
[论文阅读] The Event StoryLine Corpus:A New Benchmark for Causal and Temporal Relation Extraction
有点没太看懂这篇写了什么,只知道弄了一个语料库,具体什么样可能结合具体语料库看会比较清楚,单看论文已经折磨死我了orz
和这篇文章相关的一些资料:https://github.com/cltl/EventStoryLine.git
The Event StoryLine Corpus: A New Benchmark for Causal and Temporal Relation Extraction
Abstract
本文报道了事件故事语料库(ESC) v0.9,一个新的时间和因果关系检测基准数据集。通过开发这个数据集,我们还引入了一项新任务,即从新闻数据中提取故事情节,该任务旨在从跨时间传播的、围绕单个重要事件或主题聚集的新闻文档中提取与故事相关的事件并对其进行分类。除了描述数据集之外,我们还报告了三个基线系统,它们的结果显示了任务的复杂性,并建议了开发更健壮系统的方向。
1 Introduction
目前的自然语言处理系统可以识别复杂的信息,但它们缺乏将其连接成一个统一和一致的信息的方法
从开始到结束监控一个新闻故事是一项具有挑战性的任务,它要求系统能够:
- 1)协调可及时分发的来自不同来源的信息
- 2)解决信息重复数据删除问题;
- 3)提取信息语义结构
本文介绍了诸如资源:Event StoryLine Corpus v0.9,它是专门为评估旨在重建以事件为中心的情节结构的系统而设计的。
本文其余部分的结构如下:
- 第2节将解释注释方案,描述Event StoryLines Corpus (ESC) v0.9的注释层,并在一致性度量中报告
- 第3节将描述与故事线提取(StoryLine Extraction)任务的基线开发相关的实验。
- 在第4节中,我们回顾了以前的注释计划,展示了它们与ESC数据之间的差异和共性。
- 最后,在第5节中报告了结论和未来的工作。
2 The Event StoryLine Corpus v0.9
引言
-
ESCv0.9数据集的主要目标是为以事件为中心的故事线提取任务提供一个内在的评估基准。该任务可以被描述为三个基本子任务的组合:
-
事件检测与分类(Event Detection and Classification)
- 识别和分类组成一个主题或一个重要事件的每个文档中的事件;
-
事件事件锚定(Temporal Anchoring of Events)
- 将每个事件锚定到表示其发生时间的时间表达式,以及文档创建时间(DCT);
-
解释关系的识别与分类(Explanatory Relation Identification and Classification)
- 选择在时间上和逻辑上有联系的事件对,然后对故事关系类型进行分类。
-
-
故事情节关系可以被描述为一对事件之间的松散因果关系和时间关系,其中一个事件解释/证明了另一个事件(更多细节见章节2.3)。关系可以分为 上升作用(rising action) 和 下降作用(falling action)。
-
另一个任务是事件协同引用解决(Event Co-reference Resolution),它旨在识别在文档内部和跨文档级别事件的共同引用链。这些信息的可用性允许我们通过创建事件实例(event instances)来删除事件的重复信息,即符合RDF的正式语义表示,可以将语言信息与外部资源集成,从而允许推理(Fokkens等人,2013)。在下面的章节中,我们将说明ESC注释方案(ESC Annotation Scheme)及其注释框架的组件。
2.1 Basic Components: Events and Temporal Expressions
事件
-
具体来说,一个事件是任何准时的、持续的或静止的情况,它的发生或保持,是由四个组成部分的组合产生的,例如:
- 1)指发生或保持的动作组件;
- 2)负责在时间上锚定动作的时隙
- 3)一个位置组件,将动作组件链接到一个位置/位置;
- 4)参与者组成部分,它说明了行动组成部分所涉及的“谁”或“什么”。
-
ECB+中对事件程度的注释遵循TimeML中采用的解决方案。这意味着对于每一个事件,不管它的词性,只有承载动作意义的词汇项被注释。这通常对应于实现动作组件的短语的头部,即最小块,如下例所示。
-
- This terrible [war] could have [ended] in
a month
- This terrible [war] could have [ended] in
-
-
然而,这条规则也有例外。采用以事件为中心的注释框架,并不总是保持对文本表面的依附。例如,可以用专有名词引用的具有重大历史意义的事件,如第二次世界大战、美国内战,会用一个独特的动作组件标签进行注释。类似地,由于注释也主要关注于事件的共同引用,当事件的前置修饰符有助于识别唯一的事件实例时,可以在动作组件标签中包含事件的前置修饰符:
- [6.1-magnitude quake] strikes Indonesia’s Aceh.
