
[论文阅读] Domain generalization by learning and removing domain-specific features
1 Introduction
最近的研究发现,DNNs倾向于以与人类不同的方式学习决策规则 [17, 21, 16]。例如,在基于ImageNet的图像分类任务中,卷积神经网络(CNNs)倾向于学习局部纹理以区分对象,而我们人类则可能使用全局对象形状的知识作为线索。DNNs学到的特征可能只属于特定的领域,对其他领域不具有泛化性。例如,在现实世界的照片中,属于同一类别的对象具有相似的纹理,但在素描中,对象只由线条绘制,并不包含纹理信息 [27]。对于一个使用纹理来区分照片中对象的CNN,当应用于素描时,可以预期性能不佳。这种情况需要学习跨领域不变特征而不是学习特定领域的特征的DNNs。
一种典型的领域泛化方法是学习跨领域不变的表示[18, 30, 42, 3, 11, 14, 45, 31, 35]。这种方法基于这样的假设:每个领域都有其特定于该领域的特征,而所有领域共享领域不变的特征。这些方法并没有明确地告知深度神经网络应该有效地去除特定于领域的特征。相反,只希望通过实现学习域不变特征的最终目标来消除它们。我们主动去除特定于领域的特征,引导cnn学习领域不变特征进行分类。
在第一步中,每个领域特定分类器被设计为有效地从一个源域中学习领域特定特征。具体地,一个领域特定分类器被设计为在一个特定的源域内区分不同类别的图像。同时,这个分类器要求在任何其他源域中无法区分不同类别的图像。因此,在这种设计下,每个源域对应一个领域特定分类器。
在第二步中,编码器-解码器网络将输入图像映射到一个新的图像空间,在这个空间中,利用特定于领域的分类器从输入图像中去除上面学习到的特定于领域的特征。与第一步不同的是,这里的每个特定于域的分类器都无法区分对应源域中不同类之间的映射图像。与原始输入图像相比,映射图像预计包含更少的领域特定特征。然后将域不变分类器附加到编码器-解码器网络中,并使用映射的图像进行训练。通过这种设计,编码器-解码器网络可以主动去除特定于领域的特征,并且可以更好地引导域不变分类器学习域不变特征。经过训练后,编码器-解码器网络和领域不变分类器将用于对未见过的目标域进行分类。
值得注意的是,我们的框架与基于数据增强的领域泛化方法[43, 34, 46, 7]不同。我们的框架旨在从输入图像中去除领域特定特征,而基于数据增强的方法则生成具有新领域特定特征的各种图像。此外,我们的框架仅将输入图像映射到一个新的图像空间,并不对其进行增强以扩大训练数据集。
2 Proposed framework
2 提出的框架
假设我们有 \(N\) 个源域 \(\mathcal{D}_s=\left\{D_s^1, D_s^2, \ldots, D_s^N\right\}\),它们遵循不同的分布。对于每个域(数据集),\(D_s^i=\left\{\left(\mathbf{x}_j^i, y_j^i\right)\right\}_{j=1}^{n_i^s}\),其中 \(n_i\) 是 \(D_s^i\) 中样本的数量,\(\left(\mathbf{x}_j^i, y_j^i\right)\) 是第 \(i\) 个域中第 \(j\) 个样本的数据-标签对。根据文献,我们假设所有源域和目标域共享相同的标签空间。领域泛化的目标是利用这些源域 \(\mathcal{D}_s\) 来为未见的目标域 \(D_t\) 学习一个模型。
我们的工作受到最近的研究[32]的启发,该研究使用了一个“lens”网络(即图像到图像的转换网络),在自监督学习任务中从输入图像中移除“shortcut”(CNN可以快速学习的低级视觉特征,如水印和色彩偏差)。与此不同的是,我们的工作着重于从输入图像中移除领域特定特征,用于领域泛化任务。我们使用了一个类似于“lens”网络的编码器-解码器网络,但我们设计了一种不同的方法来利用编码器-解码器网络去除领域特定特征。在本节中,我们详细说明了我们的框架,并为我们的框架提供了理论分析。图1概述了整个框架。
