
[论文阅读] EEG:knowledge base for event evolutionary principles and patterns
EEG: knowledge base for event evolutionary principles and patterns
Abstract
1 Introduction
举例餐厅吃饭的流程
列举先前的提取时间关系的研究,指出缺陷
- 只能提取同一个句子里的关系
- 基于特定语境的语义提取关系,而不是发现大规模用户数据中事件演变的潜在模式
引出EEG
-
对EEG的定义涉及到演化模式和事物发展的逻辑
-
EEG由事件和事件之间的关系组成
-
为了考虑普遍性,我们考虑EEG中的顺序和因果关系
-
构建EEG可以被简化成两个关键问题。两个问题都可以通过分类框架解决
- 判断出两个事件之间的关系
- 区别事件之间关系的方向
简述文章做出的贡献
- 提出EEG并给出EEG的定义
- 提出了一种基于大规模、非结构化网络语料库的EEG构建框架
- 通过大量实验解决顺序关系和方向识别的核心问题
2 Related Work
2.1 Statistical Script Learning
- 简述Script Learning及其相关工作成果
- 提出EEG的目的是将事件进化模式组织成常识知识库
2.2 Temporal Relation Extraction
- 简述Temporal Relation Extraction及其相关工作成果
- 指出上述工作是从特定的上下文中提取出时间关系。作者及其实验室是通过在多个语句中基于频率推断来解决这个问题。这是一种常识性的过程。
3 Event Evolutionary Graph
给出EEG的定义
-
在EEG中,事件由抽象、概括和语义完整的动词短语表示。
- 抽象和概括意味着我们不必关注事件发生的具体时间和地点以及事件的主体
- 语义完整指的是人类可以理解事件的意义,不存在含糊和歧义
-
事件必须含有一个触发词,触发词表示该事件发生了
-
事件还必须包含其他必须的内容,例如主语、宾语、修饰词,从而保证事件的语义完整性
顺承关系

- 两个事件之间的顺序关系指的是他们之间的偏序时间关系
因果关系

- 因果关系是顺承关系的子集,顺承关系比因果关系更普遍
