1.正则表达式基础
案例:京东注册手机号校验
基本需求:手机号必须是11位、手机号必须以13 15 17 18 19开头、必须是纯数字
'''纯python代码实现'''
while True:
# 1.获取用户输入的手机号
phone_num = input('请输入您的手机号>>>:').strip()
# 2.先判断是否是十一位
if len(phone_num) == 11:
# 3.再判断是否是纯数字
if phone_num.isdigit():
# 4.判断手机号的开头
if phone_num.startswith('13') or phone_num.startswith('15') or phone_num.startswith(
'17') or phone_num.startswith('18') or phone_num.startswith('19'):
print('手机号码输入正确')
else:
print('手机号开头不对')
else:
print('手机号必须是纯数字')
else:
print('手机号必须是11位')
'''python结合正则实现'''
import re
phone_number = input('please input your phone number: ')
if re.match('^(13|14|15|18)[0-9]{9}$', phone_number):
print('是合法的手机号码')
else:
print('不是合法的手机号码')
"""
正则表达式是一门独立的技术 所有编程语言都可以使用
它的作用可以简单的概括为:利用一些特殊符号(也可以直接写需要查找的具体字符)的组合产生一些特殊的含义然后去字符串中筛选出符合条件的数据
>>>:筛选数据(匹配数据)
