正则化
参考资料:
L1、L2正则化
1. 正则化的概念
正则化 (Regularization) 是机器学习中对原始损失函数引入额外信息,以便防止过拟合和提高模型泛化性能的一类方法的统称。也就是目标函数变成了原始损失函数 + 额外项,常用的额外项一般有两种,英文称作 \(ℓ1-norm\) 和 \(ℓ2-norm\) ,中文称作 L1 正则化和 L2 正则化,或者 L1 范数和 L2 范数(实际是 L2 范数的平方)。
L1 正则化和 L2 正则化可以看做是损失函数的惩罚项。所谓惩罚是指对损失函数中的某些参数做一些限制。对于线性回归模型,使用 L1 正则化的模型叫做 Lasso 回归,使用 L2 正则化的模型叫做 Ridge 回归(岭回归)。
线性回归 L1 正则化损失函数:
线性回归 L2 正则化损失函数:
公式 (1)(2) 中 \(w\) 表示特征的系数( \(x\) 的参数),可以看到正则化项是对系数做了限制。L1 正则化和 L2 正则化的说明如下:
- L1 正则化是指权值向量 \(w\) 中各个元素的绝对值之和,通常表示为 \(\|w\|_1\) 。
- L2 正则化是指权值向量 \(w\) 中各个元素的平方和然后再求平方根(可以看到 Ridge 回归的 L2 正则化项有平方符号),通常表示为 \(\|w\|_2^2\) 。
- 一般都会在正则化项之前添加一个系数 \(\lambda\) 。Python 中用 \(\alpha\) 表示,这个系数需要用户指定(也就是我们要调的超参)。
2. 正则化的作用
L1正则化可以使得参数稀疏化,即得到的参数是一个稀疏矩阵,可以用于特征选择。
- 稀疏性,说白了就是模型的很多参数是0。通常机器学习中特征数量很多,例如文本处理时,如果将一个词组(term)作为一个特征,那么特征数量会达到上万个(bigram)。在预测或分类时,那么多特征显然难以选择,但是如果代入这些特征得到的模型是一个稀疏模型,很多参数是0,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,即使去掉对模型也没有什么影响,此时我们就可以只关注系数是非零值的特征。这相当于对模型进行了一次特征选择,只留下一些比较重要的特征,提高模型的泛化能力,降低过拟合的可能。
L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合。
- L1 正则化与稀疏性
事实上,”带正则项”和 “带约束条件” 是等价的。
为了约束 w 的可能取值空间从而防止过拟合,我们为该最优化问题加上一个约束,就是 w 的 L1 范数不能大于 m:
问题转化成了带约束条件的凸优化问题,写出拉格朗日函数:
设 \(W_*\) 和 \(\lambda_*\) 是原问题的最优解,则根据 \(KKT\) 条件得:
仔细看上面第一个式子,与公式 (1) 其实是等价的,等价于 (3) 式。
设 L1 正则化损失函数: \(J = J_0 + \lambda \sum_{w} |w|\) ,其中 \(J_0 = \sum_{i=1}^{N}(w^Tx_i - y_i)^2\) 是原始损失函数,加号后面的一项是 \(L1\) 正则化项, \(\lambda\) 是正则化系数。
注意到 L1 正则化是权值的绝对值之和, \(J\) 是带有绝对值符号的函数,因此 \(J\) 是不完全可微的。机器学习的任务就是要通过一些方法(比如梯度下降)求出损失函数的最小值。当我们在原始损失函数 \(J_0\) 后添加 L1 正则化项时,相当于对 \(J_0\) 做了一个约束。令 \(L=\lambda \sum_w|w|\) ,则 \(J=J_0+L\) ,此时我们的任务变成在 \(L\) 约束下求出 \(J_0\) 取最小值的解。
