同一个字符的两种 UTF-8 编码
我们在使用 Node.js 时遇到一个奇怪的现象:
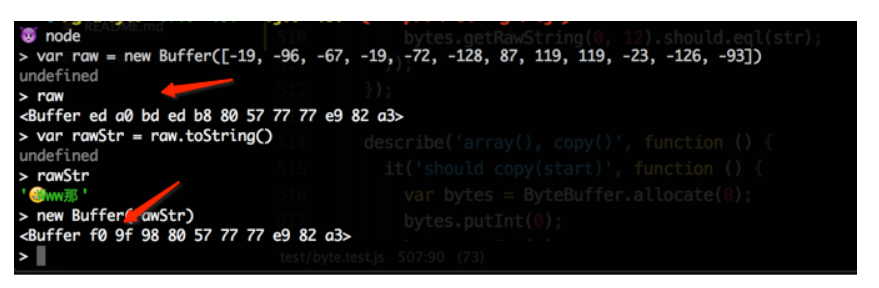
同一个字符串,为什么有两种 UTF-8 编码?第二种编码如果跟第一种编码等价且短,那么这是一种什么变换?Node.js 的什么地方做了这个变换?
注意到,"www"这几个 ASCII 范围内的英文字符,以及最后的汉字的编码是没有发生改变的。所以问题出现在第一个字符这个表情符号上。这个表情符号的两种编码分别为 eda0bdedb880 和 f09f9880,我们把这两种编码展开,它们分别是:
编码 A:
ed a0 bd ed b8 80
11101101 10100000 10111101 11101101 10111000 10000000
编码 B:
f0 9f 98 80
11110000 10011111 10011000 10000000
为了分析这个编码的意思,我们翻出 UTF-8 的解码表:
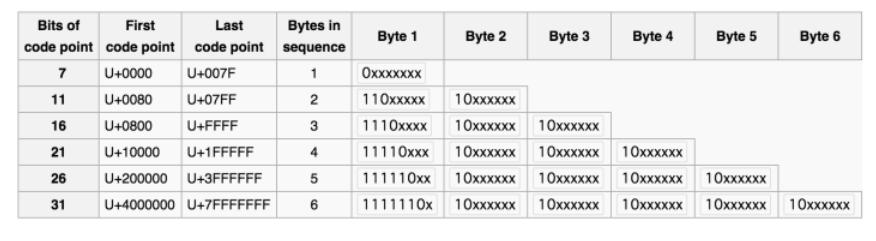
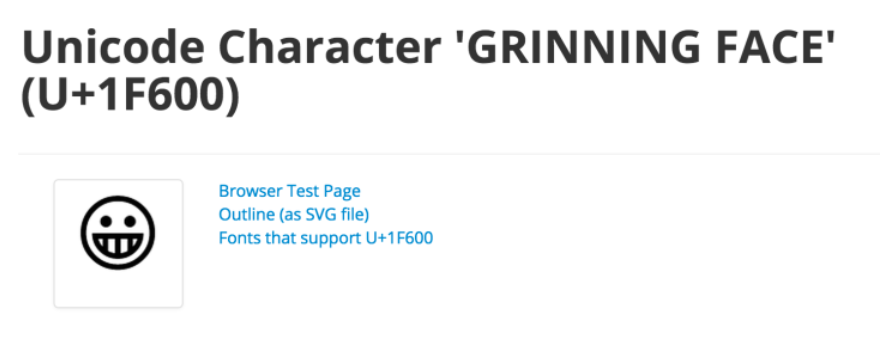
编码 B 完全符合上表的第四行,所以它是一个用4个字节编码的字符,算出上来就是 U+1F600。这是个什么字符?Google之后发现他是一个很正常的 Unicode 字符:
编码 A 的第1~3个字节符合上表的第三行,所以前三个字节表示一个字符;第4~6个字节起也符合上表的第三行,所以后三个字节又表示另外一个字符。计算出来这两个字符就是,U+D83D 和 U+DE00。这两个分别是什么字符呢?Google之:

这就不是一般的字符了,他们是什么?关键词出现了!注意到上图的 High / Low Surrogates Unicode Subset,这是什么?