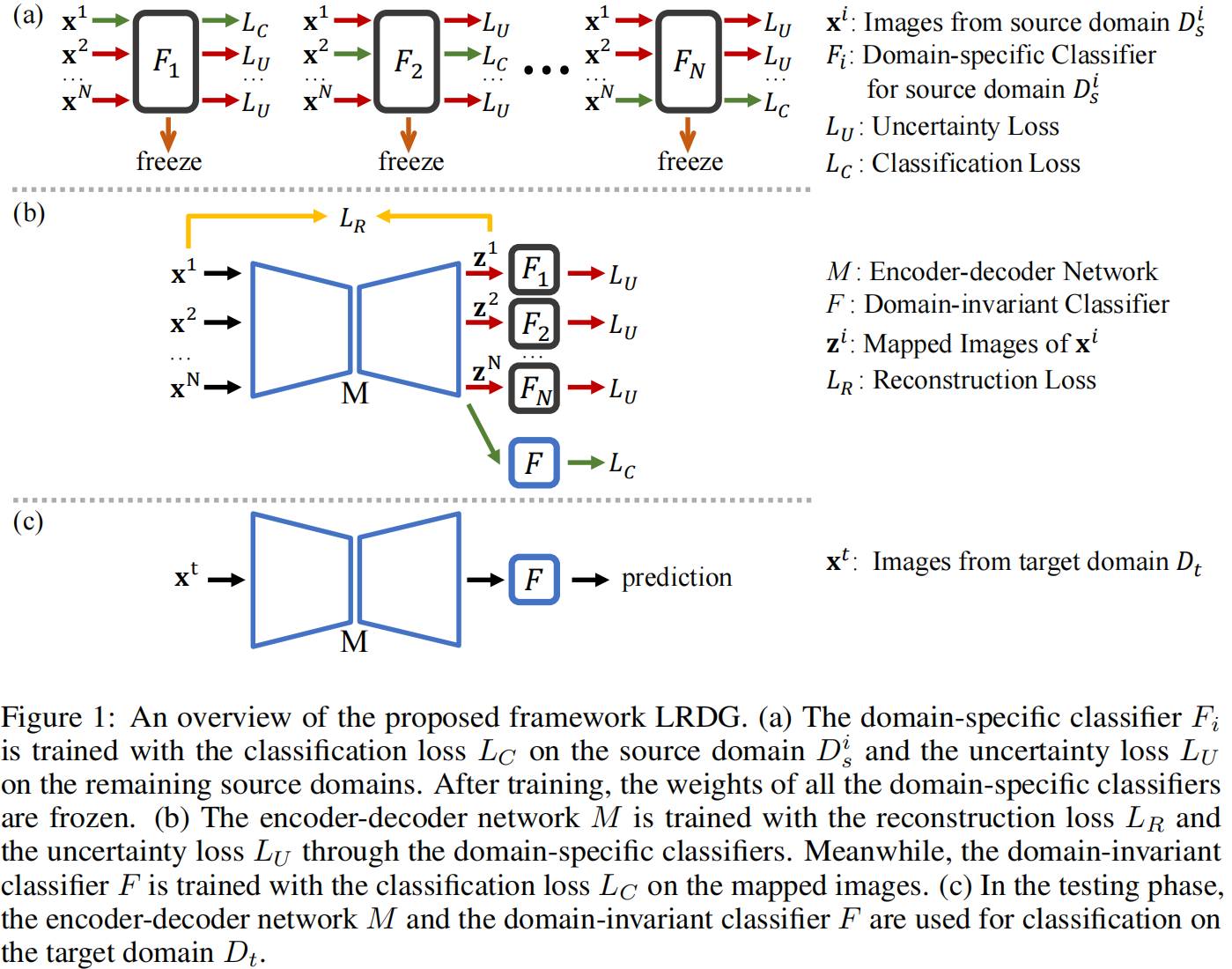
图1:LRDG提出的框架概述。 (a) 使用分类损失\(L_C\)在源域\(D_s^i\)上训练领域特定分类器\(F_i\),并使用剩余源域上的不确定性损失\(L_U\)。训练完成后,所有领域特定分类器的权重被冻结。(b) 使用重建损失\(L_R\)和通过领域特定分类器的不确定性损失\(L_U\)训练编码器-解码器网络\(M\)。同时,使用映射图像上的分类损失\(L_C\)训练领域不变分类器\(F\)。(c) 在测试阶段,编码器-解码器网络\(M\)和领域不变分类器\(F\)被用于目标域\(D_t\)上的分类。
2.1 Learning domain-specific features
我们的框架从训练 \(N\) 个单独的领域特定分类器 \(\mathcal{F}_S=\left\{F_1, F_2, \ldots, F_N\right\}\) 开始,其中分类器 \(F_i\) 被设计为仅使用源域 \(D_s^i\) 中的领域特定特征来区分图像。领域特定分类器 \(\mathcal{F}_S\) 不应使用领域不变特征作为线索。换句话说,\(F_i\) 预计能够有效地在 \(D_s^i\) 内区分不同类别的图像,但是对于任何其他域内的不同类别的图像,\(F_i\) 应该难以区分。除了 \(D_s^i\) 外的域被用来最大化分类的不确定性或者对 \(F_i\) 的分类增加对抗性以增加分类的难度。\(F_i\) 在除 \(D_s^i\) 外的域上的分类性能应该类似于随机猜测。
具体来说,分类器 \(F_i\) 通过最小化分类损失 \(\mathcal{L}_C^{F_S}\) 在 \(D_s^i\) 上进行训练,
并且最大化剩余域 \(\left\{D_s^1, \ldots, D_s^{i-1}, D_s^{i+1}, \ldots, D_s^N\right\}\) 上的不确定性损失 \(\mathcal{L}_U^{F_S}\),
其中 \(\theta_i\) 表示分类器 \(F_i\) 的参数。\(L_C\) 和 \(L_U\) 分别是分类损失函数和不确定性损失函数。我们使用交叉熵损失作为分类损失。对于不确定性损失,由于我们的目标是使预测类似于随机猜测,因此我们使用熵损失。
其中 \(C\) 是类别数量,\(p\left(y=l \mid F_i\left(\mathbf{x}_j^k ; \theta_i\right)\right)\) 表示 \(\mathbf{x}_j^k\) 属于类别 \(l\) 的概率。
最小可能损失[32]是熵损失的一种替代方法。分类器首先预测图像并获取所有类别的概率。概率最低的类别称为最不可能的类别。将该图像标记为该类别。然后我们训练分类器预测最不可能的类别。最小可能损失为
然而,实验表明熵损失可以更好地实现分类的随机性,因此我们将熵损失作为默认的不确定性损失。 训练完成后,我们冻结这些领域特定分类器 \(\mathcal{F}_S\) 的参数 \(\theta\),并使用这些分类器来学习领域不变特征。
2.2 Removing domain-specific features
为了去除领域特定分类器学习到的领域特定特征,我们利用一个编码器-解码器网络 \(M\) 将图像映射到一个新的图像空间 \(\mathcal{Z}\)。输出图像被馈送到领域特定分类器 \(\mathcal{F}_S\) 和一个新的领域不变分类器 \(F\) 中。
与领域特定分类器 \(F_i\) 的训练不同,其中源域 \(D_s^i\) 被用于最小化分类损失相反,在这一步中,源域 \(D_s^i\) 被用于最大化不确定性 \(\operatorname{loss} \mathcal{L}_U^M\),
在特定领域分类器\(F_i\)的训练过程中,源域\(D_s^i\)用于最小化分类损失的不同。但是在当前这一步中,源域 \(D_s^i\) 被用于最大化不确定性 \(\operatorname{loss} \mathcal{L}_U^M\),
