型表
src/admin/views.py:
from flask import render_template
from . import admin_bp
@admin_bp.route('/home')
def home():
return render_template('admin_home.html')
src/home/init.py:
from flask import Blueprint
home_bp = Blueprint('home',__name__,static_folder='static',template_folder='templates')
from . import views
src/home中其他地方无代码,后期根据业务需求按照app扩写
src/order/init.py:
from flask import Blueprint
order_bp = Blueprint('order', __name__, static_folder='static', template_folder='templates')
from . import views
src/order/views.py:
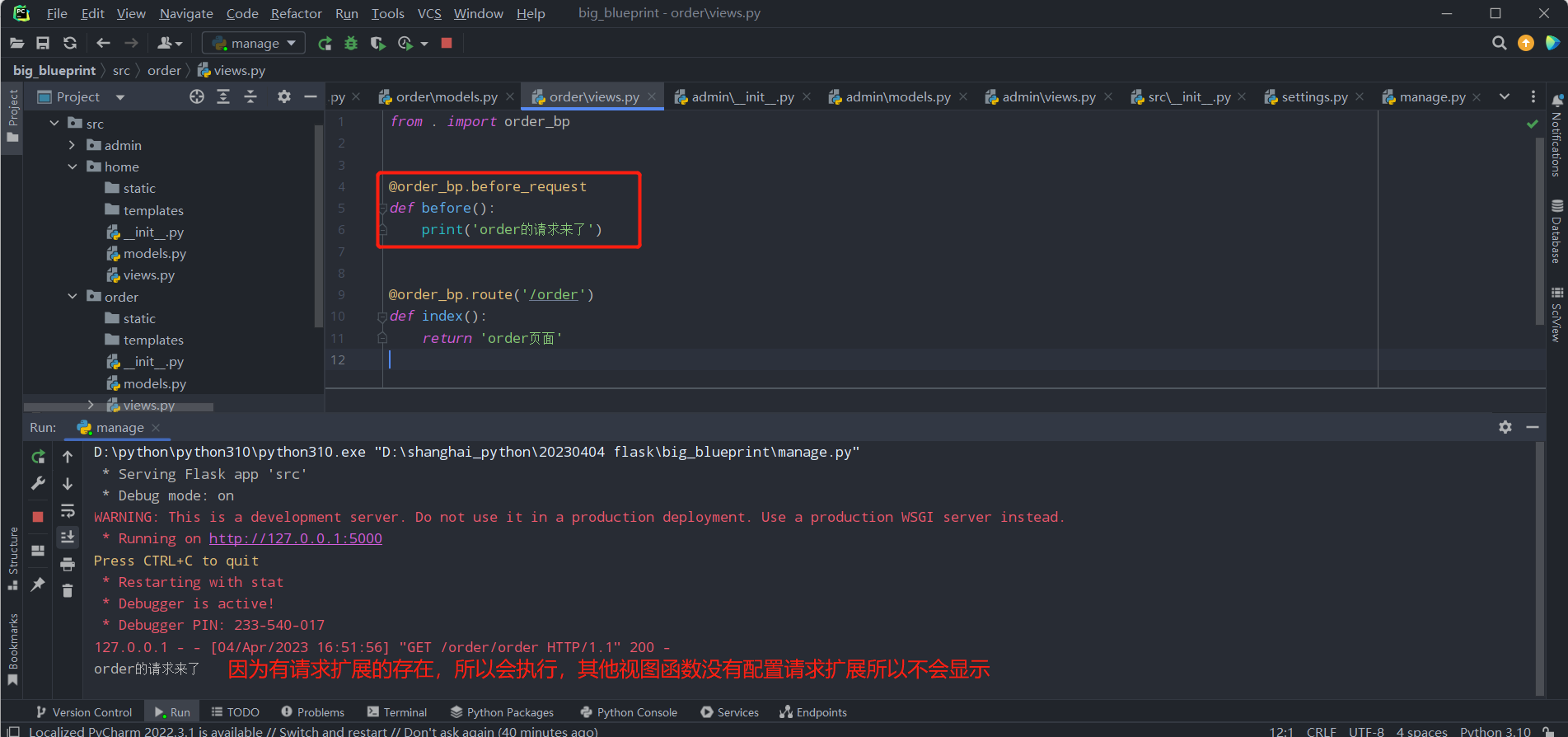
from . import order_bp
# 请求扩展
@order_bp.before_request
def before():
print('order的请求来了')
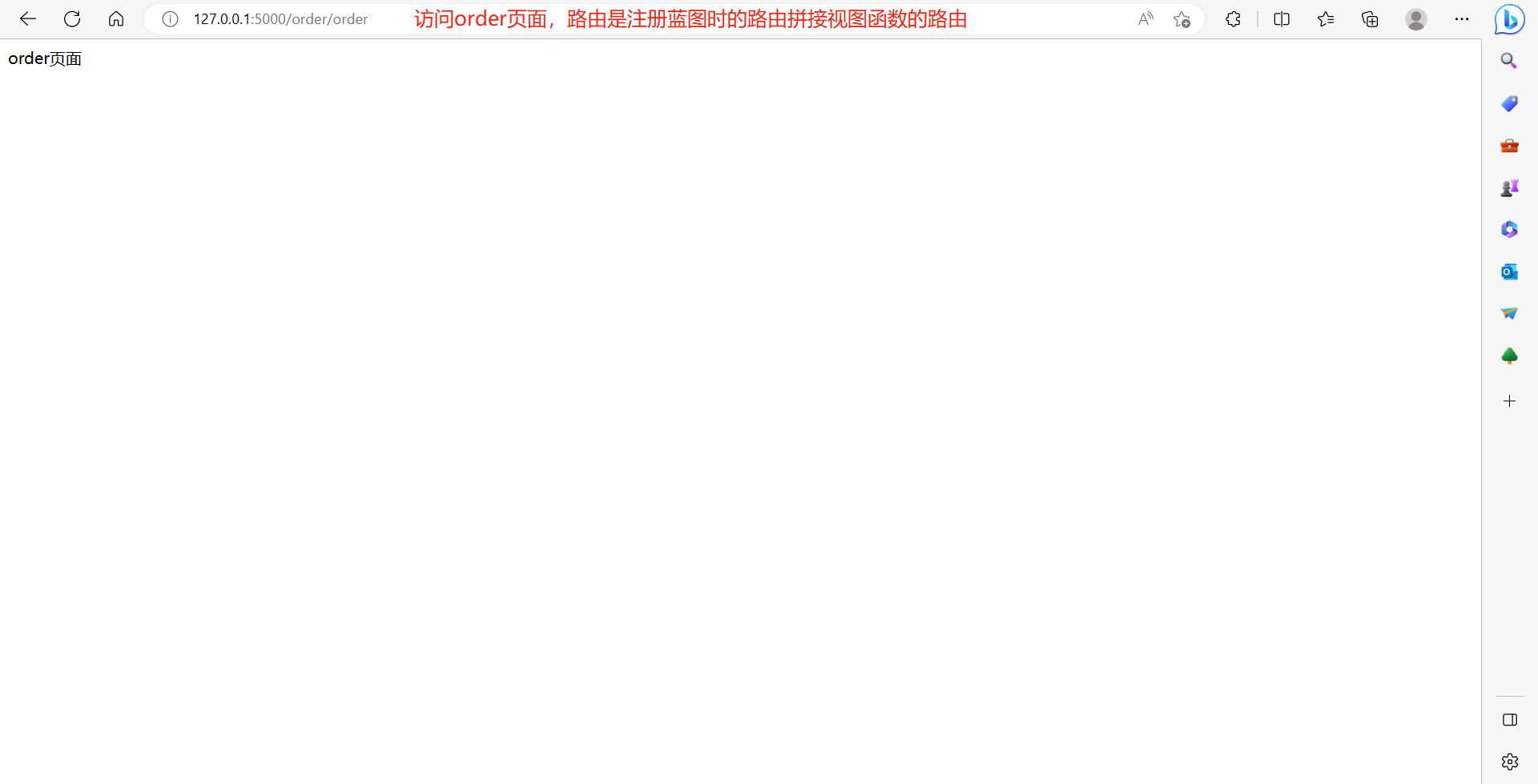
@order_bp.route('/order')
