
[论文阅读] Anomaly detection - A survey
Anomaly detection - A survey
1. Introduction
1.1 What are anomalies?
Anomalies are patterns in data that do not conform to a well defined notion of normal behavior
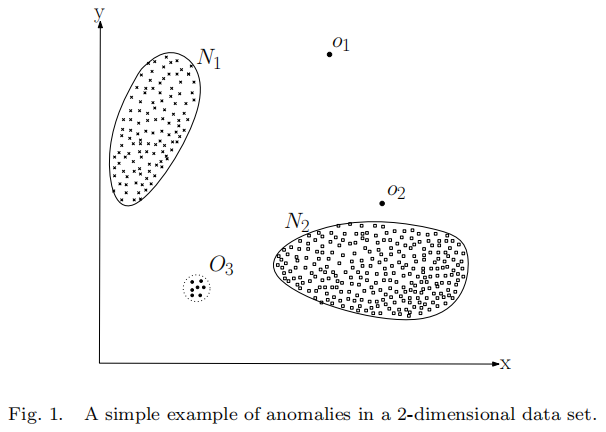
Anomaly detection is related to but distinct from noise removal and noise accommodation,both of which deal with unwanted noise in the data.
Another topic related to anomaly detection is novelty detection which aims at detecting previously unobserved patterns in the data, e.g. ,a new topic of discussion in a news group.
1.2 Challenges
- the boundary between normal and anomalous behavior is often not precise
- the malicious adversaries often adapt themselves to make the anomalous observations appear like normal
- normal behavior keeps evolving and the current notion of normal behavior might not be sufficiently representative in the future
- the exact notion of an anomaly is different for different application domains. Thus applying a technique developed in one domain to another is not straightforward
- Availability of labeled data for training/validation of models used by anomaly detection techniques is usually a major issue
- the data contains noise which tends to be similar to the actual anomalies and hence is diffcult to distinguish and remove
Most of the existing anomaly detection techniques solve a specific formulation of the problem. The formulation is induced by various factors such as nature of the data, availability of labeled data, type of anomalies to be detected, etc. These factors are determined by the application domain in which the anomalies need to be detected

2. Different Aspects of an anomaly detection problem
2.1 Nature of Input Data
The nature of attributes determine the applicability of anomaly detection techniques.
In general, data instances can be related to each other. Some examples are sequence data, spatial data, and graph data.
In sequence data, the data instances are linearly ordered, e.g., time-series data, genome sequences, protein sequences.
In spatial data, each data instance is related to its neighboring instances, e.g., vehicular traffiffiffic data, ecological data.
In graph data, data instances are represented as vertices in a graph and are connected to other vertices with edges.
2.2 Type of Anomomaly
2.2.1 Point Anomalies
If an individual data instance can be considered as anomalous with respect to the rest of data, then the instance is termed as a point anomaly.
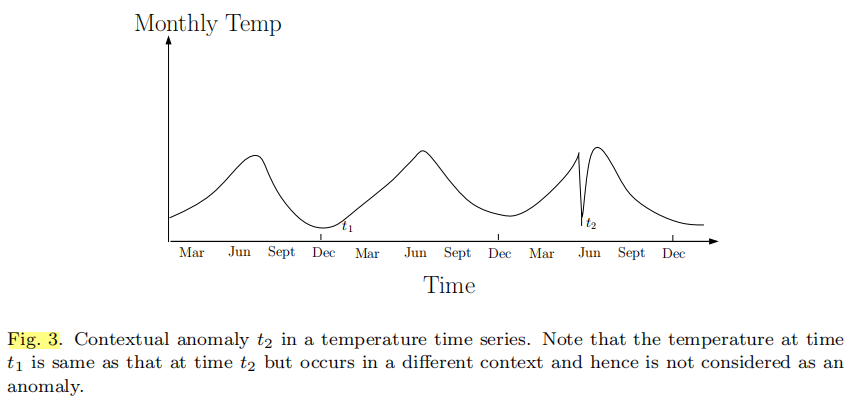
2.2.2 Contextual Anomalies
If a data instance is anomalous in a specific context (but not otherwise), then it is termed as a contextual anomaly (also referred to as conditional anomaly [Song et al. 2007]).