"""
2.字符组
"""
字符组默认匹配方式是挨个挨个匹配
"""
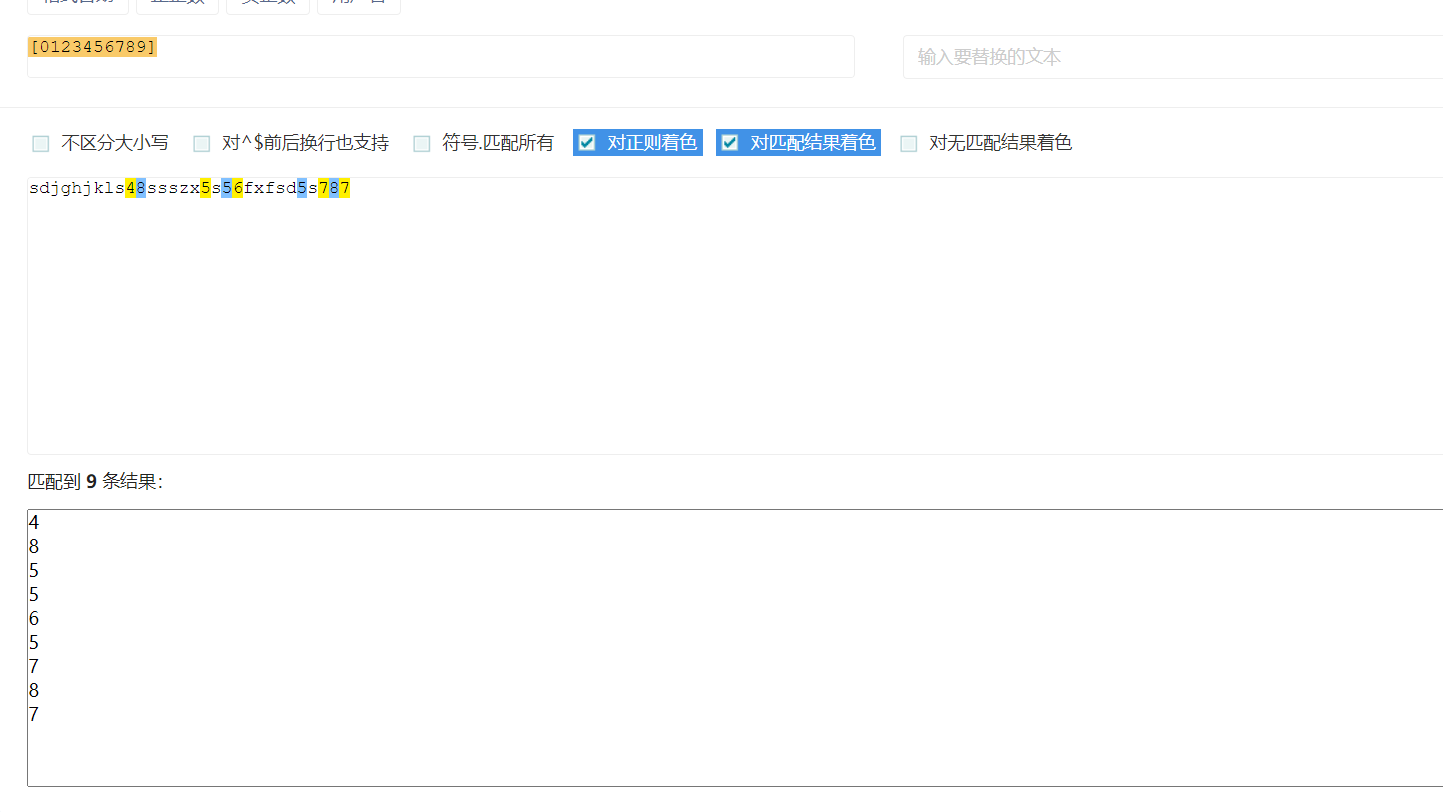
[0123456789]:匹配0-9任意一个数字(全写):文本中所有的数字会一一匹配,一次只能匹配一个字符
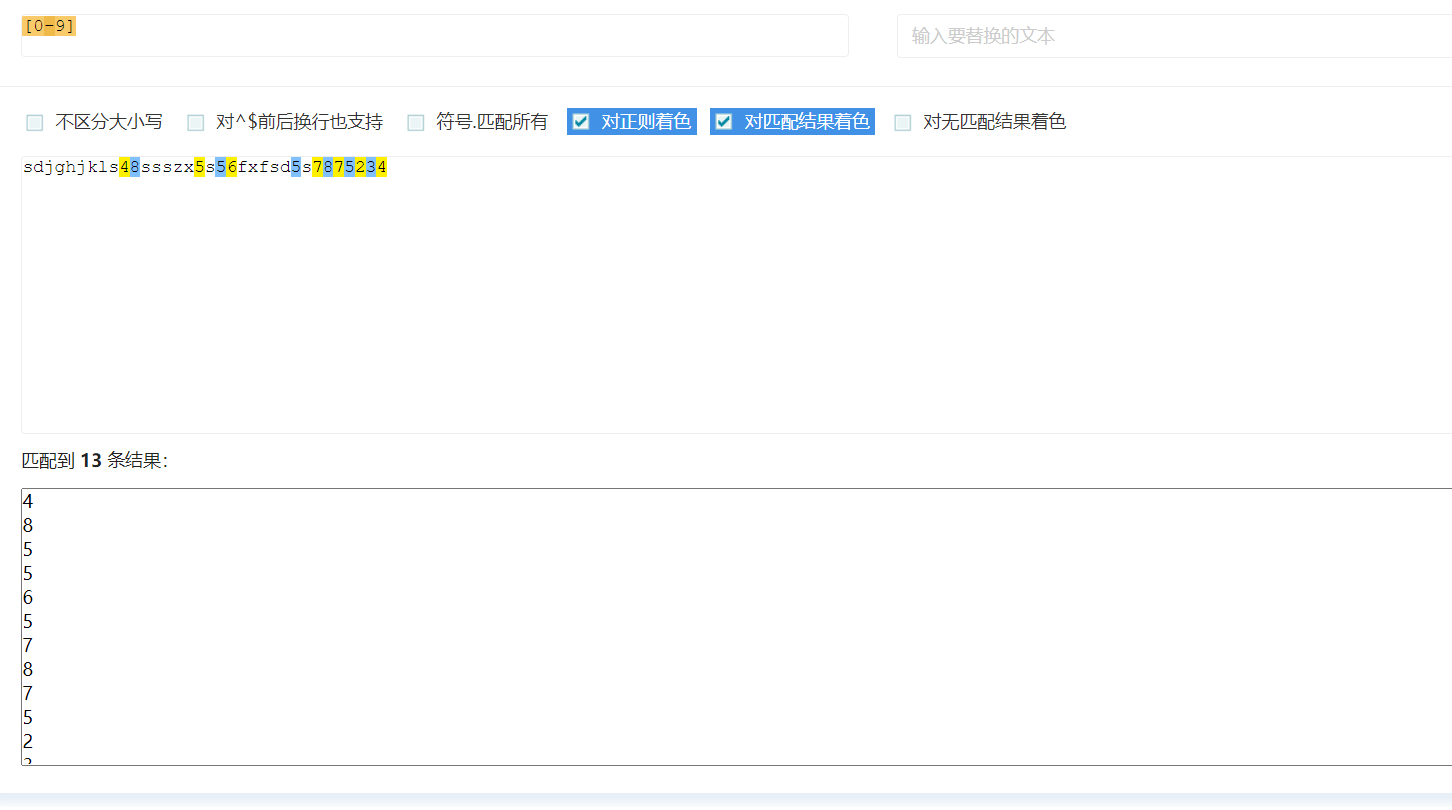
[0-9]:匹配0-9任意一个数(缩写):是上述功能的简写
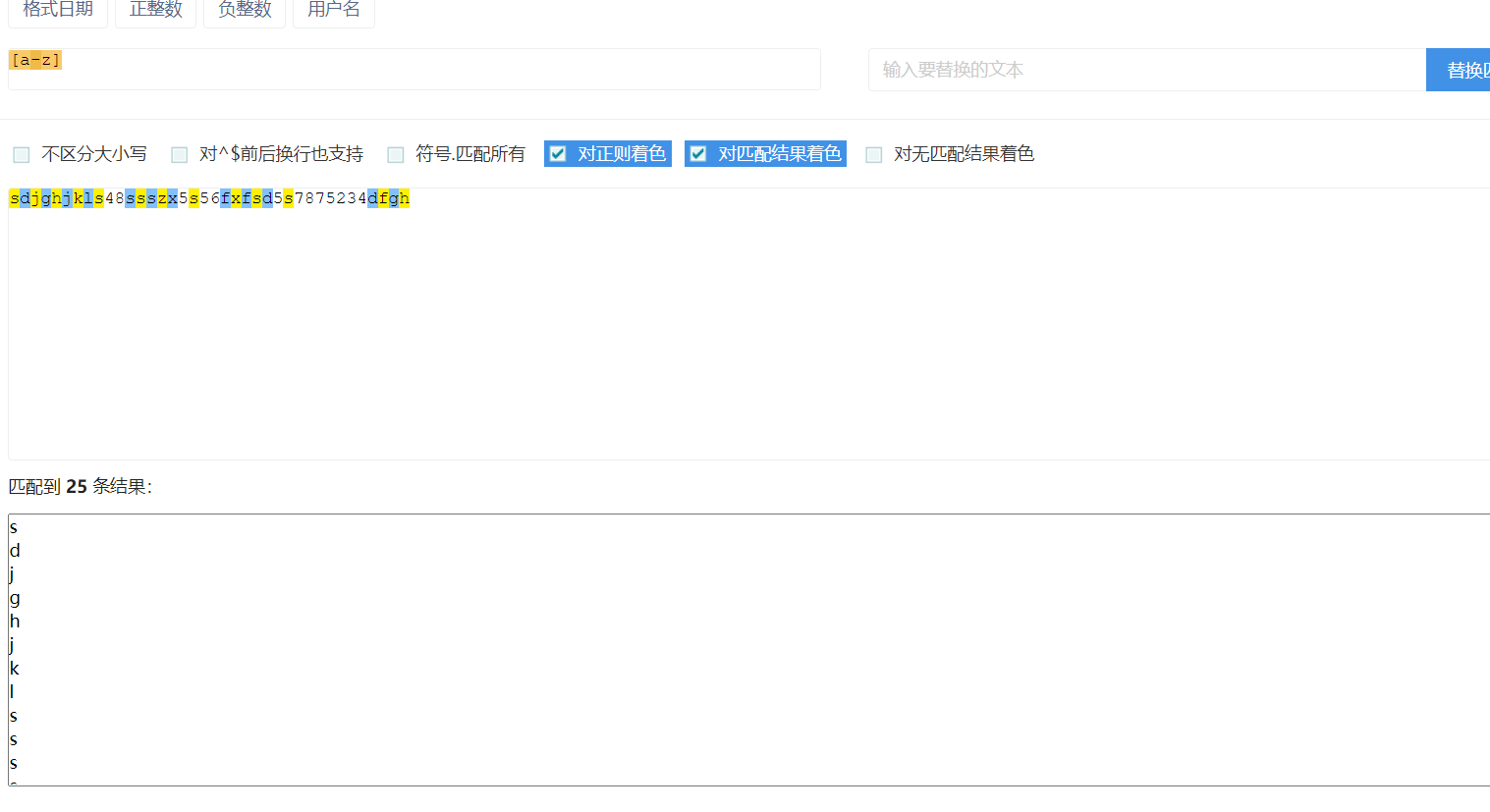
[a-z]:匹配26个小写英文字母,一一匹配
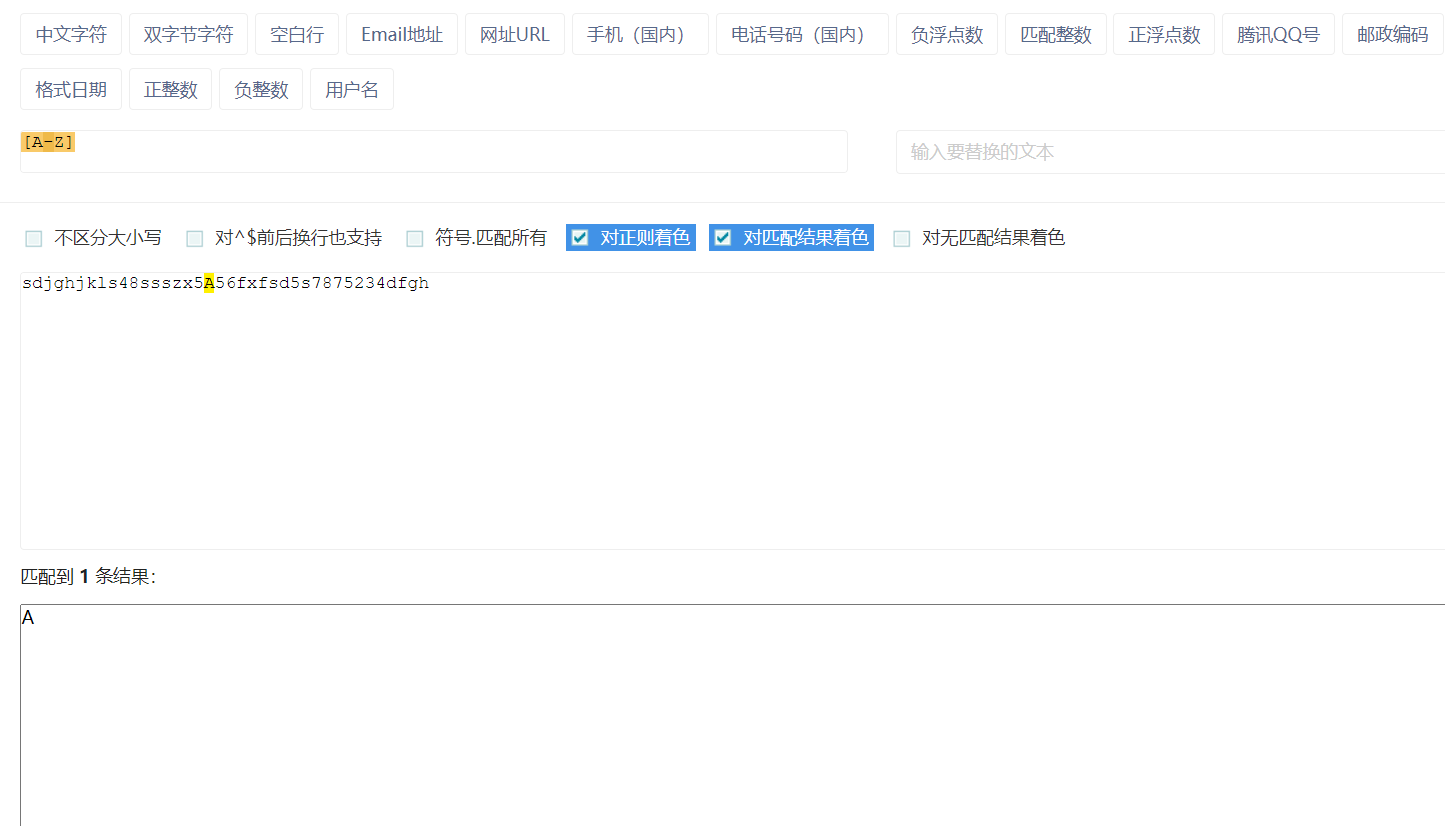
[A-Z]:匹配26个大写英文字母,一一匹配
[0-9a-zA-Z]:匹配数字或者小写字母或者大写字母
ps:字符组内所有的数据默认都是或的关系
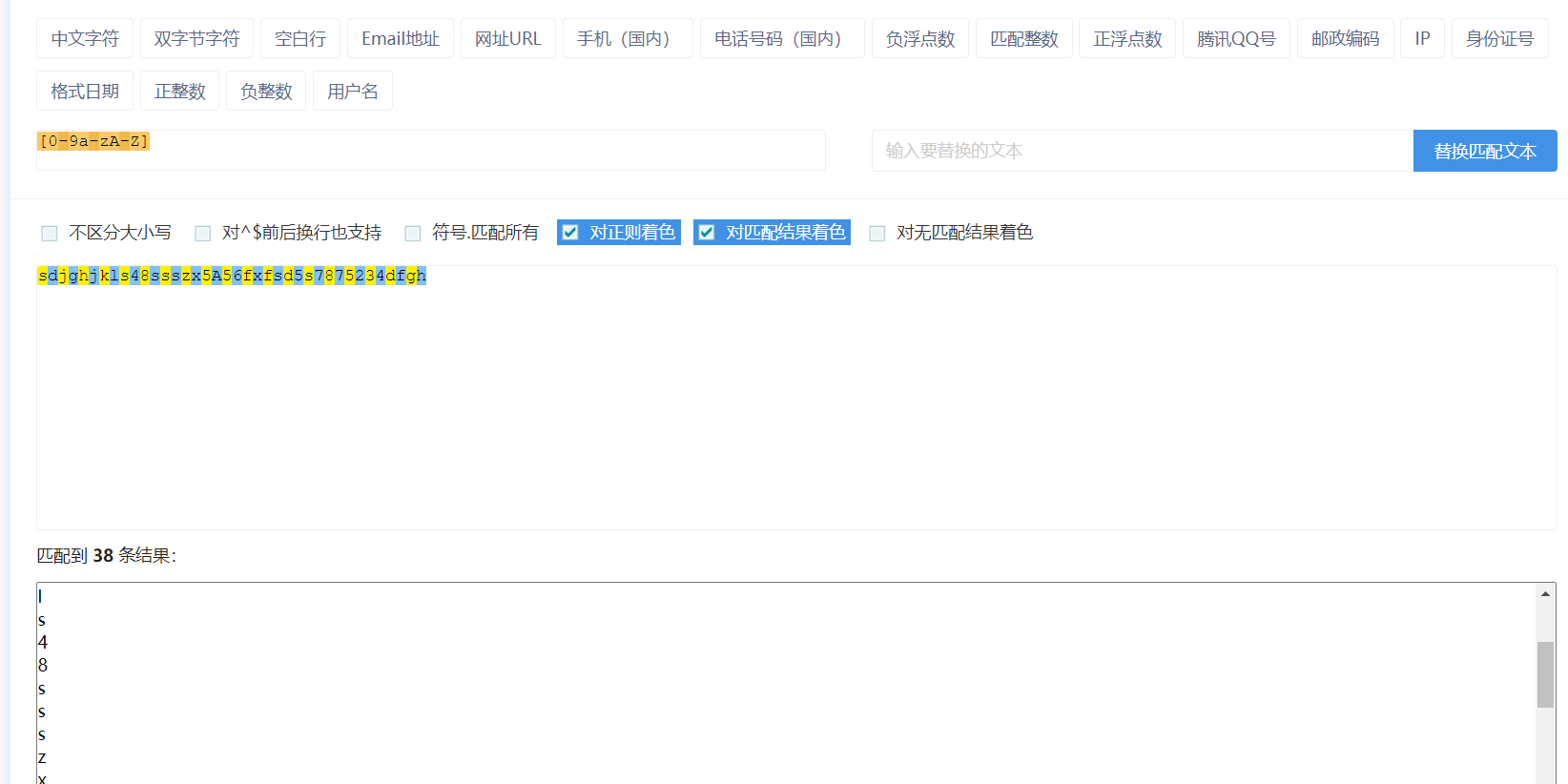
3.特殊符号
'''特殊符号默认匹配方式是挨个挨个匹配'''
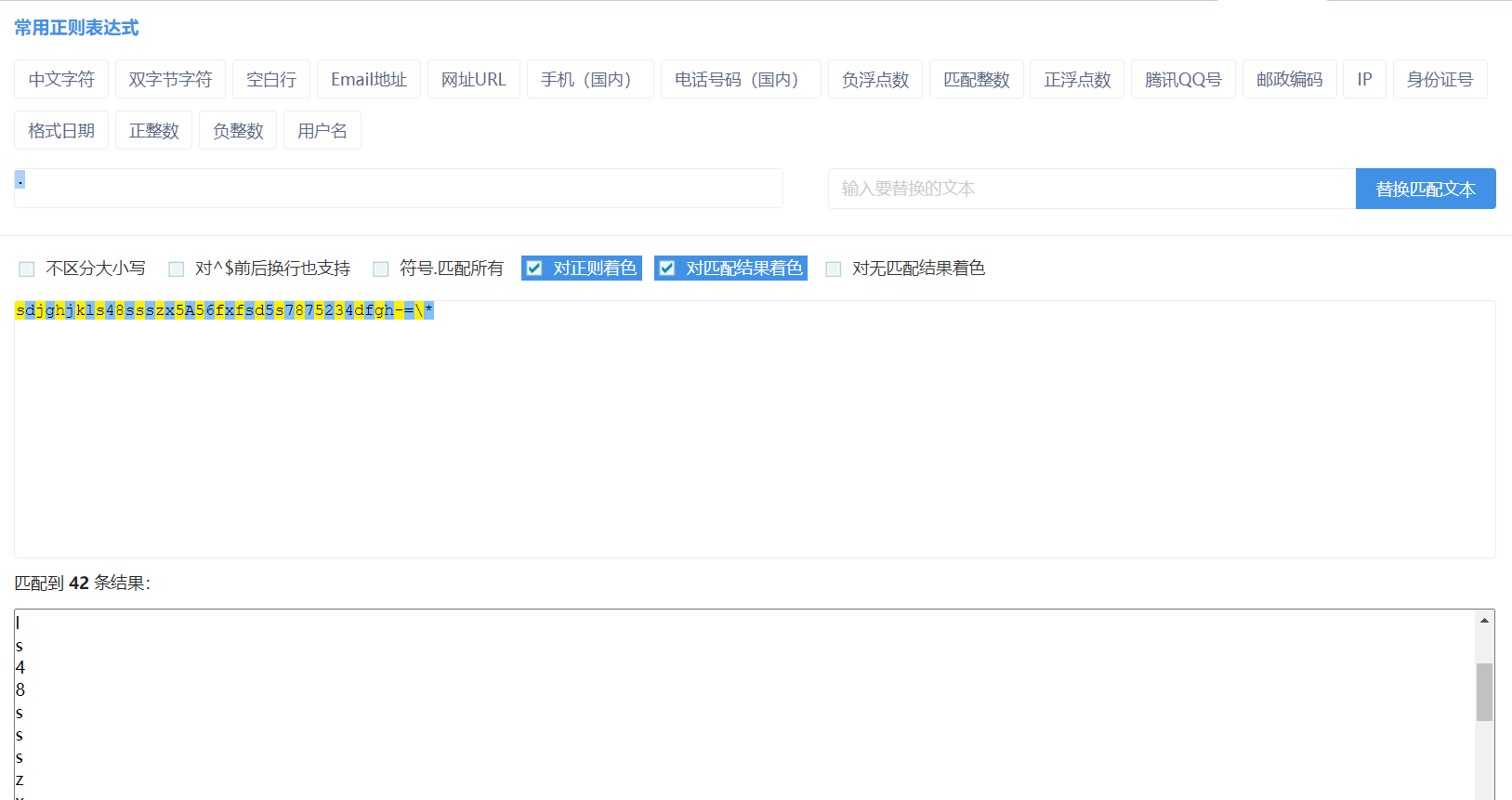
. 匹配除换行符以外的任意字符(包含数字字母)
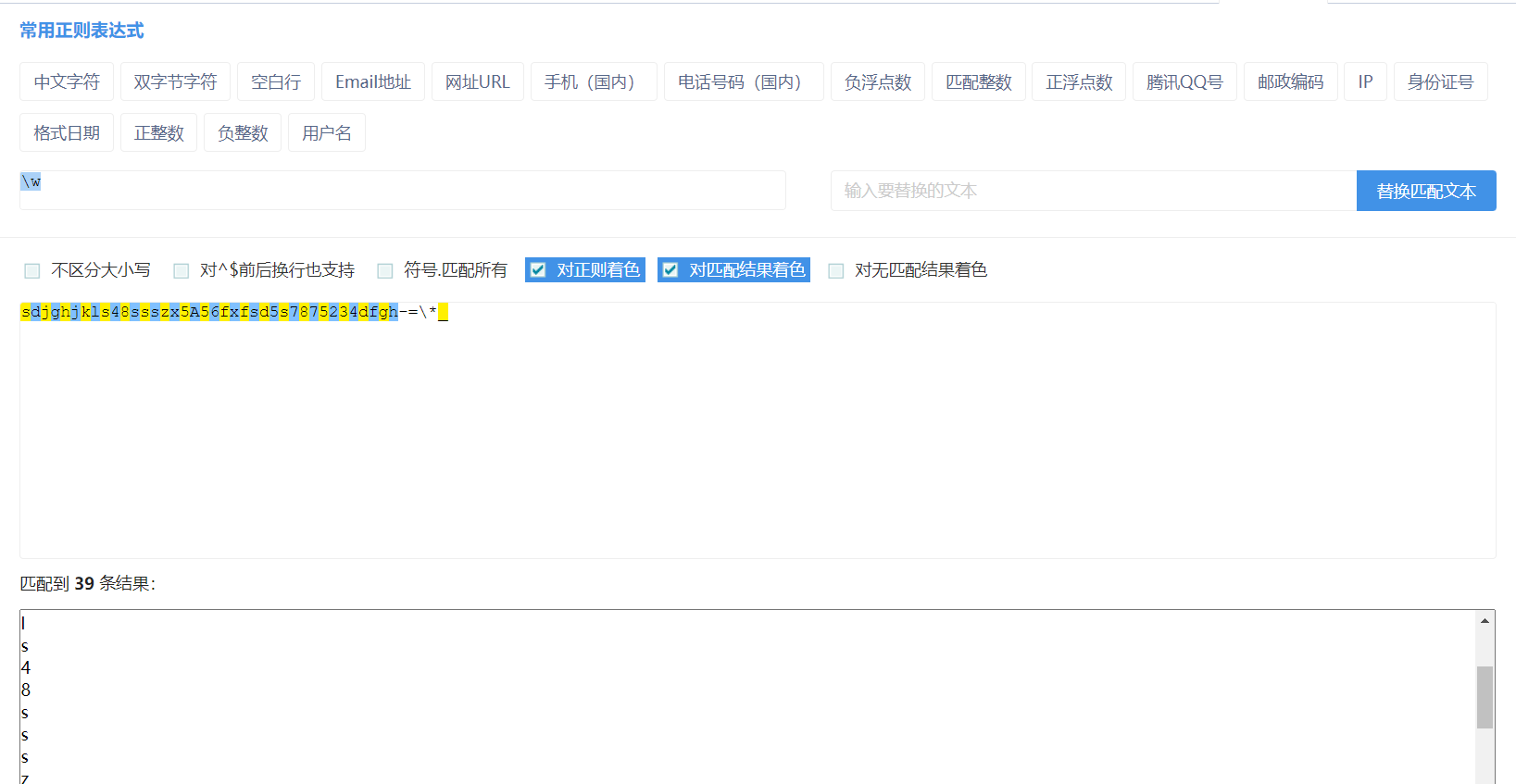
\w:匹配数字、字母、下划线
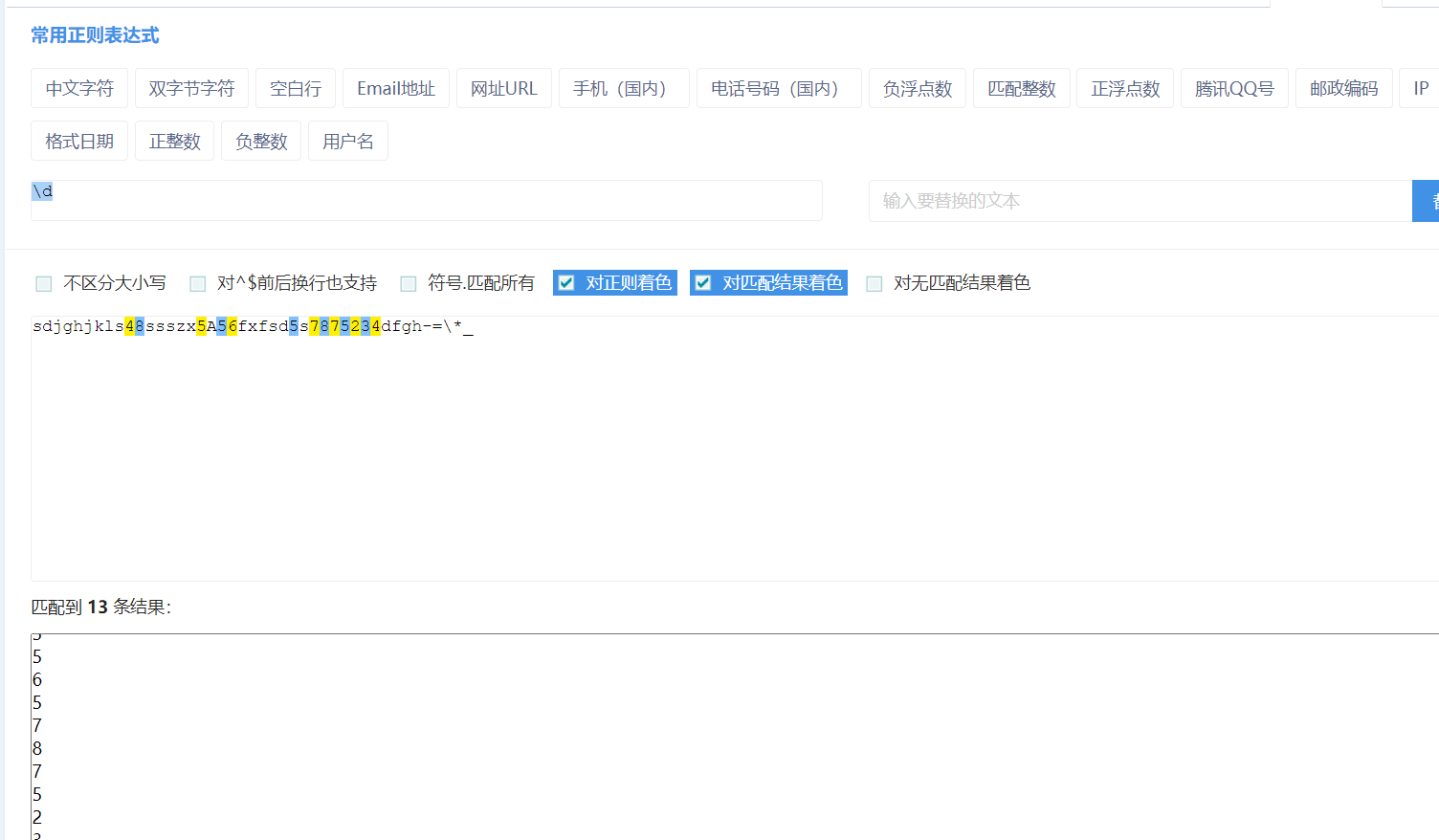
\d:匹配数字
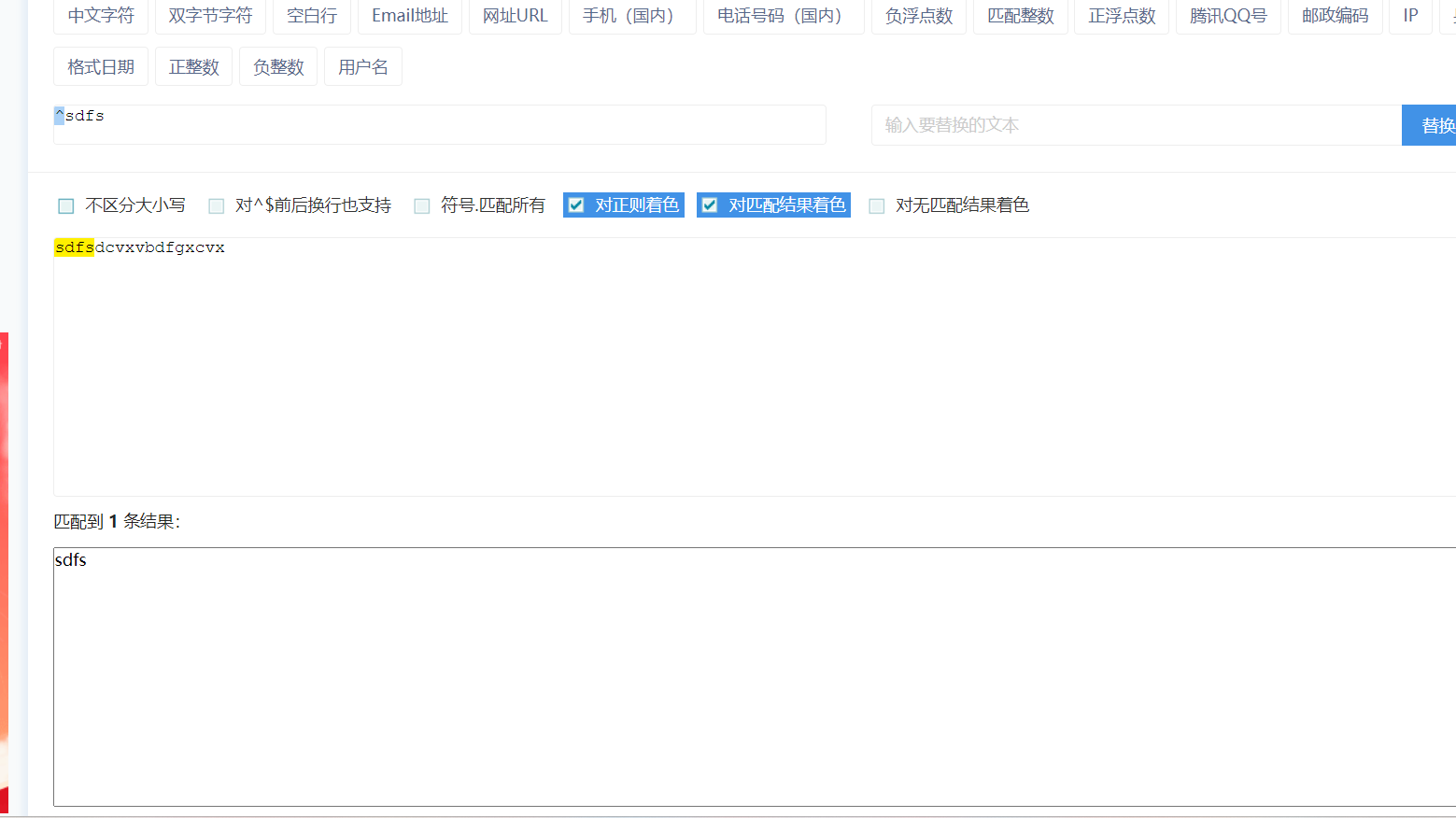
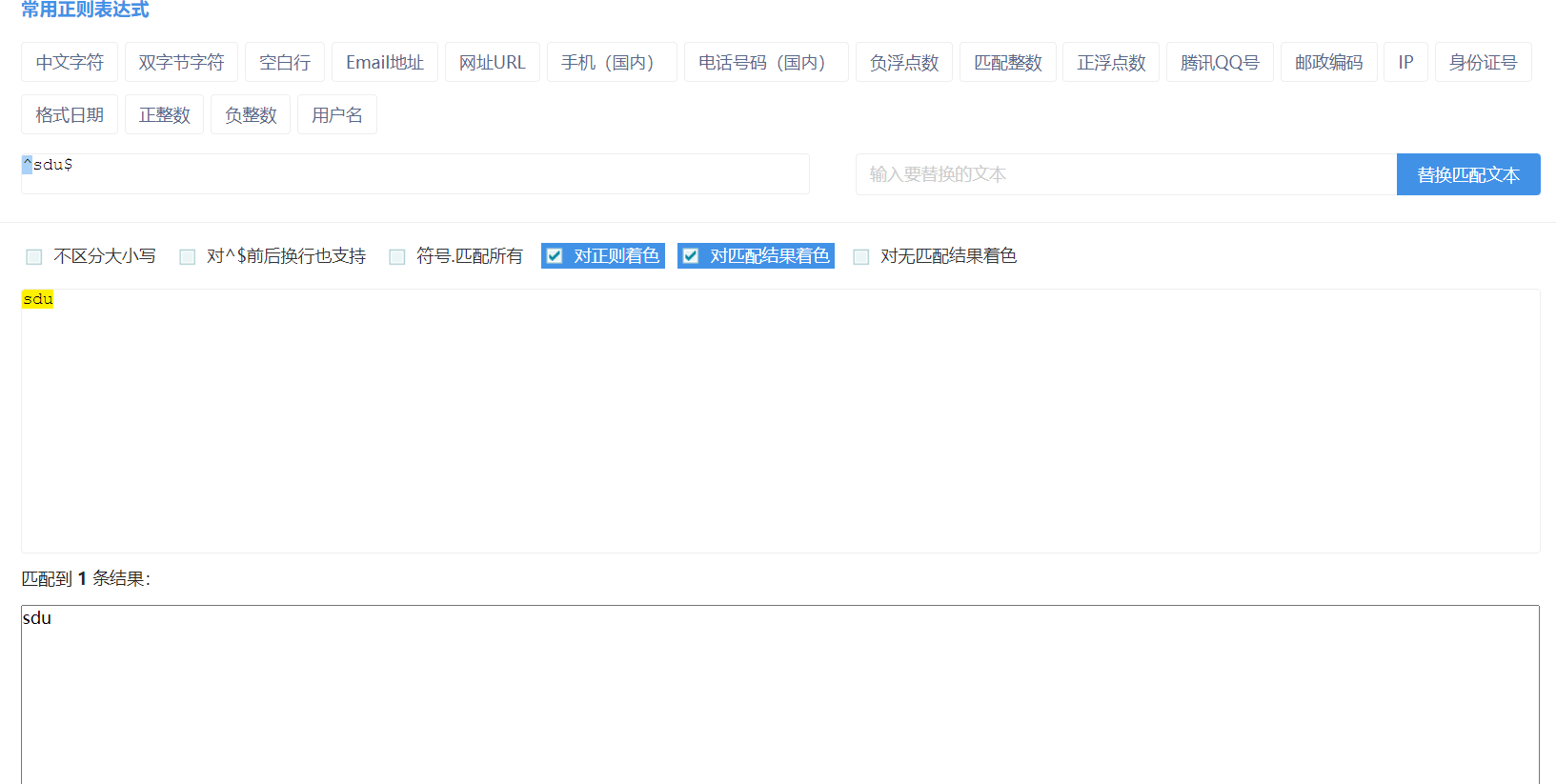
^:匹配字符串的开头(不限几个字符)
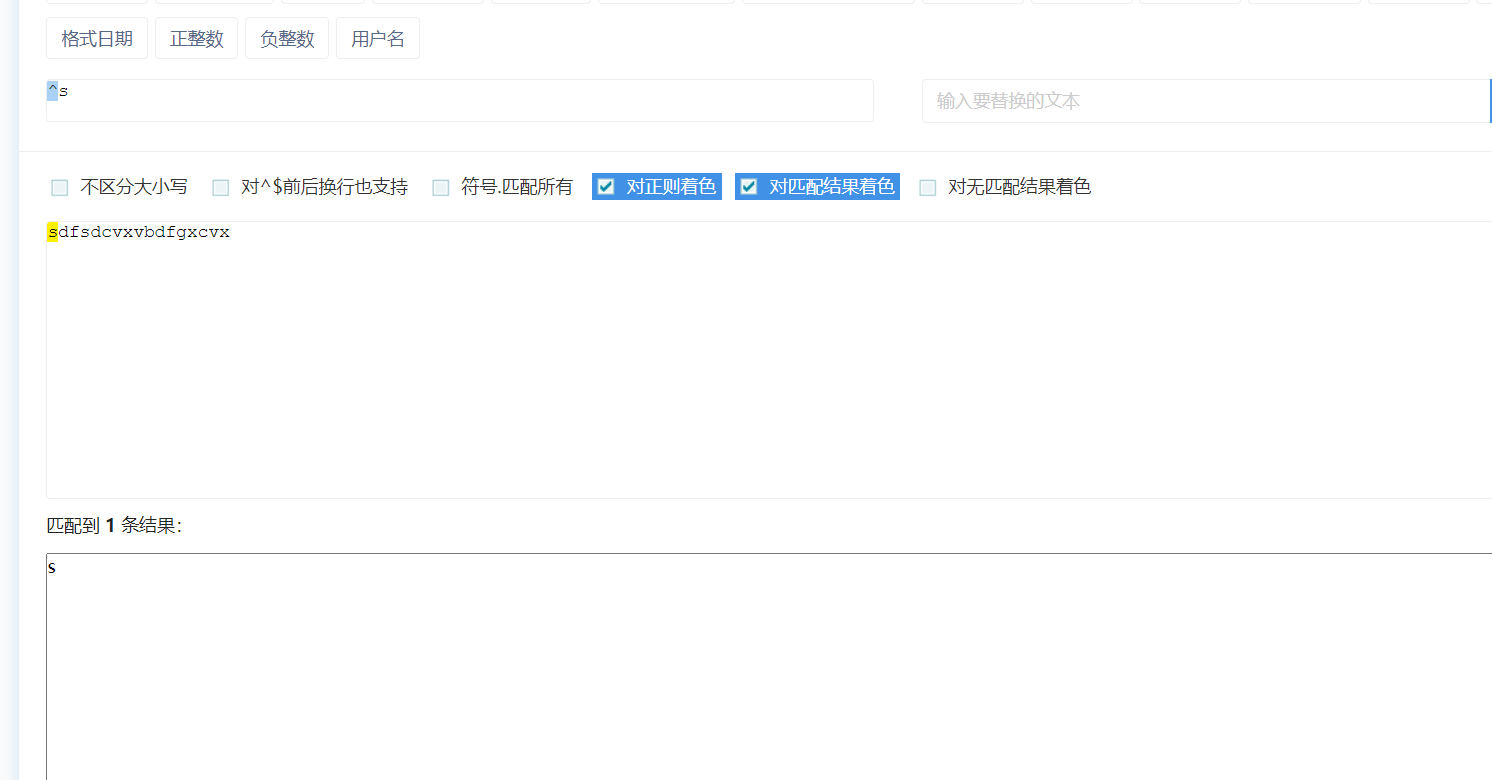
