[论文阅读] Progressive Domain Expansion Network for Single Domain Generalization
Progressive Domain Expansion Network for Single Domain Generalization
3. Method
本文提出的PDEN用于单域泛化。假设源域为 \(\mathcal{S}=\left\{x_i, y_i\right\}_{i=1}^{N_S}\),目标域为 \(\mathcal{T}=\left\{x_i, y_i\right\}_{i=1}^{N_T}\),其中 \(x_i, y_i\) 分别表示第 \(i\) 张图像和类别标签,\(N_S, N_T\) 分别表示源域和目标域中样本的数量。我们的目标是仅使用 \(\mathcal{S}\) 来训练模型,然后使其能够泛化到未见过的 \(\mathcal{T}\)。
3.1. The task model \(M\)
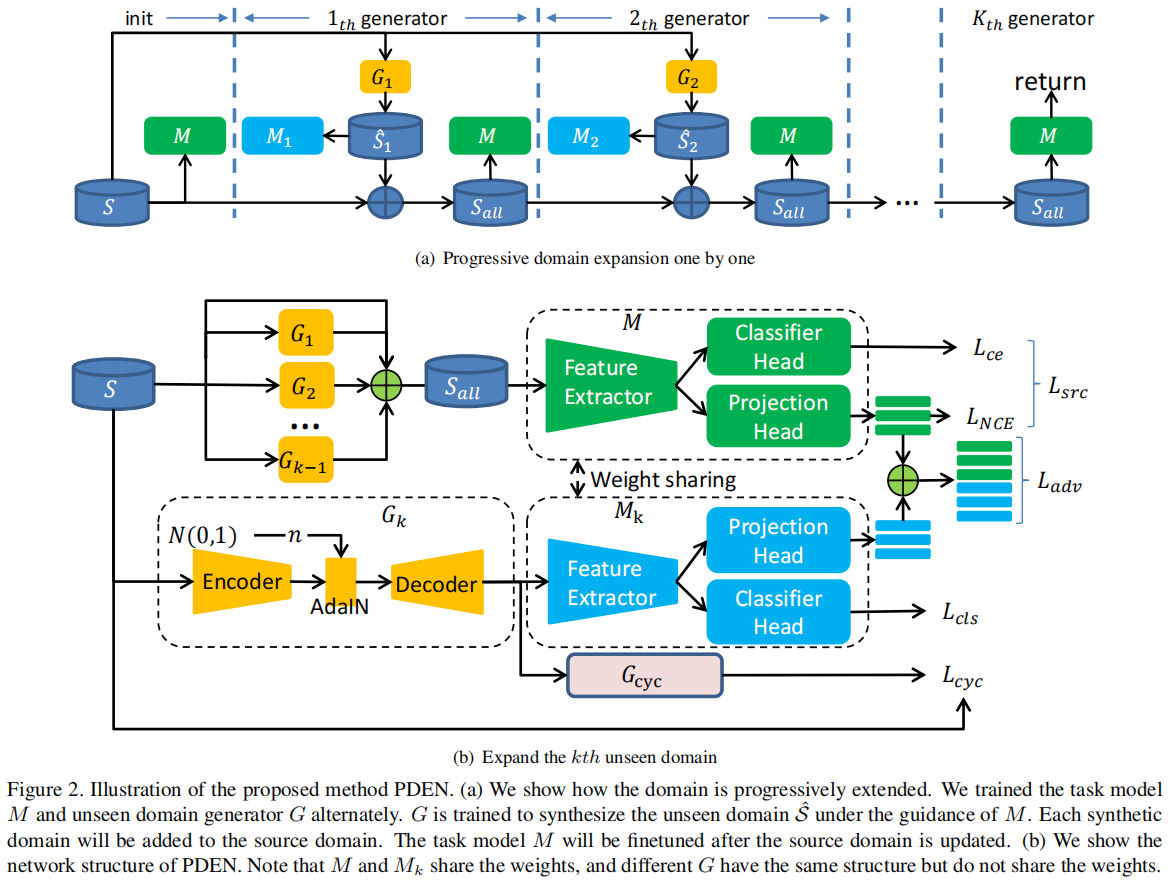
PDEN的整体模型架构如图2(b)所示,包括任务网络 \(M\) 和未见域生成器 \(G\)。在本节中,我们将介绍PDEN中的任务模型。
\(M\) 包括三个部分:
- 特征提取器 \(F: \mathcal{X} \rightarrow \mathcal{H}\),其中 \(\mathcal{X}\) 是图像空间,\(\mathcal{H}\) 是特征空间。\(F\) 是由卷积层、池化层和激活层组成的堆叠。\(F\) 的输出是通过全局池化得到的一维向量。
- 分类器头 \(C: \mathcal{H} \rightarrow \mathcal{Y}\),其中 \(\mathcal{Y}\) 是标签空间。在这里,我们关注分类任务,所以任务头 \(C\) 通过交叉熵损失进行优化。在我们的实验中,\(C\) 是由全连接层、非线性激活层组成的堆叠,\(C\) 中的最后一个激活层是 softmax 激活函数。
- 投影头 \(P: \mathcal{H} \rightarrow \mathcal{Z}\),其中 \(\mathcal{Z}\) 是隐藏空间,用于计算对比损失。在我们的实验中,\(P\) 只包含一个全连接层。我们将 \(P\) 的输出向量标准化为单位超球面上,这使得可以使用内积来度量 \(\mathcal{Z}\) 空间中的相似性。
3.2. The Unseen Domain Generator \(G\)
\(G\) 能够将原始图像 \(x\)(原始域 \(\mathcal{S}\) )转换为新图像 \(\hat{x}\)(未见域 \(\hat{\mathcal{S}}\) ),具体如下:
其中 \(\hat{x}\) 具有与 \(x\) 相同的语义信息,但 \(\hat{x}\) 和 \(x\) 的域是不同的。
\(G\) 可以是各种结构,取决于相关的下游任务,例如 AutoEncoder [18]、HRNet [37]、空间变换网络(STN)[15] 或这些网络的组合。