Each data instance is defined using following two sets of attributes:
- Contextual attributes. The contextual attributes are used to determine the context (or neighborhood) for that instance.
- Behavioral attributes. The behavioral attributes define the non-contextual characteristics of an instance.
The anomalous behavior is determined using the values for the behavioral attributes within a specific context. A data instance might be a contextual anomaly in a given context, but an identical data instance (in terms of behavioral attributes) could be considered normal in a different context.
2.2.3 Collective Anomalies.
If a collection of related data instances is anomalous with respect to the entire data set, it is termed as a collective anomaly.
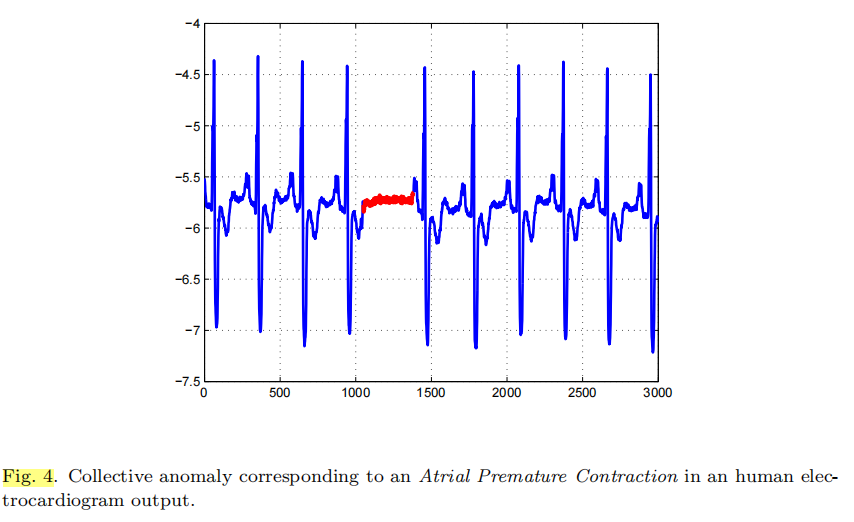
The individual data instances in a collective anomaly may not be anomalies by themselves, but their occurrence together as a collection is anomalous.
2.3 Data Labels
2.3.1 Supervised anomaly detection.
Training data set has labeled instances for normal as well as anomaly class
There are two major issues that arise in supervised anomaly detection.
First, the anomalous instances are far fewer compared to the normal instances in the training data. Issues that arise due to imbalanced class distributions have been addressed in the data mining and machine learning literature [Joshi et al. 2001; 2002; Chawla et al. 2004; Phua et al. 2004; Weiss and Hirsh 1998; Vilalta and Ma 2002]
Second, obtaining accurate and representative labels, especially for the anomaly class is usually challenging.
2.3.2 Semi-Supervised anomaly detection.
Training data has labeled instances for only the normal class.
The typical approach used in such techniques is to build a model for the class corresponding to normal behavior, and use the model to identify anomalies in the test data.
2.3.3 Unsupervised anomaly detection.
Do not require training data, and thus are most widely applicable.
The techniques in this category make the implicit assumption that normal instances are far more frequent than anomalies in the test data
2.4 Output of Anomaly Detection
2.4.1 Scores.
Assign an anomaly score to each instance in the test data depending on the degree to which that instance is considered an anomaly.
2.4.2 Labels.
Assign a label (normal or anomalous) to each test instance.
3. Applications of anomaly detection
In this section we discuss several applications of anomaly detection. For each application domain we discuss the following four aspects:
- The notion of anomaly.
- Nature of the data.
- Challenges associated with detecting anomalies.
- Existing anomaly detection techniques.
3.1 Intrusion Detection
Intrusion detection refers to detection of malicious activity (break-ins, penetrations, and other forms of computer abuse) in a computer related system [Phoha 2002]
The key challenge for anomaly detection in this domain is the huge volume of data. Moreover the data typically comes in a streaming fashion, thereby requiring on-line analysis.
Another issue which arises because of the large sized input is the false alarm rate. Since the data amounts to millions of data objects,a few percent of false alarms can make analysis overwhelming for an analyst.
