[论文阅读] Anomaly Detection under Distribution Shift
Anomaly Detection under Distribution Shift
1 Introduction
如图1中所示的示例数据所示, in-distribution(ID)测试数据中的正常样本与正常训练数据非常相似,而ID中的异常样本与正常数据差异很大;然而,由于分布转移,OOD测试数据中的正常样本在前景和/或背景特征方面与ID正常数据明显不同,因此这些正常样本可能被错误地检测为异常。
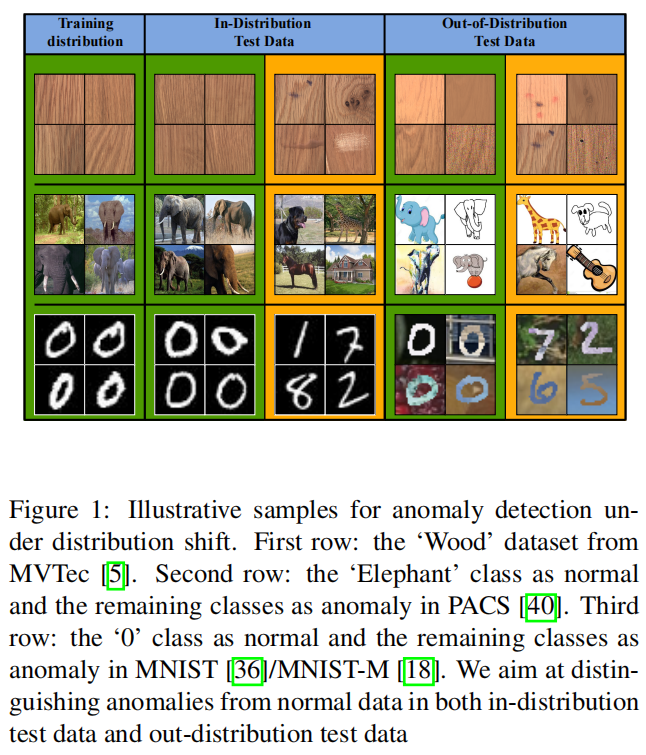
许多 OOD 泛化方法依赖于来自一个或多个相关领域的大规模标记训练数据,以学习领域不变的特征表示。它们通常需要类别标签[29, 60, 79]、领域标签[9,73,81,87]或者在源领域中存在多样化的数据[24, 85, 88]来学习这种稳健的特征表示。然而,在AD任务中,训练数据仅包含一个类别,并且数据是单调的。因此,很难将现有的OOD泛化技术调整以解决分布转移下的AD问题。
在本文中,我们着手解决了在分布转移下的异常检测问题。这是一个OOD泛化问题,旨在学习广义的检测模型,以在具有分布变化的测试数据中准确检测正常和异常样本,同时保持在内部分布测试数据上的有效性。这与OOD检测问题[23, 26, 44, 61, 75]不同,OOD检测问题旨在为了模型部署安全性而使监督学习模型具备拒绝OOD/异常样本的能力,将其视为未知样本。
contributions
- 我们进行了一项广泛的研究,探讨了在异常检测(AD)中的分布偏移问题,并在来自AD和OOD(Out-of-Distribution)泛化任务的四个广泛使用的数据集上,建立了在不同分布偏移情况下的大规模性能基准。我们的实验结果进一步揭示,现有的最先进的AD和OOD泛化方法在识别分布偏移下的异常时效果不佳。
- 我们提出了一种新颖的抗分布偏移异常检测方法,即广义正态性学习(GNL)。GNL通过无监督方式在训练和推断阶段最小化ID和OOD正常样本之间的分布差距。为此,我们引入了一个保持正常性的损失函数,以学习分布不变的正常性表示,这使得GNL能够在不同特征层面上学习正常训练数据的广义语义。GNL还利用测试时增强方法来进一步减小推断阶段的分布差距。
- 大量实验表明,我们的方法GNL在具有各种分布偏移的数据上,在AUCROC方面大幅优于最先进的AD方法和OOD泛化方法,提高了超过10%,同时在ID测试数据上保持了检测准确性。
2 Related Work
2.1. Anomaly Detection
One-class Classification:OC-SVM、SVDD、DeepSVDD、
Reconstruction-based Methods:AE
Self-supervised Learning Methods:data augmentation
Knowledge Distillation: student-teacher framework、Anomaly Detection via Reverse Distillation (RD4AD)