考虑二维的情况,即只有两个权值 \(w_1\) 和 \(w_2\) ,此时 \(L=|w_1|+|w_2|\) 对于梯度下降法,求解 \(J_0\) 的过程可以画出等值线,同时 L1 正则化的函数 \(L\) 也可以在 \(w_1\) 、 \(w_2\) 的二维平面上画出来。如下图:
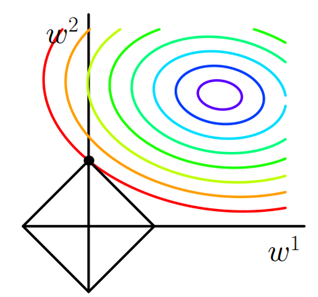
上图中等值线是 \(J_0\) 的等值线,黑色方形是 \(L\) 函数的图形。在图中,当 \(J_0\) 等值线与 \(L\) 图形首次相交的地方就是最优解。上图中 \(J_0\) 与 \(L\) 在 \(L\) 的一个顶点处相交,这个顶点就是最优解。注意到这个顶点的值是 \((w_1,w_2)=(0,w_2)\) 。可以直观想象,因为 \(L\) 函数有很多突出的角(二维情况下四个,多维情况下更多),\(J_0\) 与这些角接触的机率会远大于与 \(L\) 其它部位接触的机率,而在这些角上,会有很多权值等于 \(0\) ,这就是为什么 L1 正则化可以产生稀疏模型,进而可以用于特征选择。
而正则化前面的系数 \(\lambda\) ,可以控制 \(L\) 图形的大小。 \(\lambda\) 越小, \(L\) 的图形越大(上图中的黑色方框); \(\lambda\) 越大, \(L\) 的图形就越小,可以小到黑色方框只超出原点范围一点点,这是最优点的值 \((w_1,w_2)=(0,w_2)\) 中的 \(w_2\) 可以取到很小的值。
同理,又 L2 正则化损失函数: \(J = J_0 + \lambda \sum_w w^2\) , 同样可画出其在二维平面的图像,如下:
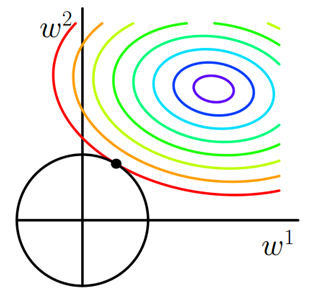
二维平面下 L2 正则化的函数图形是个圆,与方形相比,被磨去了棱角。因此 \(J_0\) 与 \(L\) 相交时使得 \(w_1\) 或 \(w_2\) 等于零的机率小了许多,这就是为什么 L2 正则化不具有稀疏性的原因。
4. L2 正则化为什么能防止过拟合
角度1:解空间形状
拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什么影响,专业一点的说法是抗扰动能力强。
为什么 L2 正则化可以获得值很小的参数?
(1) 以线性回归中的梯度下降法为例。假设要求的参数为 \(\theta\) , \(h \theta (x)\) 是我们的假设函数,那么线性回归的代价函数如下:
(2) 在梯度下降中 \(\theta\) 的迭代公式为:
(3) 其中 \(\alpha\) 是 learning rate。 上式是没有添加 L2 正则化项的迭代公式,如果在原始代价函数之后添加 L2 正则化,则迭代公式为:
其中 \(\lambda\) 就是正则化参数。从上式可以看到,与未添加 L2 正则化的迭代公式相比,每一次迭代, \(\theta_j\) 都要先乘以一个小于 1 的因子,从而使得 \(\theta_j\) 不断减小,因此总得来看, \(\theta\) 是不断减小的。
最开始也提到 L1 正则化一定程度上也可以防止过拟合。之前做了解释,当 L1 的正则化系数很小时,得到的最优解会很小,可以达到和 L2 正则化类似的效果。
角度2:函数叠加
第二个角度试图用更直观的图示来解释L1产生稀疏性这一现象。仅考虑一维的情况, 多维情况是类似的, 如图7.7所示。假设棕线是原始目标函数 \(L(w)\) 的曲线图, 显然最小值点在蓝点处, 且对应的 \(w^*\) 值非 0 。
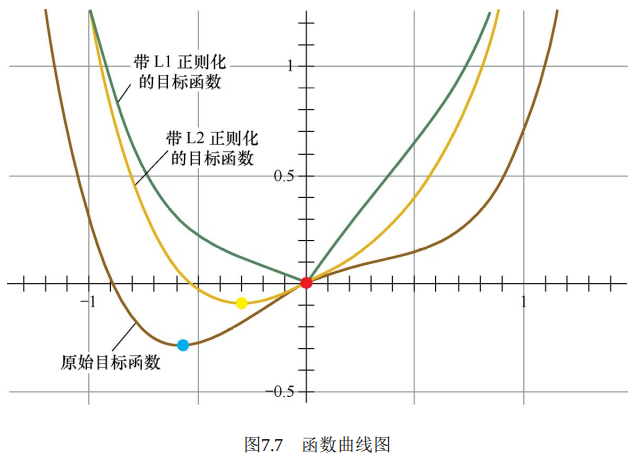
