[论文阅读] Isolation forest
IForest
所基于的假设
- 异常是由较少实例组成的少数派
- 它们拥有与正常实例差别较大的属性
换句话说,异常是少而不同的(few and different),这使得它们比正常的点更容易被孤立。
本文证明了可以有效地构造一个树状结构来隔离每个实例。因为异常点易于被隔离,它们通常被被隔离得更接近树的根部;而正常的点被隔离在树的更深的一端。
在IForest中,异常通常是那些在树上具有较短的平均路径长度的实例。
孤立与孤立树
isolation
在论文中,术语 隔离(isolation)是 “将实例与其他实例分开”(separating an instance from the rest of the instances)。
在数据引导的随机树(data-induced random tree)中,递归地对实例进行分区,直到所有实例都被隔离。
这种随机分区为异常产生了明显的更短路径,因为
- 异常实例越少,导致分区数量越少——树结构中的路径越短
- 具有可区分属性值的实例更有可能在早期分区中被分离。
因此,当一组随机树为某些特定的点共同产生较短的路径长度时,那么它们很有可能是异常的。
如下图1所示,我们观察到,一个正常的点 \(x_i\),通常需要更多的分区来被隔离。异常点\(x_o\)则相反,它通常需要更少的分区来隔离。在本例中,分区是通过随机选择一个属性,然后在所选属性的最大值和最小值之间随机选择一个分割值来生成的。
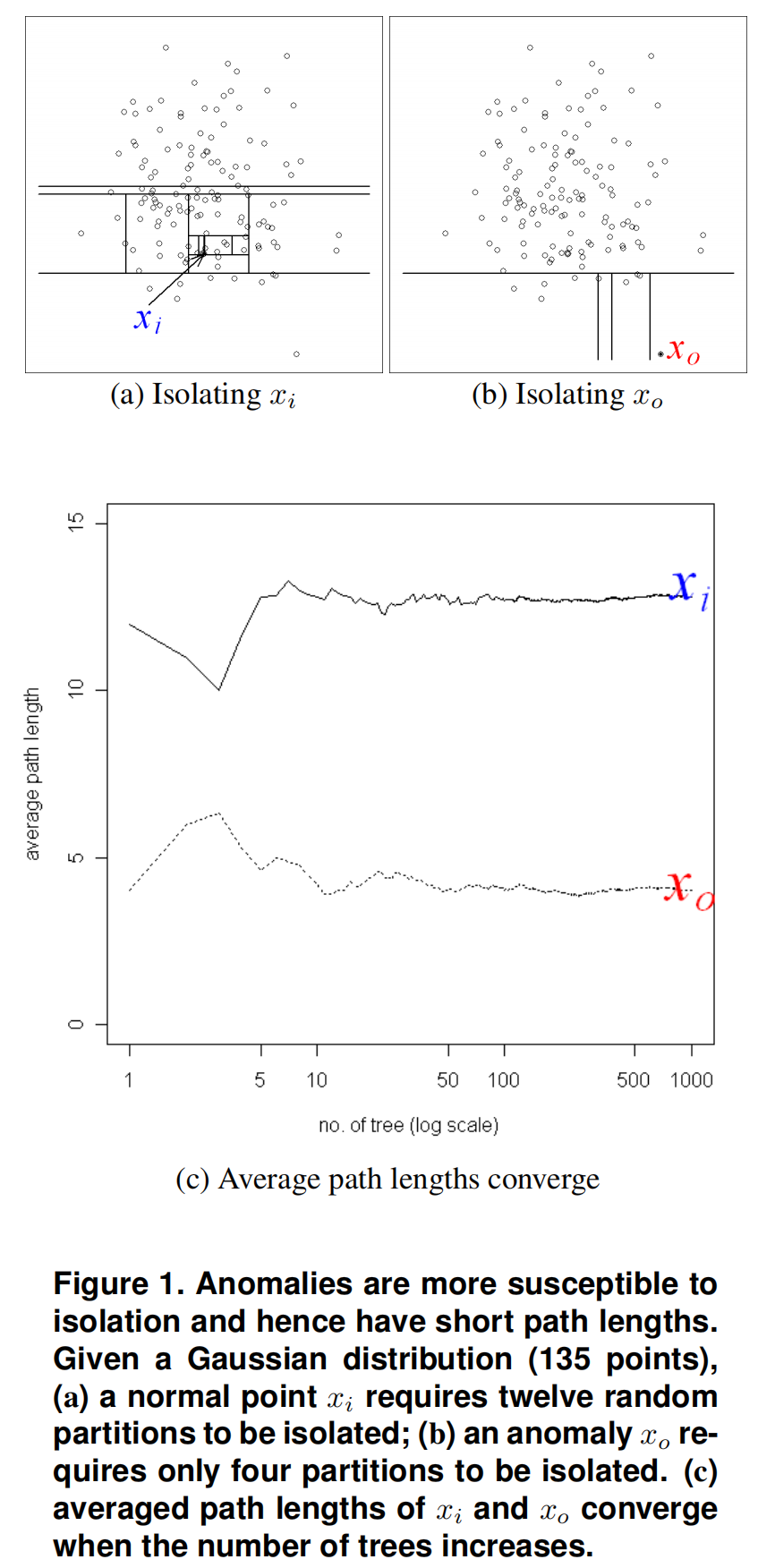