def index():
return 'order页面'
src/init.py:
from flask import Flask
app = Flask(__name__)
app.config.from_pyfile('settings.py')
# 注册蓝图
from .admin import admin_bp
from .home import home_bp
from .order import order_bp
# 在访问路由的时候需要根据蓝图中注册的路由再拼接视图函数中的路由,注册蓝图时的路由前缀必须以/开头
app.register_blueprint(admin_bp,url_prefix='/admin')
app.register_blueprint(home_bp,url_prefix='/home')
app.register_blueprint(order_bp,url_prefix='/order')
src/settings.py:
# 象征性的写了一个配置文件,也可以用类的方法来配置
DEBUG = True
manage.py:
from src import app
if __name__ == '__main__':
app.run()
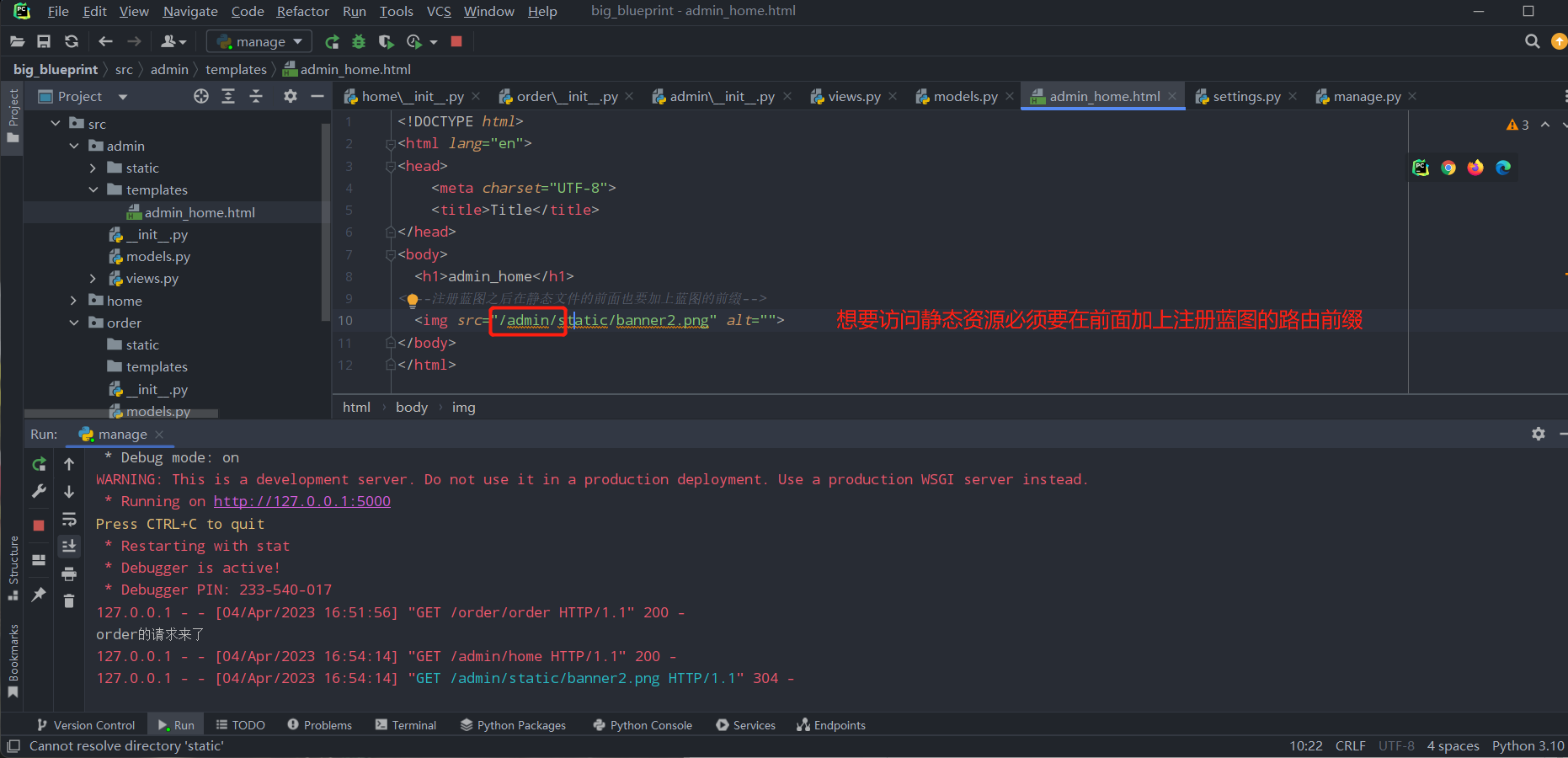
2.g对象
1.g对象的作用:在整个请求(不是整个项目)的全局,可以放值,也可以取值。在任意位置导入即可。之所以没有用request作为全局对象是因为request的属性太多,使用频率太高,怕数据污染。
在其他框架中叫context(上下文)
2.g对象的使用:
放值:g.变量名=值
取值:g.变量名
from flask import Flask,request,g
app = Flask(__name__)
app.debug = True
@app.route('/')
def index():
name = request.args.get('name')
g.name = name
return g.name
if __name__ == '__main__':
app.run()
g对象虽然是全局的,但是对于每个请求存入的值不会乱:


的但是当我们想要将name存入对象,再从另一个请求当中拿出来,发现会直接报错:
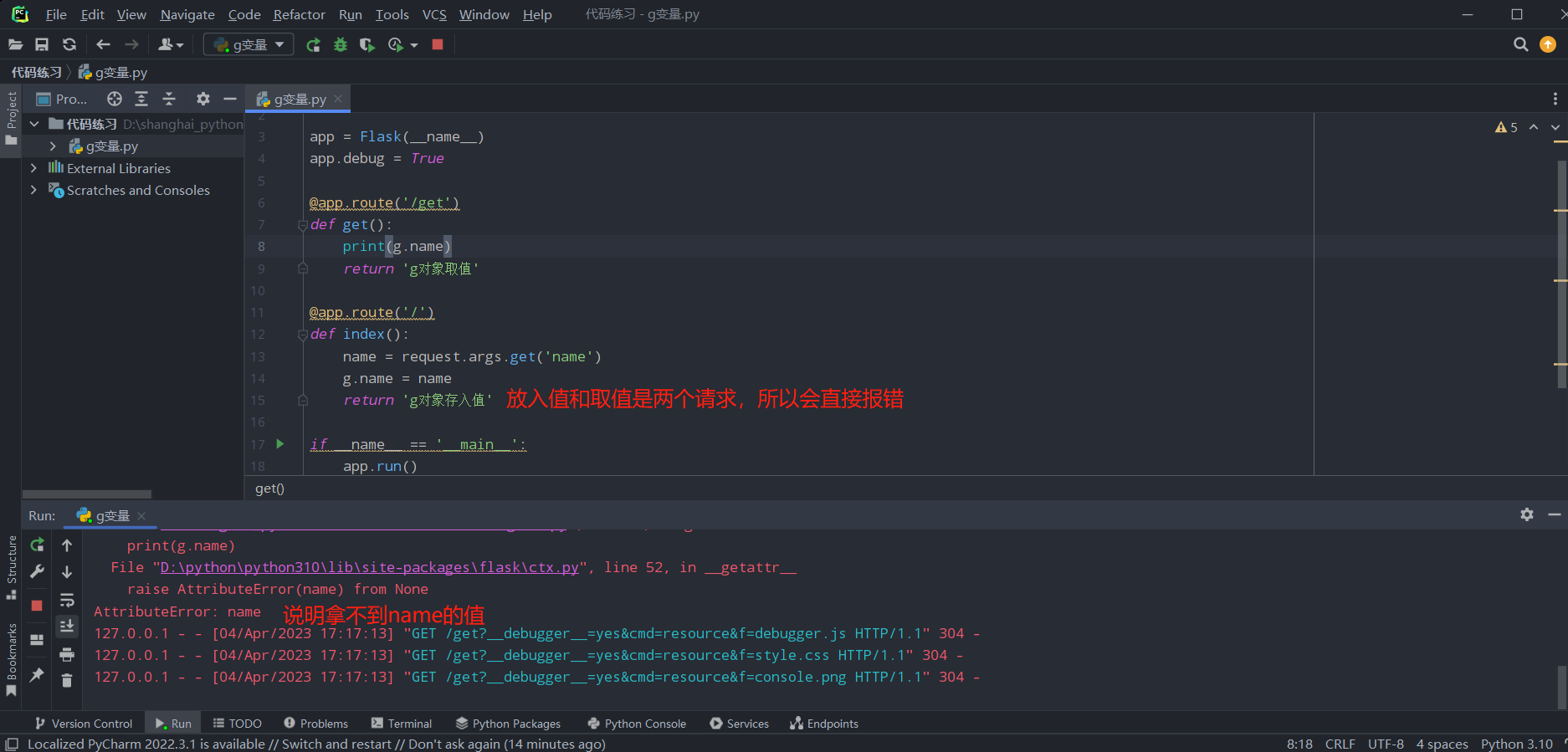
报上述错误的原因是g对象的存入值和取值只能再一次请求中。这也是g对象和session的区别:
g是只针对的当次请求
session针对于多次请求
但是针对于一个请求的视图函数调用了另一个视图函数,两个特视图函数之间依旧可以共享g对象中的值:
from flask import Flask,request,g
app = Flask(__name__)
app.debug = True
def add(a,b):
print('g对象',g.name)
return 'g对象取值'
@app.route('/')
def index():
name = request.args.get('name')
g.name = name
add(1,2)
return 'g对象存入值'
if __name__ == '__main__':
app.run()