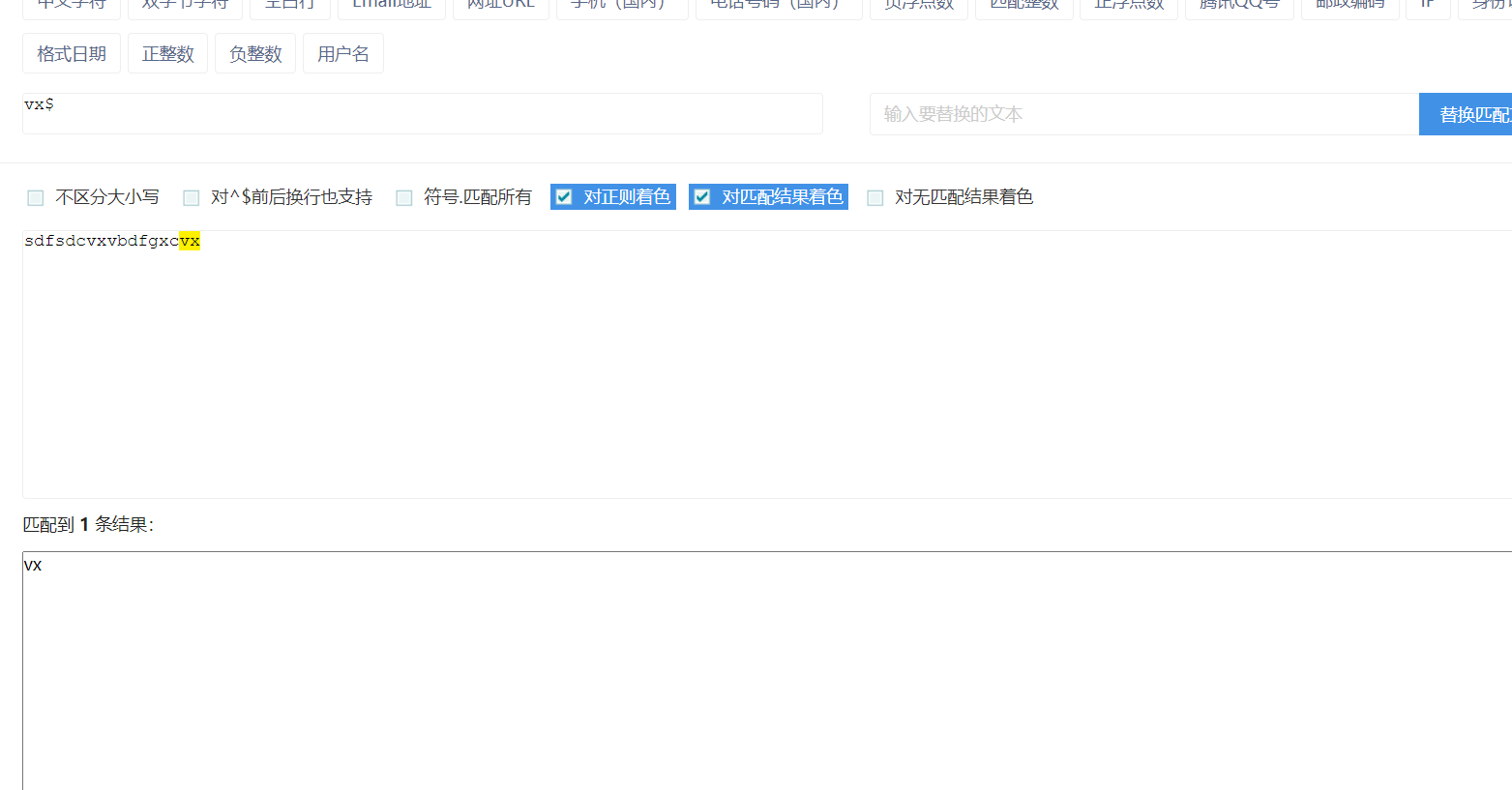
$:匹配字符串的结尾
不限字符个数
^和$两者可以非常精确地限制匹配的内容
a|b:|是或的意思,匹配a或b
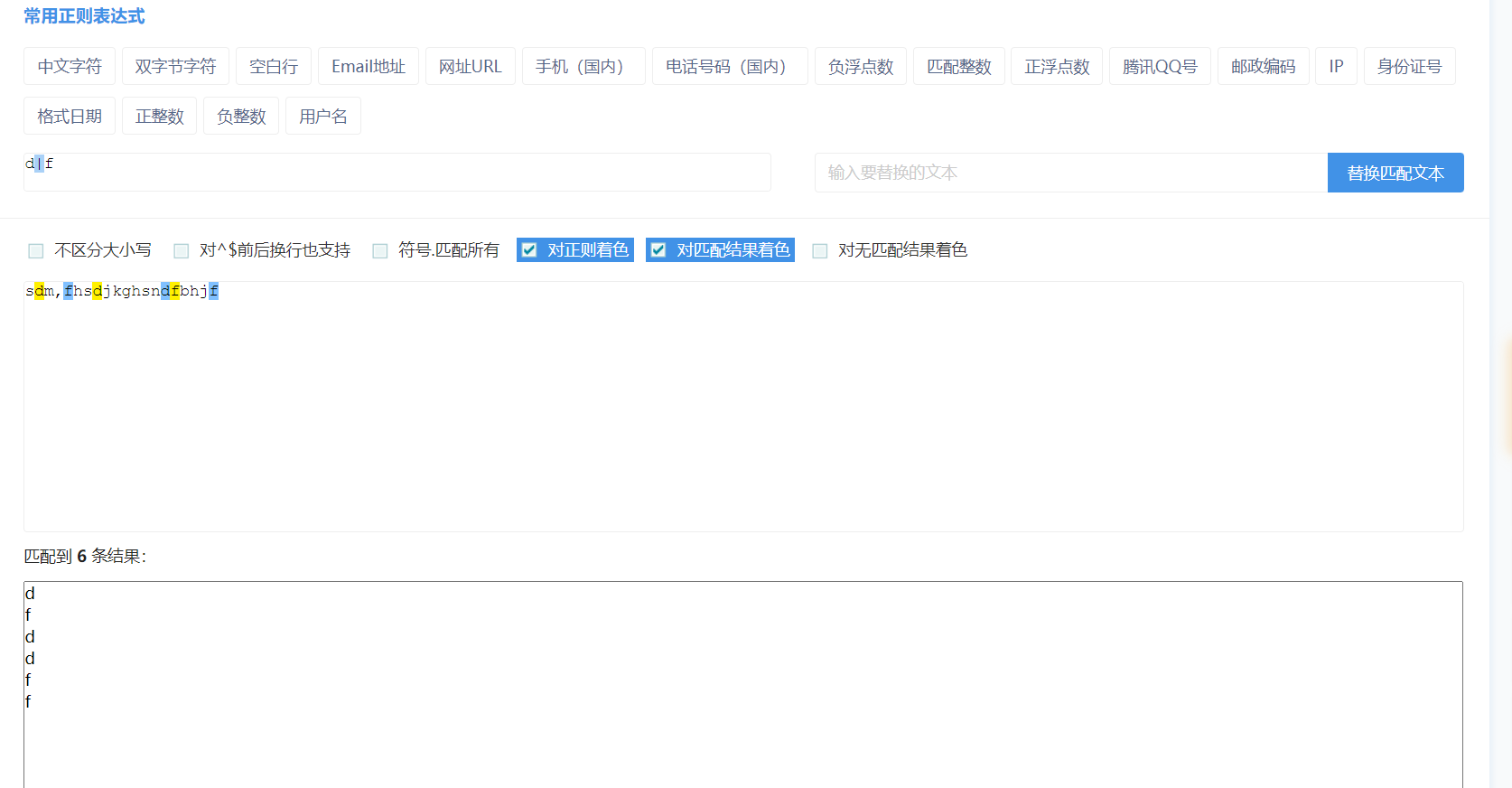
():给正则表达式分组 不影响表达式的匹配功能
[]:字符组 内部填写的内容默认都是或的关系
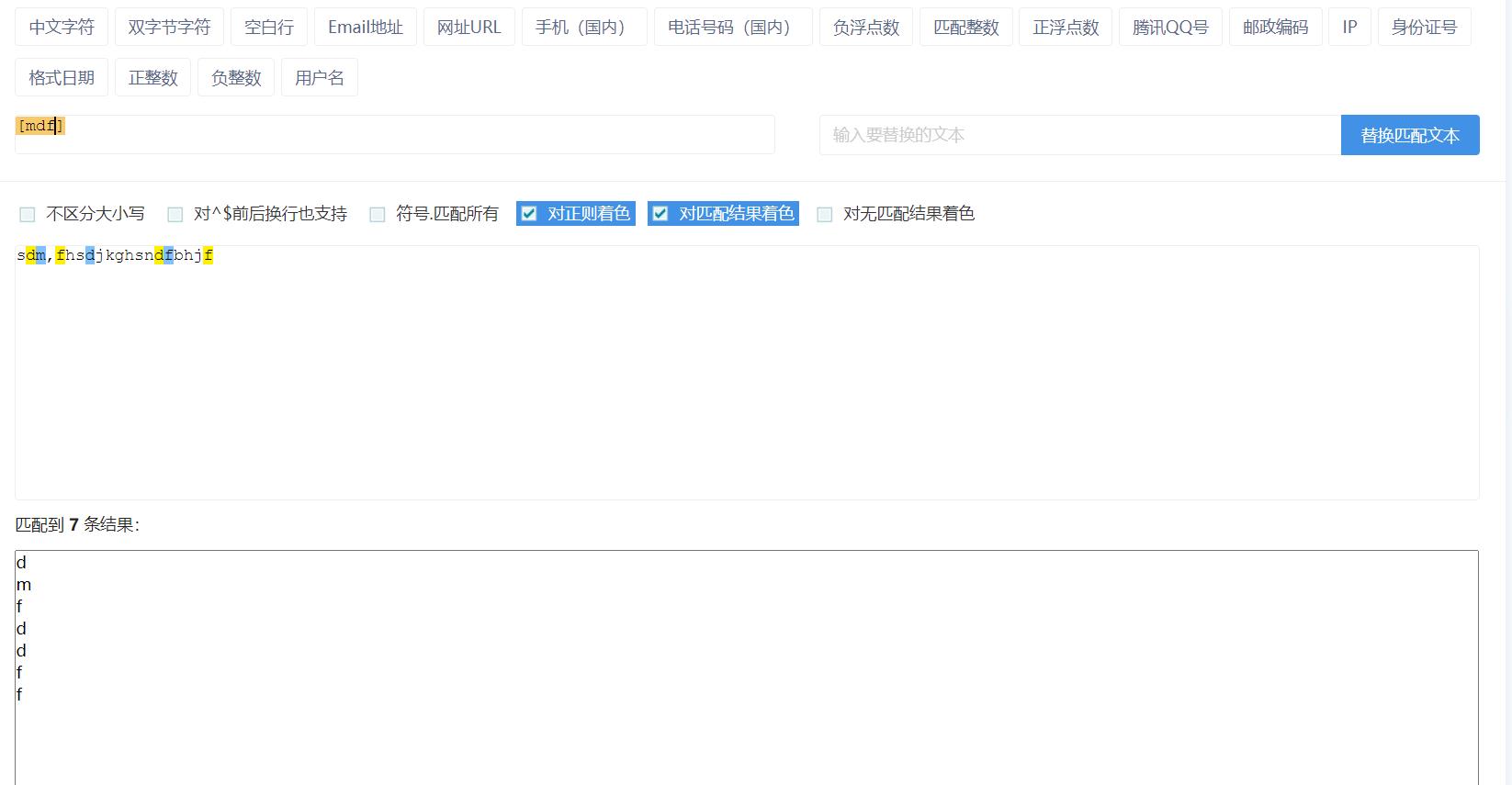
[^]:取反操作,匹配除了字符组里面的其他所有字符(上尖号在中括号内和中括号意思完全不同)
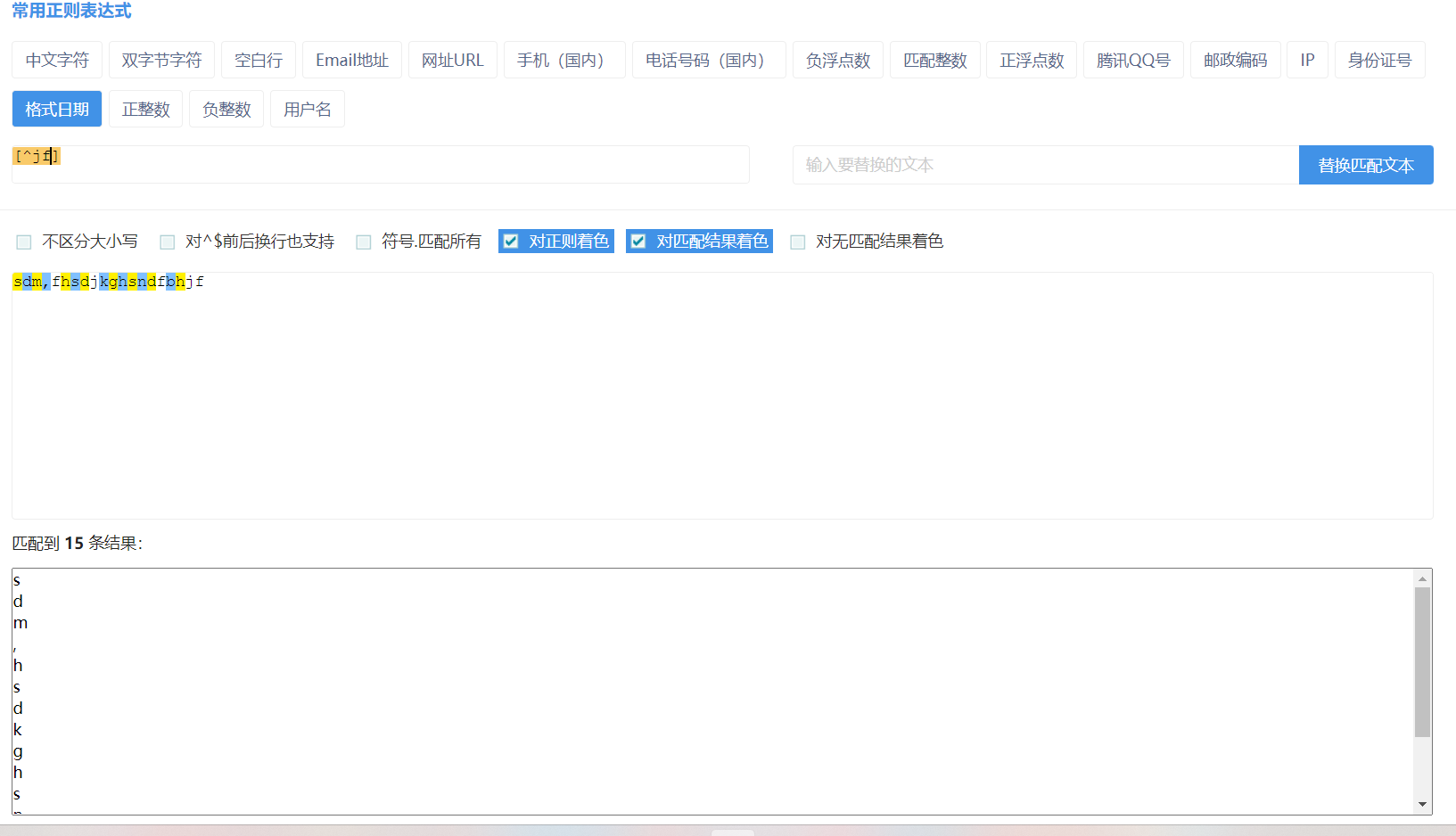
4.量词
'''正则表达式默认情况下都是贪婪匹配>>>:尽可能多的匹'''
* 匹配零次或多次,默认是多次(有多少要多少)
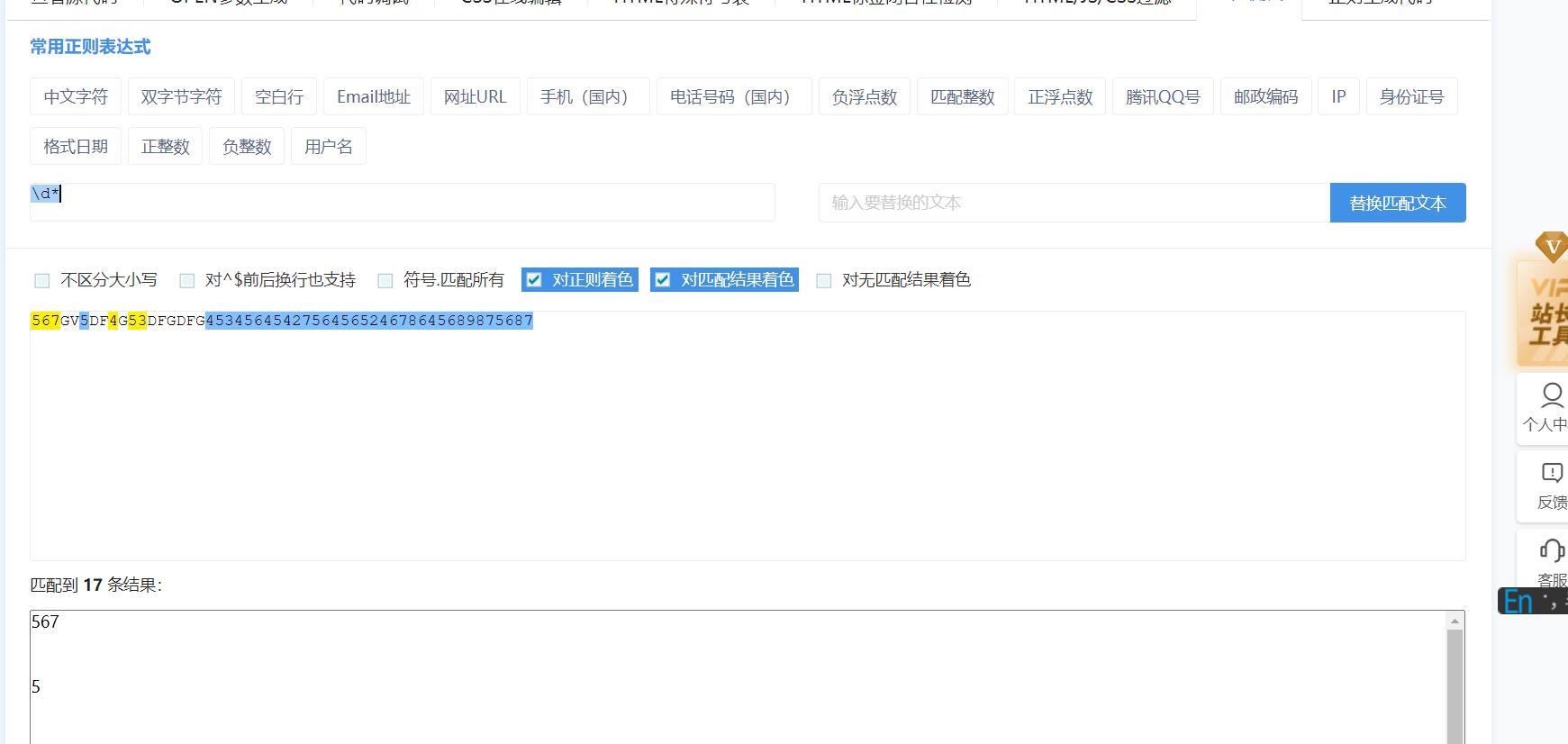
*前的字符不出现、或出现若干次,都可匹配得到。*、+、?中*兼容性最强
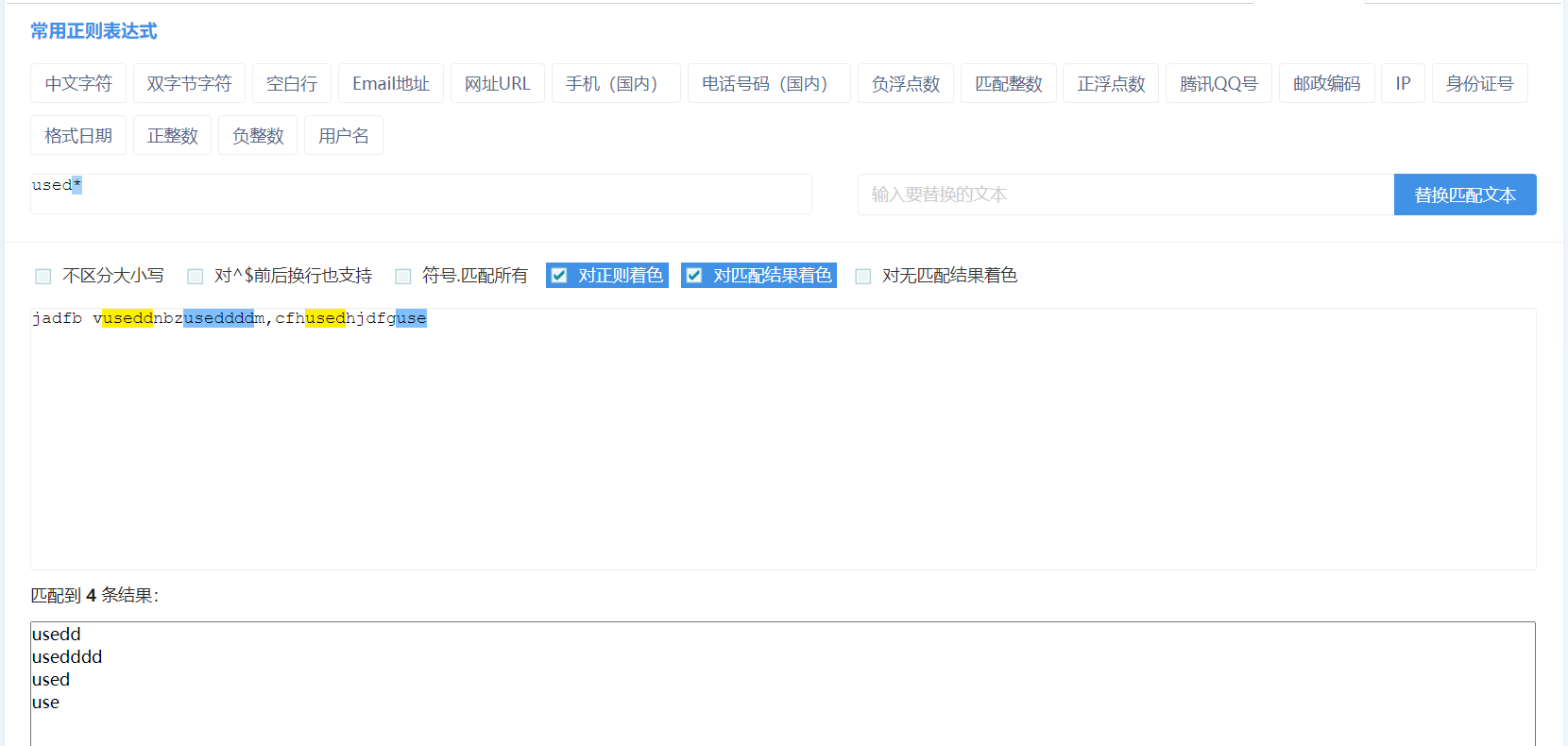
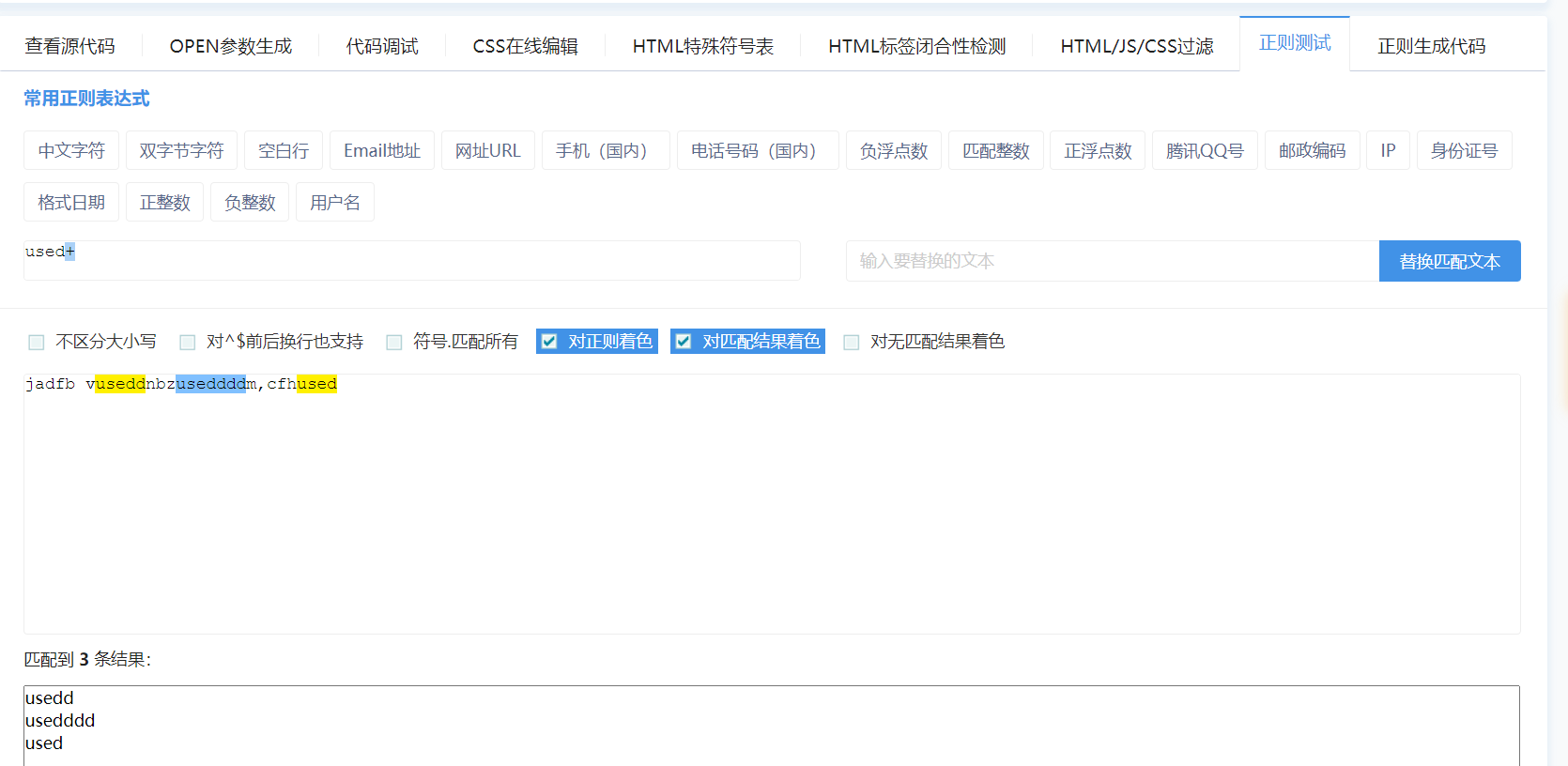
+ 匹配一次或多次,默认是多次(无穷次)
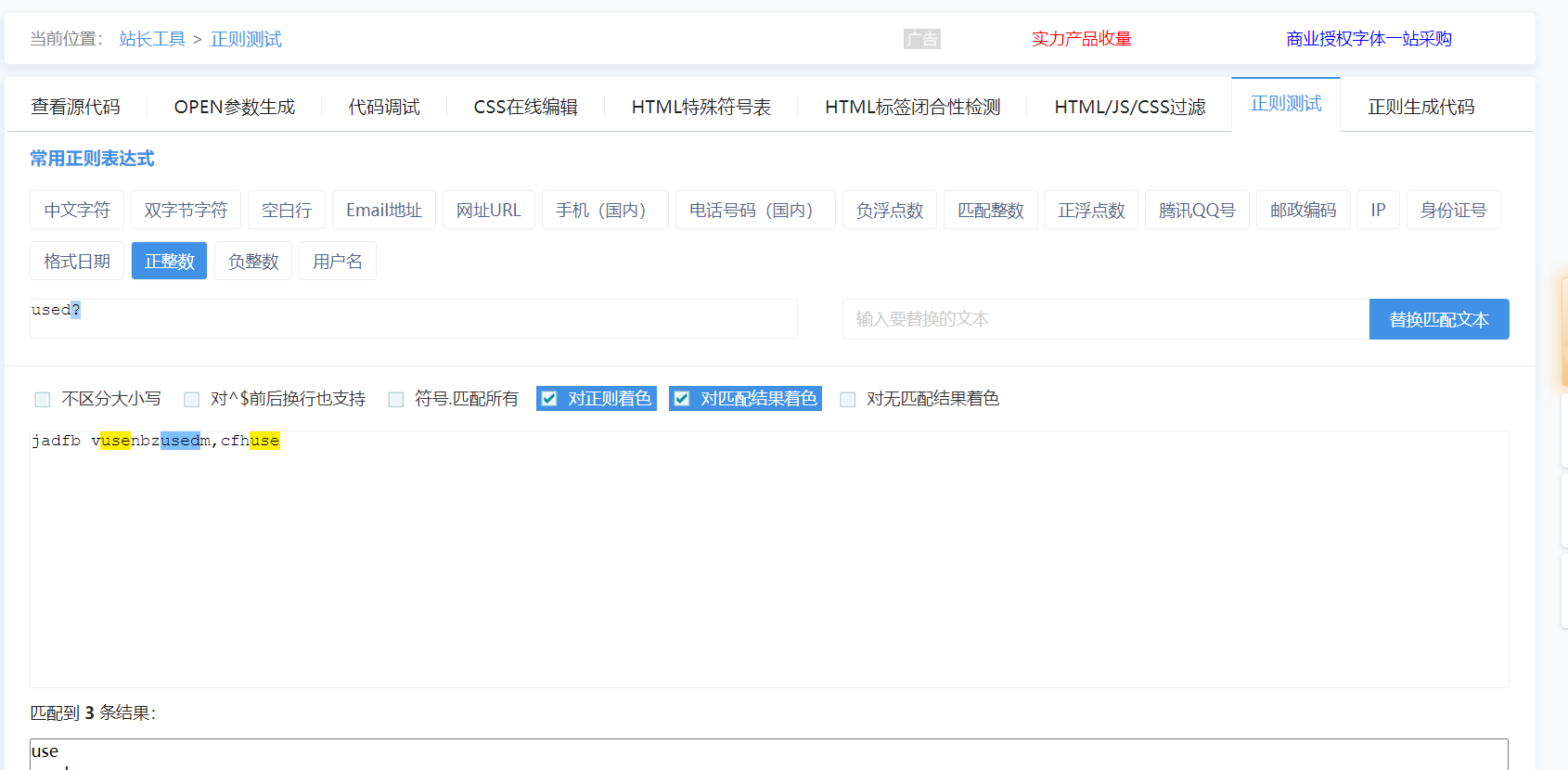
? 匹配零次或一次,和不加效果一样,作为量词意义不大主要用于非贪婪匹配
字符后面加+表示+前的字符字符出现一次、出现多次都可以匹配的的到
字符后面加了?相当于?前的字符可有可无
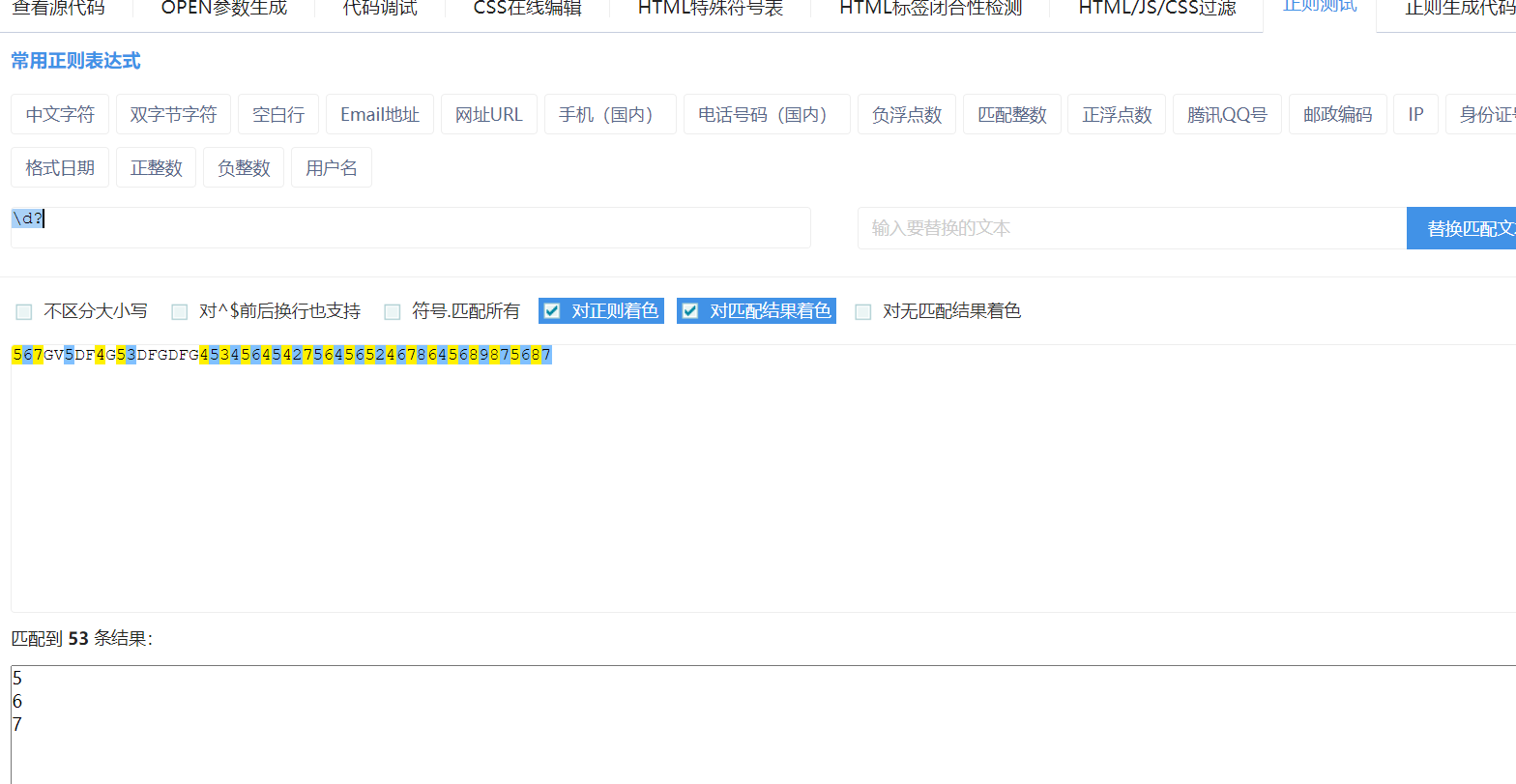
{n} 一次拿n个限定字符,不够n个不拿
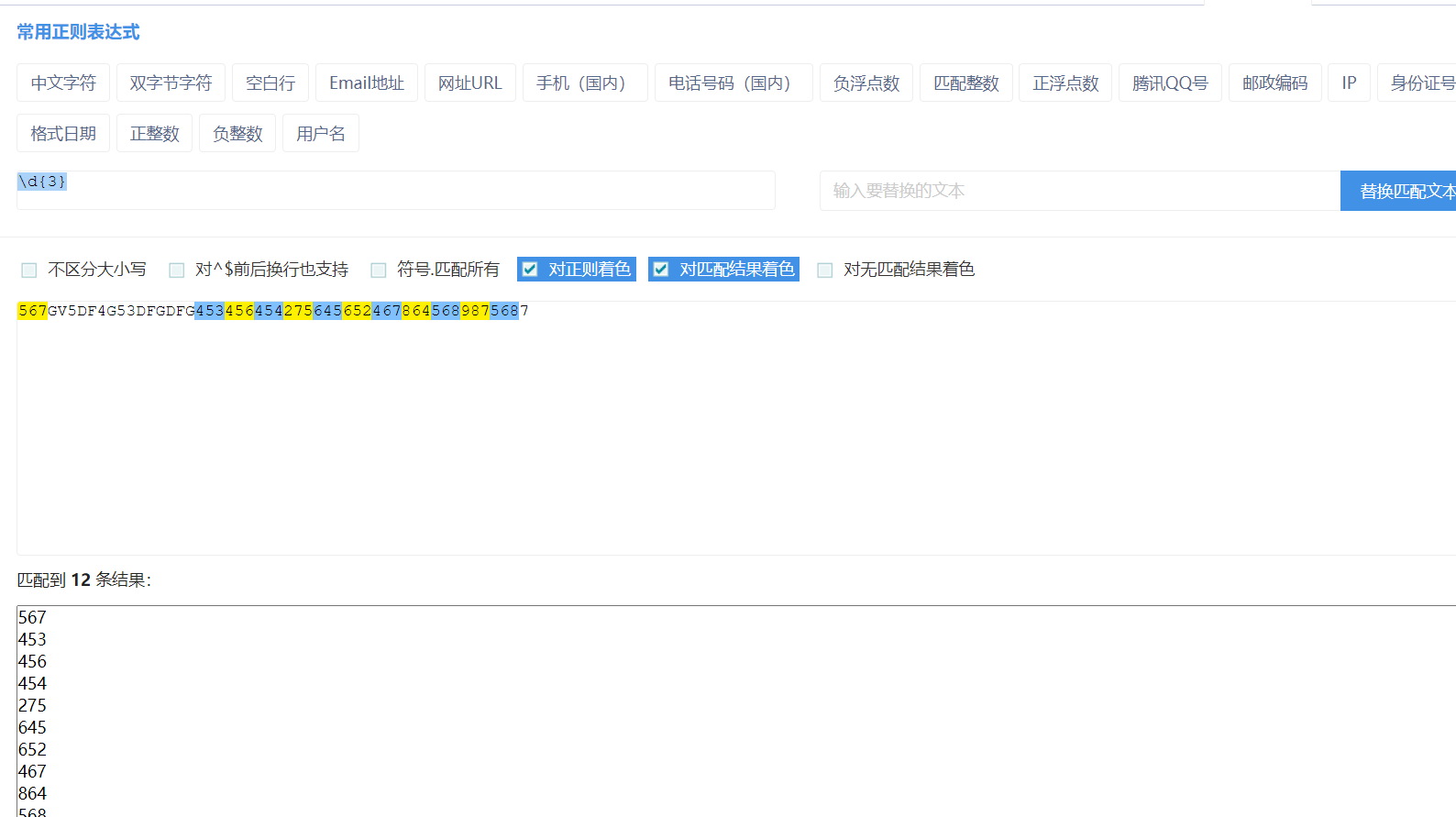
{n,} 一次拿n到无穷多个数字,默认是多次(无穷次)