以 Autoencoder 作为 \(G\):在我们的实验中,我们主要使用带有 AdaIN [17] 的 Autoencoder 作为生成器,如图2中所示的 \(G_k\)。生成器 \(G\) 包含编码器 \(G_E\)、AdaIN 和解码器 \(G_D\)。在 AdaIN 中,有两个全连接层 \(L_{f c 1}, L_{f c 2}\):
其中 \(n \sim N(0,1)\)。图3(a) 显示了由 Autoencoder 生成的未见域。
以 STN 作为 \(G\):可以用 STN[15] 替代 Autoencoder 作为生成器。STN 是一种具有几何感知的模块,可以变换图像的空间结构。图3(b) 显示了由 STN 生成的未见域。
PDEN是一个框架,生成器可以根据任务的不同而被替换为不同的结构。在我们的实验中,应用了自动编码器。
3.3. Progressive Domain Expansion
为了提高生成域的完整性并扩展其覆盖范围,我们使用可学习的生成器 \(G\) 逐渐生成 \(K\) 个未见域 \(\left\{\hat{\mathcal{S}}_k=G_k(\mathcal{S})\right\}_{k=1}^K\)。任务模型 \(M\) 将与这些未见域一起训练,以学习跨域不变表示。我们交替训练任务模型和生成器,如图2所示。
以第 \(k\) 个域扩展为例。首先,通过最小化等式(9),共同训练生成器 \(G\) 和任务模型 \(M\),合成安全有效的未见域 \(\hat{\mathcal{S}}_k\)。然后,通过最小化等式(3),使用更新后的数据集 \(\mathcal{S} \cup\left\{\hat{\mathcal{S}}_i\right\}_{i=1}^k\) 重新训练任务模型 \(M\)。\(M\) 的性能将得到改善,从而 \(M\) 可以引导生成器 \(G_{k+1}\) 合成更好的未见域。算法如图Alg.1所示。

3.4. Domain Alignment and Classification
在本节中,我们将介绍如何学习跨域不变表示。给定一个小批量 \(\mathcal{B}=\) \(\left\{x_i, y_i\right\}_{i=1}^{2 N}\),其中 \(x_i\) 是源图像,\(x_i^{+}=G\left(x_i, n\right)\) 是由 \(x_i\) 生成的合成图像(\(x_i\) 和 \(x_i^{+}\) 具有相同的语义信息,但来自不同的域),\(y_i\) 是类别标签。\(M\) 的优化目标为:
其中 \(y_i^m\) 是 \(y_i\) 的第 \(m\) 维;\(\hat{y}_i=C\left(F\left(x_i\right)\right)\);\(z_i=P\left(F\left(x_i\right)\right)\)。
\(L_{c e}\) 是用于分类的交叉熵损失。\(L_{N C E}\) 是用于对比学习的 InfoNCE 损失[32]。在小批量 \(\mathcal{B}\) 中,\(z_i\) 和 \(z_i^{+}\) 具有相同的语义信息,但来自不同的域。通过最小化 \(L_{N C E}\),\(z_i\) 和 \(z_i^{+}\) 之间的距离将变小。