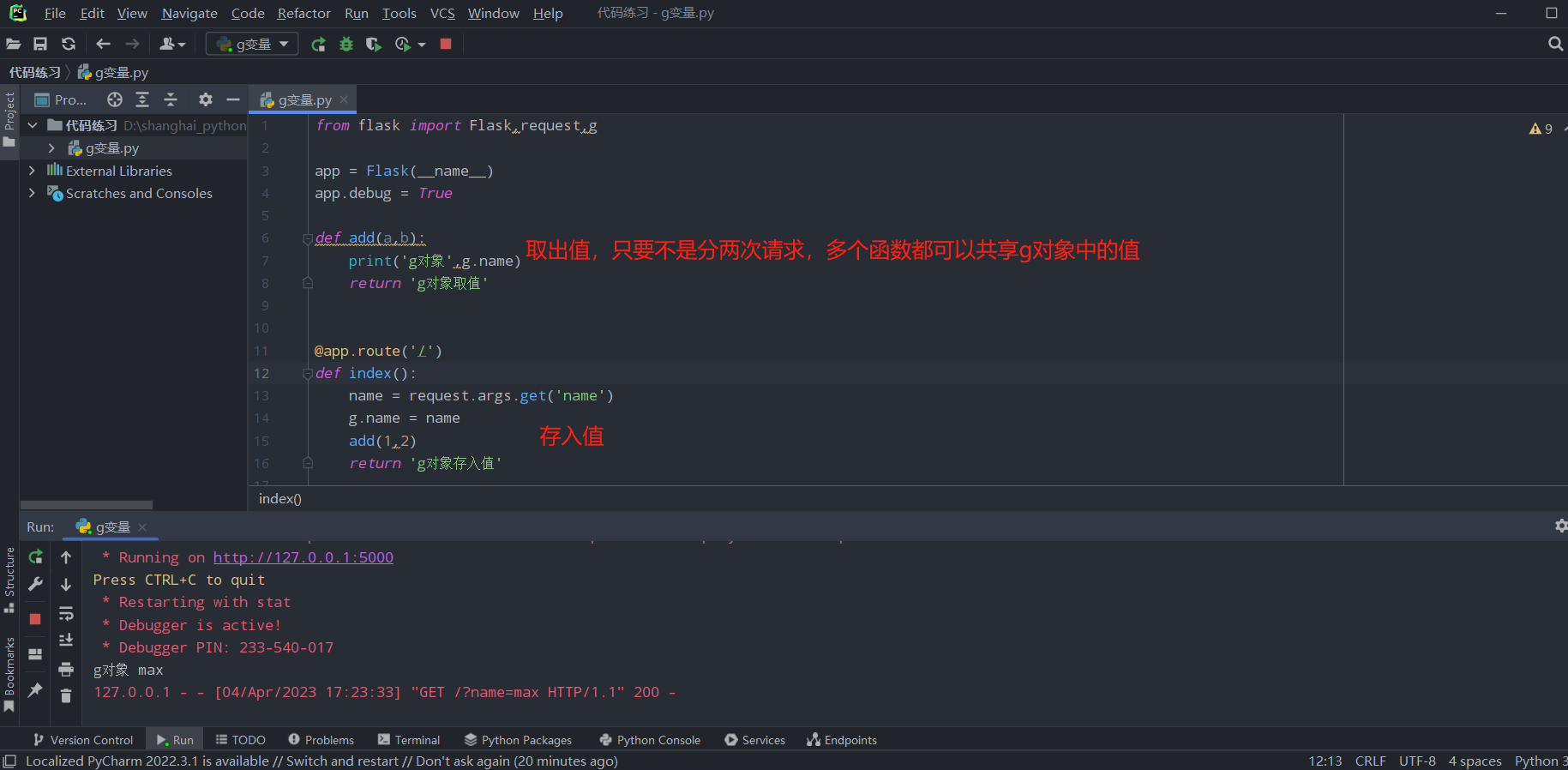
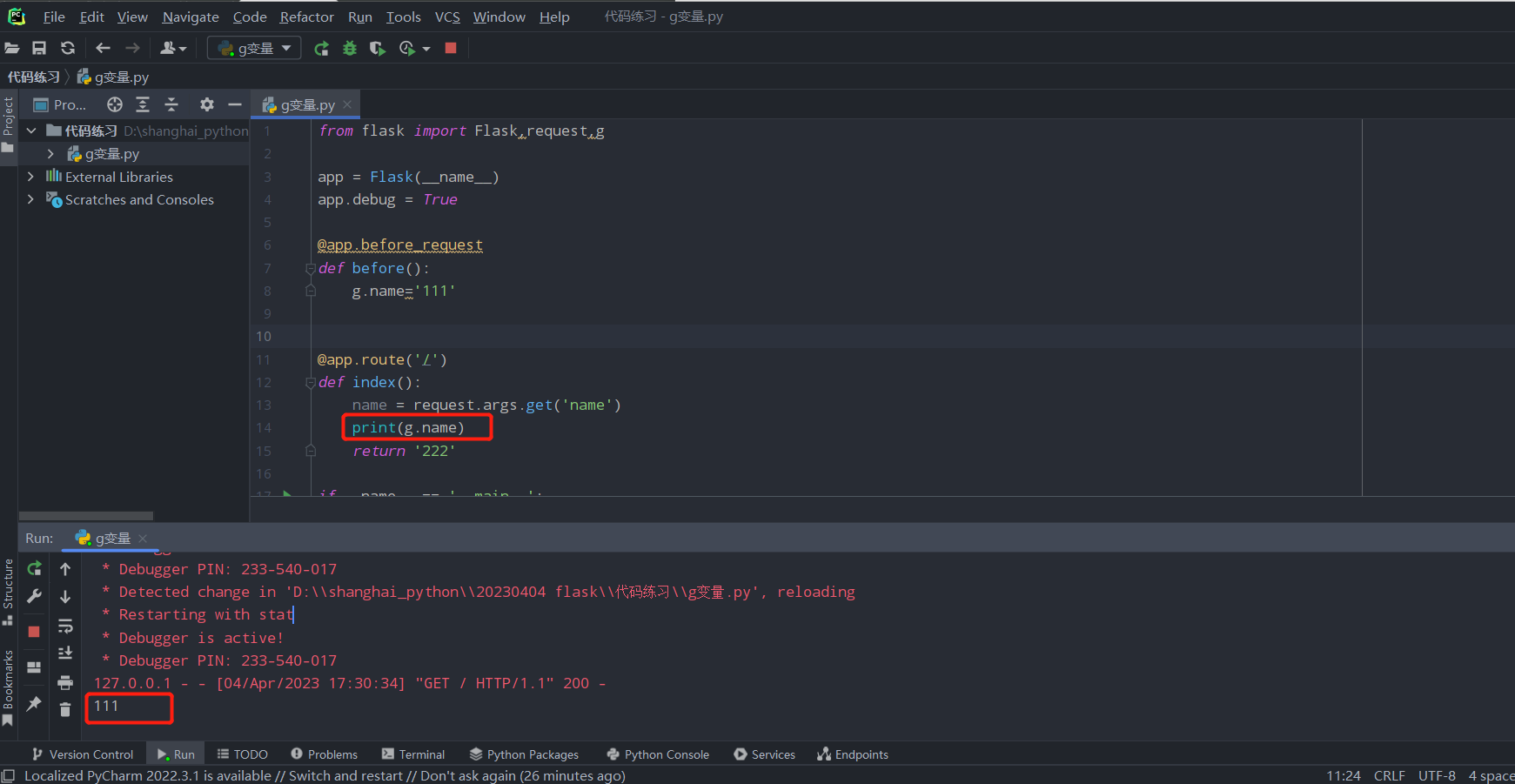
同理,同一个请求也可以在请求扩展中的before_request中存入值,在视图函数中取值:
from flask import Flask,request,g
app = Flask(__name__)
app.debug = True
@app.before_request
def before():
g.name='111'
@app.route('/')
def index():
name = request.args.get('name')
print(g.name)
return '222'
if __name__ == '__main__':
app.run()
3.数据库连接池
3.1 flask连接数据库
python连接数据库都需要首先下载pymysql模块
连接数据库有以下几种方式:
方式一:以上操作的底层逻辑是来一个请求,创建一个连接,请求结束,连接关闭,django就是这么做的
from flask import Flask
import pymysql
app = Flask(__name__)
app.debug=True
@app.route('/book')
def book():
conn = pymysql.connect(
user='root',
password='123456',
host='127.0.0.1',
database='book',
port=3306,
)