由于每个分区都是随机生成的,所以每个树是由不同的分区生成的。对于每个实例,我们对其在一些树上的路径长度求平均,以找到路径长度的期望。图1(c)显示,当树数增加时,\(x_o\) 和 \(x_i\) 的平均路径长度收敛。使用1000棵树,\(x_o\) 和 \(x_i\) 的平均路径长度分别收敛到 4.02 和 12.82。它表明异常的路径长度比正常实例短。
Isolation Tree
孤立树上的点 \(T\) 要么是没有子节点的叶子节点,要么是包含test的、有\((T_l,T_r)\)两个子节点的内部节点。一个test由一个属性 \(q\) 和一个分割值 \(p\) 组成,这样在属性 \(q\) 上,根据 \(p\) 将数据点分为 \(T_l\) 和 \(T_r\)。
给定一个样本的数据 \(X={x_1,\cdots,x_n}\),共 \(n\) 个实例,每个实例为 \(d\) 维度。我们递归地随机选择属性 \(q\) 和 分割值 \(p\) 来划分 \(X\),直到树高达到高度限制,或者样本个数为1,或者样本拥有相同的值。
孤立树为真二叉树(Proper binary trees )(不知道怎么翻译),即每个点拥有0个或2个子节点。当样本 \(X\) 中每个实例都不同时,则 iTree 拥有 n 个叶子节点,n-1个内部节点,其中每个叶子节点对应一个实例。因此 iTree 总共有 \(2n-1\) 节点,需要的空间大小为 \(O(n)\)
Path Length
\(h(x)\) 表示从树根出发,到实例 \(x\) 所在的叶子节点的边的个数。
Anomaly Score