所有这些方法都专注于在训练和测试数据中具有相同分布的AD问题,但在具有分布转移的数据上表现不佳。
2.2 OOD Generalization
Data Augmentation:一种流行的OOD泛化方法是基于数据增强的方法。这一系列方法涉及从现有数据中生成新的数据样本,以增加训练数据的规模和多样性。模型可以通过这种方式更好地学习底层数据分布,从而在测试数据发生变化时变得更加健壮
Unsupervised Learning:通过解决预训练任务,模型可以发展出不特定于目标任务的通用特征。因此,模型不太可能受到特定领域独有的偏见的影响,这有助于避免过拟合并提高对不同未见数据的泛化能力
尽管这两种方法并非专为AD设计,但它们可以很容易地用于AD,因为它们在训练过程中不需要类别或领域标签。另一方面,许多现有的OOD泛化方法,如领域对齐[27, 31, 41, 42, 49, 52, 86]、元学习[15–17, 39, 72]和解耦表示学习[10,30,32,40,58,73],需要类别/领域相关的监督,这对于AD任务是不适用的。
相比之下,我们专注于无监督AD,并且在训练过程中不需要任何OOD数据。此外,他们专注于视频数据,而我们专注于图像数据。
3 Problem Formulation and Challenges
3.1. Problem Formulation
记\(\mathcal{X}_s\)和\(\mathcal{X}_t\)分别表示源(ID)分布和目标(OOD)分布,其中\(\mathcal{X}_s\)用于训练和测试阶段,而\(\mathcal{X}_t\)仅用于推断阶段。我们假设在训练期间,只有来自\(\mathcal{X}_s\)的正常数据可用,即\(\mathcal{D}_s=\left\{x \in \mathcal{X}_s \mid y=0\right\}\),其中\(y \in\{0,1\}\)是二进制标签,指示\(x\)是正常(\(y=0\))还是异常(\(y=1\))样本。在测试期间,数据可以是正常的或异常的,可以来自源分布或目标分布,即\(\mathcal{D}_t=\left\{x \in \mathcal{X}_s \cup \mathcal{X}_t \mid y=\{0,1\}\right\}\)。然后,目标是开发一个无监督异常检测模型,可以有效处理分布转移,并在\(\mathcal{D}_t\)中准确检测异常。具体来说,我们的目标是学习一个函数\(f: \mathcal{X} \rightarrow \mathbb{R}\),该函数为每个样本\(x\)分配一个异常分数,以使\(\forall x_i, x_j \in \mathcal{D}_t, f\left(x_i\right)<f\left(x_j\right)\),当\(y_i=0\)且\(y_j=1\)时成立。
3.2. The Challenges
当前的AD方法涉及对正常训练数据的显式拟合[2,13,64,65]。这可能导致模型学习与正常数据的外观无关的不相关特征,例如,模型可能会将领域特定的背景信息错误地视为正常特征,导致在存在分布转移时异常检测不准确。