# cursor = conn.cursor() # (('三国演义', Decimal('888.88'), '北方出版社'), ('西游记', Decimal('999.99'), '东方出版社'))
# 括号内什么都不写是元组套元组
cursor = conn.cursor(pymysql.cursors.DictCursor) # [{'name': '三国演义', 'price': Decimal('888.88'), 'publish': '北方出版社'}, {'name': '西游记', 'price': Decimal('999.99'), 'publish': '东方出版社'}]
# 括号内指定pymysql.cursors.DictCursor结果是列表套元组
cursor.execute('select * from book limit 2')
res = cursor.fetchall()
# res = cursor.fetchone() fetchone是一次只能拿一条,执行多次就是每次都只拿第一条,后面的无法拿到
print(res)
return 'index'
if __name__ == '__main__':
app.run()
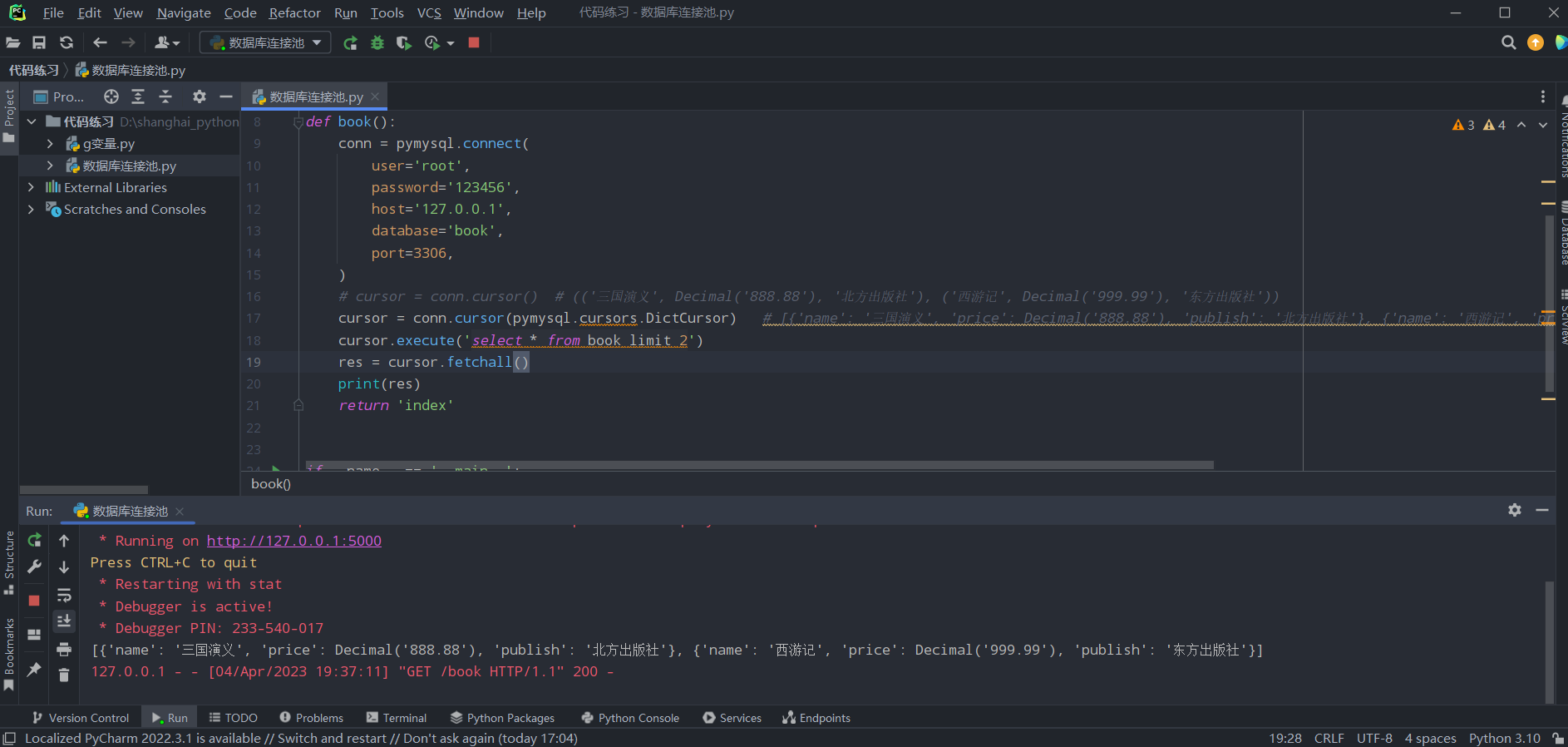
如果想展示在前端页面直接return出去:
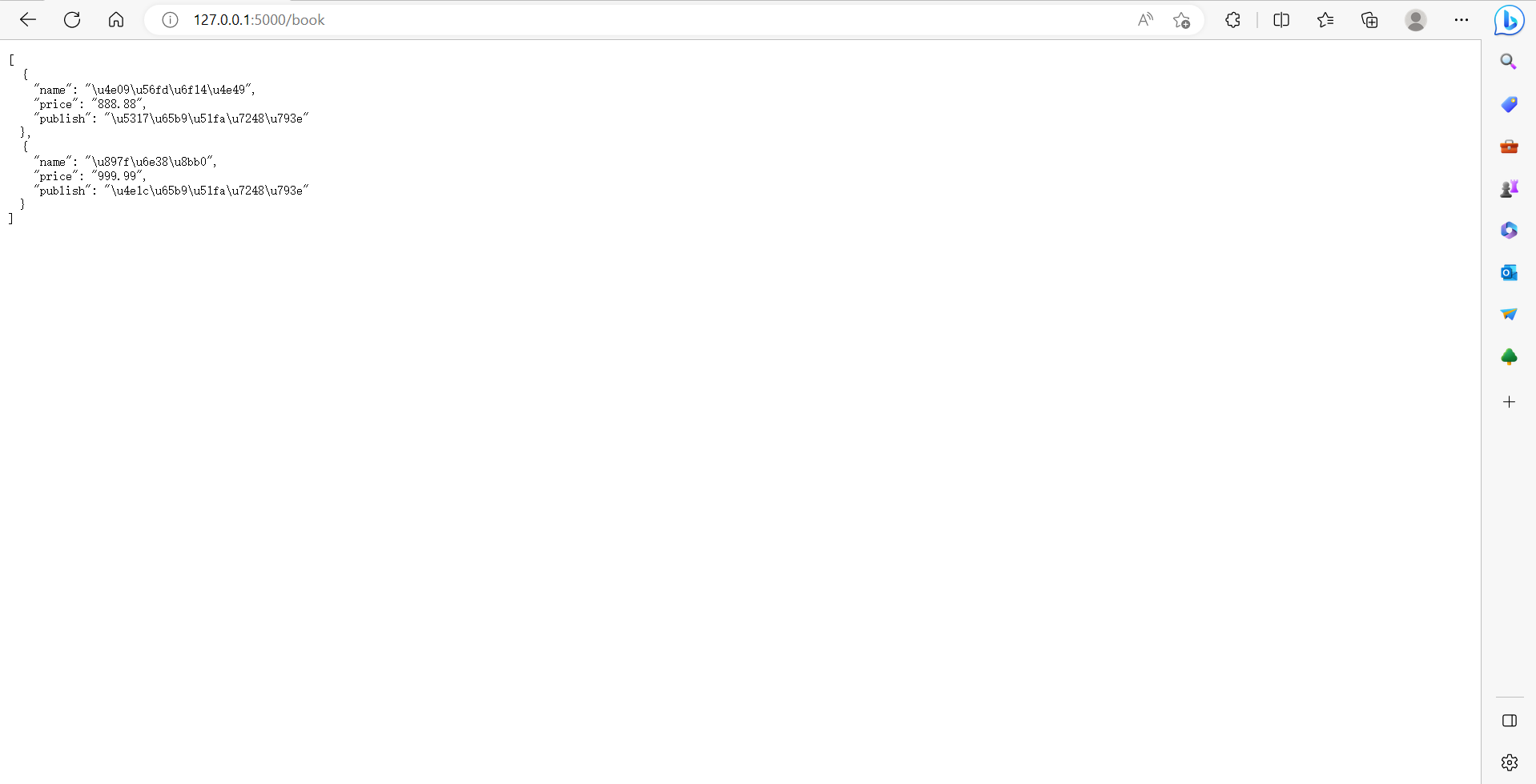
方式二:把链接对象做成全局的,在视图函数中使用全局的连接,查询,返回给前端。但是这种方法也会出一个问题:数据并发量很高的时候,会出现数据错乱:
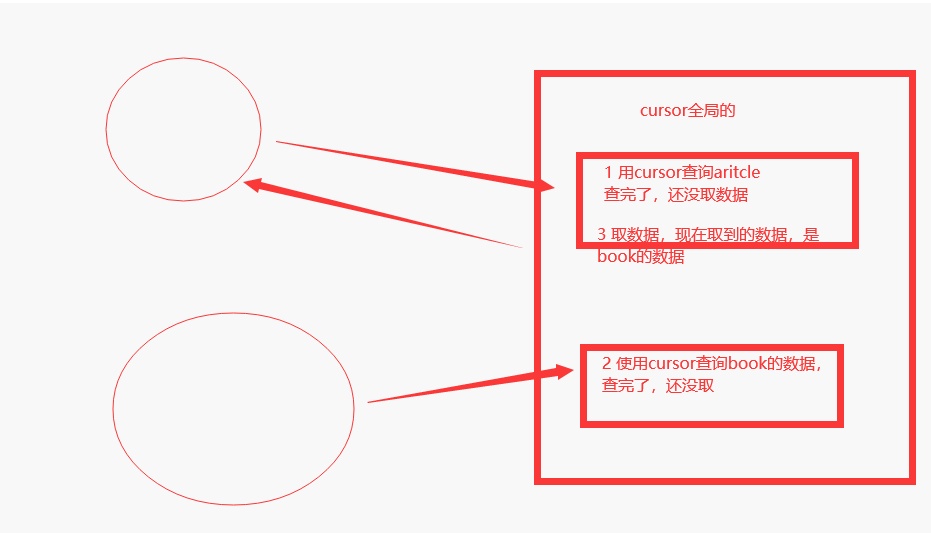
方式三:数据库连接池
创建一个全局的池,每次进入视图函数,从池中取一个连接使用,使用完放回到池中,只要控制池大小,就能控制mysql连接数。flask不回提供连接池,需要使用第三方模块。
使用连接池连接步骤:
1.下载模块:
pip install dbutils
2.实例化得到一个池对象
POOL.py
from dbutils.pooled_db import PooledDB
import pymysql
pool = PooledDB(
creator=pymysql, # 使用链接数据库的模块
maxconnections=10, # 连接池允许的最大连接数,0和None表示不限制连接数
mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建
maxcached=5, # 链接池中最多闲置的链接,0和None不限制。如果设置一个数字,那么连接完成没有用的线程就会被销毁
maxshared=3,
# 链接池中最多共享的链接数量,0和None表示全部共享。PS: 无用,因为pymysql和MySQLdb等模块的 threadsafety都为1,所有值无论设置为多少,_maxcached永远为0,所以永远是所有链接都共享。
blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,直接报错
maxusage=None, # 一个链接最多被重复使用的次数,None表示无限制
setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."]
