
[论文阅读] Constructing Narrative Event Evolutionary Graph for Script Event Prediction
Constructing Narrative Event Evolutionary Graph for Script Event Prediction
Abstract
脚本事件预测需要一个模型来预测给定现有事件上下文的后续事件。以往基于事件对或事件链的模型不能充分利用密集的事件连接,这限制了它们的事件预测能力。为了解决这一问题,我们提出构建一个事件图来更好地利用事件网络信息进行脚本事件预测。具体来说,我们首先从大量的新闻语料库中提取叙事事件链,然后在此基础上构建叙事事件进化图(narrative event evolutionary graph , NEEG)。NEEG可以被看作是描述事件进化原理和模式的知识库。为了解决NEEG上的推理问题,我们提出了一个缩放图神经网络( scaled graph neural network , SGNN)来建模事件交互并学习更好的事件表示。SGNN不是在整个图上计算表示,而是每次只处理相关的节点,这使得我们的模型适用于大规模的图。通过比较输入上下文事件表示与候选事件表示之间的相似性,我们可以选择最合理的后续事件。在广泛使用的《纽约时报》语料库上的实验结果表明,我们的模型使用标准的多项选择叙事完形评价方法,显著优于目前最先进的基线方法。
1 Introduction
脚本事件预测:给定一个事件的上下文,需要从候选列表中选出最合适的后续事件
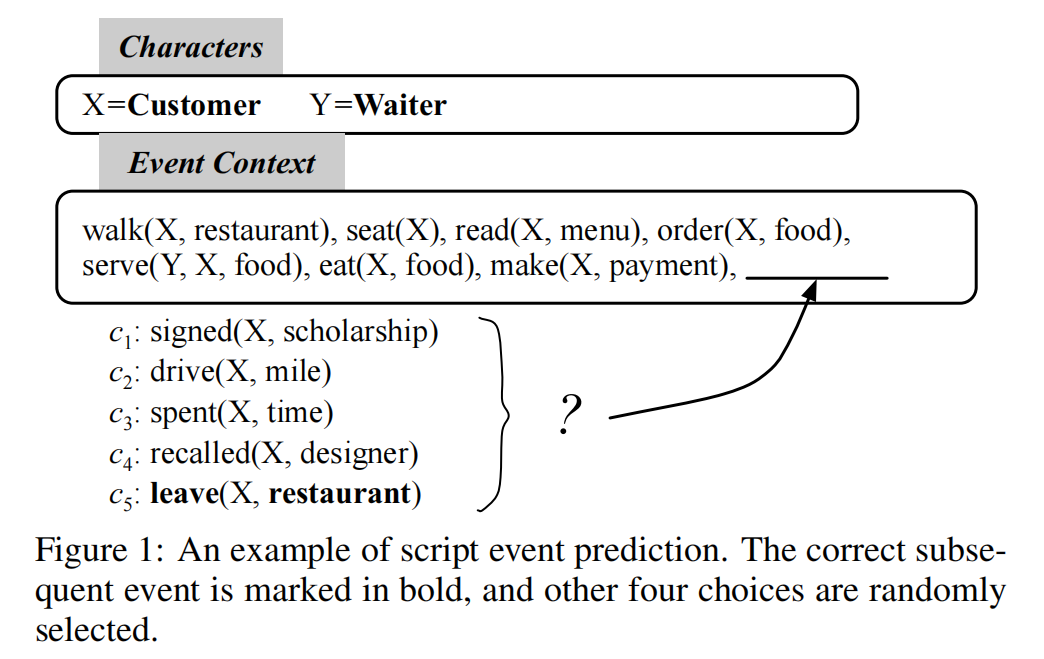
先前关于建立预测模型的研究都是基于事件对或者事件链,虽然也获得了成功,但是事件之间丰富的联系并没有被完全开发。为了更好地建模事件连接,我们提出解决基于事件图结构的脚本事件预测问题,并基于网络嵌入推断出正确的后续事件
给定一个事件上下文A(enter),B(order),C(serve),我们需要从候选列表D(eat),E(talk)中选出最合理的后续事件,其中D(eat)是正确的但,E(talk)是随机选择的候选事件,在各种场景中经常发生。
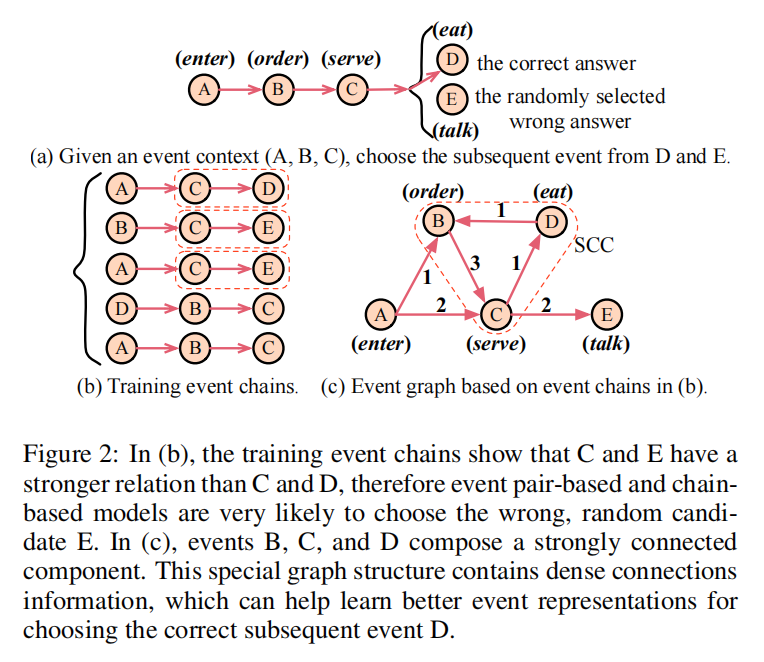
- 在事件链数据集上训练的基于事件对的模型和基于事件链的模型(如图2(b)所示)很可能会选择错误的答案E,因为训练数据表明C和E比C和D有更强的关系。
