JavaScript内存管理
JavaScript并没有提供内存管理的接口,而是在创建变量时自动分配内存,当变量不再需要使用时自动释放,也就是我们所常说的垃圾回收机制。
但不管是什么程序语言,内存的声明周期都满足以下三个阶段:
a.分配你需要的内存空间
b.使用分配到的内存(读、写)
c.不需要时将其释放或归还
大部分语言对于第二步是明确的,但对于JavaScript而言三步都是隐含的,也正是因如此才让JavaScript开发者产生了不用关心内存管理的错觉。
JavaScript内存空间分为栈,堆,池,队列。其中栈存放变量,基本类型数据与指向复杂类型数据的引用指针;堆存放复杂类型数据;池又称为常量池,用于存放常量;而队列在任务队列也会使用。我们一一细说。
1.栈数据结构
栈数据结构具备FILO(first in last out)先进后出的特性,较为经典的就是乒乓球盒结构,先放进去的乒乓球只能最后取出来。我在 一篇文章看懂JS执行上下文 这篇文章中有提到执行上下文栈,它用于存放js代码在执行过程中创建的所有上下文,同样也具备FILO的特性。
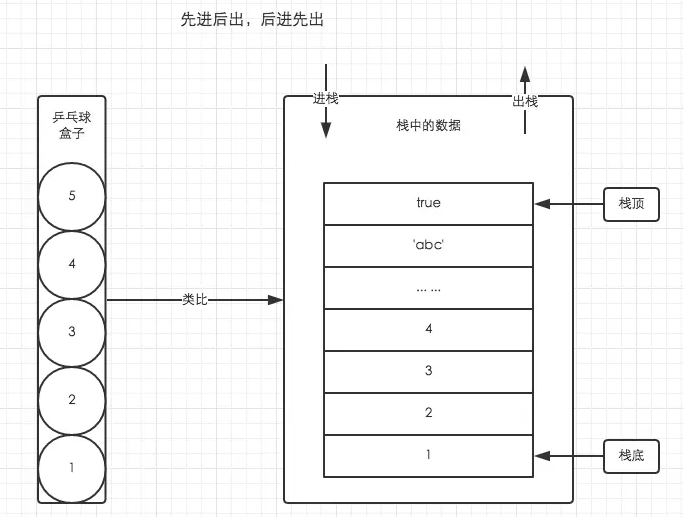
在js中数据类型一般分类基本数据类型(Number Boolean Null Undefined String Symbol)与引用数据类型(Object Array Function ...),其中栈一般用于存放基本类型数据,例如以下代码在栈内存中分布:
var a = 1;
var b = a;
a = 2;
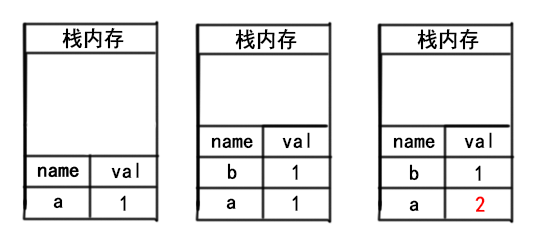
可以看到基本类型数据的变量名与值都存放在栈内存中,当我们将变量a复制给b时,栈会新开内存用于存放变量b,且当我们修改变量a时对变量b不会造成任何影响,因为a与b是互不相关的两份数据。
2.堆数据结构
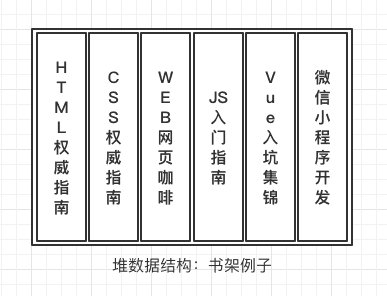
堆数据结构是一种无序的树状结构,同时它还满足key-value键值对的存储方式;我们只用知道key名,就能通过key查找到对应的value。比较经典的就是书架存书的例子,我们知道书名,就可以找到对应的书籍。
在js中堆内存一般用于存储引用类型的数据,需要注意的是由于引用类型的数据一般可以拓展,数据大小可变,所以存放在堆内存中;但对引用类型数据的引用地址是固定的,所以地址指向还是会存放在栈内存中。
我们通过内存图来模拟以下代码:
var a = [1,2,3];
var b = a;
a.push(4);
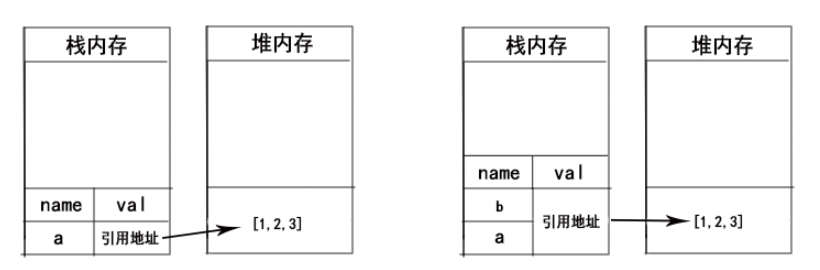
当我们创建数组a时,栈内存中只保存了变量a与指向堆内存中数组的地址指针,而当我们将a复制给变量b时,其实只是复制了一份地址指针,两者还是指向同一数组,无论谁修改,都会影响彼此。
这便是我们熟知的浅拷贝,若想对浅拷贝与深拷贝有更深了解,欢迎阅读博主 深拷贝与浅拷贝的区别,实现深拷贝的几种方法这篇文章。
这里也就解释了:为什么把数组a直接付给数组b,当我们改变b时,a也改变,因为他们存在堆里,地址存在栈里,赋值赋的是栈
3.队列
队列具有FIFO(First In First Out)先进先出的特性,与栈内存不同的是,栈内存只存在一个出口用于数据进栈出栈;而队列有一个入口与一个出口,理解队列一个较为实际的例子就像我们排队取餐,先排队的永远能先取到餐。
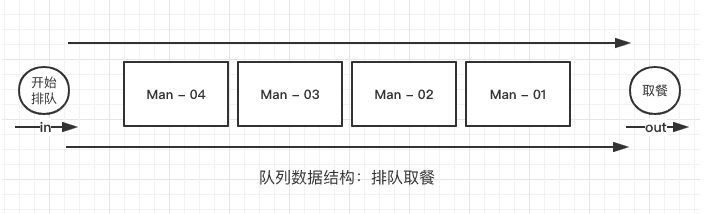
在js中使用队列较为突出的就是js执行机制中的event loop事件循环,如果大家对于js事件执行机制有兴趣,可以阅读博主 JS执行机制详解,定时器时间间隔的真正含义 这篇文章,一定会让你有所收获。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号