ping=0,
# ping MySQL服务端,检查是否服务可用。# 如:0 = None = never, 1 = default = whenever it is requested, 2 = when a cursor is created, 4 = when a query is executed, 7 = always
host='127.0.0.1',
port=3306,
user='root',
password='123456',
database='book',
charset='utf8'
)
flask.py:
from flask import Flask,jsonify
import pymysql
from POOL import pool
app = Flask(__name__)
app.debug=True
'''使用连接池连接'''
@app.route('/index')
def index():
conn = pool.connection()
cursor = conn.cursor(pymysql.cursors.DictCursor)
cursor.execute('select * from book limit 2')
res = cursor.fetchall()
print(res)
return jsonify(res)
'''使用pymysql连接'''
@app.route('/book')
def book():
conn = pymysql.connect(
user='root',
password='123456',
host='127.0.0.1',
database='book',
port=3306,
)
cursor = conn.cursor(
pymysql.cursors.DictCursor) # [{'name': '三国演义', 'price': Decimal('888.88'), 'publish': '北方出版社'}, {'name': '西游记', 'price': Decimal('999.99'), 'publish': '东方出版社'}]
cursor.execute('select * from book limit 2')
res = cursor.fetchall()
print(res)
return jsonify(res)
if __name__ == '__main__':
app.run()
访问/index页面依然可以看到数据显示在页面上:

我们现在访问/index和/book都可以拿到相同的结果,但是我们无法判断他们之间的差异:
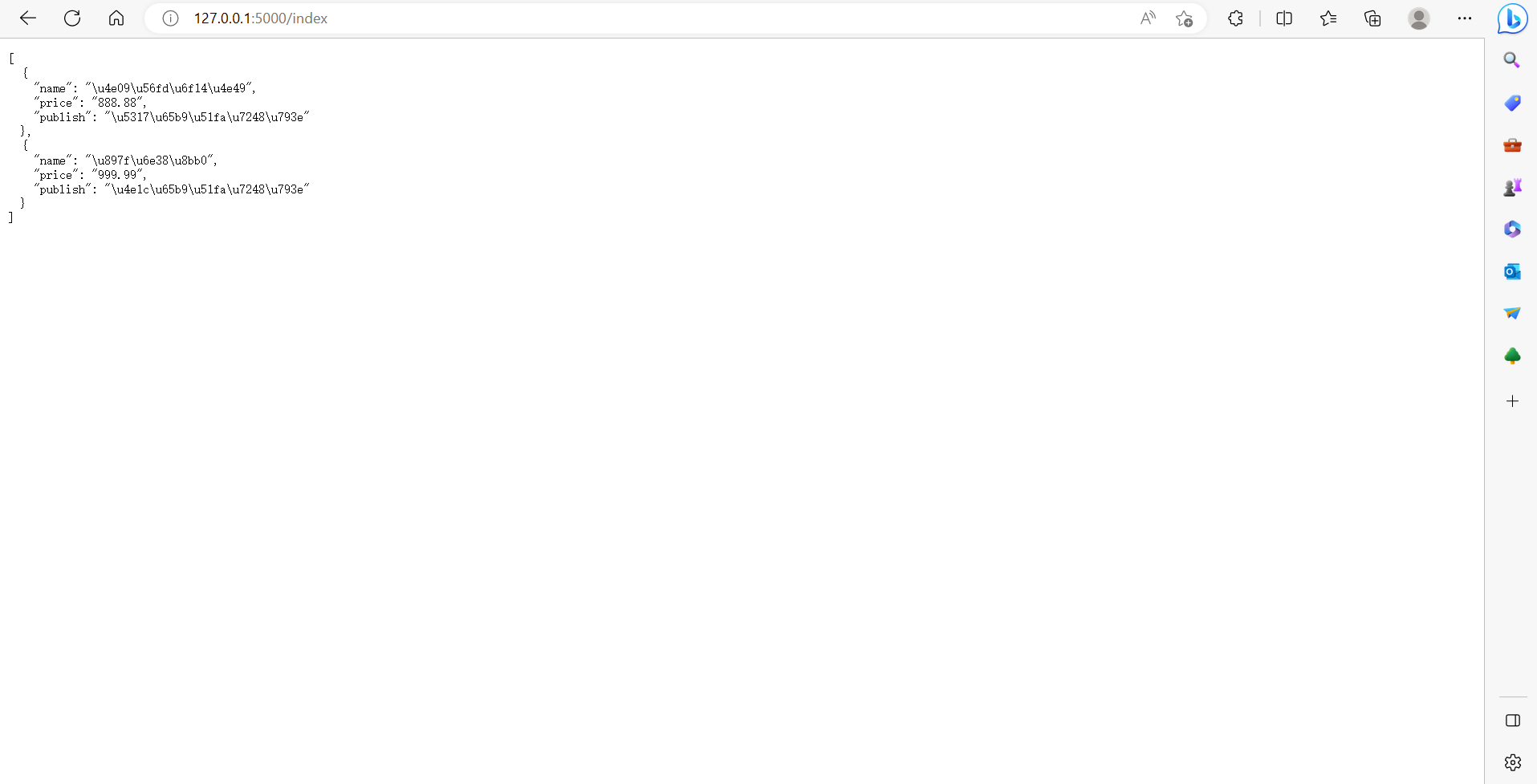
接下来我们修改代码,在每个执行路由下time.sleep3秒,然后写300个线程连接数据库,来观察普通链接和连接池连接的差别:
import time
from flask import Flask, jsonify
import pymysql
from POOL import pool
app = Flask(__name__)