- 如图2(c)所示,通过基于训练事件链构建事件图,上下文事件B、C和候选事件D构成了一个强连接组件,这表明给定上下文事件A、B、C时,D是一个更合理的后续事件
EEG在结构上是一种有向循环图,节点是事件,边代表事件之间的关系,如时间关系和因果关系。本文基于叙事事件链构造了一个事件进化图,称为叙事事件进化图(narrative event evolutionary graph , NEEG)。有了NEEG,另一个具有挑战性的问题是如何推断图表上的后续事件。一个可能的解决方案是学习基于网络嵌入的事件表示。
在本文中,我们进一步扩展了Li等人[2015]的工作,提出了一种缩放图神经网络(scale graph neural network, SGNN),它适用于大规模图。在训练过程中,我们借用了分治的思想,SGNN每次只处理相关节点,而不是计算整个图的表示。通过对比从SGNN学习到的上下文事件表示和候选事件表示,我们可以选择正确的后续事件。
本文的两大贡献
- 我们是第一个提出构建事件图而不是事件对和事件链的脚本事件预测任务
- 我们提出了一种缩放图神经网络,它可以在大规模密集有向图上建模事件交互,并学习更好的事件表示来进行预测。
2 Model
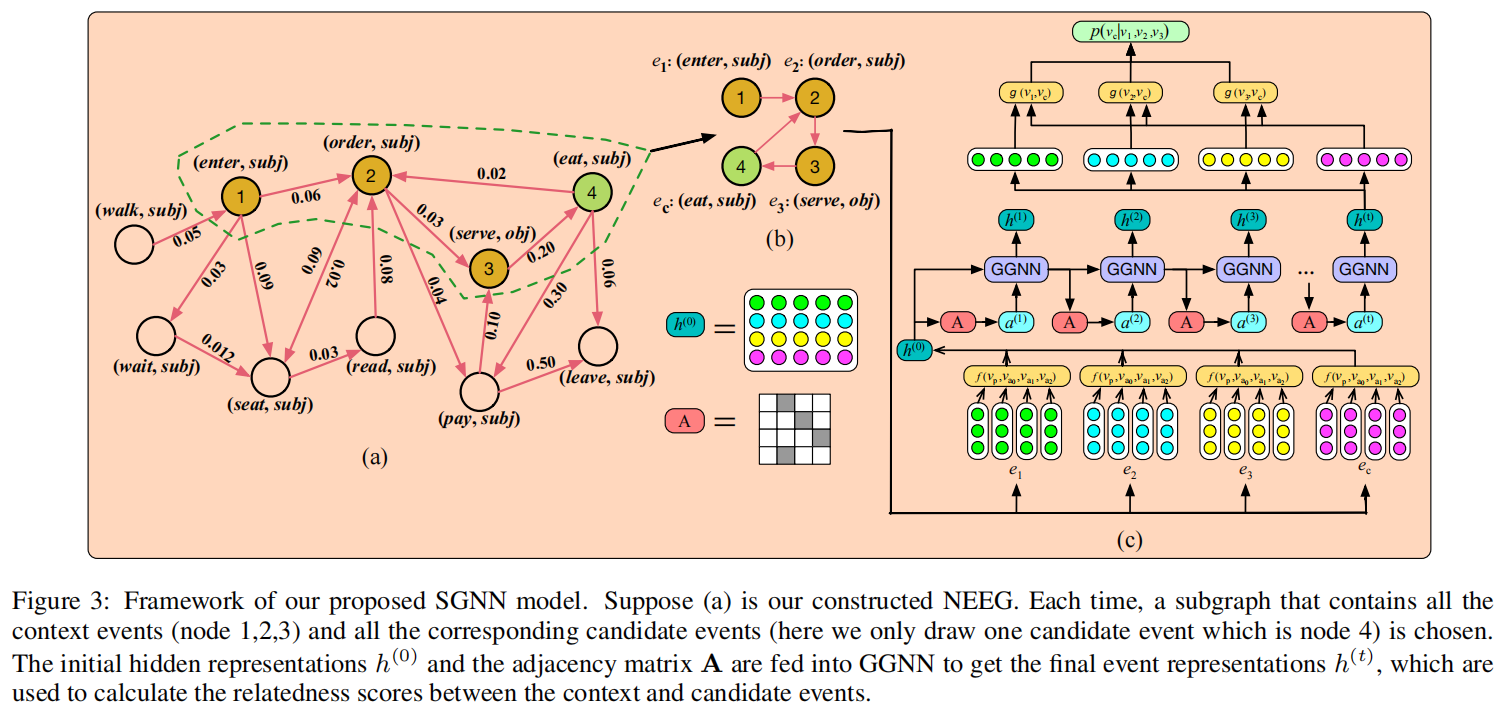
如图3所示,我们的模型包括两个步骤。第一步是构建一个基于叙事事件链的事件进化图。其次,我们提出了一个缩放图神经网络来解决所构造的事件图上的推理问题。
2.1 Narrative Event Evolutionary Graph Construction
NEEG的构建包括两个步骤
- 从新闻专线语料库中提取叙事事件链
- 基于提取的事件链构建NEEG。
为了与之前的工作进行比较,我们采用了与[格兰罗斯-怀尔丁和Clark,2016]相同的新闻语料库和事件链提取方法
我们提取了一组叙事事件链\(S=\{s_1,s_2,s_3,\dots,s_n\}\),其中\(s_i=\{T,e_1,e_2,e_3,\dots,e_n\}\)。例如\(s_i\)可以是\(\{ T = customer, walk(T, restaurant, -), seat(T, -, -), read(T, menu, -), order(T, food, -), serve(waiter, food, T), eat(T, food, fork)\}\)。\(T\)是该链中所有事件共享的主语,\(e_i\)是一个四元组\(\{p(a_0,a_1,a_2)\}\),其中p是谓词,\(a_0,a_1,a_2\)分别是动词的主语、宾语和间接宾语。