-
此外,ECB+允许将修饰符位置上的现在和过去分词注释为事件:
- The [earthquake] . . . left hundred trapped in [collapsed] buildings.
-
每个动作组件被划分为属于七个可能的类-中的一个。其中的五个, ACTION_OCCURRENCE,ACTION_ASPECTUAL,ACTION_REPORTING,ACTION_STATE,还有ACTION_PERCEPTION,都是TimeML类的镜像。另外两个类,ACTION_CAUSATIVE和ACTION_GENERIC,已经被引入来注释表达因果关系的事件,以及不固定于特定时间和地点的表达通用行为的事件(即事件的真实性独立于特定的话语时刻)。
时间表达式
-
时间表达式从TimeML继承并标记遵循TIMEX3注释准则。为了与TIMEX3的TimeML注释相兼容,我们修改了原来的ECB+注释指南:,
- 1)使用TIMEX3标签来注释时态表达式
- 2)重新引入type属性作为时态表达式标签的一部分;
- 3)重新引入value属性值,实现时态表达式的规范化。
-
我们还允许创建空的TIMEX3标签,即,对应于隐式的非文本消费时间表达式标记,即没有在文本中实现,表示持续时间的时间表达式的开始和/或结束点。除此之外,作为动作组件描述的一部分被包含在动作标签中的时态表达式也必须作为独立时态表达式进行注释。这意味着我们允许在不同文本表达式的重叠标记上有多个注释。我们之所以做出这样的选择,是因为在大多数情况下,这些时态表达式也可以作为事件组件的时态锚。(看不懂)
- (We also allow the creation of empty TIMEX3 tag, i.e. non-text consuming temporal expression markables corresponding to implicit, i.e. not realized in the text, beginning and/or end points of temporal expressions denoting a duration.)
2.2 Temporal Anchoring of Events (TLINKs)
-
时间关系可识别为两种类型:
- 1)顺序关系(ordering relations),涉及同一本体论类型的元素,如事件对或时间表达式;
- 2)锚定关系(anchoring relations),涉及跨类型元素关系,如事件对和相关的时间表达。
-
虽然这两种时间关系都是有用的,但它们具有不同的信息地位。继Pustejovsky和Stubbs(2011)之后,我们假设时间关系的信息水平可以表示为每个时间链接及其闭包所包含的信息的函数。在这种假设下,锚定关系表示事件何时发生或持续时间,比排序关系更能提供信息。前者允许我们将事件放在虚构的时间线上的特定点(或间隔)上,因此,也给了我们事件之间的顺序关系(ordering relations)
-
ESC注释方案使用TimeML TLINK标记表达时间关系,并将它们限制为锚定关系。当一个锚定关系被实例化时,事件和时间表达式之间的TLINKs会被系统地注释。在句内和句间层面,事件和时间表达之间可能存在锚定关系。此外,每个事件还与每个文档的文档创建时间(Document Creation Time, DCT)相连接。
-
将注释限制为锚定关系也是一种策略,可以避免事件之间顺序关系的复杂性。大多数当前的解决方案不是最佳的,因为他们给的注释器太多自由的选择事件对(例如TimeML),或者迫使注释器标记所有可能的关系(例如TimeBank-Dense( (Cassidy et al., 2014)),或限制注释明确语言的存在证据(例如RED)。
-
ESC中的时间值来源于RED指南。我们根据注释的锚定关系的类型应用两组TLINK值:四个值应用于事件和DCTs之间的关系(即before、after、overlap和contains),而只有一个值(contains)应用于事件和时态表达式之间的关系。注释器还被指示TLINK的方向性,它应该总是从时态表达式(DCT)到目标事件。
2.3 Explanatory Relation Annotation (PLOT LINKs)
-
PLOT LINK注释分两步进行:首先,注释器必须识别事件对之间所有符合条件的关系,然后将每个关系分类为属于两个类中的一个:
- rising action,是对另一事件有间接影响、导致或促成的事件
- falling action,是明确标记推测和结果的事件,即是另一事件(预期)的结果或影响。
-
PLOT链接与因果和时间关系注释相关( (Miltsakaki et al., 2004; Bethard et al., 2008; Mirza and Tonelli, 2014; Dunietz et al., 2015),但它们在三个方面有所不同:
- 1)它们既包括标准的因果关系,即因果关系(cause)、使能关系(enablement)和预防关系(prevention),也包括附加的event-event关系,如偶然性(contingency)、子事件关系(sub-event)、蕴含关系(entailment)和共同参与关系(co-paticipation);
- 2)它们通常没有通过关系结构在文本中明确标记出来;
- 3)它们比所有处于时间关系中的事件更具体,因为它们增加了解释性信息。
-
PLOT链接可以通过克服当前的缺点来定位在时间标注和因果标注之间,例如在前一种情况下创建无信息的事件对,在后一种情况下创建极其有限的标注,即存在明确的因果触发。( PLOT_LINKs can be positioned in between temporal and causal annotations by overcoming current shortcomings, such as creation of uninformative pairs of events, in the former case, and an extremely limited annotation in the latter, i.e. presence of an explicit causality trigger.)PLOT_LINK关系中的每一对事件基本上都是在帮助阅读器(和机器)以有意义的方式连接事件。简而言之,PLOT_LINKs旨在回答某些事情发生的“为什么”。考虑到它们以事件为中心的本质,这样一个问题的答案必须是在分析中文档中明确声明的另一个事件
-
PLOT_LINK关系是不对称和非传递的。考虑到这类关系的性质,非传递性是合理的。它们适用于对事件之间的局部分析,而不能转移到全局层面,即被有助于确定故事情节的完整事件链所继承。虽然受时间顺序的影响,但这种关系的目的是使(新闻)故事中的事件具有明确的连贯性或逻辑联系。
-
在注释PLOT LINKs时,关系的(广义的)“因果”维度比时间维度更为重要。我们并不是在填充时间轴,即时间的内部方向性(Internal Directionlity of Time) (Bonomi和Zucchi, 2001)所支持的公理,而是根据分析文件中给出的信息,寻找事件“为什么”发生的解释。因此,在例4中,“地震”和“被困”事件之间的关系是通过回答“为什么人们被困?”,而不是通过传递关系将"earthquake" rising_action "collapsed" 与 "collapsed" rising_action trapped 联起来。
- The earthquake killed 14 and left hundred trapped in collapsed buildings.
- earthquake rising_action killed
- earthquake rising_action trapped
- earthquake rising_action collapsed
- collapsed rising_action trapped
-
注释器可以自由地识别可能处于PLOT_LINK关系中的事件对。 我们没有像在TimeBank-Dense语料库中那样,创建一组预定义的可能位于一个情节链接中的事件对,因为这需要在同一句中和所有句子中发生的所有事件之间创建一个非常大的图表。 然而,我们将PLOT_LINKs的注释限制在与以下三类之一对应的事件上: 动作发生(ACTION_OCCURRENCE), 动作感知(ACTION_PERCEPTION), 动作状态(ACTION_STATE)。 我们将这些事件标记为“语义完整(semantically full)”或“语义加载(semantically loaded)”的事件。这些类中的事件确实有一个描述情况的内容组件,而不是表示事件的元级别信息。ACTION_REPORTING(行动报告)的类别也被排除在外。在这种情况下,有意义的信息是由言语事件的“内容(content)”而不是引入它的词汇表达来表示的。这种选择保证了只有有意义的事件才是故事情节的一部分。
-
最后,PLOT链接还允许对事件对之间的明确的因果关系进行注释。两个二进制属性,原因(cause)和由于(cause_by),必须选择存在明确的因果关系。明确的因果关系可以由ACTION_CAUSATIVE事件引入,或因果信号,如连词(例如because)、介词(例如by,from,for,among others)和其他连接词。一个额外的属性,信号(signal),已经被创建来注释因果关系的“标记(markers)”。在开发的这个阶段,只有当ACTION_CAUSATIVE事件被用来表示一种偶然关系的存在时,该属性才会被填充:
- A massive quake struck off Aceh in 2004 , sparking a tsunami.