app.debug = True
'''连接池连接'''
@app.route('/index')
def index():
conn = pool.connection()
cursor = conn.cursor(pymysql.cursors.DictCursor)
cursor.execute('select * from book limit 2')
res = cursor.fetchall()
time.sleep(3)
print(res)
return jsonify(res)
'''普通连接'''
@app.route('/book')
def book():
conn = pymysql.connect(
user='root',
password='123456',
host='127.0.0.1',
database='book',
port=3306,
)
cursor = conn.cursor(
pymysql.cursors.DictCursor) # [{'name': '三国演义', 'price': Decimal('888.88'), 'publish': '北方出版社'}, {'name': '西游记', 'price': Decimal('999.99'), 'publish': '东方出版社'}]
cursor.execute('select * from book limit 2')
time.sleep(3)
res = cursor.fetchall()
print(res)
return jsonify(res)
if __name__ == '__main__':
app.run()
在写一个py脚本,来开启多线程连接数据库:
import requests
from threading import Thread
def task():
res = requests.get('http://127.0.0.1:5000/book')
print(res.text)
if __name__ == '__main__':
for i in range(300):
t = Thread(target=task)
t.start()
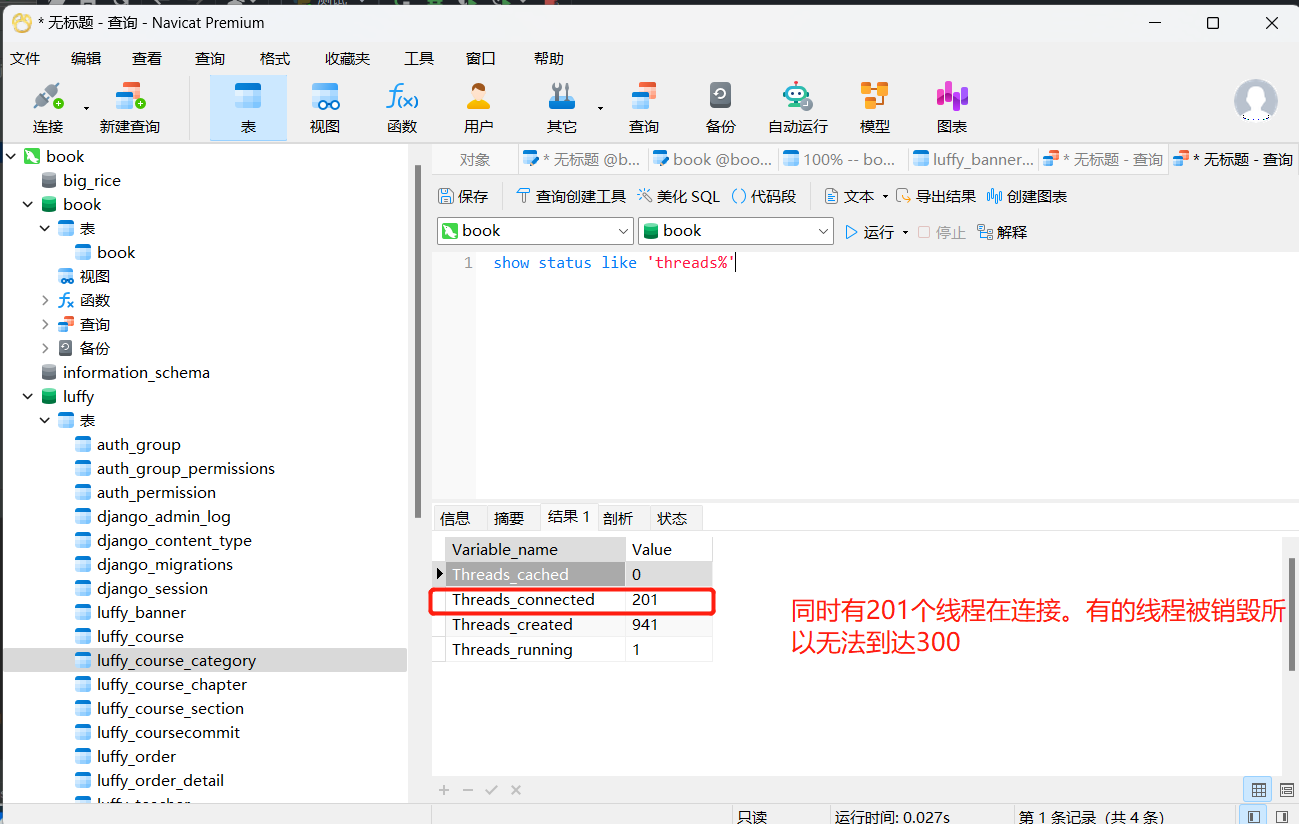
补充:在navicat中可以使用以下代码查看正在连接的线程数,Threads_connected就是正在连接的线程数:
show status like 'threads%'
而我们再用连接池连接,发现无论我们sleep几秒(其实和sleep几秒无关),正在连接的线程数都不超过10,这是因为我们设置池的最大连接数为10:
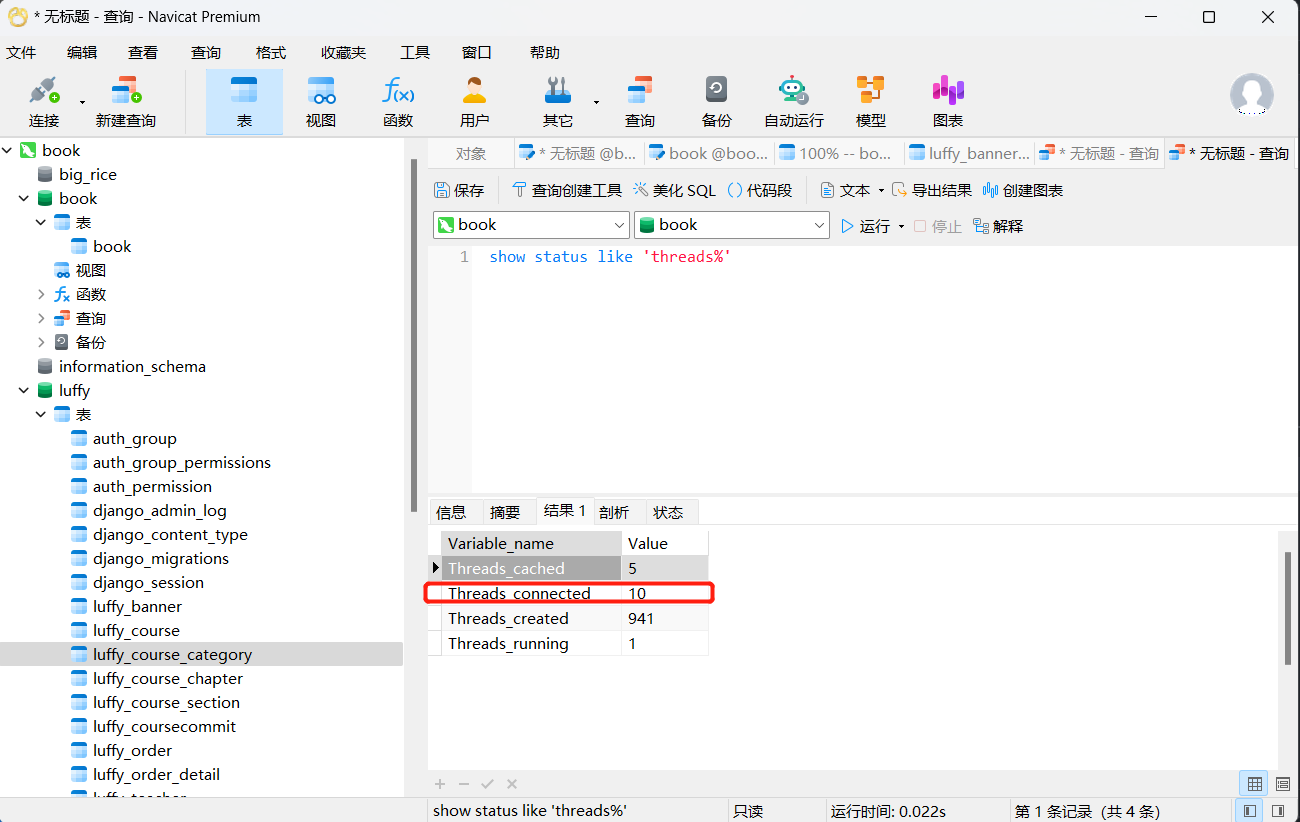
结论:使用连接池连接的数量会受限,这也是保证数据库效率的措施。不使用连接池同时有多个线程在连接数据库,尤其是做了集群化的部署,这样数据库的效率会受限更明显。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号