NEEG可以表示为\(G=\{V,E\}\),其中\(V=\{v_1,v_2,v_3,\dots,v_P\}\)为节点集,\(E=\{l_1,l_2,l_3,\dots,l_Q\}\)为边集。为了克服事件的稀疏性问题,我们用事件的抽象形式\((v_i,r_i)\)来表示事件,其中\(v_i\)用一个未还原的谓词表示,\(r_i\)是\(v_i\)与链主体\(T\)的语法依赖关系,例如\(e_i=(eats,subj)\)。这种事件表示被称为predicate-GR[Granroth-Wilding and Clark, 2016]。我们计算训练事件链中的所有predicate-GR双元组,并将每个predicate-GR当做\(E\)中的一条边\(l_i\)。每个\(l_i\)都是一个\(v_i\rightarrow v_j\)的有向边,带有权值\(w\),\(w\)计算方式如下。
其中\(count(v_i,v_j)\)是双元组\((v_i,v_j)\)在训练事件链中出现的频率
构建的NEEG有104,940个predicate-GR节点,6,187,046条有向加权边。图3(a)说明了G中的一个局部子图,它描述了餐厅场景中可能涉及的事件。事件图不像事件对或事件链,事件图具有事件之间紧密的联系,包含了更丰富的事件交互信息。
2.2 Scaled Graph Neural Network
为了缩放到大尺度图,我们在训练过程中借鉴了分治的思想,即我们不将整个图输入GGNN。相反,对于每个训练实例,只有一个包含上下文和候选事件节点的子图(如图3(b)所示)输入其中。最后,学习到的节点表示可以用来解决图上的推理问题。
如图3(c)所示,SGNN的整体框架有三个主要组件。第一部分是一个表示层,用于学习初始事件表示。第二部分是门控图神经网络,用于建模事件之间的交互作用,并更新初始事件表示。第三部分用于计算上下文和候选事件之间的关联得分,根据它,我们可以选择正确的后续事件。
Learning Initial Event Representations
我们通过对其动词和参数预先训练好的单词嵌入来进行组合来学习初始事件表示。对于由多个单词组成的参数,我们遵循[Granroth-Wilding and Clark, 2016],并且只使用由解析器标识的头词。词汇量外的单词和没有词汇量的参数用零向量表示。