因为 iTree 与 BST(Binary Search Tree,二叉搜索树)拥有相同的结构,所以对于在叶子节点终止\(h(x)\) 的平均值估计与 BST 上未找到对象的搜索相同。(两者都是在proper binary tree上从根遍历到叶子节点)。
给定 \(n\) 个实例,在 BST 上的不成功搜索的平均路径为
其中 \(H(i)\) 是调和数(harmonic number),可以用 \(ln(i)+0.5772156649\) 进行估计。
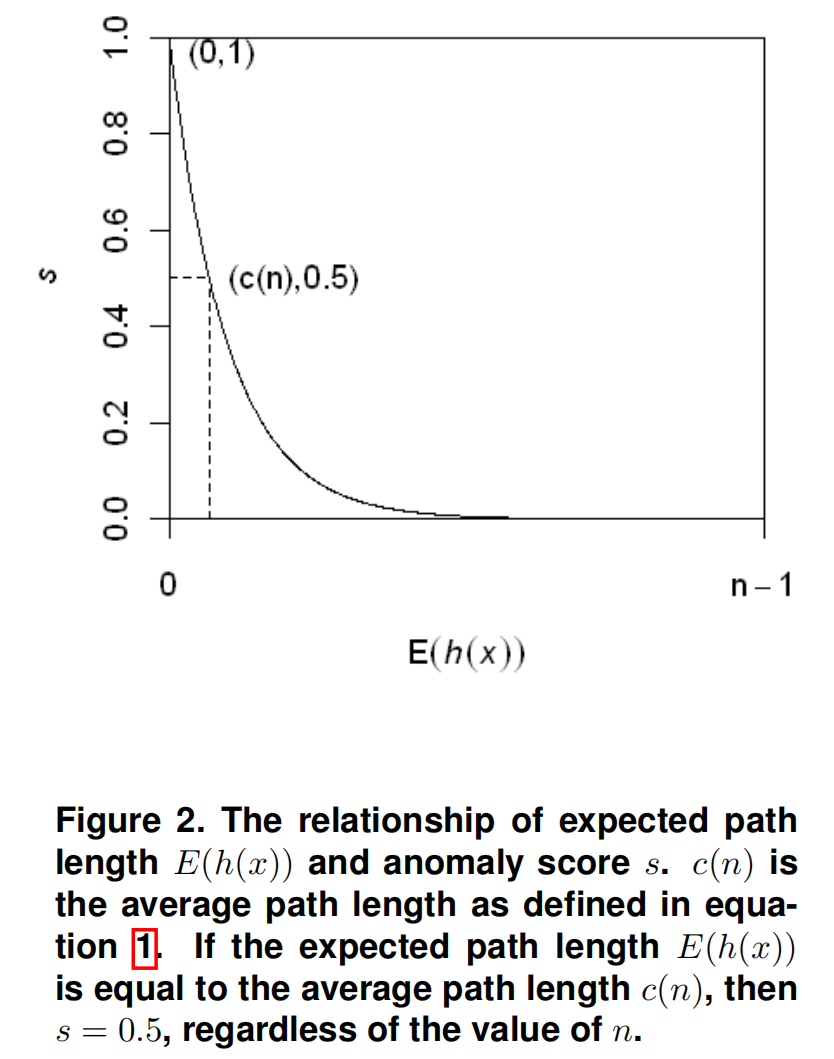
我们用 \(c(n)\) 对 \(h(x)\) 进行归一化。则实例 \(x\) 的得分 \(s\) 定义如下
其中 \(E(h(x))\) 是孤立树集合中 \(h(x)\) 的平均值。
- 当 \(E(h(x)) \rightarrow c(n)\) 时, \(s \rightarrow 0.5\)
- 当 \(E(h(x)) \rightarrow 0\) 时, \(s \rightarrow 1\)
- 当 \(E(h(x)) \rightarrow n-1\) 时, \(s \rightarrow 0\)
图2展示了 \(E(h(x))\) 与 \(s\) 之间的关系。
-
如果实例的异常得分 \(s\) 非常接近1,那么它们肯定是异常
-
如果实例的异常得分 \(s\) 远小于0.5,那么它们可以被视为正常实例
-
如果所有实例的异常得分 \(s \approx 0.5\),那么整个样本实际上没有任何明显的异常。
Characteristic of Isolation Trees
作为一个使用隔离树的树集合,iForest
- 将路径长度较短的点识别为异常