EEG是有向循环图,其节点是事件,边是事件之间的顺承关系、因果关系。EEG本质上是常识知识图,描述事件演化的模式。
4 Methods for Constructing EEG
引言:
-
该节提出了基于大规模非结构化数据构造EEG的构建框架,包括数据清洗,自然语言处理,事件提取,事件候选对提取,顺序关系和方向识别,因果关系和转移概率计算
![image-20220128234132197]()
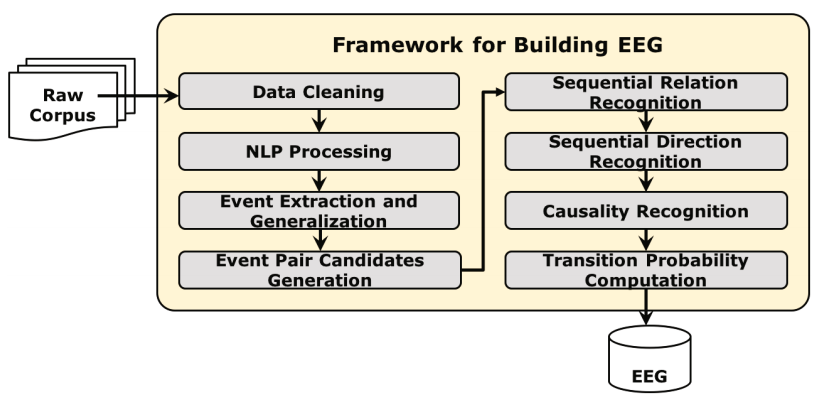
4.1 Event Extraction
- 数据清洗之后,采取一系列的自然语言处理步骤,包括切分,词性标注,依赖关系解析。该过程采用Language Technology Platform的工具
- 事件提取策略因任务而异,取决于底层任务。作者从依赖解析树种提取动宾短语。虽然这是一个简单的策略,作者确实发现很多高质量的动词短语被提取出来。
- 选择适当的阈值来筛去低频率的动宾短语,从而排出由于分割和依赖解析错误而提取出来的动宾短语
- 一些过于普遍的短语,例如“go somewhere”,则通过正则表达式去除
- 注意:事件提取并不是这篇文章的关键问题
4.2 Event Pair Candidates Generation
-
候选事件对的提取基于两个启发式策略
- 两个来自同一个句子的事件被认为是一个事件候选对
- 两个来自两个连续的句子的事件被认为是一个事件候选对
- 例如事件A,B来自前一个句子,C,D,E来自后一个句子,则有十个事件对(A, B), (A, C), (A, D), (A, E), (B, C), (B, D), (B, E), (C,D), (C, E), (D, E)
4.3 Sequential Relation and Direction Recognition
-
作者将顺承关系和方向识别看作两个独立的二元分类任务。
-
以往的时间关系分类研究都是从单句判断关系和方向。或者,可以通过从多个句子中基于频率的推理来解决这个问题。
- 具体来说,我们通过强迫事件A和事件B同时发生超过k次来实现这一点。
-
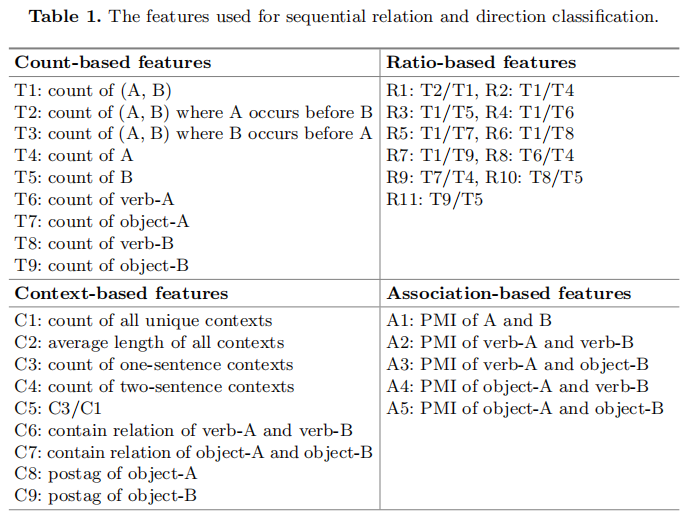
针对这两个监督分类任务,提取了多种特征