给定一个事件\(e_i=\{p(a_0,a_1,a_2)\}\),其动词和参数的词嵌入为\(v_p,v_{a_0},v_{a_1},v_{a_2}\in \mathbb{R}^d\),其中\(d\)是词嵌入的维度。通过映射函数\(v_{e_i}=f(v_p,v_0,v_{a_1},v_{a_2})\),又多种方式获得整个事件\(v{e_i}\)的表示。这里,我们介绍三种广泛使用的语义成分的方法
- Average:使用动词和所有参数向量的平均值作为整个事件的代表
- Nonlinear Transformation [Wang et al., 2017]:\(v_e=tanh(W_p \cdot v_p+W_0 \cdot v_{a_0} + W_1 \cdot v_{a_1} + W_2 \cdot v_{a_2} + b)\)
- Concatenation:连接动词和所有参数向量作为整个事件的表示。
Updating Event Representations Based on GGNN
对GGNN的输入是两个参数,矩阵\(h^{(0)}\)和A。\(h^{(0)}={v_{e_1},v_{e_2},...,v_{e_n},v_{e_{c_1}},v_{e_{c_2}},...,v_{e_{c_k}}}\),包含初始上下文和候选事件向量。\(A\in \mathbb{R}^{(n+k)\times(n+k)}\),对应于子图的邻接矩阵
邻接矩阵A决定了子图中的节点如何相互交互。GGNN的基本循环是:
GGNN的行为类似于广泛使用的门控循环单元(GRU)[Cho et al., 2014]。等式(4) 是通过有向邻接矩阵A在图的不同节点之间传递信息的步骤。\(a^{(t)}\)包含来自边的激活。其余的是类似GRU的更新,它包含来自其他节点和上一个时间步的信息来更新每个节点的隐藏状态。\(z^{(t)}\)和\(r^{(t)}\)是更新和重置门,\(\sigma\)是sigmoid函数,\(\odot\)是哈达玛积。我们以固定数量的步骤k展开上述循环传播。GGNN的输出\(h^{(t)}\)可以用作上下文和候选事件的更新表示。
Choosing the Correct Subsequent Event