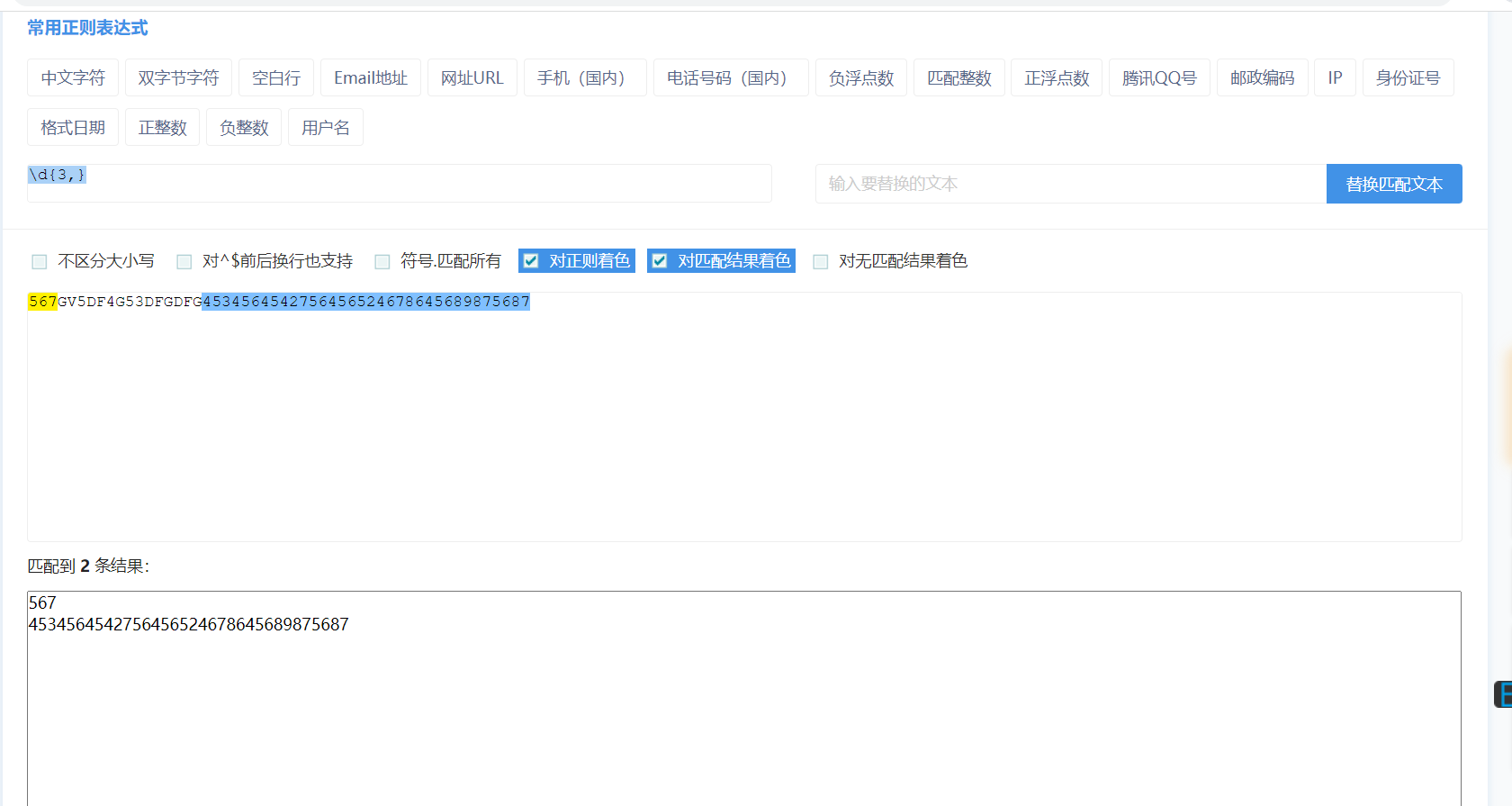
{n,m} 一次拿n到m和数字,在这个区间有多少拿多少,不够n个不拿,默认是m次
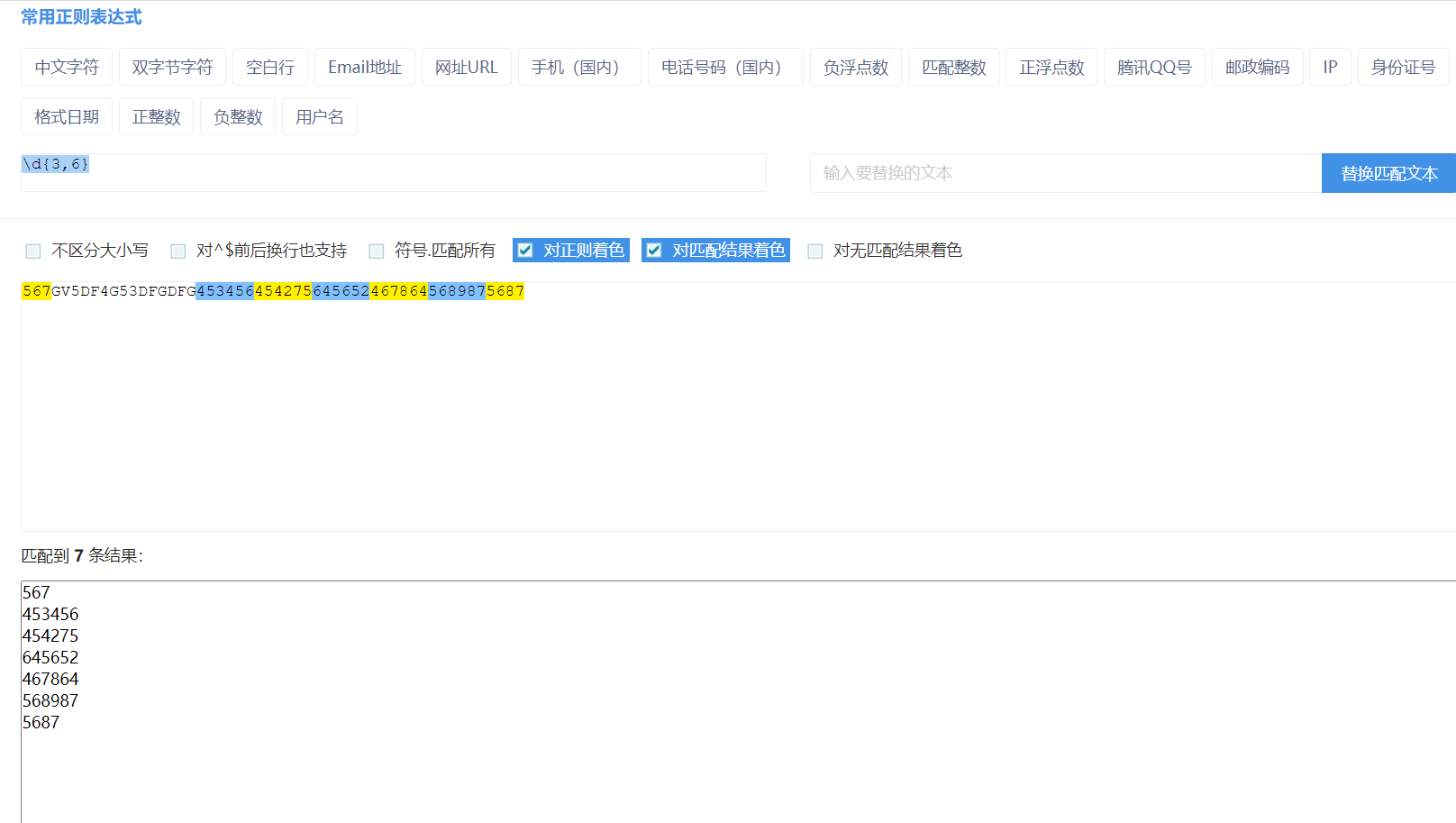
ps:量词必须结合表达式一起使用 不能单独出现 并且只影响左边第一个表达式
jason\d{3} 只影响\d
5.贪婪匹配和非贪婪匹配
"""所有的量词都是贪婪匹配如果想要变为非贪婪匹配只需要在量词后面加问号"""
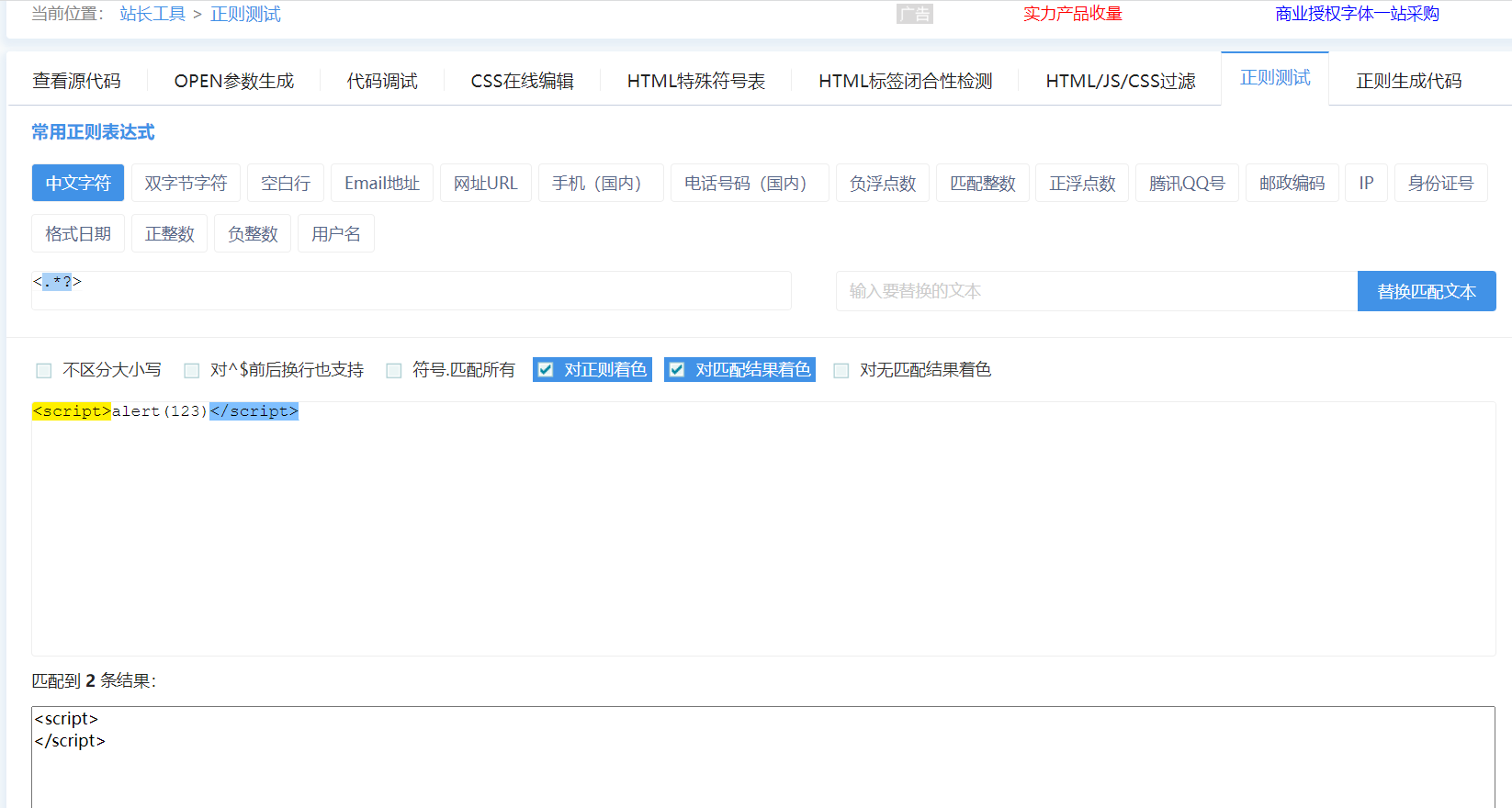
待匹配的文本
<script>alert(123)</script>
待使用的正则(贪婪匹配)
<.*>
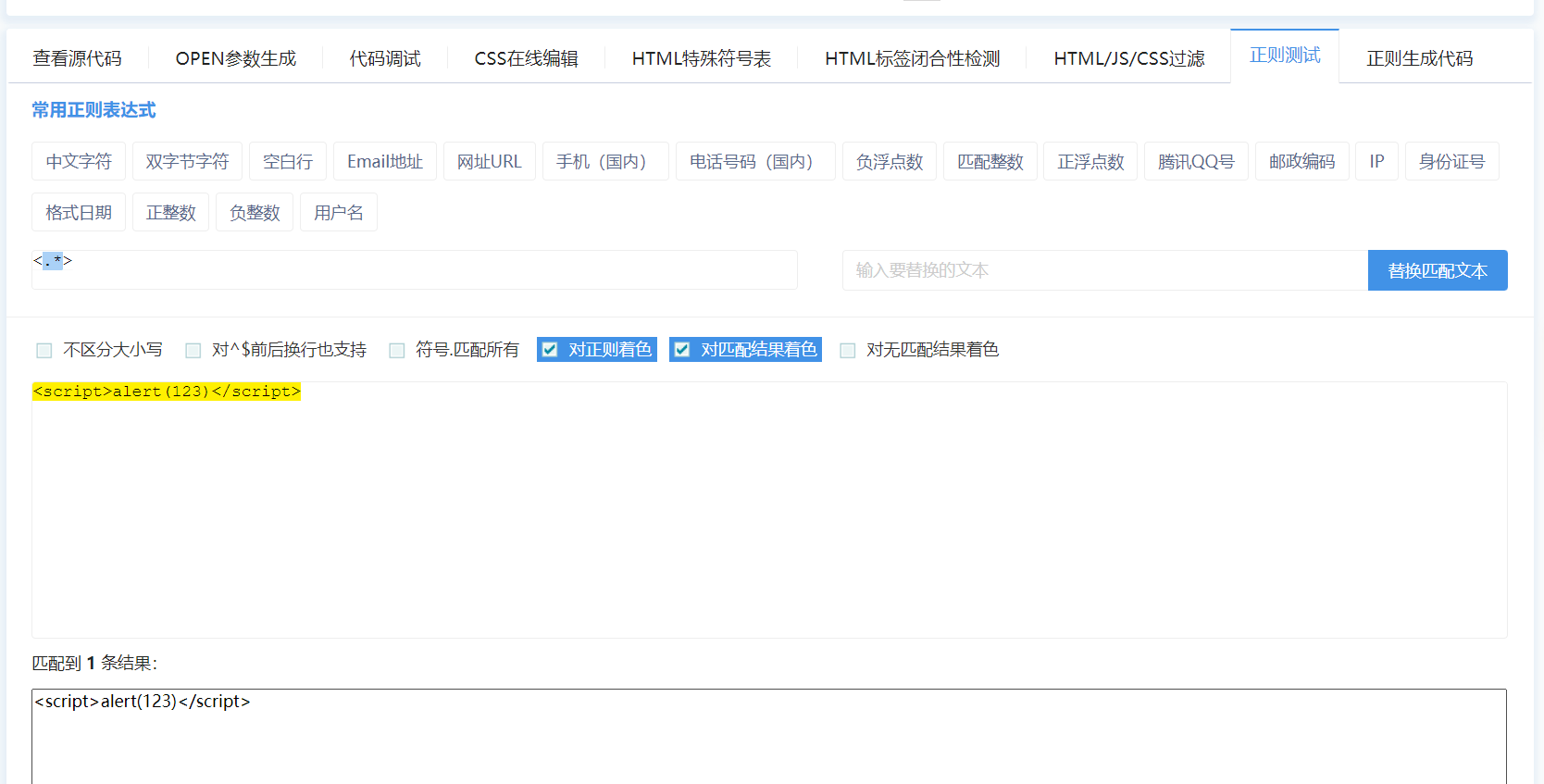
请问匹配的内容
<script>alert(123)</script> 一条
# .*属于典型的贪婪匹配 使用它 结束条件一般在左右明确指定
待使用的正则(非贪婪匹配)
<.*?>
6.转义符
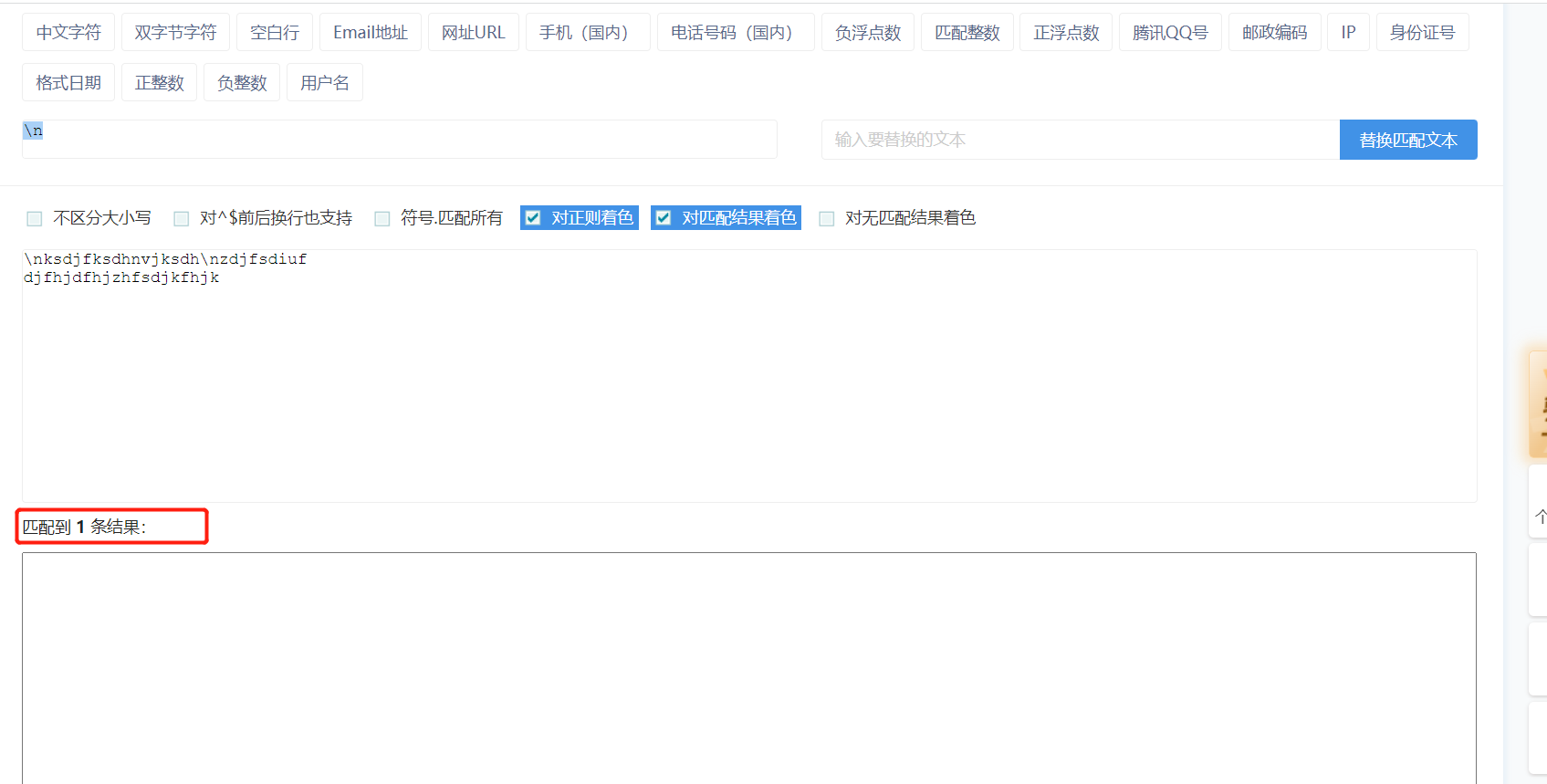
"""斜杠与字母的组合有时候有特殊含义"""
\n 匹配的是换行符:在文本中不会显示匹配结果,但是会显示匹配到×条结果
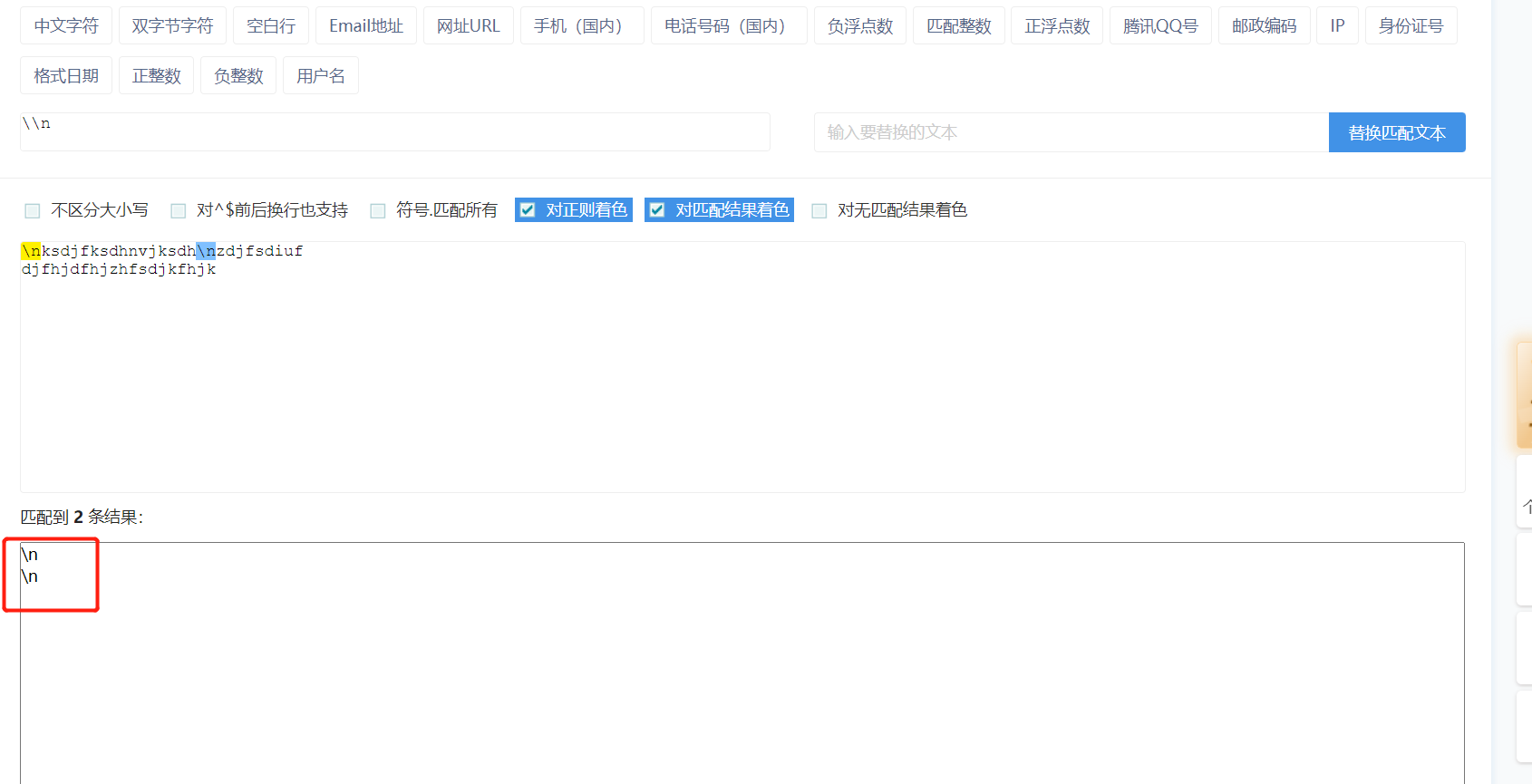
\\n 匹配的是文本\n
\\\\n 匹配的是文本\\n
ps:如果是在python中使用 还可以在字符串前面加r取消转义
7.正则表达式实战建议
1.编写校验用户身份证号的正则
^[1-9]\d{13,16}[0-9x]$
^[1-9]\d{14}(\d{2}[0-9x])?$
^([1-9]\d{16}[0-9x]|[1-9]\d{14})$
