[论文阅读] Patient subtyping via time-aware LSTM networks
Patient Subtyping via Time-Aware LSTM Networks
3.1.2 Time-Aware LSTM (T-LSTM).
T-LSTM 被提出,以将经过时间的信息纳入标准 LSTM 架构中,从而能够捕捉具有时间不规则性的序列数据的时间动态。所提出的 T-LSTM 架构如图 2 所示,其中输入序列由患者的时间数据表示。患者的两个连续记录之间的经过时间可能非常不规则。例如,两次连续入院/医院就诊之间的时间可能是几周、几个月或几年。如果两个连续记录之间有数年的间隔,那么对于前一次记录的依赖性不足以影响当前输出,因此前一次记忆对当前状态的贡献应该被折扣。T-LSTM 架构的主要组成部分是对前一个时间步长的记忆进行子空间分解。虽然正在调整前一个时间步长的记忆中包含的信息量,但我们不希望失去患者的全局特征。换句话说,长期影响不应该被完全丢弃,但是短期记忆应该与时间步长 \(t\) 和 \(t-1\) 之间的时间跨度成比例地调整。如果时间 \(t\) 和 \(t-1\) 之间的间隔很大,这意味着患者很长一段时间内没有记录新的信息。因此,对于当前输出的预测,对短期记忆的依赖性不应起到重要作用。
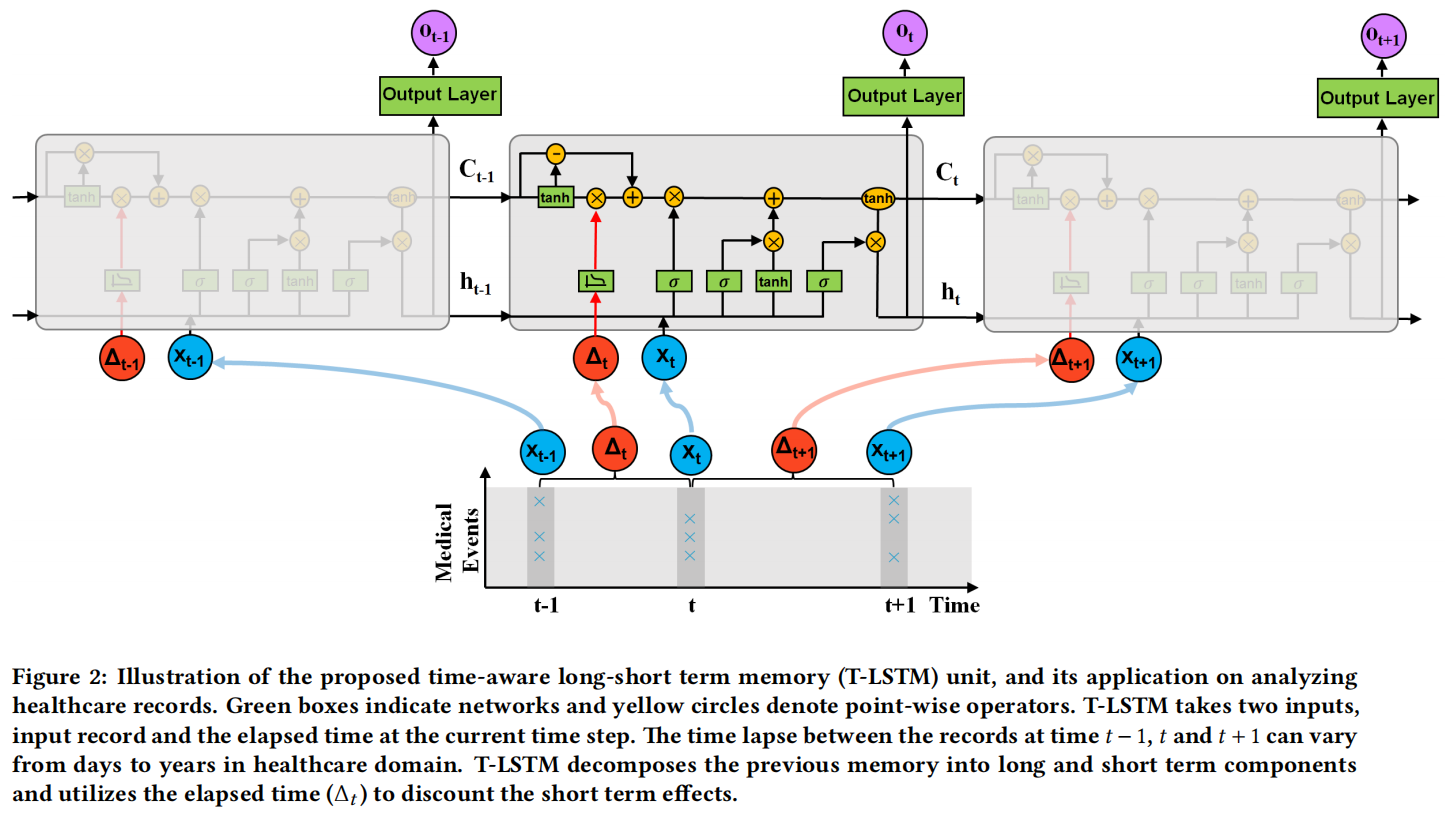
T-LSTM通过利用连续元素之间的经过时间来加权短期记忆内容,从而应用记忆折扣。为了实现这一点,我们建议使用经过时间的非递增函数,将时间间隔转换为适当的权重。子空间分解过程的数学表达式如下所示。首先,通过网络获得短期记忆组件 \(\left(C_{t-1}^S\right)\)。请注意,这种分解是数据驱动的,分解网络的参数与网络的其余部分一起通过反向传播同时学习。对于分解网络的激活函数类型没有特定要求。我们尝试了几种函数,但没有观察到T-LSTM单元预测性能的显著差异,但是tanh激活函数表现略好一些。在获得短期记忆之后,通过经过时间的权重进行调整,得到折扣短期记忆 \(\left(\hat{C}_{t-1}^S\right)\)。最后,为了组成调整后的先前记忆 \(\left(C_{t-1}^*\right)\),将长期记忆的补充子空间 \(\left(C_{t-1}^T=C_{t-1}-C_{t-1}^S\right)\) 与折扣短期记忆相结合。T-LSTM的子空间分解阶段后面是LSTM的标准门控架构。下面给出了提出的T-LSTM架构的详细数学表达式:
其中,\(x_t\) 表示当前输入,\(h_{t-1}\) 和 \(h_t\) 分别表示上一个和当前的隐藏状态,\(C_{t-1}\) 和 \(C_t\) 分别表示上一个和当前的细胞记忆。\(\left\{W_f, U_f, b_f\right\}\)、\(\left\{W_i, U_i, b_i\right\}\)、\(\left\{W_o, U_o, b_o\right\}\) 和 \(\left\{W_c, U_c, b_c\right\}\) 分别是遗忘门、输入门、输出门和候选记忆的网络参数。\(\left\{W_d, b_d\right\}\) 是子空间分解的网络参数。参数的维度由输入、输出和所选的隐藏状态的维度确定。\(\Delta_t\) 是 \(x_{t-1}\) 和 \(x_t\) 之间的经过时间,\(g(\cdot)\) 是一种启发式衰减函数,使得 \(\Delta_t\) 的值越大,短期记忆的影响越小。根据特定应用领域的时间间隔测量类型,可以选择不同类型的单调非递增函数作为 \(g(\cdot)\)。如果我们处理的是时间序列数据,如视频,那么经过时间通常以秒为单位测量。另一方面,如果经过时间从几天到几年不等,如医疗领域,我们需要将连续元素之间的时间间隔转换为一种类型,如天数。在这种情况下,当两个连续记录之间有数年的时间时,经过时间可能具有较大的数值。作为一个指导方针,对于经过时间较少的数据集,可以选择 \(g\left(\Delta_t\right)=1 / \Delta_t\),而对于经过时间较长的数据集,推荐选择 \(g\left(\Delta_t\right)=1 / \log \left(e+\Delta_t\right)\)。
在文献中,可以找到提出不同方法将经过时间纳入学习过程的研究。例如,在文献[24]中,经过时间被用来修改遗忘门。在 T-LSTM 中,调整记忆单元而不是遗忘门的一个原因是为了避免改变当前输入对当前输出的影响。当前输入通过遗忘门并且来自输入的信息起到决定我们应该从上一个单元保留多少记忆的作用。正如在当前隐藏状态的等式中可以看到的,直接修改遗忘门可能会消除输入对当前隐藏状态的影响。另一个重要的点是,子空间分解使我们能够有选择地修改短期影响,而不会丢失长期记忆中的相关信息。第 4 节表明,通过修改遗忘门可以提高 TLSTM 的性能,在本文中称之为修改后的遗忘门 LSTM(MF-LSTM)。本文采用了文献[24]中的两种方法进行比较。第一种方法,标记为 MF1-LSTM,将遗忘门的输出乘以 \(g\left(\Delta_t\right)\),例如 \(f_t=g\left(\Delta_t\right) * f_t\)。而 MF2-LSTM 则利用了一个参数化的时间权重,例如 \(f_t=\sigma\left(W_f x_t+U_f h_{t-1}+Q_f q_{\Delta_t}+b_f\right)\),其中当 \(\Delta_t\) 以天为单位时,\(q_{\Delta_t}=\left(\frac{\Delta_t}{60},\left(\frac{\Delta_t}{180}\right)^2,\left(\frac{\Delta_t}{360}\right)^3\right)\),与文献[24]类似。