-
![image-20220128234144781]()
-
Count-Based Features
- 对于强关联的事件对(a, B),它们有许多不同的统计数据。 这些数据从共存的上下文中和整个语料库中直接计数。作者认为这些数据能够有效地反映事件A,B之间联系的强弱和联系方式。
- 统计数据包括共同出现的次数(T1-T3),出现在整个语料库中的次数(T4-T5),作为动词和宾语出现在事件中的次数(T6-T9)
-
Ratio-Based Features
- 基于计数的特征是直接从上下文和语料库中统计出来的数字。这些数字之间的一些有意义的组合可能会提供额外的对顺承关系和方向判断有用的信息
- 例如:如果T2/T1接近1,我们可以认为在A、B两者共同出现的上下文当中,A几乎总是在B之前发生。这是一个从A到B顺承关系的显著信号
-
Context-Based Features
- 我们认为上下文中存在哪里更可能出现顺承事件候选对的信息。A和B同时出现在非重复上下文中的次数(C1);所有上下文的平均长度(C2);A和B出现在同一个句子中的次数(C3);不同语句中的次数(C4);同一个句子中的概率(C5);动词和宾语之间的包含关系(C6和C7) ;A、B宾语的词性标注(C8和C9);
-
Association-Based Features
- 该部分特征衡量事件A、B之间关联的强度,包括两个不同方面PMI的得分。
- 计算(A, B)的PMI得分作为事件A和事件B相互关联强度的宏观度量(A1);作者进一步考虑(动词A,动词B)、(动词A,宾语B)、(宾语A,动词B)和(宾语A,宾语B)的细粒度PMI得分,它们测量事件组件的部分关联强度(A2到A5)
-
4.4 Transition Probability Computation
-
对于给定的事件对(A,B),用以下公式计算转移概率。
![image-20220128234151145]()
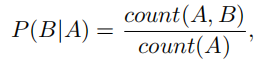
5 Experiments
引言:
- 在该节,我们进行了两种实验。第一种是判断两个事件之间是否有顺承关系。第二种是判断两个顺承事件之间的偏序方向。这两步是构建清楚、准确的EEG的关键和核心