在获取每个事件的隐藏状态后,利用这些隐藏状态向量对事件对关系进行建模。为两个事件之间的关系建模的一种直接方法是使用Siamese网络[Granroth-Wilding和Clark, 2016]。上下文事件的GGNN输出为\(h^{(t)}_1,h^{(t)}_2,\dots,h^{(t)}_n\),对于候选事件是\(h^{(t)}_{c_1},h^{(t)}_{c_2},\dots,h^{(t)}_{c_k}\)。给定一对事件\(h_i^{(t)}(i\in[1\dots n])\)和\(h^{(t)}_{c_j}(j\in [1,\dots,k])\),关联度得分由\(sij=g(h^{(t)}_i,h^{(t)}_{c_j})\)计算,其中g为得分函数。
在我们的模型中,分数函数\(g\)有多个选择。在这里,我们将介绍四个常用的相似度计算度量
- Manhattan Similarity:曼哈顿距离 \(manhattan(h_i^{(t)},h_{c_j}^{(t)})=\sum|h_i^{(t)}-h_{c_j}^{(t)}|\)
- Cosine Similarity:余弦距离 \(cosine(h_i^{(t)},h_{c_j}^{(t)})=\frac{h_i^{(t)}\cdot h_{c_j}^{(t)}}{\left \| h_i^{(t)} \right \| \left \| h_{c_j}^{(t)}\right\|}\)
- Dot Similarity:点积距离 \(dot(h_i^{(t)},h_{c_j}^{(t)})=h_i^{(t)}\cdot h_{c_j}^{(t)}\)
- Euclidean Similarity:欧几里得距离 \(euclid(h_i^{(t)},h_{c_j}^{(t)})=\left\|h_i^{(t)}-h_{c_j}^{(t)}\right\|\)
给定每个上下文事件\(h_i^{(t)}\)和每个后续候选事件\(h^{(t)}_{c_j}\)之间的相关性得分\(s_{ij}\),给定\(e_1,e_2,\dots,e_n\),\(e_{cj}\)的可能性可以计算为\(s_j=\frac{1}{n}\sum^n_{i=1}s_{ij}\),然后我们通过\(c=max_js_j\)选择正确的后续事件。
我们还将注意机制[Bahdanau et al.,2014] 应用于上下文事件,因为我们认为不同的上下文事件在选择正确的后续事件时可能具有不同的权重。我们使用一个注意神经网络,根据后续的事件候选项计算每个上下文事件的相对重要性:
关联度得分计算方式如下:
Training Details
所有的超参数都在开发集上进行了调整,我们使用边际损失(margin loss)作为目标函数:
其中,\(s_{Ij}\)是第 \(I\) 个事件上下文与对应的第 \(j\) 个后续候选事件之间的关联得分,\(y\) 是正确的后续事件的索引。\(margin\)为 margin loss 函数的参数,设置为0.015。\(\Theta\)是模型的参数集合。\(\lambda\) 是L2正则化的参数,设置为0.00001。学习率为0.0001,批量大小为1000,循环次数K为2
我们使用DeepWalk算法[Perozzi et al., 2014]在构建的NEEG上训练predicate-GR的嵌入(我们发现在图上从DeepWalk训练的嵌入比在事件链上训练的Word2vec更好),并使用Skipgram算法 [Mikolov et al., 2013]训练事件链上参数\(a_0,a_1,a_2\)的嵌入。嵌入维数 \(d\) 为128。采用RMSprop算法对模型参数进行了优化。早期停止是用来判断何时停止训练循环的。
3 Evaluation
我们评估了SGNN的有效性,并比较了几种最先进的基线方法。选择正确的后续事件的准确性(%)作为评估指标
3.1 Baselines
- PMI [Chambers and Jurafsky, 2008] 是一个基于共存的模型,它基于Pairwise Mutual Information计算predicate-GR事件对关系
- Bigram [Jans et al., 2012] 是一种基于计数的skipgrams模型,它基于Bigram概率计算事件对关系。
- Word2vec [Mikolov et al., 2013] 是一种被广泛使用的模型,它可以从大规模的文本语料库中学习单词嵌入。动词和参数的学习嵌入被用于计算事件对相关性得分。
- DeepWalk [Perozzi et al., 2014] 是一个无监督模型,它扩展了word2vec算法来学习网络的嵌入。
- EventComp [Granroth-Wilding and Clark, 2016] 是一种神经网络模型,它同时学习事件动词和参数的嵌入,一个将嵌入组合到事件表示中的函数,以及一个预测两个事件之间关联强度的相干函数(coherence function)。
- PairLSTM [Wang et al., 2017] 是通过使用LSTM隐藏状态作为事件表示来计算成对事件关联得分,将事件顺序信息和成对事件关系集成在一起的模型
3.2 Dataset
