
(1)RGB-D SLAM系列- 工具篇(硬件+关键技术)

/***********************************************************************************************************
.....从前,一种叫WALL-E的小机器人被送往地球清除垃圾,但WALL-E并不适合地球的环境,大批量地来也大批量地坏,最后只剩下WALL Tang还在日复一日的按照程序收拾废品。就这么过了几百年,仅存的WALL Tang还在垃圾堆里淘到不少人造宝贝,它也开始有了自我意识,懂得什么是孤独。有一天一艘飞船突然降落,一个女机器人Candy来到地球执行搜寻任务,捡垃圾的机器人“爱”上了Candy,自此他决定跟随Candy远离地球。然而,以前WALL Tang的两只眼睛是两个固定的RGB相机,通过视觉算法(SFM)自动计算垃圾和自己的距离。这几年来,因为老化问题,它有一只眼睛已经看不见东西了,庆幸的是,它从垃圾堆里面捡到一种叫做深度相机的东西,它可以通过机构光,TOF或者激光扫描的方式直接计算自己和前面东西的位置。 就这样为了更好的适应这对新的眼睛实现私奔计划,WALL TANG潜心研究,志在用一只RGB眼睛和一只深度(depth)眼睛来进行高精度定位,搞清楚自己到底在哪,自己旁边都有神马,自己怎么走出去。
多年以后,当WALL TANG站在多普拉多星球俯视地球上堆积如山的垃圾堆的时候,才知道这种定位技术叫做机器人定位与制图(SLAM)技术,自此,WALL TANG走上了教书育人的道路,势必要把这项技术发扬传承。那么接下来就让WALL TANG 讲讲RGB-D SLAM 涉及到的硬件和关键吧。
*********************************************************************************************************/
1) 硬件部分
目前用在SLAM上的Sensor主要分两大类,激光雷达(单线阵,多线阵), RGB相机(单目,双目,多目)(这一部分就不详细介绍了),另一类为近年来新兴的RGB-D传感器(如微软的Kinect,Primer Sense的Structure Sensor),通过价格低廉,实时,以及可接受的量测精度打入室内建模市场, 其深度相机主要是以结构光原理进行成像,通常具有激光投射器、光学衍射元件(DOE)、红外摄像头三大核心器件。它可以同时产生RGB图像和深度图像,如下图所示,工作机制和视频流类似,以每秒30帧的速度收集数据。下图中是Primer sense 的strucutre sensor相机,它的doe是由两部分组成的,一个是扩散片,一个是衍射片。先通过扩散成一个区域的随机散斑,然后复制成九份,投射到了被摄物体上。根据红外摄像头捕捉到的红外散斑,PS1080这个芯片就可以快速解算出各个点的深度信息。
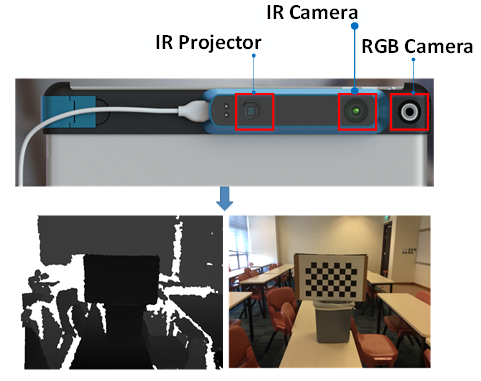
有了深度图和RGB图像之后呢,,SLAM算法就需要工作了,由于RGB-D传感器实际上将结合了三维结构和二维图像结合在一起,所以与传统的只通过激光点云或者只通过RGB图像序列进行SLAM有所不同,但其思路以及涉及到的关键技术都大同小异。

1) 关键技术部分
(1)深度数据模型
RGB-D的一大优势在于每一帧获取的RGB图像和深度图像能够逐像素匹配在一起,针对深度图像上的每一个像素,都可以获取到它对应的深度值,然而,RGB-D相机的量测范围有限,其数据量测精度和量测距离有关,一般只有3-4米以下的深度数据可用于室内建模。下图为量测距离与量测精度图表。

通过图像的像素坐标可通过以下公式来获取对应的三维坐标:
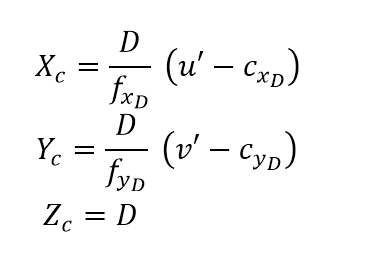
其中,Xc,Yc,Zc是获取的地面坐标,u’和v’是像素坐标,D是从深度图像中获取的深度值(一般都有一个scale,D=D'/Scale),fxD和fyD是图像的焦距
(2)特征点探测
特征点探测和匹配有多种方法,最常用的属SIFT算子,1999年提出,2004年完善,David G.Lowe提出
a.SIFT:1999年提出,2004年完善,David G.Lowe提出
b.FAST(Features from Accelerated Tegment Test):2006年,Edward Rosten ,Tom
优缺点:计算速度快,只计算了灰度信息
c.SURF(Speed UpRobust Feature):2006年,Bay等提出的
优缺点:由sift改进而来,比sift快,多幅图片时鲁棒性好。
d.CenSurE(Center SurroundExtremas for Realtime Feature Detection and Matching)
比较:文章提出了新的方法,并与已有特征点检测进行比较,比较时用到的算子:Harris,FAST,SIFT,SURF.方法:1. 计算当特征点是800时,对于不同的序列,特征点的可重复性。2. 计算最小的欧式距离值,对比距离区间点的个数,画折线图。3. 计算不同搜索范围下,当特征点个数是800时,每种特征点检测的可以匹配成功的百分比。4.使用the visual odometry(VO)评估每种算法的表现。5.比较了每种算法所用的时间。
e. BRISK(Binary Robust invariant scalable keypoints) :2011年,Leutenegger,S等提出
优缺点:是对FAST算法的改进
具体的算法实现大家可以去官网直接下载对应的库文件,笔者使用的是最常规的SIFT算法,由于RGB-D图像数量较多,最好使用SIFT-GPU,可通过GPU对特征提取进行加速。
(3)回环检测 (大回环,随机回环,局部回环)+ appearance-based navigation(新技术)
回环检测的作用主要是去除Drift Error, 就好比一个人蒙着眼睛,如果让你一直走直线,实际情况是,随着你走的距离越长,产生的偏差越大,可能完全变成一条曲线,这时候就需要去有人提醒你你要往右边多走一点还是往左边都走一点。
1)大回环:也叫全局回环检测,进行大回环检测需要知道我们什么时候回到起点,一般在进行三维测图时我们规定一个起始位置,最后结束测图的时候会重新回来,一般这个时候,就用起始数据帧与终止数据帧进行回环检测,得到对应的约束,如全局回环图所示,为三维测图时获取的首尾图像,在回环框架图中,‘e14,1’,‘e14,2’就是全局回环检测得到的边界约束。

全局回环
2)随机回环:随机回环即是在当前关键帧时,与前面所有的关键帧进行随机匹配,可以随机选择5个或者10个关键帧进行匹配,得到对应的边界约束,下面回环检测框架图中短虚线表示的就是随机回环检测到的边界约束,e4,8
3)局部回环:局部回环是最常用的回环检测方法,实际上是在当前数据帧位置下,做一个缓冲区,如下图局部回环检测,得到相邻的关键帧索引,然后将当前数据帧与缓冲区内所有的关键帧一一进行匹配,得到对应的边界约束,回环检测框架图中adjacent edge即是局部回环检测得到的边界约束。
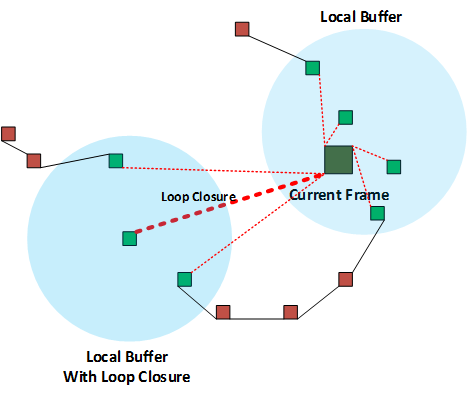
局部回环检测

回环检测框架
以上三种回环检测可以应对大部分场景,但有些情况下我们并不知道什么时候会重新回到相同的位置,随机回环和全局回环需要在一定的知识引导的情况下才能得到对应的边界约束,随意常规来说局部回环是不管在任何场景中都可以用来有效减少drift error。 近些年出现了一种appearance-based navigation(新技术)的新技术,输入所有的图像之后,可以得到图像之间相似性关系,进而可以很容易判断出是否回到同一个位置。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号