5.1 Dataset Description
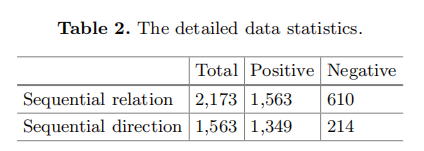
- 作者从知乎爬取了320,702个关于旅行话题的问答对作为实验数据。旅行是一个相对高层次的话题,它覆盖了很多关于旅行的内容。因此能从数据源中提取出许多常识性的事件演变只是
- 作者标注了2,173个共同发生次数大于5的事件对,将其作为实验的语料库。在标注的过程中,提供给标注者事件对以及与其对应的上下文。标注者需要从常识的角度判断两个事件对是否含有顺承关系。如果有则将其标注为正,否则标注为负。如果顺承关系是从前往后,则标记为正,否则为负
- 因为正负样本数量不平衡,所以作者对负样本采用过采样使其数量与正样本相当
5.2 Compared Methods and Evaluation Metrics
-
baseline method
- 对于顺承关系识别,一对事件的PMI用来作为基准方法;如果事件A发生在B之前的频率比B发生在A之前的频率要高,则认为顺承关系是从A到B,这种方法叫做先验假设,用来作为顺承关系识别中的基准方法
-
对于判断是否有顺承关系和判断顺承事件之间的偏序方向这两个实验,作者采取4种分类器进行实验。它们分别是朴素贝叶斯(NB)、逻辑回归(LR),多层感知机(MLP),支持向量机(SVM)。作者探索各种不同的特征组合,寻找对于各个分类器来说都是最佳的特征组。所有的实验都使用五折交叉验证。最终的实验结果是实现的平均性能的10倍。
-
两种评价指标被用来评价我们所提出的方法的性能。它们是准确性,精度,召回率和f1值。
5.3 Results and Analysis
-
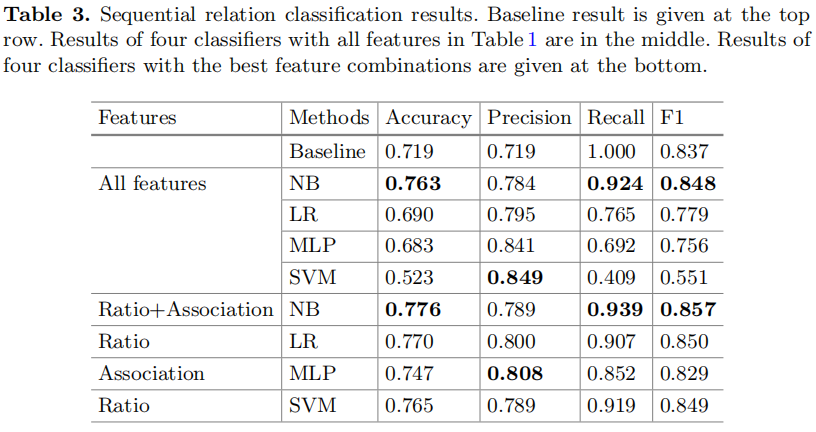
表三展示了顺承关系分类器的结果,作者发现单纯的PMI分类器取得了非常好的效果。实际上,因为正负样本不平衡,PMI基准方法选择了一个阈值将所有的测试样本归为正样本,从而取得了100%的召回率。4中分类器搭配表1中的所有特征,都取得了较差的结果,只有NB的表现高于基准方法。我们探索4中特征的各种组合,从而寻找各个分类器的最佳特征集。尽管如此,NB分类器还是以0.776的准确率和0.857的F1得分表现得最高。
![image-20220128234242132]()
-