在研究的设置中,OOD泛化模型也面临着显著的挑战。这主要是因为AD任务中的训练数据只包含一个类别,数据是单调的,因此很难学习和识别区分正常和异常实例的模式。
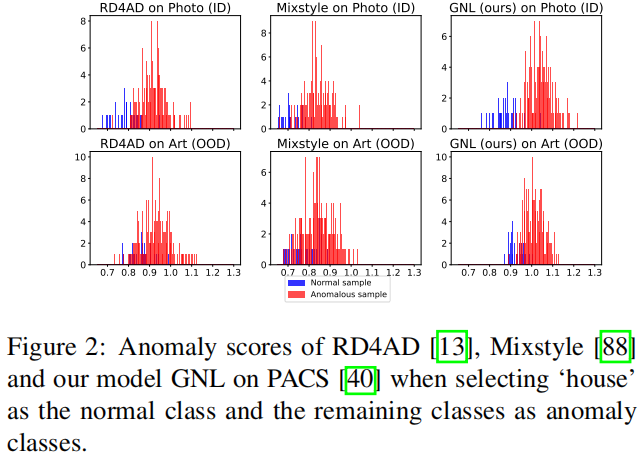
图2说明了这个问题,其中像RD4AD [13](最新的SOTA AD模型)和Mixstyle [88](与RD4AD组合使用的OOD泛化方法)这样的模型在存在分布转移时难以识别正常样本,通常将它们误分类为异常。正常样本和异常样本的异常得分直方图重叠表明这些模型已经学习到了不代表正常数据的特征,这可能是检测异常的主要障碍。主要原因之一是特定数据集的背景或风格特征可能由于不同的自然条件而发生变化。因此,模型可能会将这些变化的特征错误地视为异常,导致分布转移中的正常样本被高异常得分分类为异常。此外,OOD数据中的一些异常样本可能具有与训练数据中的背景或风格特征相似的特征,导致它们以低异常得分被错误分类。
4. Our Approach
为了应对这些挑战,我们引入了一种新的方法,即generalized normality learning(GNL)。
GNL以无监督的方式在训练和推断阶段都最小化了ID和OOD正常样本之间的分布差距。为此,我们引入了一个保持正常性的损失函数,以学习分布不变的正常性表示,这使得GNL能够在不同特征级别上学习正常训练数据的广义语义。
GNL还利用基于特征分布匹配的AD导向测试时间数据增强方法来提高泛化性能。
图3描述了我们方法的两个主要组成部分:(a)用于训练的分布不变正常性学习,以及(b)测试时间增强方法。这两个组件相互补充,意味着在训练期间使用的分布不变正常性学习过程可以支持在测试期间使用的测试时间增强方法,反之亦然。
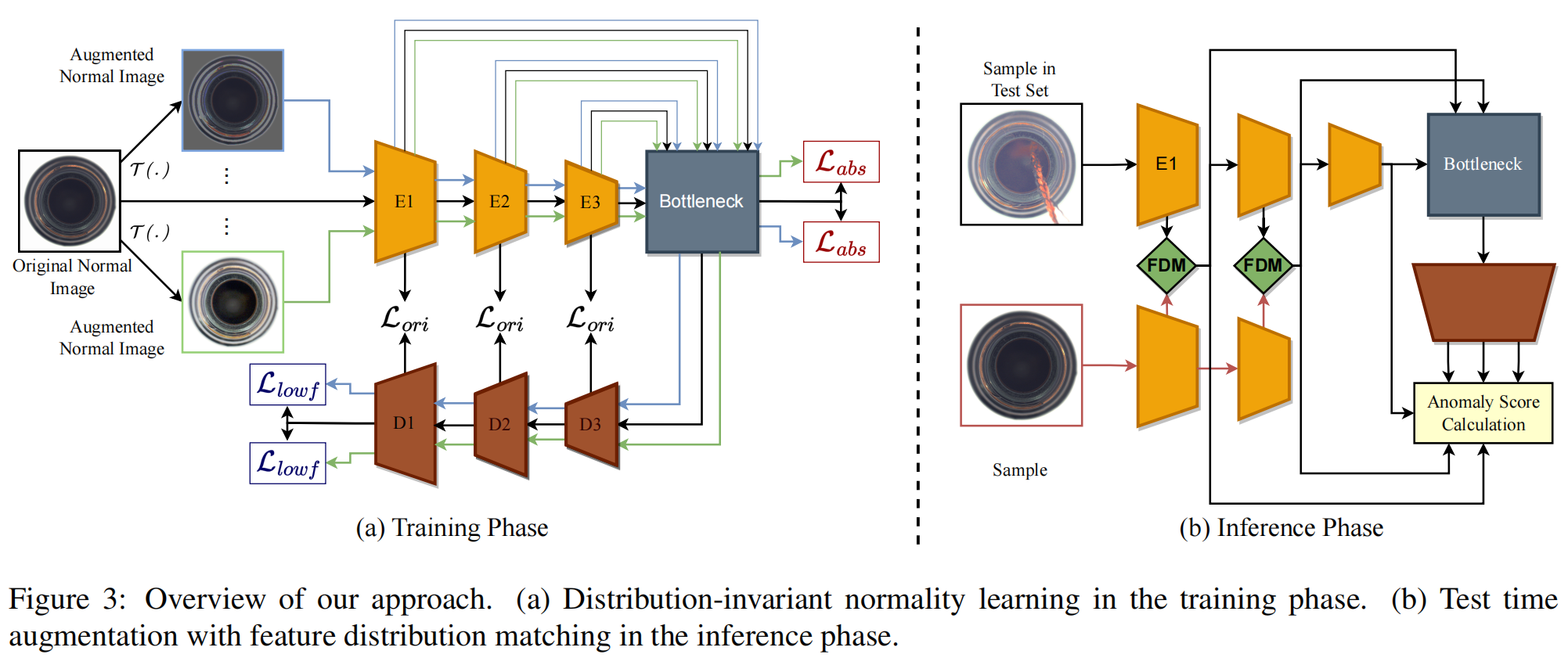
4.1. Distribution-invariant Normality Learning
我们提出引入一个相似性损失,用于量化原始样本的嵌入特征与每个转换过的正常样本的特征之间的差异。具体来说,我们在编码器的瓶颈层和学生解码器的最终块上都强制执行这个损失。为了进一步说明,我们提出了一个损失项,标记为\(\mathcal{L}_{\text{abs}}\),它集成在编码器的瓶颈层。此外,我们还引入了另一个损失项,称为\(\mathcal{L}_{lowf}\),它被添加到学生解码器架构的最终块中。特别地,对于给定的样本\(x \in \mathcal{D}_s\),我们首先对其应用一个增强函数\(\mathcal{T}(.)\),并让\(x_k'=\mathcal{T}(x)\),其中\(k \in [1, N]\),\(N\)是由数据增强生成的增强正常样本的数量,\(\phi\)是将原始图像\(I\)映射到瓶颈层的嵌入空间的映射,然后我们定义\(\mathcal{L}_{\text{abs}}\)为:
其中\(\mathcal{L}_{\text{sim}}(.,.)\)是一种基于余弦相似性的损失函数。
让\(\omega\)表示从抽象特征到解码器最终块的低级特征的重构函数,然后我们进一步定义\(\mathcal{L}_{\text {lowf}}\)为:
我们将这些损失函数组合起来,引入分布不变、保持正常性的损失函数:
其中\(\mathcal{L}_{O r i}\)是RD4AD的原始损失,\(\lambda_{\text {Ori }}, \lambda_{a b s}\)和\(\lambda_{\text {lowf }}\)是确定每种损失函数应该给予多少权重的超参数。
我们采用AugMix [24]作为数据增强方法。然而,我们删除了可能会生成异常样本的增强类型,例如“shear x”、“shear y”、“translate x”和“translate y”,以确保所有生成的数据都是正常样本。这样做可以确保数据增强不会引入异常样本,从而保持了正常性。
直观地说,解码器的最后一个块负责重构简单和低级的特征,例如edges,corners and blobs,而 bottleneck层负责提取更复杂和高级的特征。在瓶颈层,来自不同合成方法的相同图像的抽象信息必须相同,同时保留足够的信息以供解码器重构。因此,通过最小化公式5中的损失函数,GNL分别从低层CNN和高层CNN中学习特征,使其从单个样本生成的不同分布中相同。这有助于确保从不同分布生成的样本在瓶颈层的特征表示是相同的,同时保持了解码的需要信息。
4.2. Test Time Augmentation for Anomaly Detection under Distribution Shift
这个组件的目标是解决测试期间数据分布不匹配的问题。为了实现这一目标,我们提出在推断阶段的教师编码器的多层级层面上使用特征分布匹配(FDM)将训练分布注入到推断样本中。我们提出的测试框架在图3(b)中进行了示范。我们的测试时增强应用于教师编码器的前两个残差块。从第三个残差块开始的推断过程以及异常分数的计算遵循原始的RD4AD框架,没有任何修改。
一些先前的研究关注于FDM,假设输入特征遵循高斯分布[28, 45, 51]。最近,Zhang等人[85]发现了更精确的方法,称为Exact Feature Distribution Matching(EFDM)。所有这些FDM技术都适用于我们提出的框架。需要注意的是,FDM已经用于OOD Generalization,例如Mixstyle [88]和EDFMix [85],但它们在训练期间使用,其目标是通过混合训练集中可用样本的样式来创建新的分布样本,而我们采用FDM作为推断阶段的一个组成部分,其目标不同。
具体来说,给定一个测试样本\(p \in \mathcal{D}_t\),我们随机选择一个来自训练正常样本集\(\mathcal{D}_s\)的样本\(q\)。然后将这两个样本送入教师编码器。让\(\mathcal{P}^m\)和\(\mathcal{Q}^m\)分别表示\(p\)和\(q\)在残差编码块\(E^m\)中的嵌入特征,然后进行以下测试过程:
其中,\(m \in\{0,1\}\),\(\alpha\)是一个用于平衡推断样本和选择的正常样本之间样式混合强度的超参数。处理后的嵌入特征\(\mathcal{P}^1\)和\(\mathcal{P}^2\)然后输入到瓶颈层,并参与计算与原始RD4AD的推断过程相符的异常分数。
对于上述的FDM()函数,我们采用了EFDM(Exact Feature Distribution Matching),这是FDM的最先进方法。其操作如下:
其中,\(\left\{\mathcal{C}_{\tau_i}\right\}_{i=1}^n\)和\(\left\{\mathcal{V}_{\kappa_i}\right\}_{i=1}^n\)是嵌入特征\(\mathcal{C}\)和\(\mathcal{V}\)按升序排列的值。这里,\(n\)代表向量\(\mathcal{C}\)和\(\mathcal{V}\)中元素的数量。注意,\(\mathcal{C}\)是测试样本\(p\)的嵌入特征,起到携带 appearance information的作用。\(\mathcal{V}\)是从训练数据中随机抽样的正常样本\(q\)的嵌入特征,携带style information。
实质上,样本\(q\)在传递与训练数据相关的分布信息方面发挥作用。随机选择样本的原因是由于训练期间数据的单调性,训练集中的任何样本都能携带代表训练数据的分布信息,因此,它有助于避免通常在计算上昂贵的仔细样本选择过程。
通过利用FDM,我们提出的测试过程在推断样本来自OOD集的情况下,最小化了推断样本的特征分布与训练数据中正常样本的特征分布之间的差异。此外,FDM确保了如果推断样本来自ID集,则特征分布保持几乎不变,因为测试样本的分布与其自身的分布一致。因此,我们的测试方法可以在不损害ID数据性能的情况下提高OOD数据的性能。
5. Experiments
5.1. Datasets
**Anomaly Detection : **MVTec,CIFAR-10。为了生成OOD数据集,我们对MVTec和CIFAR-10应用了4种类型的视觉破坏:亮度、对比度、虚焦模糊和高斯噪声。每种类型的破坏程度在MVTec上设置为3,在CIFAR-10上设置为5,以获得OOD数据。
**OOD Generalization : **MNIST-M, PACS。常用的 one-versus-all 协议用于将这两个数据集转换为具有分布变化的AD数据集,其中一个类的样本被用作正常样本,其余类别被视为异常类别。此外,对于MNIST/MNIST-M数据集,我们进行了多类别设置,将偶数类的样本标记为正常样本,而奇数类的样本被识别为异常样本。
在训练过程中,我们只使用ID数据集中的图像,即假设在训练期间不可用OOD数据。在推断过程中,同时使用ID和OOD的测试集。
5.2. Baselines
Deep SVDD [65], f-AnoGAN [68], KDAD [67], and RD4AD [13].
为了评估OOD通用技术在异常检测中的有效性,我们通过将一系列最新的OOD方法与最近提出的RD4AD模型相结合,从而提高在多个数据集上的SOTA性能。使用了四种不同的方法,包括三种基于数据增强的方法Augmix [25]、Mixstyle [91]和EFDM [88],以及一种自监督的方法Jigsaw [8]。
5.3. Implementation Details
OOD generalization baselines : Augmix, Mixstyle, EFDM, Jigsaw。
metric : AUROC
5.4. Comparison Results
我们的模型GNL和基线模型在MVTec、CIFAR-10、MNIST和PACS上的性能分别如表1、表2、表3和表4所示。这四个表格中的性能是每个数据集的类别的平均结果。详细的结果在附录中呈现。
GNL在检测OOD测试数据中的异常时能够显著优于SOTA AD模型和OOD通用方法,同时保持对ID数据的检测准确性。以下我们将详细讨论结果。
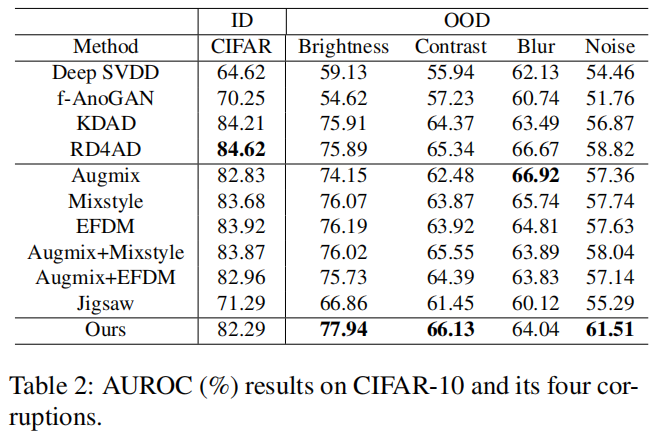
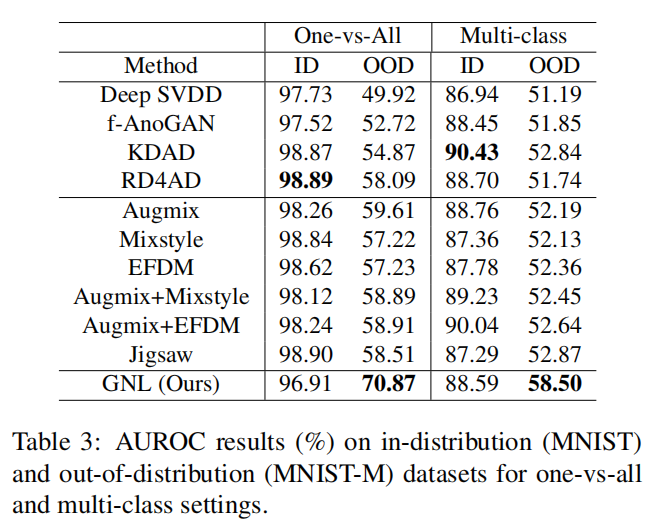
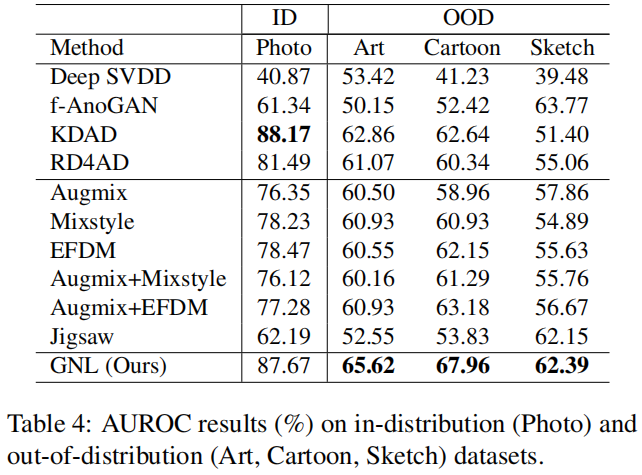
5.4.1 Performance of AD Methods
总体而言,我们观察到所有AD方法,包括Deep SVDD、f-AnoGAN、KDAD和RD4AD,在使用的四个数据集上的OOD数据的AUC分数都显著下降。这表明它们的性能受到了分布偏移的严重影响。特别是在MNIST数据集上,所有AD模型的性能表现令人鼓舞。然而,当这些模型在包含原始MNIST数据集中不存在的变化的MNIST-M数据集上进行测试时,性能下降了约30-40%。在PACS数据集中也观察到类似的趋势,模型的性能也受到OOD数据中分布偏移的显著影响。模型在Photo数据上表现良好,这是ID数据,但在三个OOD数据集Art、Cartoon和Sketch上,它们的性能显著下降。在MVTec和CIFAR-10上,性能仍然下降,但不如其他两个数据集严重。
5.4.2 Performance of Combined OOD Generalization and AD Methods
OOD方法试图通过根据其自身的分布来丰富可用数据,以增加数据的多样性。然而,由于AD中的训练数据通常是单调的和单峰的,这些OOD方法通常无法生成明显偏离原始数据分布的数据样本。因此,生成的数据的增加多样性不足以显著提高AD模型的性能。此外,这些OOD技术还有生成不希望的异常数据的倾向,类似于将噪音注入训练数据,从而降低了AD模型在分布内数据集上的性能。
5.4.3 Performance of Our Method GNL
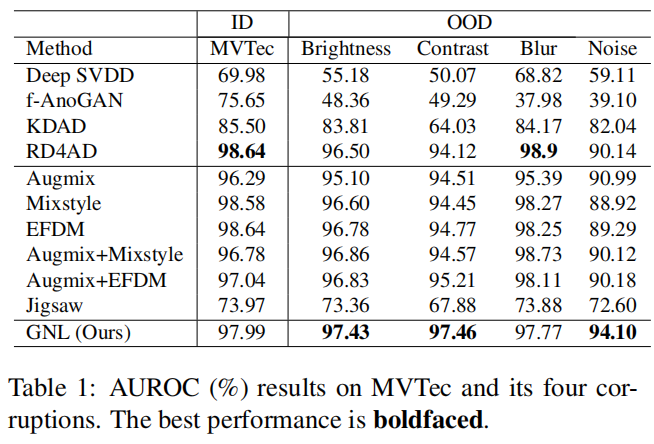
在表11中的MVTec AD数据集上,我们的方法在OOD数据集上表现出显著的性能提升,同时保持了ID数据上的性能。事实上,我们的方法在原始的MVTec ID数据上实现了高度可比的AUROC分数0.9799,同时在亮度0.9743、对比度0.9746、焦散模糊数据集0.9777和高斯噪声0.9410上获得了令人印象深刻的AUROC分数,这些分数较其他方法都有显著提高。这些结果证明了我们的GNL模型对不同的分布转移具有鲁棒性和有效性。
在表2中的CIFAR-10数据集上,我们的方法的实验结果与MVTec数据集上的结果非常相似。我们的方法在原生MVTec ID数据上获得了竞争性的AUROC分数0.8229。值得注意的是,我们的方法在亮度、对比度、焦散模糊和高斯噪声数据集上获得了提高的AUROC分数,分别为0.7794、0.6613、0.6404和0.6151,展示了与其他方法相比的显著改进,尤其是在对比度和噪声情况下。
在表3的MNIST/MNIST-M数据集上,GNL在OOD数据MNIST-M上始终明显优于所有其他方法,AUROC分数至少增加了10个。与最佳性能者RD4AD在ID数据集上获得的AUROC分数0.9889相比,GNL在ID数据集上表现略有下降,获得了AUROC分数0.9691。然而,在MNIST-M数据集上观察到了性能的显著提升,AUROC分数为0.7087,而RD4AD的AUROC分数为0.5809。关于多类别设置,结果表明相对于一对多设置,它增加了挑战性。我们的模型仍然在OOD数据上保持着出色的性能,同时在ID数据上表现出色。
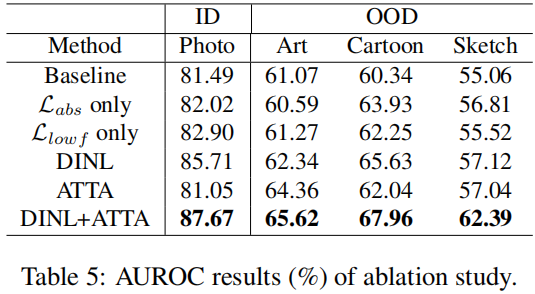
类似地,在表4中的PACS数据集上,GNL在所有四个OOD数据集上始终表现出更高的AUROC性能。特别是,在Art和Cartoon数据集上,GNL获得了至少5%的AUROC分数提高,分别为0.6562、0.6796和0.6239,超过了竞争模型。与RD4AD相比,我们的方法不仅在OOD性能上取得了很大的提升,而且提高了ID数据(Photo数据)的性能。这是因为Photo数据包含多个子域,而RD4AD可能会受到在训练数据中特定子域的过拟合的影响。相比之下,我们的方法通过学习更广义的正常性表示来缓解这个问题,从而改善了Photo数据中所有子域的性能。GNL在ID数据上的性能也与最佳性能者KDAD相当,0.8767对0.8817,而在三个OOD数据集上,GNL的AUROC分数比KDAD高出约3%-10%。
5.5. Robustness to Various Distribution Shift Levels
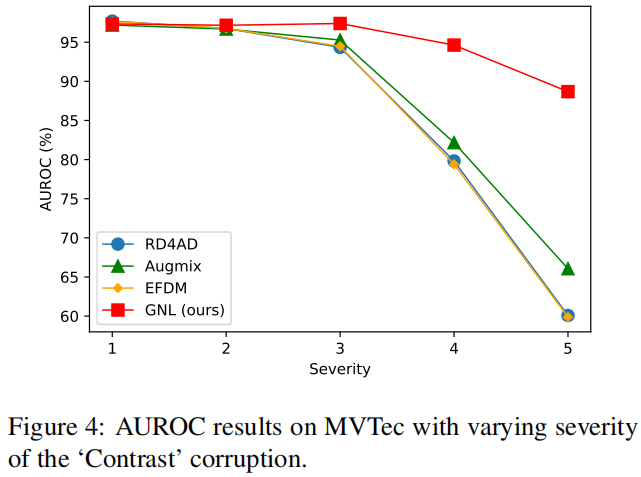
图4展示了GNL对不同程度的分布转移的稳健性结果,使用最佳竞争方法RD4AD、Augmix和EFDM作为基线,在MVTec上进行的实验中,逐渐增加了“对比度”损坏的程度。值得注意的是,基线的性能在损坏严重程度增加时表现出显著下降。这种现象背后的原因很直观,因为增加的损坏严重程度引入了更大的分布方差,使模型难以区分异常和正常样本。另一方面,我们提出的方法在多个分布转移级别上表现出了显著的性能稳定性。我们的方法在严重程度在1到3之间保持稳定的性能,并且在严重程度为4和5时降至约0.90的AUROC,减少了约5%的AUROC,而竞争方法降低了约30%-35%的。这些结果表明了GNL对严重的分布转移具有很强的稳健性。
5.6. Ablation Study