- quake rising action
- tsunami signal= sparking
- cause = YES
2.4 Event Co-reference
- 目前,事件提及之间的共同引用链的注释已经继承自ECB+。如果两个事件描述相同的动作组件,无论是在同一文档还是跨文档,ECB+指南都把它们看作同一事件引用时。也就是说它们描述相同的动作组件,而且1.)共享相同的参与者;2.)共享相同的时间锚点;3.)共享相同的位置。
2.5 Data
-
ESCv0.9数据集目前由ECB+语料库中的22个关于灾难事件组成,即自然灾害、枪击、杀人、事故和审判等。
该语料库包含258个文档,共7275个事件提及(其中191个被否定了)共有1297个时态表达式,248个对应DCTs,其中22个是通过空的TIMEX3标签实现的。在其余的10篇文章中,无论是从文章中还是通过搜索Web都无法恢复DCT。
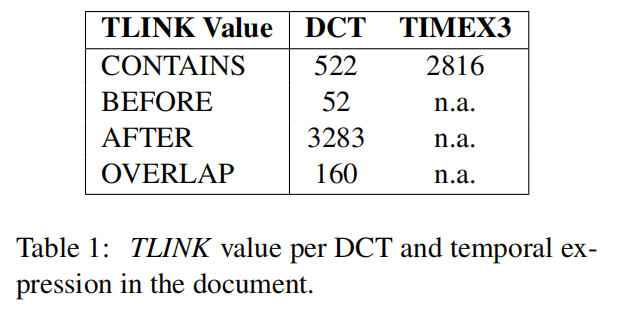
根据TLINKs的扩展锚定关系方法,我们注解了事件和DCT之间的共6904个关系,以及事件和时间表达式之间的关系。 表1列出了这些值分布的详细情况![image-20220207150547242]()
-
对于PLOT_LINKd,总共注释了2265个解释关系,平均每个文档有8.7个关系。1147个关系被列为rising_action,而1118个关系被列为falling_action。通过文档内事件共同引用链扩展手动注释关系(manually annotated relations),我们总共达到了5,519个PLOT_LINKs,几乎是每个文档平均关系的3倍。这分别导致2653个上升关系和2844个下降关系。最后,只有117个明确的因果关系被确定。
-
ESC v0.9语料库的标注由2位专家按照多步骤进行,并使用基于web的工具CAT (Bartalesi Lenzi et al., 2012)。
-
在第一阶段,两个注释者都经历了一个熟悉任务的培训阶段,并被允许讨论和比较他们的注释,特别是对于PLOT_LINK任务。该阶段通过引入更具体的选择事件对规则,从而对注释指南进行了修订。
-
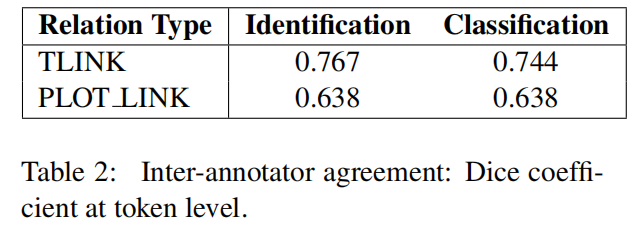
在第二个阶段,在ESC v0.9数据集的一个子集上计算了注释者间协议。特别是,考虑到基本组件,(即事件、时间表达式和事件共引用链,这些直接从ECB+语料库继承的内容),协议仅为锚定(即TLINK标签)和解释关系(即PLOT_LINK标签)计算。使用Dice系数计算互注释器协议,用于关系检测和关系分类。ESC v0.9语料的两个不同子集被用于这两个关系:一个重要事件用于TLINKs, 4个重要事件用于PLOT_LINKs。我们之所以做出这样的选择,是因为这两种关系的性质不同。结果见表2。PLOT_LINKS的分数是作为4个重大事件的平均值计算的。