原来,在某些语言里面,例如 Javascript,在一个内部字符是用16位的内存空间存储的,所以对于unicode而言,一个内部字符最多只能存储编码为 U+0000 到 U+FFFF 范围内的字符,例如“©”(U+00A9);对于编码为 U+FFFF 以上的字符,例如本例中的表情符号U+1F600,一个内部字符就存不开了,只能用两个字符。
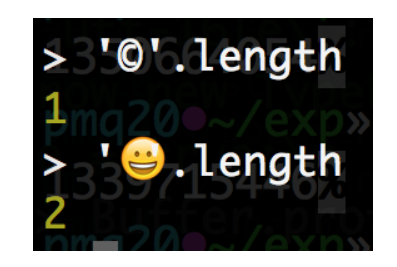
这就要求我们必须设计一个函数,能够把两个16位的小编码合并成一个大编码,也能把一个大编码拆分成两个16位的小编码。事实上,Unicode 3.0的设计者已经做过这样的设计了:
一个大于 0xFFFF 的编码 C,通过下面的公式计算出它对应的小编码对 H, L:
H = Math.floor((C - 0x10000) / 0x400) + 0xD800
L = (C - 0x10000) % 0x400 + 0xDC00
一个小编码对 H, L 通过下面的公式反映射为大编码 C:
C = (H - 0xD800) * 0x400 + L - 0xDC00 + 0x10000
这个算法的具体描述在 Unicode 3.0 规范的第 3.7 章节:http://unicode.org/versions/Unicode3.0.0/ch03.pdf
那么,Node.js 的什么地方做了这个变换?分析代码发现,变换发生在new Buffer(rawStr)这句话上。Buffer()构造函数本来是可以接收第二个参数的,第二个参数意为用什么编码来解释第一个参数;当第二个参数没传的时候,默认就是用utf-8编码。
在 Node.js 的代码中继续寻找,可以发现 Buffer 构造函数调用了Buffer.prototype.write,之后调http://node_buffer.cc的StringWrite范型,这个范型的UTF-8版本最后调到 v8 源码的Utf8::Encode:
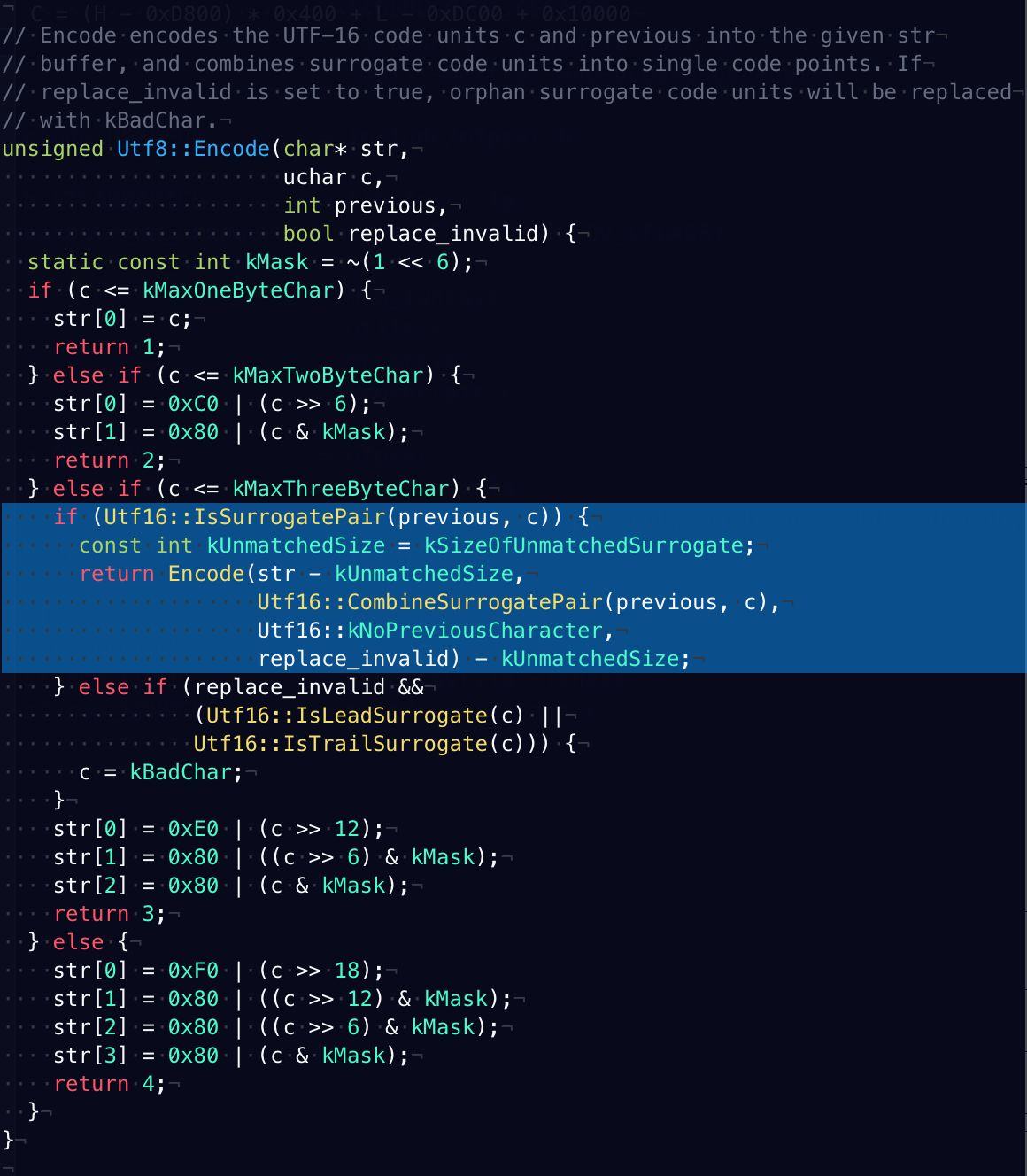
在本案例中,Utf16::IsSurrogatePair 判断到这 6 个字节 eda0bdedb880 可以 3-3 划分成两个 UTF-8 字符,刚好构成一个SurrogatePair,于是执行 Utf16::CombineSurrogatePair 将他们合并成一个字符了,合并之后再递归调用 Utf8::Encode 出来的就是 f09f9880 这4个字节了,所以这个Buffer最后构造出来只有4个字节。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY