Quartz简介
任务调度概述
以论坛为例,每天凌晨统计用户的积分排名,每隔30分钟对锁定到期的用户进行解锁。对别的应用来说,每月一日凌晨统计数据生成月报表,每隔半小时查询用户是否有快到期的待处理业务。
以上所举调度场景的核心都是以时间为关注点的调度,即在特定的时间点执行指定的操作。任务调度本身设计多线程并发、运行时间规则指定与解析、运行现场保持与恢复、线程池维护等诸多方面的工作。如果直接使用自定义线程的方法处理,开发会很具有挑战性。Quartz提供的功能让开发者可以应对绝大多数任务调度的功能需求。
Quartz基础结构
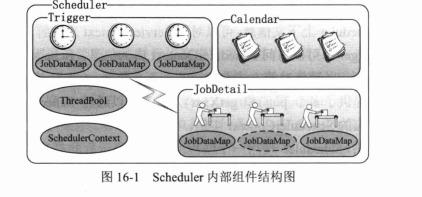
Quartz对任务调度的领域问题进行了高度抽象,提出了调度器、任务和触发器这3个核心的概念。
- Job:是一个接口,只有一个方法void execute(JobExecutionContext context),开发者通过实现该接口来定义需要执行的任务,JobExecutionContext 类提供了调度上下文的各种信息,Job运行时的信息保存在JobDataMap实例中。
- JobDetail:Quartz在每次执行Job时都重新创建一个Job实例,所以它不是直接接受一个Job实例,而是接受一个Job实现类,以便运行时通过newInstance()的反射调用机制实例化Job。JobDetail承担的角色就是描述Job的实现类及其他相关的静态信息,如Job名称、描述、关联监听器等信息。
- Trigger:是一个类,描述Job执行的时间出发规则。主要有SimpleTrigger和CronTrigger这两个子类。当仅需要触发一次或者以固定间隔周期性执行时,SimpleTrigger是最合适的选择;而CronTrigger则可以通过Cron表达式定义出各种复杂的调度方案,如每天早上9:00执行,每周一、周三、周五下午5:00执行等。
- Calendar:与java.util.Calendar不同,它是一些日历特定时间点的集合。一个Trigger可以和多个Calendar关联,以便排除或包含某些时间点。假设安排每周一早上10:00执行任务,但如果遇到节假日则不执行,这是就需要在Trigger触发机制的基础上使用Calendar进行定点排除。
- Scheduler:代表一个Quartz的独立运行容器,Trigger和JobDetail可以注册到Scheduler中,两者在Scheduler中拥有各自的组和名称。组和名称是Scheduler查找定位容器中某一对象的依据。Scheduler定义了多个接口方法,允许外部通过组及名称访问和控制容器中的Trigger和JobDetail。Scheduler可以将Triggle绑定到某一JobDetail中,这样,当Trigger被触发时,对应的Job就被执行。一个Job可以对应多个Triggle,但一个Trigger只能对应一个Job。可以通过SchedulerFactory创建一个Scheduler实例。Scheduler拥有一个SchedulerContext,保存着Scheduler上下文信息。Job和Trigger都可以访问SchedulerContext内的信息。SchedulerContext内部通过一个Map,以键值对的方式维护这些上下文数据。
- ThreadPool:Scheduler使用一个线程池作为任务运行的基础设施,任务通过共享线程池中的线程来提高运行效率。
Job有一个StatefulJob子接口,代表有状态的任务,该接口是一个没有方法的标签接口。无状态任务在执行时拥有自己的JobDataMap实例,对JobDataMap的更改不会影响下次执行。而有状态的任务共享同一个JobDataMap实例,每次任务执行时对JobDataMap所做的更改都会保存,后面的执行会受到影响。
因此无状态的Job可以并发执行,而有状态的StatefulJob不能并发执行。除非必要,避免使用有状态的Job。
如果Quartz使用了数据库持久化任务调度信息,则无状态的JobDataMap仅会在Scheduler注册任务时保存一次,而有状态任务对应的JobDataMap在每次执行任务后都会进行保存。