换句话说,具有相同语义信息但来自不同域的样本将在 \(\mathcal{Z}\) 空间中更加接近。\(L_{N C E}\) 将引导 \(F\) 学习域不变表示。
3.5. Unseen Domain \(\hat{\mathcal{S}}\) Generation
在本节中,我们将展示如何通过生成器 \(G_k\) 从 \(\mathcal{S}\) 中生成第 \(k\) 个未见域 \(\hat{\mathcal{S}}_k\)(为方便起见,我们使用 \(G, \hat{\mathcal{S}}\) 代替 \(G_k, \hat{\mathcal{S}}_k\))。\(\hat{\mathcal{S}}\) 需要满足安全性和有效性的约束。安全性意味着生成的样本包含域不变信息。有效性意味着生成的样本包含各种未见域特定信息。
安全性。 如果任务模型 \(M\) 能够对 \(\hat{\mathcal{S}}\) 中的所有 \(x\) 进行正确预测,则 \(\hat{\mathcal{S}}\) 是安全的。形式上,我们优化:
进一步确保 \(\hat{\mathcal{S}}\) 的安全性,引入了循环一致性损失[47]。如果可以通过生成器 \(G_{c y c}\) 将 \(\hat{\mathcal{S}}\) 转换回 \(\mathcal{S}\),则 \(\hat{\mathcal{S}}\) 是安全的。\(G_{c y c}\) 与 \(G\) 具有相同的结构,但没有噪声输入。形式上,我们优化:
有效性。 对抗学习被引入以生成有效的未见域。生成器 \(G\) 和任务模型 \(M\) 被联合学习。任务模型 \(M\) 提取域共享表示,并始终被训练以最小化 InfoNCE 损失。生成器 \(G\) 被训练以最大化 InfoNCE 损失。通过对抗训练,\(G\) 将生成未见域,从中 \(M\) 无法提取域共享表示,而 \(M\) 将更能够提取跨域不变表示。损失可以定义为:
然而,损失函数Equ. 6 难以收敛。随着 \(\tilde{L}_{a d v}\) 中的第一项变小,梯度变大。因此,我们使用以下方程来近似 \(\tilde{L}_{a d v}\)。
我们还使用一个损失函数来鼓励 \(G\) 生成更多样化的样本。
其中 \(n_1, n_2 \sim N(0,1)\),且 \(n_1 \neq n_2\)。总的来说,训练生成器 \(G\) 的损失函数如下:
其中 \(L_{c l s}\) 的权重始终为 \(1\),\(w_{c y c}\)、\(w_{a d v}\)、\(w_{d i v}\) 分别是 \(L_{c y c}\)、\(L_{a d v}\)、\(L_{d i v}\) 的权重。
4. Experiment
4.1. Datasets and Evaluate
Follow [33, 40], we evaluated our approach on Digits, CIFAR 10-C and SYNTHIA.