- 有多个树作为“专家”来定位不同的异常。
采样的好处
隔离法在样本量较小的情况下效果最佳。大样例量会降低forest隔离异常的能力,因为正常实例会干扰隔离过程,因此会降低其清晰隔离异常的能力。
swamping指将正常样本标识为异常。当正常样本与异常样本很近时,分离异常实例所需的分区数量就会增长,这使得区分正常实例与异常实例更加困难。
masking指异常的大量存在掩盖了自身的存在。当异常簇大且密集时,将会增加分区的数量来隔离每个异常。这种情况下,这些孤立树的评估具有更长的路径长度,使得异常更难检测到。
注意,swamping和masking都是太多数据用于异常检测的后果。
孤立树使用子采样来建立一个部分模型,从而减轻了swamping和masking的影响。
这是因为
- 子样本控制了数据的大小,这有助于iForest更好地隔离异常的例子
- 每个隔离树都可以特殊化,因为每个子样本包含不同的异常集,甚至没有异常。
如图4(a)所示。该数据集有两个异常簇,位于中心的一个大的正常点簇附近。异常簇周围存在干扰的正常点,而且异常簇比正常簇更加密集。
图4(b)展示了原始数据的128个采样。异常簇在子样本中可以清晰地识别出来。那些围绕着两个异常簇的正常实例已经被清除,而且异常簇的大小变小,这使得它们更容被易识别。
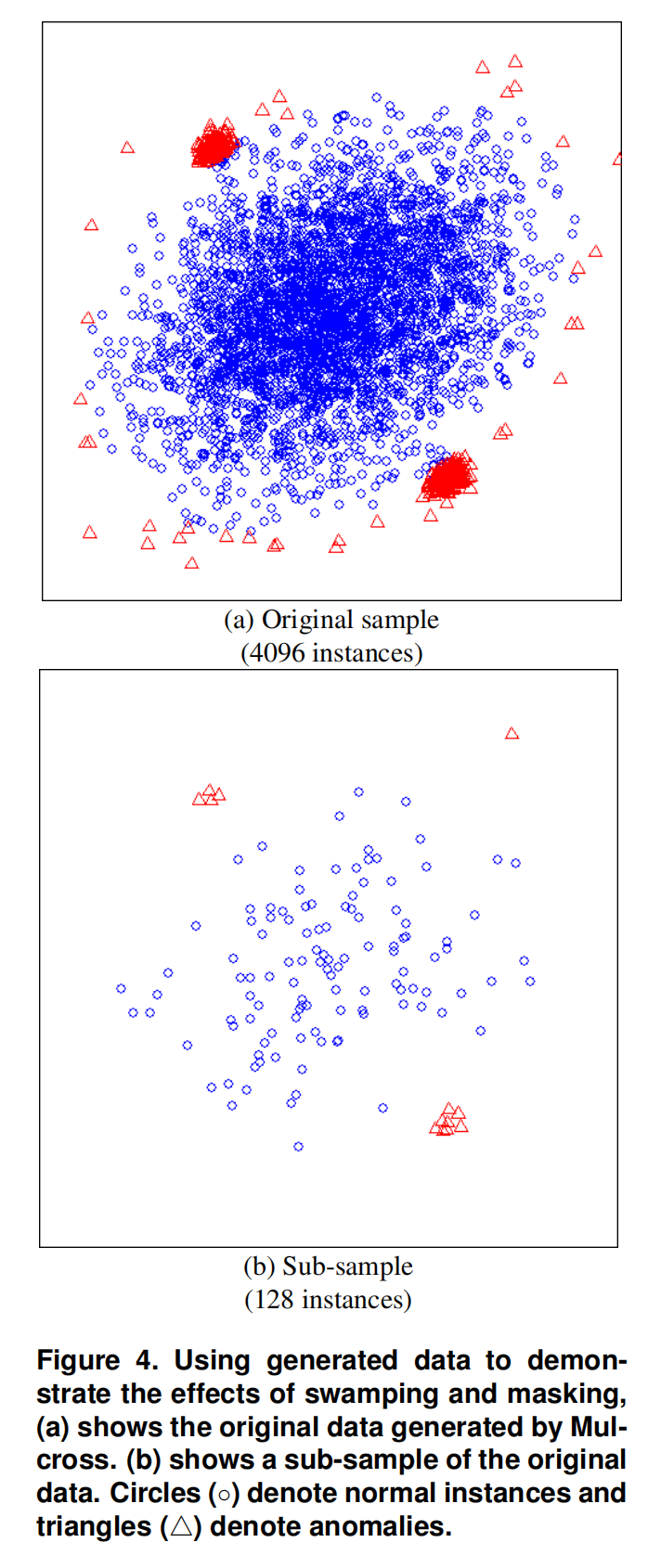
当使用整个样本时,iForest的AUC为0.67。当使用128的子采样大小时,iForest的AUC为0.91。
结果表明,通过显著减少的子样本,forest在处理swamping和masking效应方面具有优越的异常检测能力。