领域特定分类器 \(F_i\) 的参数 \(\theta_i\) 被冻结,而编码器-解码器网络 \(M\) 的参数 \(\theta_M\) 被训练。最大化不确定性损失迫使输出图像 \(\mathbf{z}_i=M\left(\mathbf{x}_i\right)\) 包含比输入图像更少的领域特定特征。通过这样做,编码器-解码器网络可以从输入图像 \(\mathbf{x}\) 中去除领域特定特征,并在输出图像 \(\mathbf{z}\) 中保留领域不变特征。
为了保持输入和输出图像的整体相似性,我们为编码器-解码器网络添加了一个重建损失 \(\mathcal{L}_R^M\),
其中 \(L_R\) 是重建损失函数。我们使用像素级 \(l_2\) 损失作为默认的重建损失,因为它简单并且具有相当良好的性能。也可以使用其他重建损失,比如像素级 \(l_1\) 损失和感知损失[24]。详细讨论请参见补充材料。
接着,我们通过在所有源域的输出图像上最小化分类损失 \(\mathcal{L}_C^{F M}\) 来训练领域不变分类器 \(F\)。
其中 \(\theta_F\) 是领域不变分类器 \(F\) 的参数。这个分类损失 \(\mathcal{L}_C^{F M}\) 也更新了编码器-解码器网络,以防止由于不确定性损失而使编码器-解码器网络丢失领域不变特征。如果难以区分领域特定特征和领域不变特征,则不确定性损失也有可能去除领域不变特征。
总体而言,在训练领域特定分类器时,我们优化
而在学习领域不变特征时,我们优化
其中 \(\lambda_1, \lambda_2\) 和 \(\lambda_3\) 是控制这些损失相对权重的超参数。
为了方便起见,我们将编码器-解码器网络 \(M\) 和领域不变分类器 \(F\) 统称为领域不变模型。在测试阶段,领域不变模型被用于目标域 \(D_t\) 上的分类。
2.3 Explanation of LRDG with respect to existing theory
我们首先介绍领域泛化的generalization risk bound [2],然后进一步解释我们的框架相对于这个界的有效性。
理论上,对于一个领域,相应的任务被定义为一个确定性的真实标签函数 \(f\),其中 \(f: \mathcal{X} \rightarrow \mathcal{Y}\)。这里 \(\mathcal{X}\) 和 \(\mathcal{Y}\) 分别是输入空间和标签空间。我们将候选假设的空间表示为 \(\mathcal{H}\),其中一个假设 \(h: \mathcal{X} \rightarrow \mathcal{Y}\)。假设 \(h\) 在领域 \(\mathcal{D}\) 上的风险被定义为
这里 \(\mathcal{L}: \mathcal{Y} \times \mathcal{Y} \rightarrow \mathcal{R}_{+}\) 用来度量假设和真实标签函数之间的差异。
根据 [2],对于源域 \(\left\{\mathcal{D}_s^1, \mathcal{D}_s^2, \ldots, \mathcal{D}_s^N\right\}\),我们将源域的凸包 \(\Lambda_S\) 定义为一组混合源分布:\(\Lambda_S=\left\{\overline{\mathcal{D}}: \overline{\mathcal{D}}(\cdot)=\sum_{i=1}^N \pi_i \mathcal{D}_s^i(\cdot), 0 \leq \pi_i \leq 1, \sum_{i=1}^N \pi_i=1\right\}\)。我们还将 \(\overline{\mathcal{D}}_t \in \Lambda_S\) 定义为最接近目标域 \(\mathcal{D}_t\) 的域。