首先, 考虑加上 \(\mathrm{L} 2\) 正则化项, 目标函数变成 \(L(w)+C w^2\), 其函数曲线为黄色。此时, 最小值点在黄点处, 对应的 \(w^*\) 的绝对值减小了, 但仍然非 0 。
然后, 考虑加上 \(L 1\) 正则化项, 目标函数变成 \(L(w)+C|w|\), 其函数曲线为绿色。此时, 最小值点在红点处, 对应的 \(w\) 是 0 , 产生了稀疏性。
产生上述现象的原因也很直观。加入L1正则项后, 对带正则项的目标函数求导, 正则项部分产生的导数在原点左边部分是 \(-C\), 在原点右边部分是 \(C\), 因此,只要原目标函数的导数绝对值小于 \(C\), 那么带正则项的目标函数在原点左边部分始终是递减的, 在原点右边部分始终是递增的, 最小值点自然在原点处。相反, L2 正则项在原点处的导数是 0 , 只要原目标函数在原点处的导数不为 0 , 那么最小值点就不会在原点, 所以L2 只有减小 \(w\) 绝对值的作用, 对解空间的稀疏性没有贡献。
在一些在线梯度下降算法中, 往往会采用截断梯度法来产生稀疏性, 这同L1 正则项产生稀疏性的原理是类似的。
角度3:贝叶斯先验
从贝叶斯的角度来理解L1正则化和 L2正则化, 简单的解释是, L1正则化相当于对模型参数 \(w\) 引了拉普拉斯先验, L2正则化相当于引入了高斯先验, 而拉普拉斯先验使参数为 0 的可能性更大。
图7.8是高斯分布曲线图。由图可见,高斯分布在极值点 (0点) 处是平滑的,也就是高斯先验分布认为 \(w\) 在极值点附近取不同值的可能性是接近的。这就是L2正则化只会让 \(w\) 更接近 0 点, 但不会等于 0 的原因。
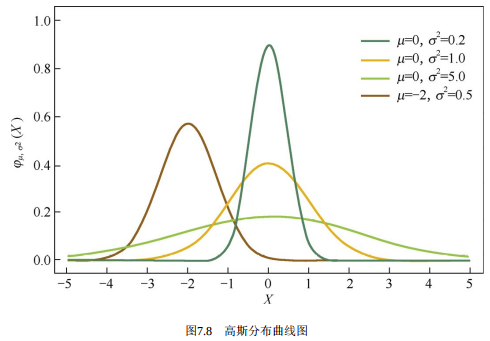
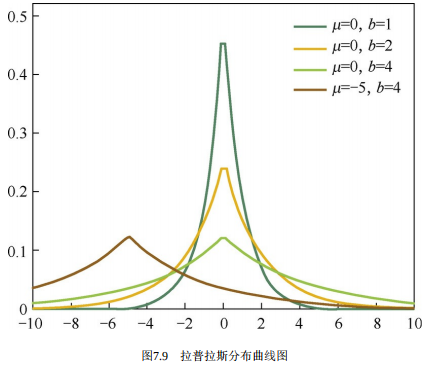
相反, 图7.9是拉普拉斯分布曲线图。由图可见, 拉普拉斯分布在极值点 \((0\)点) 处是一个尖峰, 所以拉普拉斯先验分布中参数 \(w\) 取值为 0 的可能性要更高。在此我们不再给出L1和L2正则化分别对应拉普拉斯先验分布和高斯先验分布的详细证明。
- 正则化项的参数选择
L1、L2 的参数 \(\lambda\) 如何选择好?
以 L2 正则化参数为例:从公式 (8) 可以看到,λ越大, \(\theta_j\) 衰减得越快。另一个理解可以参考 L2 求解图, \(\lambda\) 越大,L2 圆的半径越小,最后求得代价函数最值时各参数也会变得很小;当然也不是越大越好,太大容易引起欠拟合。
经验
从 0 开始,逐渐增大 \(\lambda\) 。在训练集上学习到参数,然后在测试集上验证误差。反复进行这个过程,直到测试集上的误差最小。一般的说,随着 \(\lambda\) 从 0 开始增大,测试集的误分类率应该是先减小后增大,交叉验证的目的,就是为了找到误分类率最小的那个位置。建议一开始将正则项系数λ设置为 0,先确定一个比较好的 learning rate。然后固定该 learning rate,给 \(\lambda\) 一个值(比如 1.0),然后根据 validation accuracy,将λ增大或者减小 10 倍,增减 10 倍是粗调节,当你确定了 \(\lambda\) 的合适的数量级后,比如 \(\lambda= 0.01\) ,再进一步地细调节,比如调节为 0.02,0.03,0.009 之类。
本文来自博客园,作者:Un-Defined,转载请保留本文署名Un-Defined,并在文章顶部注明原文链接:https://www.cnblogs.com/EIPsilly/p/18381873

 浙公网安备 33010602011771号
浙公网安备 33010602011771号