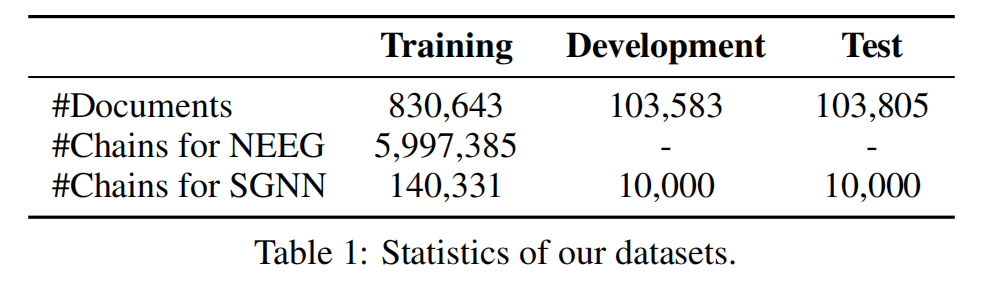
继Granroth-Wilding and Clark [2016]之后,我们从Gigaword语料库的《纽约时报》部分提取了事件链。C&C工具[Curran et al., 2007] 用于POS标记和依赖关系解析,OpenNLP用于短语结构解析和共引用解析。每个事件上下文有5个候选的后续事件,其中只有一个是正确的。详细的数据集统计数据如表1所示。
4 Results and Analysis
4.1 Overall Results
实验结果如表2所示。
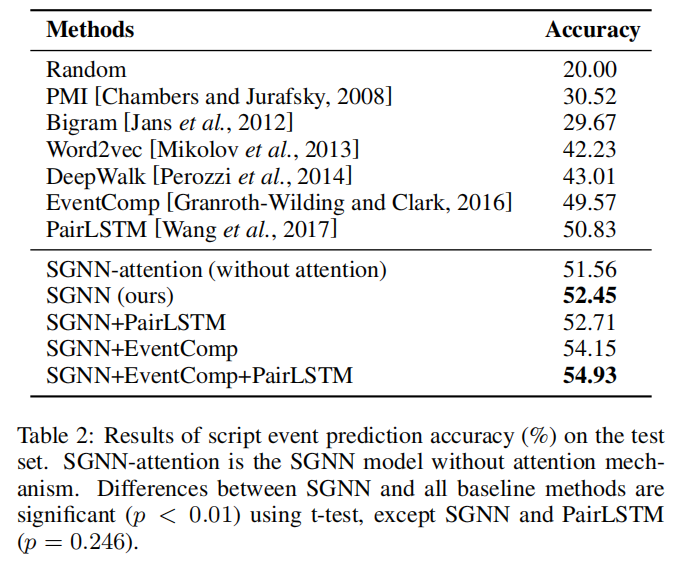
- Word2vec、DeepWalk和其他基于神经网络的模型(EventComp、PairLSTM、SGNN)比基于计数的PMI和Bigram模型取得了明显更好的结果。其主要原因是,对于脚本事件预测,学习事件的低维密集嵌入比稀疏特征表示更有效。
- 对“Word2vec”和“DeepWalk”以及“EventComp , PairLSTM”和“SGNN”的比较表明,基于图的模型比基于对和基于链的模型具有更好的性能。这证实了我们的假设,即事件图结构比事件对和链更有效,并且可以为脚本事件预测提供更丰富的事件交互信息。
- “SGNN-attention”和“SGNN”的比较表明,注意机制可以有效提高SGNN的性能。这说明不同的上下文事件对于选择正确的后续事件具有不同的意义。
- SGNN的最佳脚本事件预测性能为52.45%,比最佳基线模型(PairLSTM)提高了3.2%。
我们还实验了不同模型的组合,以观察不同的模型之间是否存在互补效应。我们发现,SGNN+EventComp将SGNN的性能从52.45%提高到了54.15%。这表明他们可以从彼此中受益。然而,SGNN+PairLSTM只能将SGNN的性能从52.45%提高到52.71%。这是因为SGNN和PairLSTM之间的差异并不显著,这表明它们可能学习类似的事件表征,但SGNN学习的方式更好。SGNN、EventComp和PairLSTM组合的最佳性能为54.93%。这主要是因为对结构、链结构和图结构各有各自的优点,它们可以相互补充。
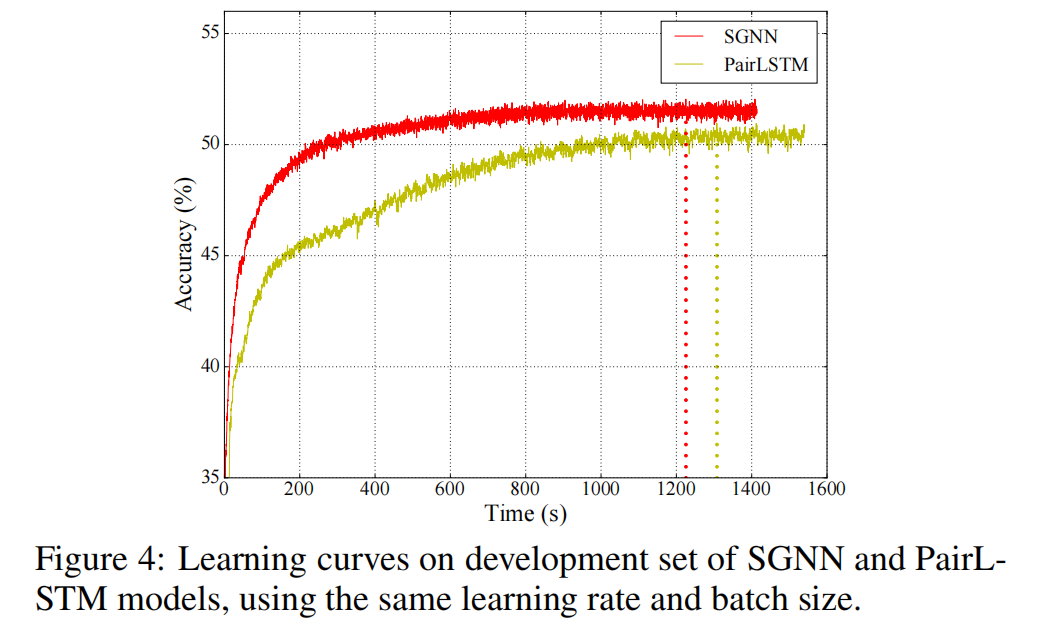
SGNN和PairLSTM的学习曲线(精度随时间的变化)如图4所示。我们发现SGNN快速达到稳定的高精度,从头到尾优于PairLSTM。这说明了SGNN相对于PairLSTM模型的优势。