我们在PACS数据集上以RD4AD为基线研究了两个主要组成部分的重要性:单独或同时使用\(\mathcal{L}_{abs}\)和 \(\mathcal{L}_{lowf}\) 的 Distribution-invariant Normality Learning(DINL)(另外还有 \(\mathcal{L}_{ori}\))以及 AD-oriented Test Time Augmentation(ATTA)。结果报告在表5中。实验结果表明,\(\mathcal{L}_{abs}\) 和 \(\mathcal{L}_{lowf}\) 分别从低级和高级特征对DINL的卓越性能做出了积极贡献;当它们在DINL中组合时,它们可以互补。更广泛地看,两个主要组件,DINL和ATTA,也为GNL的卓越性能做出了积极贡献。特别是,实验结果显示,如果只应用测试时间增强,我们在OOD数据集上相对基线获得约2%的AUROC提升,但在ID数据上导致轻微的性能下降。当应用DINL时,无论是在ID数据集还是OOD数据集上都实现了实质性的提高,提高了4%-7%的AUROC。当两者都应用时,我们获得了最佳性能,进一步提高了AUROC。这表明,两个组件,一个用于减小训练期间的分布差距,另一个用于减小推断期间的差距,可以很好地互补。
5.7. Hyperparameter Analysis
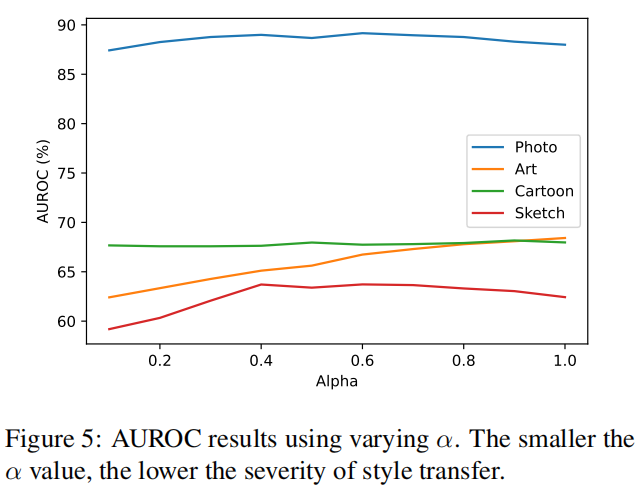
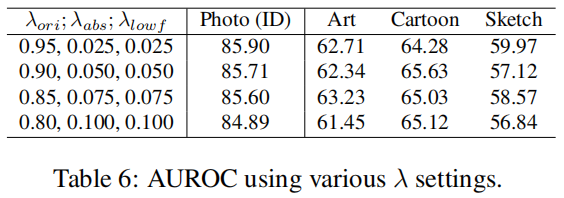
图5显示了我们的模型GNL在不同的 \(\alpha\) 值下性能如何变化,\(\alpha\) 是ATTA中的一个超参数。结果表明,在Photo和Cartoon数据集上,我们的模型的有效性在不同的 \(\alpha\) 值下保持一致。相比之下,模型在Art数据上检测异常的能力似乎随着 \(\alpha\) 的增加而提高。然而,在Sketch数据上,模型的性能在\(\alpha=0.4\) 时达到最高点,并随着\(\alpha\)的进一步增加略有下降。总体而言,实践中通常推荐中等值,例如\(\alpha=0.5\)。我们评估了我们的关键组件DINL对超参数的敏感性,使用了三个 \(\lambda\) 超参数的四种设置:\(\lambda_{ori}\)、\(\lambda_{abs}\)和 \(\lambda_{lowf}\),它们的总和设置为1以便于分析。在PACS上的结果如表6所示。DINL在三个损失的不同超参数比例下表现出良好的稳健性。
5.8. Time and Space Efficiency
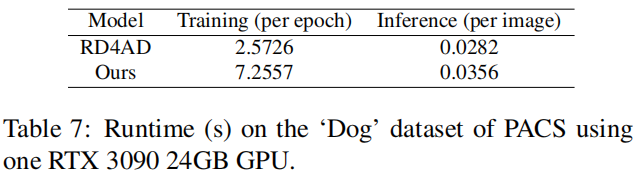
对于空间复杂性,我们的方法改进了RD4AD的训练目标和推断,而不改变其架构,因此没有增加参数数量。如表7所示,就时间效率而言,我们的方法的训练持续时间略长于RD4AD,但这额外的时间产生了显著的性能提升。至于推断,我们的方法仍然具有合理的响应性。
本文来自博客园,作者:Un-Defined,转载请保留本文署名Un-Defined,并在文章顶部注明原文链接:https://www.cnblogs.com/Undefined-Summer/p/17730973.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号