3.1.1 Host Based Intrusion Detection Systems.
The intrusions are in the form of anomalous subsequences (collective anomalies) of the traces.
Anomaly detection techniques applied for host based intrusion detection are required to to handle the sequential nature of data. The techniques have to either model the sequence data or compute similarity between sequences.
3.1.2 Network Intrusion Detection Systems
These systems deal with detecting intrusions in network data.
The intrusions typically occur as anomalous patterns (point anomalies) though certain techniques model the data in a sequential fashion and detect anomalous subsequences (collective anomalies) [Gwadera et al. 2005b; 2004].
The data available for intrusion detection systems can be at different levels of granularity, e.g., packet level traces, CISCO net-flows data, etc. It has a temporal aspect associated with it,but most of the techniques typically do not handle the sequential aspect explicitly. The data is high dimensional typically with a mix of categorical as well as continuous attributes.
A challenge faced by anomaly detection techniques in this domain is that the nature of anomalies keeps changing over time as the intruders adapt their network attacks to evade the existing intrusion detection solutions
3.2 Fraud Detection
Fraud detection refers to detection of criminal activities occurring in commercial organizations such as banks, credit card companies, insurance agencies, cell phone companies, stock market, etc.
The organizations are interested in immediate detection of such frauds to prevent economic losses.
Fawcett and Provost [1999] introduce the term activity monitoring as a general approach to fraud detection in these domains. The typical approach of anomaly detection techniques is to maintain a usage profile for each customer and monitor the profifiles to detect any deviations
3.2.1 Credit Card Fraud Detection
The data typically comprises of records defined over several dimensions such as the user ID, amount spent, time between consecutive card usage, etc.
The credit companies have complete data available and also have labeled records. Moreover, the data falls into distinct profiles based on the credit card user. Hence profiling and clustering based techniques are typically used in this domain
It requires online detection of fraud as soon as the fraudulent transaction takes place.
Two different ways to address this problem:
- The first one is known as by-owner in which each credit card user is profiled based on his/her credit card usage history
- Another approach known as by-operation detects anomalies from among transactions taking place at a specific geographic location.
Both by-user and by-operation techniques detect contextual anomalies
3.2.2 Mobile Phone Fraud Detection
Mobile/cellular fraud detection is a typical activity monitoring problem.
The task is to scan a large set of accounts,examining the calling behavior of each, and to issue an alarm when an account appears to have been misused.
Calling activity is usually described with call records. Each call record is a vector of features, both continuous (e.g., CALL-DURATION) and discrete (e.g., CALLING-CITY)
The anomalies correspond to high volume of calls or calls made to unlikely destinations
3.2.3 Insurance Claim Fraud Detection.
Individuals and conspiratorial rings of claimants and providers manipulate the claim processing system for unauthorized and illegal claims.
The available data in this domain are the documents submitted by the claimants. The techniques extract different features (both categorical as well as continuous)from these documents.
Insurance claim fraud detection is quite often handled as a generic activity monitoring problem [Fawcett and Provost 1999].
3.2.4 Insider Trading Detection
Insider trading is a phenomenon found in stock markets, where people make illegal profits by acting on
(or leaking) inside information before the information is made public.
The available data is from several heterogenous sources such as option trading data, stock trading data, news.
The temporal and streaming nature has also been exploited in certain techniques [Aggarwal 2005].
Anomaly detection techniques in this domain are required to detect fraud in an online manner and as early as possible, to prevent people/organizations from making illegal profifits
3.3 Medical and Public Health Anomaly Detection
3.4 Industrial Damage Detection
3.4.1 Fault Detection in Mechanical Units
3.4.2 Structural Defect Detection.
3.5 Image Processing
3.6 Anomaly Detection in Text Data
3.7 Sensor Networks
3.8 Other Domains
4. Classification Based anomaly detection techniques
Classification [Tan et al. 2005; Duda et al. 2000] is used to learn a model (classifier) from a set of labeled data instances (training) and then, classify a test instance into one of the classes using the learnt model (testing)
4.1 Neural Networks Based
本文来自博客园,作者:Un-Defined,转载请保留本文署名Un-Defined,并在文章顶部注明原文链接:https://www.cnblogs.com/EIPsilly/p/16694372.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号