另一种处理时间不规则性的方法可能是通过在两个连续时间步之间对数据进行采样,以获得规则的时间间隔,然后在扩充的数据上应用 LSTM。然而,当经过时间以天为单位时,对于中间相隔数年的时间步,需要采样如此之多的新记录。其次,数据插补方法可能会严重影响性能。患者记录包含详细信息,很难保证插补的记录反映了现实情况。因此,建议改变常规 LSTM 的架构以处理时间不规则性。
3.2 Patient Subtyping with T-LSTM Auto-Encoder
In this paper, patient subtyping is posed as an unsupervised clustering problem since we do not have any prior information about the groups inside the patient cohort. An efficient representation summarizing the structure of the temporal records of patients is required to be able to cluster temporal and complex EHR data. Autoencoders provide an unsupervised way to directly learn a mapping from the original data [2]. LSTM auto-encoders have been used to encode sequences such as sentences [32] in the literature. Therefore, we propose to use T-LSTM auto-encoder to learn an effective single representation of the sequential records of a patient. T-LSTM auto-encoder has T-LSTM encoder and T-LSTM decoder units with different parameters which are jointly learned to minimize the reconstruction error. The proposed auto-encoder can capture the long and the short term dependencies by incorporating the elapsed time into the system and learn a single representation which can be used to reconstruct the input sequence. Therefore, the mapping learned by the T-LSTM auto-encoder maintains the temporal dynamics of the original sequence with variable time lapse.
In Figure 3, a single layer T-LSTM auto-encoder mechanism is given for a small sequence with three elements \(\left[X_1, X_2, X_3\right]\). The hidden state and the cell memory of the T-LSTM encoder at the end of the input sequence are used as the initial hidden state and the memory content of the T-LSTM decoder. First input element and the elapsed time of the decoder are set to zero and its first output is the reconstruction \(\left(\hat{X}_3\right)\) of the last element of the original sequence \(\left(X_3\right)\). When the reconstruction error \(E_r\) given in Equation 1 is minimized, T-LSTM encoder is applied to the original sequence to obtain the learned representation, which is the hidden state of the encoder at the end of the sequence.