Digits Dataset: Digits数据集包含5个子数据集:MNIST[22]、MNSIT-M[10]、SVHN[31]、USPS[7]、SYNDIGIT[10]。每个数据集被视为一个域。我们使用MNIST作为源域,其他四个数据集作为目标域。在MNIST中,我们使用前10,000张图像进行模型训练。
CIFAR 10-C Dataset: 我们将CIFAR 10[21]用作源域,将CIFAR10-C[13]用作目标域。CIFAR10-C是一个用于评估分类模型鲁棒性的基准数据集。CIFAR 10-C数据集包含具有19种污染类型的测试图像,这些类型是通过算法生成的。污染来自4个类别,每种污染类型有5个严重程度级别。
SYNTHIA Dataset: SYNTHIA VIDEO SEQUENCES[35]数据集用于交通场景分割。该数据集包含3个位置:Highway、New York ish和Old European Town。每个位置包含相同的交通情境,但在不同的天气/光照/季节条件下(在我们的实验中使用Dawn、Fog、Spring、Night和Winter)进行拍摄。按照[40]的协议,我们在一个域上训练模型,然后在其他域上进行评估。对于每个域,我们从左前摄像头中随机采样900张图像,并将所有图像调整为192×320像素。
Evaluate: 对于Digit和CIFAR10数据集,我们计算每个未见域的平均准确度。对于SYNTHIA数据集,我们使用标准的平均交并比(mIoU)来评估每个未见域上的性能。
4.2. Evaluation of Single Domain Generalization
我们将我们的方法与以下最先进的方法进行比较:
- 经验风险最小化(Empirical Risk Minimization,ERM)[19]是基准方法,仅使用交叉熵损失进行训练。