![image-20220207150605168]()
-
-
PLOT_LINK分析中最有趣的观察结果之一是,协议可能会根据影响事件的类型而有所不同。例如,T19的一致性最高:一次枪击事故:关系识别的Dice系数为0.723,关系分类识别的Dice系数为0.728。越狱事件的一致性最低(T3):关系识别的Dice系数为0.48,关系分类的Dice系数为0.471。研究结果虽然是初步的,但表明不同类型的开创性事件可能以不同的方式叙述不同的故事模式(例如或多或少的线性故事)。
3 Experiments: Baselines
在本节中,我们将描述ESC v0.9数据集上的许多故事线提取基线系统的实验结果。这些实验的结果将有助于比较未来(和更复杂的)系统的性能,以及对任务的复杂性进行初步评估。
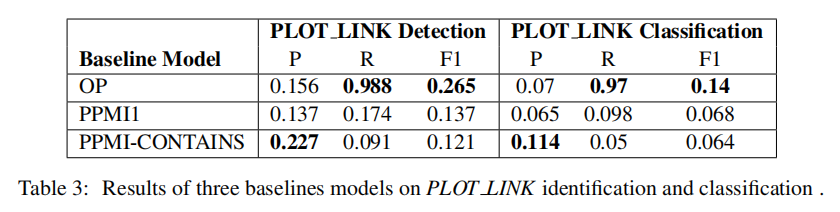
ESC v0.9数据集被划分为6个影响重大事件的开发集和16个影响重大事件的测试集。当使用文档内事件共同引用链进行扩展时,测试子集总共包含4,027个PLOT_LINKs。所有实验都考虑了gold data的事件范围,时间表达范围和值,以及事件共参照
已经开发了三个基线:
- OP: 在模仿文本顺序的关系中选择事件对
- PPMI1:使用PPMI( Positive Pointwise Mutual Information)选择事件对。PPMI从一组被选择的种子对和开发集中人工标注的对中得到
- PPMI-CONTAINS:使用PPMI选择事件对,就像在PPMI1模型中一样,但将事件集限制为那些共享相同的时间锚的事件集,即具有类型为contains的TLINK。
4 Related Work
5 Conclusion and Future Works
本文提出了事件故事情节语料库v0.9,这是第一个用于故事情节抽取任务的基准语料库,即从时间上传播的文档中,对与特定主题相关的事件序列进行时间上和逻辑上的连接。我们还介绍了三个基线系统及其在数据库上的性能。这个任务的目的是摆脱现有的时间轴和因果关系提取的方法。关于前一项任务,故事线只针对与故事相关的事件的按时间顺序排序,从而清理时间轴结构。与此同时,故事情节通过覆盖句内、句间事件之间的显性和隐性因果关系,扩展了因果关系的提取。这有助于学习叙事模式,即新闻数据中的解释模式,可以用来识别新闻中重大事件或主题的刻板和情景叙事。一个创新的方面是跨文档的事件的共同引用关系的连接,从而使带注释的数据对于开发跨文档的摘要系统也很有用。
本文来自博客园,作者:Un-Defined,转载请保留本文署名Un-Defined,并在文章顶部注明原文链接:https://www.cnblogs.com/EIPsilly/p/15867942.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号