SchedulerContext提供Scheduler全局可见的上下文信息,每个任务对应一个JobDataMap,虚线的JobDataMap表示有状态的任务。
一个Scheduler可以拥有多个Trigger和多个JobDetail,它们可以分到不同的组中。在注册Trigger和JobDetail时,如果不指定所属组,那么将放入默认组。
任务调度信息存储
默认情况下,Quartz将任务调度的运行信息保存在内存中。这种方法提供了最佳的性能,因为在内存中数据访问速度最快;不足之处是缺乏数据的持久性,当程序中途停止时,所有运行的信息都会丢失。例如安排一个执行100次的任务,运行到50次时系统崩溃,当重启时,任务执行计数器将从0开始计数。
如果需要持久化任务调度信息,可以调整属性文件,将信息保存到数据库中。使用数据库保存信息的任务称为持久化任务。
实际应用中的任务调度
实际应用中,有运行规则固定的静态任务(如每隔30min更新缓存),有时则需要更具业务数据动态产生任务。例如在论坛系统中,当发现某些用户发表非法内容时,需要将该用户锁定一段时间。这个功能就需要通过操作业务功能动态地创建任务来完成:锁定用户后,经过一段时间,通过任务自动将其解锁。随着业务系统的运行,任务源源不断地产生,又源源不断地执行。
任务产生
在实际应用中,有两种不用的创建动态任务的方式。
(1)业务流程产生型
(2)扫描线程产生型
前者表示在运行一个业务时,在业务操作过程中产生任务;而后者由一个任务线程定时扫描业务数据库的任务表,并根据业务数据产生任务。
在业务流程中产生
某个业务需要用到任务,如果任务的执行点离业务的操作时间点不是太长,则可以在业务流程中安排好任务。假设在电力传输管理系统中有一个功能,可以将一条传输线路在某段时间内停止供电。在用户执行线路停电安排时,可立即向Scheduler中注册两个任务:一个是在某一时间点执行断电的任务;另一个是在某一时间点执行恢复供电的任务。
如果要考虑到系统重启的情况,就需要使用持久化任务。
由扫描任务周期产生
有些情况下不适合在业务流程中产生任务,而应当通过定期扫描的功能,根据业务数据动态产生任务。
在论坛系统中,为了清除一些无效的注册账号,可以定义这样的规则:如果账号在注册后半年内都没有激活,则删除这些账号。对系统来说,引发这个删除账号的任务的业务是用户注册功能,但不应该在注册账号后就安排一个清除账号的任务。一般像这种定期清除账号的任务对时间的执行点要求不会太高,只要安排一个以天为周期定期执行的任务,将当天满足条件的账号删除即可。
假设有另一种更极端的情况,项目对清除账号的执行时间点有严格要求:清除账号的时间点只能精准发生在一年之后的那个时间点上。这是,定期周期执行的清除任务就不再适用了。因为如果清除任务执行频率过小,就不能满足精确执行点的要求;如果频率过大,则会对业务数据库产生频繁的访问,对数据库的性能产生不良影响。
为了保证严格的执行时间点,并尽量减少对数据库的影响,需要一个用于产生最近执行任务的扫描任务定期查询数据库,并为那些在一小段时间后就要执行的潜在任务进行动态安排。
例如:每隔30分钟执行一次,扫描业务表,查出在后续的扫描周期范围内将要执行的任务,创建并安排这些任务。这样在30分钟内只会访问一次数据库,对数据库影响很小。
如果系统存在许多依赖一个主任务动态创建出来的子任务,那么最好通过一张任务表来维护这些任务,而不要分散在不同的业务表中。假设用户账号清除任务的条件信息在用户表中,锁定用户任务的信息存在锁定用户表中,商品过期任务的信息在商品表中。如果和任务有关的业务表非常多,为了动态创建任务,扫描时会对数据库产生很大影响。如果用一张任务表记录所有潜在任务,并在业务操作过程中动态维护这张任务表,则仅需一个扫描任务查询这张任务表就可以了。使用这种方式也是有代价的,任务有关的业务模块在业务功能之外需要额外地考虑维护任务表中的数据。比如,在用户注册模块,用户注册完成后,就向任务表添加一条清除账号的任务;而在激活模块,则需要将清除该用户账号的任务记录删除。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号