- CCSA [28]通过对同一类别不同域的样本进行对齐,获得了用于域泛化的强大特征空间。
- d-SNE[41]通过最小化相同类别样本对的最大距离,并最大化不同类别样本对之间的最小距离。
- GUD [40]提出了一种对抗数据增强方法,用于合成更难的样本,从而提高分类器的鲁棒性。
- MADA [33]通过最小化语义空间的距离和最大化像素空间的距离,生成更有效的样本。
- JiGen [2]提出了一种多任务学习方法,将目标识别任务与Jigsaw分类任务结合起来,以提高模型的跨域泛化能力。
- AutoAugment(AA)[4]提出了一种自动搜索特定数据集的改进数据增强策略的方法。
- 在AA基础上,RandAugment(RA)[5]具有更好的数据增强策略,大大减小了策略空间。
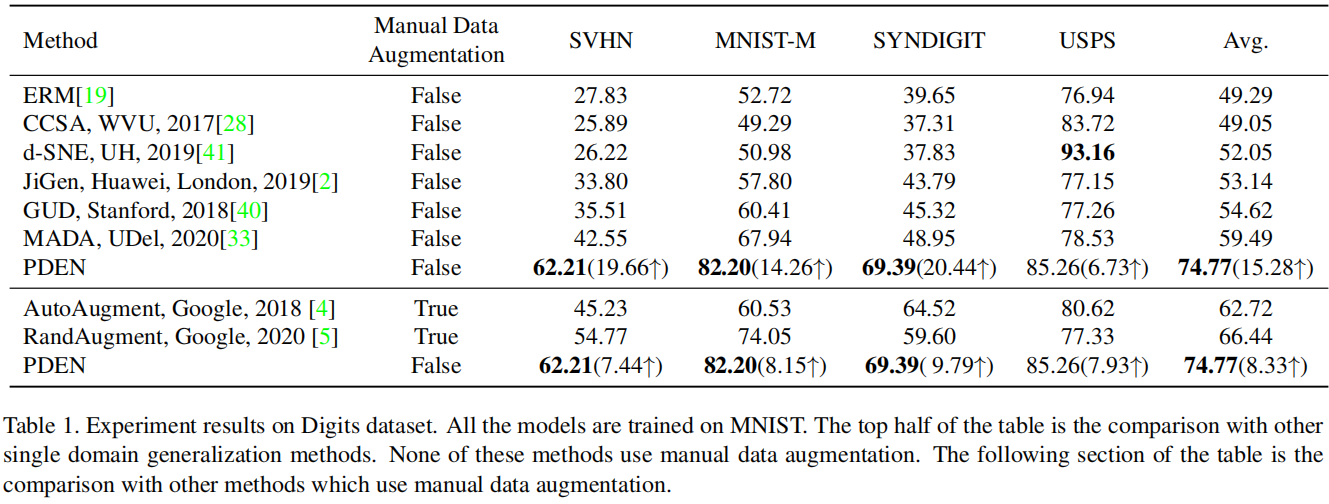
Comparison on Digits: 我们使用MNIST训练集中的前10,000张图像训练模型,在MNIST测试集上进行验证,并在MNISTM、SVHN、USPS和Syndigits数据集上进行评估。我们计算每个数据集上的平均准确度作为评估指标。首先,我们与单域泛化方法进行比较,如表1的上半部分所示。为了公平起见,我们没有使用任何手动数据增强。我们观察到我们的方法在SVHN、MNIST-M和USPS上的性能明显优于其他方法。在USPS上,我们的方法的性能与其他方法相当,主要是因为USPS与MNIST更相似。d-SNE[41]在USPS上表现良好,但在其他数据集上表现不佳。我们还与数据增强方法进行比较,如表1的下半部分所示。超参数与原始论文中的相一致。我们发现我们的方法优于这些方法。此外,我们的方法与这些数据增强技术是正交的。