4.2 Comparative Experiments
我们对开发设置进行了几个比较实验,以研究不同设置对SGNN的影响。
Experiment with Different Event Semantic Composition Methods
我们比较了在第2.2.1节中介绍的三种事件语义组合方法。实验结果如表3所示。
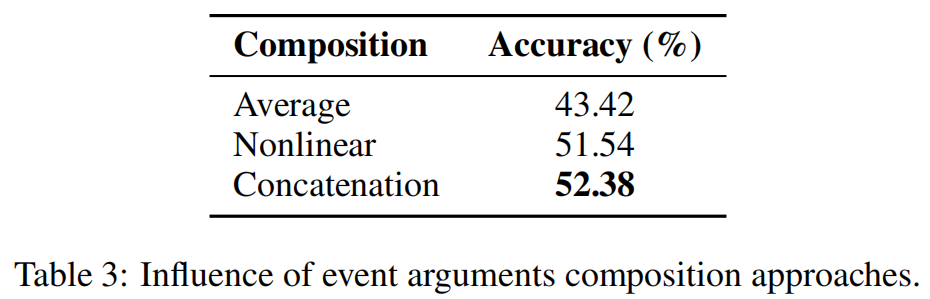
我们发现,连接动词和参数向量的嵌入可以获得最好的性能。而平均输入向量是得到表示ve的最差的方法。主要原因是许多事件没有间接对象\(a_2\),这可能会损害平均操作的性能。
Experiment with Different Score Functions
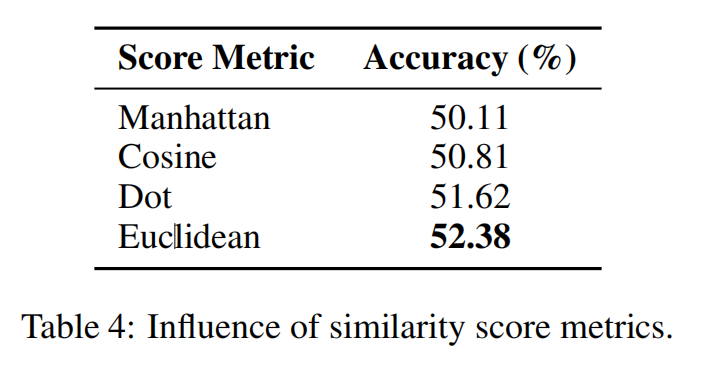
我们比较了在第2.2.3节中介绍的几个常用的相似度评分指标 \(g\),以调查它们对性能的影响。如表4所示,我们发现不同的分数指标确实对性能有不同的影响,尽管它们之间的差距并不是很大。欧几里得得分度量达到最佳结果,这与之前使用单词嵌入计算文档距离的研究结果一致[Kusneretal.,2015]。
5 Related Work
5.1 Statistical Script Learning
5.2 Neural Network on Graphs
5.3 Graph-based Organization of Events
6 Conclusion
本文提出构造事件图来解决基于网络嵌入的脚本事件预测问题。特别是,为了更好地利用事件之间密集的连接信息,我们基于提取的叙事事件链构建了叙事事件进化图(narrative event evolutionary graph , NEEG)。为了解决NEEG上的推理问题,我们提出了一个缩放图神经网络(scaled graph neural network , SGNN)来建模事件交互,并学习更好的事件表示,以选择正确的后续事件。实验结果表明,事件图结构比事件对和事件链更有效,可以显著提高预测性能,使模型具有鲁棒性
本文来自博客园,作者:Un-Defined,转载请保留本文署名Un-Defined,并在文章顶部注明原文链接:https://www.cnblogs.com/EIPsilly/p/15870736.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号