iFroest异常检测
训练阶段
树高限制根据采样的大小 \(\psi\) 自动选择 \(l=ceiling(log_2\psi)\),其数值与平均树高相近。将树高限制在平均树高的基本原理是:我们只对路径长度小于平均路径长度的数据点感兴趣,因为这些点更有可能是异常点。


子采样大小的选择
通常 \(\psi=256\)
当 \(\psi\) 增加到一个期望的值时,iForest可以可靠地检测,并且不需要进一步增加 \(\psi\) ,因为它增加了处理时间和内存大小,而检测性能没有任何提高。
树的个数 \(t\)
我们发现路径长度通常在t = 100之前收敛。
iForest训练的复杂性是\(O(t\psi log\psi)\)。
评估阶段
异常得分的计算在[第二节第四小节](###Anomaly Score)进行了描述,具体的伪代码描述如下图所示。
需要注意的是,当 \(x\) 位于叶子节点(external node)时,需要在原来路径长度的基础上增加调整项 \(C(Size)\)。该调整项说明了超出树高度限制的未构建子树。

评估过程的复杂性为\(O(ntlog\psi)\),其中 \(n\) 为测试数据的大小
实验评估
详细的内容需看原论文,这里只摘录一点重要的结论
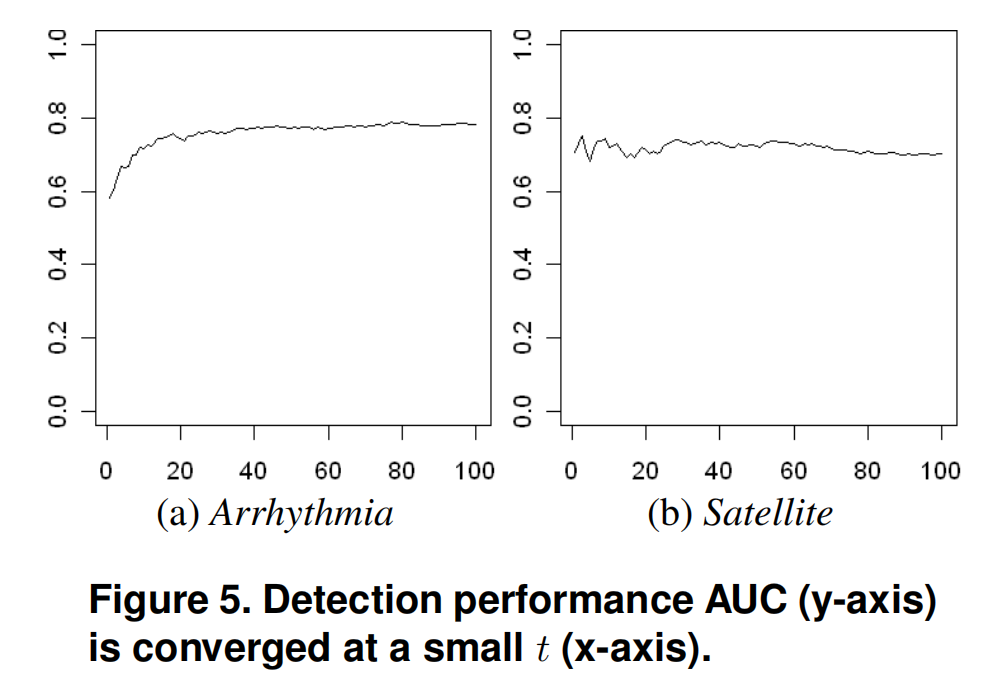
关于孤立树的个数 \(t\)
在较大的 \(t\) 范围内,iForest的性能是稳定的。使用两个最高维的数据集,图5显示AUC在 \(t\) 较小的时候就已经收敛。由于增加 \(t\) 也会增加处理时间,AUC的早期收敛表明,如果将 \(t\) 针对一个数据集进行调优,iForest的执行时间可以进一步缩短。