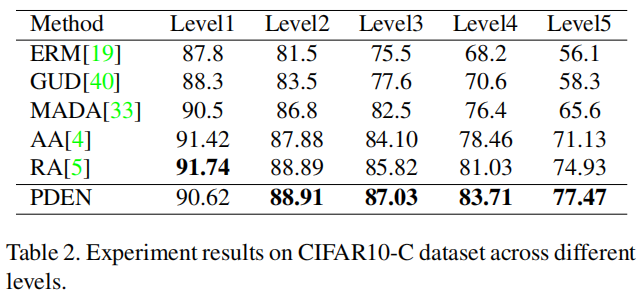
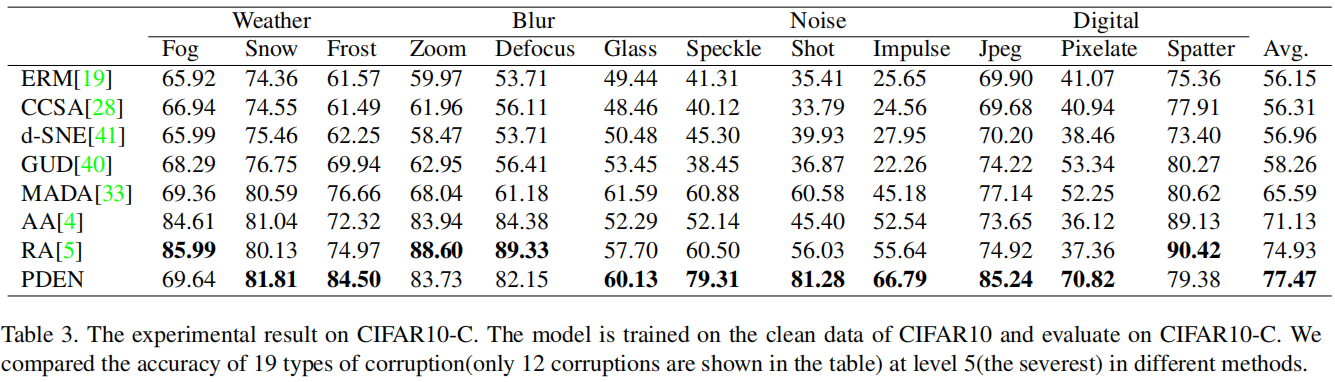
Comparison on CIFAR10: 我们在CIFAR10训练集上训练所有模型,在CIFAR10测试集上进行验证,并在CIFAR10-C上进行评估。在表2中展示了在五个污染严重程度级别上的实验结果。我们的方法优于其他单域泛化方法,如GUD和MADA。污染越严重,我们的方法超越MADA的优势越大。与使用手动数据增强的方法相比,我们的方法在较低程度的污染下表现得与它们一样好,在较高程度的污染下表现更好。我们还在表3中展示了在不同类型的污染下的实验结果,其中污染的严重程度为第5级。我们的方法具有更高的平均准确度。在某些污染类型中,RandAugment方法的表现优于我们的方法。然而,重要的是要注意,在我们的方法中没有手动数据增强,并且我们的方法可以与RandAugment一起使用。
Comparison on SYNTHIA: 遵循[33]中的协议,我们进行了三个实验,分别以HighwayDawn、Highway-Fog和Highway-Spring作为源域,将New York ish和Old European Town中的所有天气视为未见目标域。场景分割结果(mIoU)如表4所示。与其他方法相比,我们的方法提高了平均mIoU。当源域为HighwayDawn或Highway-Fog时,提高更为显著。
4.3. Additional Analysis
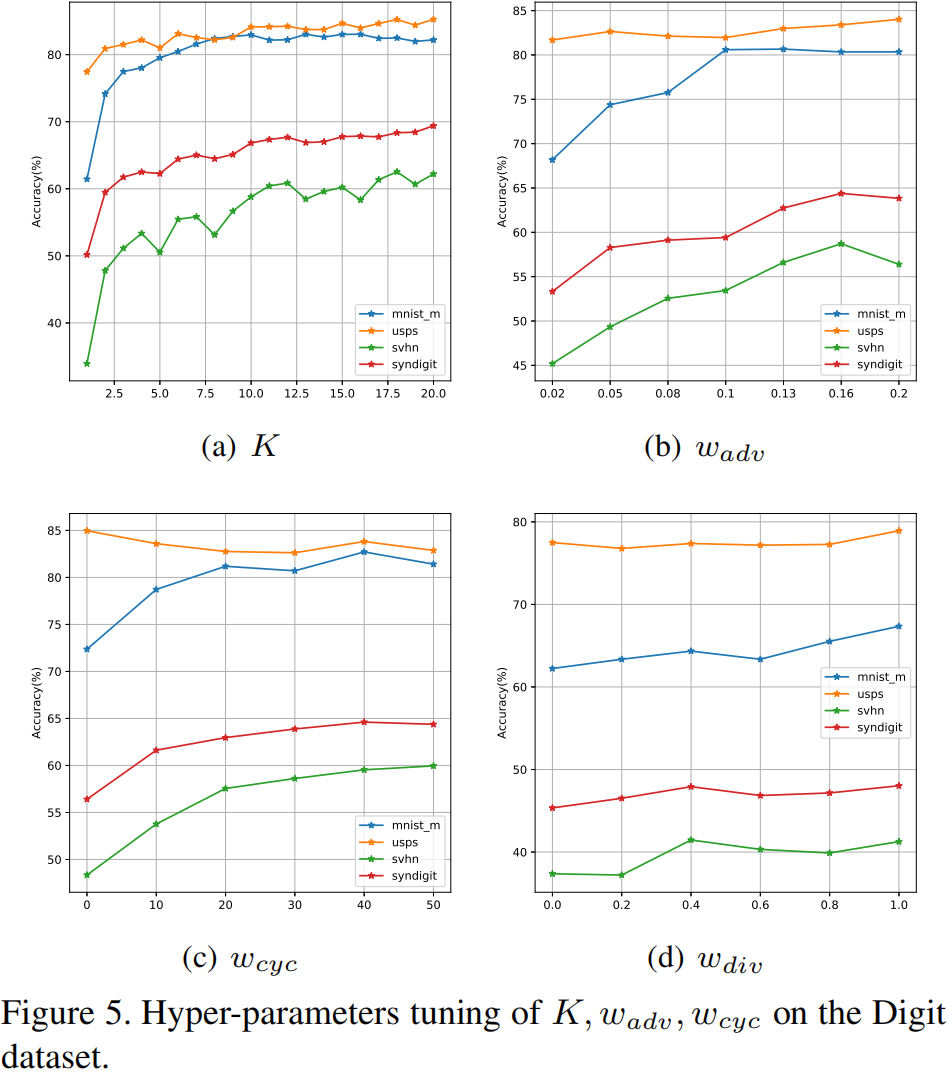