\(\overline{\mathcal{D}}_t\) 给出为 \(\arg \min _{\pi_1, \ldots, \pi_N} d_{\mathcal{H}}\left[\mathcal{D}_t, \sum_{i=1}^N \pi_i \mathcal{D}_s^i\right]\),其中 \(d_{\mathcal{H}}[\cdot, \cdot]\) 是 \(\mathcal{H}\)-散度 [25],用于量化两个域的分布差异。我们针对目标域 \(\mathcal{D}_t\)使用以下generalization risk bound [2]。
Theorem 1 (Generalization risk bound [2])
在前述设置下,对于任何域 \(\mathcal{D}_t\) 和任意假设 \(h \in \mathcal{H}\),风险 \(\mathcal{R}_t[h]\) 满足以下不等式:
其中 \(\gamma=d_{\mathcal{H}}\left[\mathcal{D}_t, \overline{\mathcal{D}}_t\right]\),\(\epsilon=\sup _{i, j \in[N]} d_{\mathcal{H}}\left[\mathcal{D}_s^i, \mathcal{D}_s^j\right]\),\(\lambda_\pi\) 是一些假设 \(h \in \mathcal{H}\) 在 \(\mathcal{D}_t\) 和 \(\overline{\mathcal{D}}_t\) 上达到的风险之和的最小值。\(\gamma\) 衡量了源域和目标域之间的分布差异。\(\epsilon\) 是源域之间的最大两两 \(\mathcal{H}\)-散度。
定理 1 表明目标域的上界取决于 \(\gamma\) 和 \(\epsilon\)。我们展示了我们的框架可以降低给定领域泛化任务的这个generalization risk bound的值。回想一下,我们的编码器-解码器网络将输入图像映射到一个新的图像空间。我们将映射后的源域表示为 \(\left\{\widehat{\mathcal{D}}_s^1, \widehat{\mathcal{D}}_s^2, \ldots, \widehat{\mathcal{D}}_s^N\right\}\),将映射后的目标域表示为 \(\widehat{\mathcal{D}}_t\)。通过使用领域特定分类器,许多源域的领域特定特征被移除,并且映射后的源域的特征倾向于更加领域不变。因此,映射后的源域 \(\left\{\widehat{\mathcal{D}}_s^1, \widehat{\mathcal{D}}_s^2, \ldots, \widehat{\mathcal{D}}_s^N\right\}\) 的分布差异可能会比原始源域小,即 \(d_{\mathcal{H}}\left[\widehat{\mathcal{D}}_s^i, \widehat{\mathcal{D}}_s^j\right] \leq d_{\mathcal{H}}\left[\mathcal{D}_s^i, \mathcal{D}_s^j\right]\),这表明方程式 11 中的 \(\epsilon\) 可能会减小。在为每个源域移除领域特定特征后,映射后的目标域 \(\widehat{\mathcal{D}}_t\) 会更接近于映射后的源域,因此我们的框架也可能会减小方程式 11 中的 \(\gamma\)。关于定理 1,这些变化提供了对所提出的框架有效性的原理性解释和保证。我们将在实验部分(第 3.3 节)展示这些变化。
本文来自博客园,作者:Un-Defined,转载请保留本文署名Un-Defined,并在文章顶部注明原文链接:https://www.cnblogs.com/EIPsilly/p/18113402

 浙公网安备 33010602011771号
浙公网安备 33010602011771号