2.编写校验邮箱的正则
3.编写校验用户手机号的正则(座机、移动)
4.编写校验用户qq号的正则
"""
日常用到的大多数正则可以百度
"""
8.re模块
1.查找所有符合正则表达式要求的数据,结果是一个列表
import re
res = re.findall('m', 'milk mushroom man')
print(res) # ['m', 'm', 'm']
2.查找所有符合正则表达式要求的数据,结果直接是一个迭代器对象
res = re.finditer('m', 'milk mushroom man')
for i in res:
print(i)
"""
<re.Match object; span=(0, 1), match='m'>
<re.Match object; span=(5, 6), match='m'>
<re.Match object; span=(12, 13), match='m'>
<re.Match object; span=(14, 15), match='m'>
"""
3.查找所有符合正则表达式要求的数据,匹配到一个符合条件的就结束
res = re.search('m', 'milk mushroom man')
print(res) # <re.Match object; span=(0, 1), match='m'>
print(res.group()) # m
4.匹配字符串的开头 如果不符合后面不用看了
res = re.match('m', 'milk mushroom man')
print(res) # <re.Match object; span=(0, 1), match='m'>
print(res.group()) # m
res = re.match('m', 'jason apple eva')
print(res.group()) # None
4.当某一个正则表达式需要频繁使用的时候 我们可以做成模板
obj = re.compile('.{4}')
res = obj.findall('sdhjg4hhgdhf23dhhe5g')
print(res) # ['sdhj', 'g4hh', 'gdhf', '23dh', 'he5g']
obj = re.compile('\d{2}')
res = obj.findall('2764rtyf67245rrtf')
print(res) # ['27', '64', '67', '24']
res = re.split('[df]', 'dhsfg')
print(res) # ['', 'hs', 'g'] 先按d分割得到''和'hsfg',再用f分割得到'hs'和'g'
res = re.split('[sh]', 'fsgkfkjh')
print(res) # ['f', 'gkfkj', '']
ret = re.sub('\d', 'T', 'sjkdfh3ghjgc33hg2', 2)
print(ret) # sjkdfhTghjgcT3hg2 从左往右将数字替换成T并且只替换2个
ret = re.subn('\d', 'S', 'hgvsdjkh2jrhfgj35h63qwegh2')
print(ret) # ('hgvsdjkhSjrhfgjSShSSqweghS', 6) 从左往右将数字替换成S,比并且统计替换个数
9.re模块补充说明
1.分组优先
res = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com')
print(res) # ['oldboy']