Validation of \(K\) :我们研究了超参数 \(K\) 对Digits数据集的影响。我们以MNIST为源域,将MNIST-M、SVHN、USPS和SYNDIGIT作为未见目标域。实验结果如图5(a)所示。我们报告了在 \(K=1,2, \ldots, 20\) 时在目标域上的分类准确度。当 \(K\) 较小时,准确度迅速增加,当 \(K\) 较大时逐渐收敛。在Digits的实验中,我们设定 \(K=20\)。在MADA[33]的Digits实验中,他们的方法在 \(K=3\) 时表现最好,随着 \(K\) 的增长而降低。这表明我们方法生成的域比MADA更安全。
Validation of \(w_{a d v}\) : 我们研究了超参数 \(w_{adv}\) 对Digits数据集的影响。实验结果如图5(b)所示。我们报告了在目标域上的分类准确度,当 \(w_{adv}=0.02,0.05,0.08,0.1,0.13,0.16,0.2\) 时。我们发现随着 \(w_{adv}\) 的增加,准确度在未见目标域上增加。
Validation of \(w_{c y c}\) : 我们研究了超参数 \(w_{cyc}\) 对Digits数据集的影响。实验结果如图5(c)所示。我们报告了在MNIST-M、USPS、SVHN和SYNDIGIT上的分类准确度,当 \(w_{cyc}=0,10,20,30,40,50\) 时。在MNIST-M、SVHN和SYNDIGIT上,随着 \(w_{cyc}\) 的增加,准确度增加。在USPS上,分类准确度随着 \(w_{cyc}\) 的增加没有显著变化(在一个较小的范围内波动),主要是因为USPS与MNIST之间的相似性较高。
Validation of \(w_{d i v}\) : 我们在图5(d)中说明了超参数 \(w_{div}\) 的影响。对于Digits数据集中的所有未见域,随着 \(w_{div}\) 的增加,分类准确度也在增加。
 .
.