关于子采样 \(\psi\)
总而言之,\(\psi\) 值越小,AUC越高,处理时间越短,无需再增大 \(\psi\) 值。
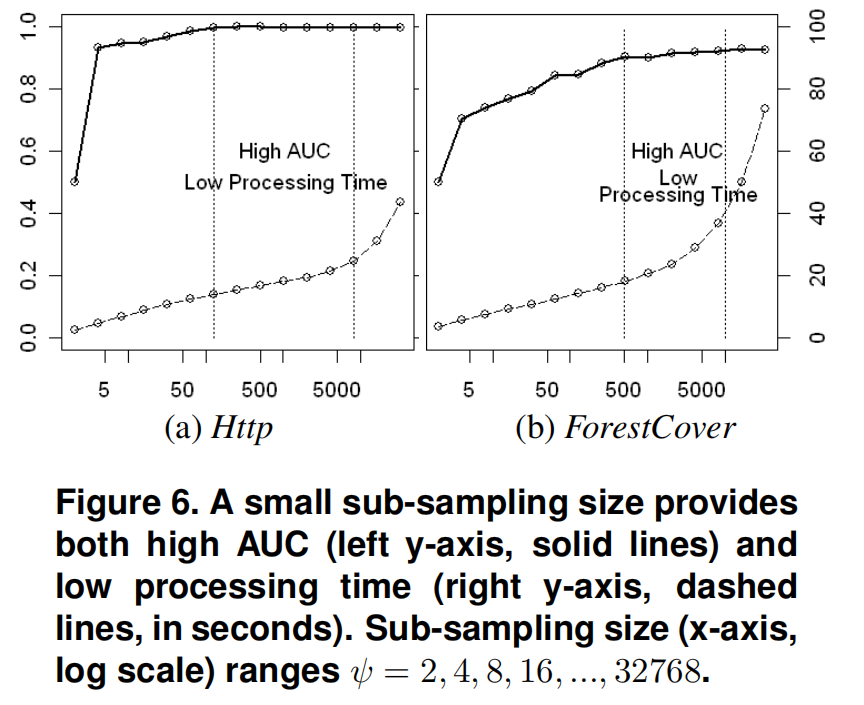
关于高维数据
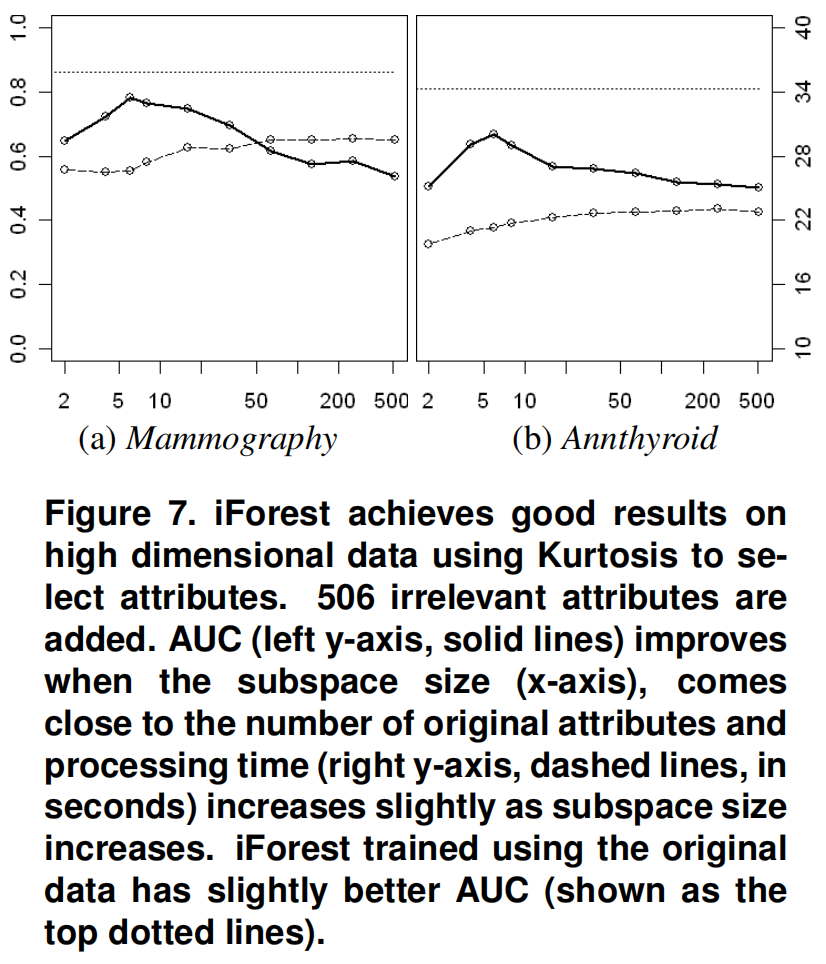
在构建每个iTree之前,我们使用峰度(Kurtosis)进行一个简单的统计检验,从子样本中选择一个属性子空间。峰度为每个属性提供了一个排序后,根据这个排序选择属性的子空间来构造每棵树。结果表明,当子空间大小接近原始属性数时,检测性能有所提高。
从图7可以看出
- 使用整个所有维度的处理时间都小于30秒
- 当子空间大小与原始属性数量相同时,AUC达到峰值
所以,iForest能够通过一个简单的添加峰度测试来提高检测性能。
关于只是使用正样本进行训练
当使用异常点和正常点进行训练时,Http报告AUC = 0.9997;而当训练仅使用正常点时,AUC降至0.9919。对于ForestCover, AUC从0.8817降低到0.8802。使用更大的子样本量可以帮助恢复检测性能。
论述
使用小样本的含义是,可以很容易地以最小的内存占用托管在线异常检测系统。
本文来自博客园,作者:Un-Defined,转载请保留本文署名Un-Defined,并在文章顶部注明原文链接:https://www.cnblogs.com/EIPsilly/p/16986003.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号