findall分组优先展示:优先展示括号内正则表达式匹配到的内容
res = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com')
print(res) # ['www.oldboy.com']
res = re.search('www.(baidu|oldboy).com', 'www.oldboy.com')
print(res.group()) # www.oldboy.com
res = re.match('www.(baidu|oldboy).com', 'www.oldboy.com')
print(res.group()) # www.oldboy.com
2.分组别名:可以在分组当中加上<>,中建放上分组的别名,前面加?P,之后可以通过res.group('别名')的方式来找到匹配的内容;也可以通过索引值来找到匹配的内容,索引[0]是全部匹配的内容,索引[1]是第一个分组内匹配的内容,索引[2]是第二个分组内匹配的内容
res = re.search('www.(?P<content>baidu|oldboy)(?P<hei>.com)', 'www.oldboy.com')
print(res.group()) # www.oldboy.com
print(res.group('content')) # oldboy
print(res.group(0)) # www.oldboy.com
print(res.group(1)) # oldboy
print(res.group(2)) # .com
print(res.group('hei')) # .com
10.作业
要求:爬取网站http://www.redbull.com.cn/about/branch所有分公司信息
import re
# 1.读取网页源码,拷贝到redbull.html
with open(r'redbull.html', 'r', encoding='utf8') as f:
data = f.read()
# 2.利用re模块将需要的信息转成列表
com_name = re.findall("<h2>(.*?)</h2><p class='mapIco'>", data)
com_addr = re.findall("<p class='mapIco'>(.*?)</p><p class='mailIco'>", data)
com_mail = re.findall("</p><p class='mailIco'>(.*?)</p><p class='telIco'>", data)
com_phonenum = re.findall("</p><p class='telIco'>(.*?)</p></li><li", data)
# 3.利用内置函数将几个列表组合在一起,列表中每一个元组就是一个分公司信息
res = zip(com_name, com_addr, com_mail, com_phonenum)
# 4.写入文件
with open(r'company_info', 'w', encoding='utf8') as f1:
for data in res:
print("""
公司地址:%s
公司地址:%s
公司邮编:%s
公司电话:%s
""" % data)
f1.write("""
公司地址:%s
公司地址:%s
公司邮编:%s
公司电话:%s
""" % data)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号