where \(L\) is the length of the sequence, \(X_i\) is the \(i\) th element of the input sequence and \(\hat{X}_i\) is the \(i\) th element of the reconstructed sequence. The hidden state at the end of the sequence carries concise information about the input such that the original sequence can be reconstructed from it. In other words, representation learned by the encoder is a summary of the input sequence [7]. The number of layers of the auto-encoder can be increased when the input dimension is high. A single layer auto-encoder requires more number of iterations to minimize the reconstruction error when the learned representation has a lower dimensionality compared to the original input. Furthermore, learning a mapping to low dimensional space requires more complexity in order to capture more details of the high dimensional input sequence. In our experiments, a two layer T-LSTM auto-encoder, where the output of the first layer is the input of the second layer, is used because of the aforementioned reasons.
Given a single representation of each patient, patients are grouped by the \(k\)-means clustering algorithm. Since we do not make any assumption about the structure of the clusters, the simplest clustering algorithm, \(k\)-means, is preferred. In Figure 3 , a small illustration of clustering the patient cohort for 8 patients is shown. In this figure, learned representations are denoted by \(R\). If \(R\) has the capability to represent the distinctive structure of patient sequence, then clustering algorithm can group patients with similar features (diagnoses, lab results, medications, conditions, and so on) together. Thus, each patient group has a subtype, which is a collection of common medical features present in the cluster. Given a new patient, learned T-LSTM encoder is used to find the representation of the patient and the subtype of the cluster which gives the minimum distance between the cluster centroid and the new patient's representation is assigned to the new patient. As a result, T-LSTM auto-encoder learns powerful single representation of temporal patient data that can be easily used to obtain the subtypes in the patient population.
本文来自博客园,作者:Un-Defined,转载请保留本文署名Un-Defined,并在文章顶部注明原文链接:https://www.cnblogs.com/EIPsilly/p/18055021

 浙公网安备 33010602011771号
浙公网安备 33010602011771号