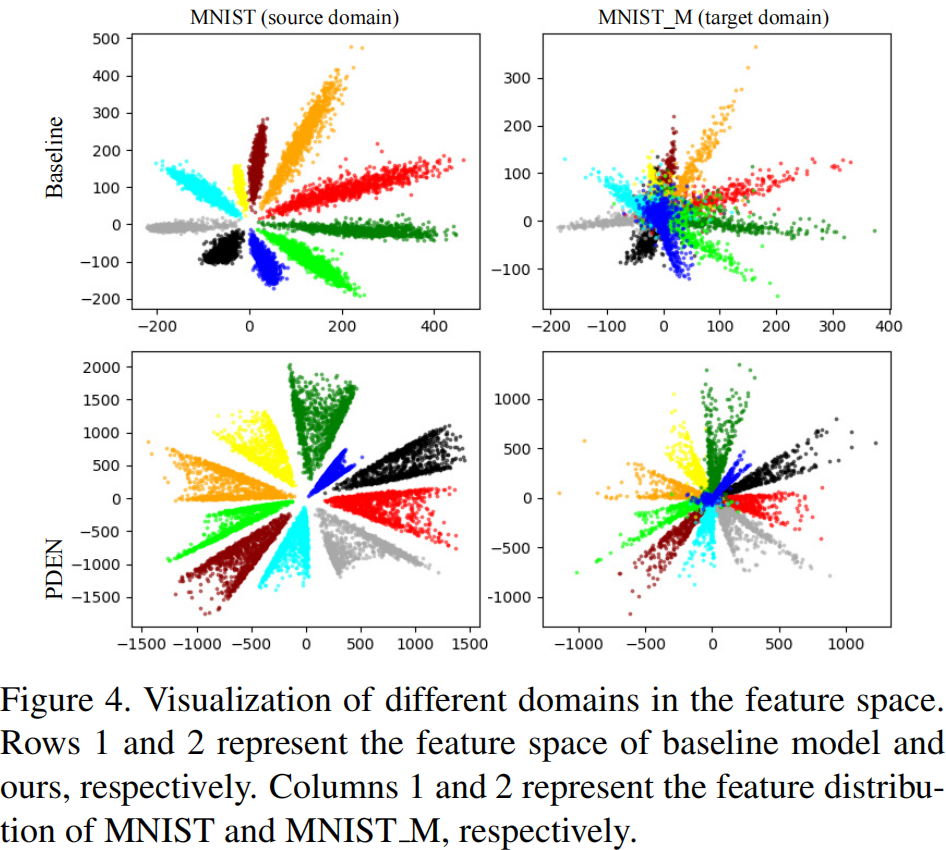
Visualization of the feature space: 图4说明了PDEN与基线模型在2维特征空间中的差异。对于PDEN,目标域的样本分布与源域一致。对于基线模型,大多数目标样本在特征空间中混合在一起,因此很难对它们进行分类。
4.4. Evaluation of of Few-shot Domain Adaptation
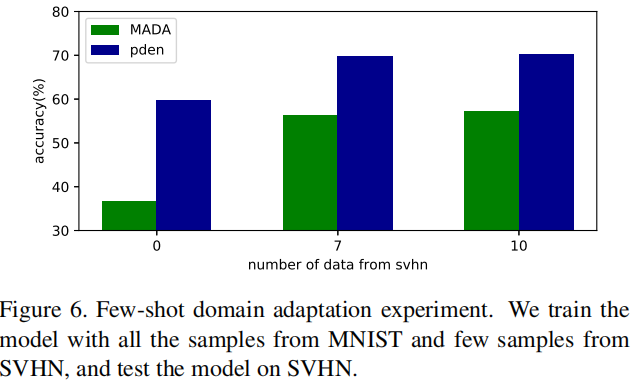
我们还在少样本领域自适应的实验设置中比较了我们的方法[27]。在少样本领域自适应中,使用来自源域 \(\mathcal{S}\) 和目标域 \(\mathcal{T}\) 中的少量样本来训练模型。
我们以MNIST为源域,SVHN为目标域进行实验。我们首先使用提出的PDEN在MNIST上训练模型,然后用来自SVHN的少量样本对模型进行微调。模型将在SVHN上进行评估,如图6所示。我们发现用少量来自目标域的样本进行微调可以显著提高模型在目标域上的性能。与MADA相比,提出的PDEN在这种情况下表现更好。
本文来自博客园,作者:Un-Defined,转载请保留本文署名Un-Defined,并在文章顶部注明原文链接:https://www.cnblogs.com/Undefined-Summer/p/17974449

 浙公网安备 33010602011771号
浙公网安备 33010602011771号