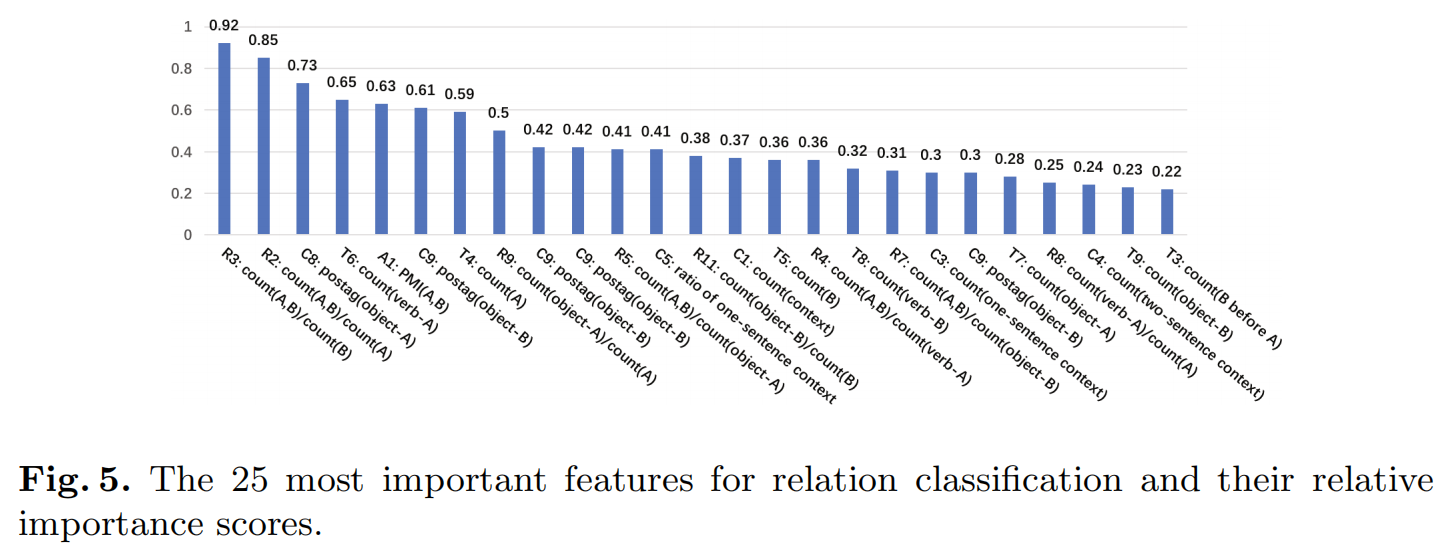
此外,作者还计算了表1中所有特征的相对重要得分,对于关系分类最终要的25个特征和它们的得分展示在图5中。通过卡方检验、方差分析f值法、最大信息系数法、随机森林法、递归特征消除法和稳定性选择法等6种方法计算重要度。各个方法的分数被归一化为0和1的范围,6个分数的平均值被计算为最后的重要分数。
作者发现基于比例的特征对于顺承关系分类器最为重要。表3的实验结果验证了这一结论,三个分类器都在使用基于比例的特征时取得了最好的效果。基于关联的特征第二重要。![image-20220128234252842]()
-
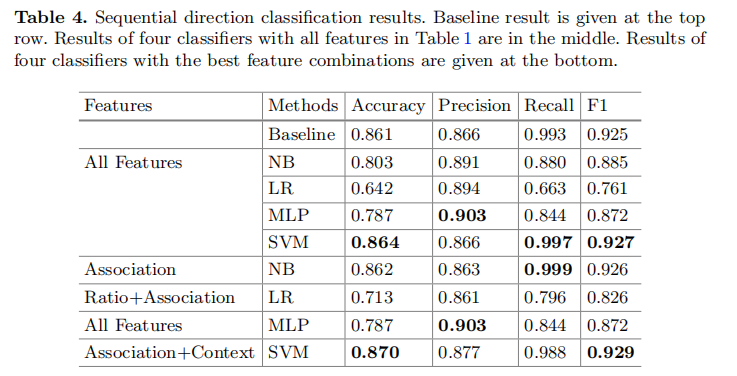
表4展示了顺承关系方向分类的结果。我们从中发现先验假设是一个鲁棒性非常强的基准方法,其精度为0.861,F1为0.925。
![image-20220128234257578]()
-
4种分类器搭配表1中的所有特征取得了较差的结果,只有SVM分类器的表现优于基准方法。我们探索了四种特征的所有组合,以找到不同分类器的最佳特征集。尽管如此,SVM分类器搭配关联和基于上下文的特征,以0.870的准确性和0.929的F1分数获得了最佳的性能。
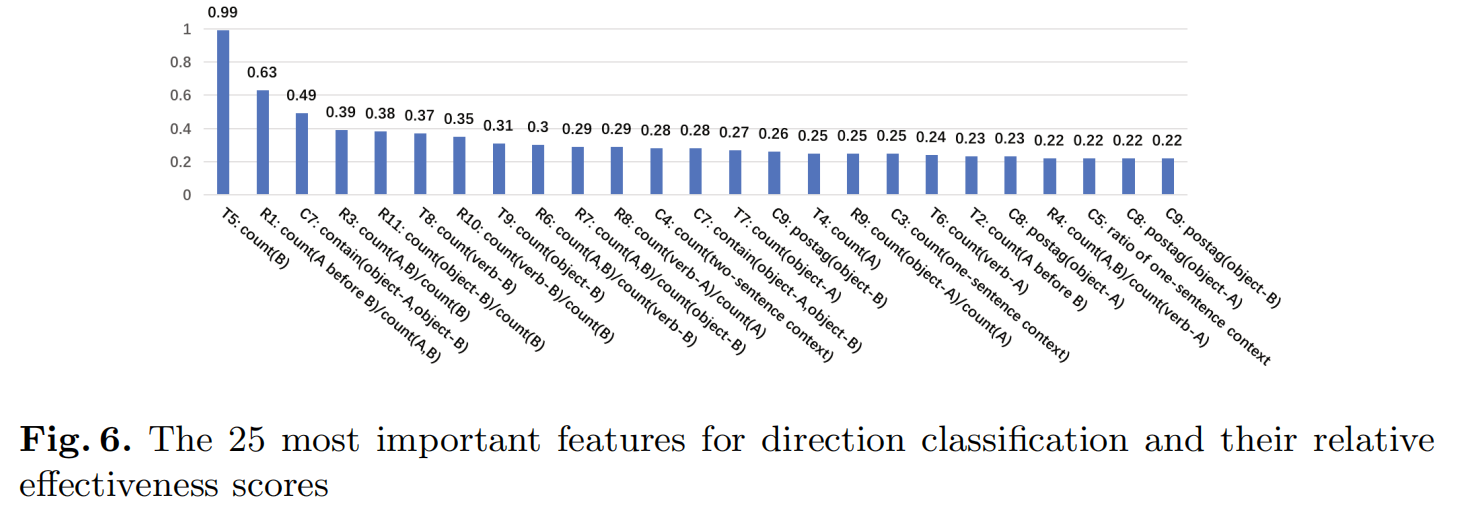
作者也计算了特征的相对重要得分。发现最重要的两个特征时T5(事件B的出现次数)和R1(count(A before B)/ count(A,B))。但是4个里面有3个分类器在没有用这两个特征的情况下,取得了最好的结果。作者后来在加入这两个特征的情况下进行了实验,发现没有帮助。这主要是因为特征重要性评分单独检查每个特征,以确定特征和响应变量之间的关系强度。 因此,由于它们相互之间的相关性相反,当它们组合在一起时可能会降低性能。![image-20220128234302952]()
总结
- 特征越多,表现越好是错误的,不同的分类器捕获不同的特征
- 两种基准方法在实验中取得了很好的效果,但是我们提出的基于特征的监督学习方法取得了最好的结果
- 即使某个特征单独来讲非常重要,但是由于特征之间关联性相反,组合装一起的时候效果可能会变差
6 Case Study
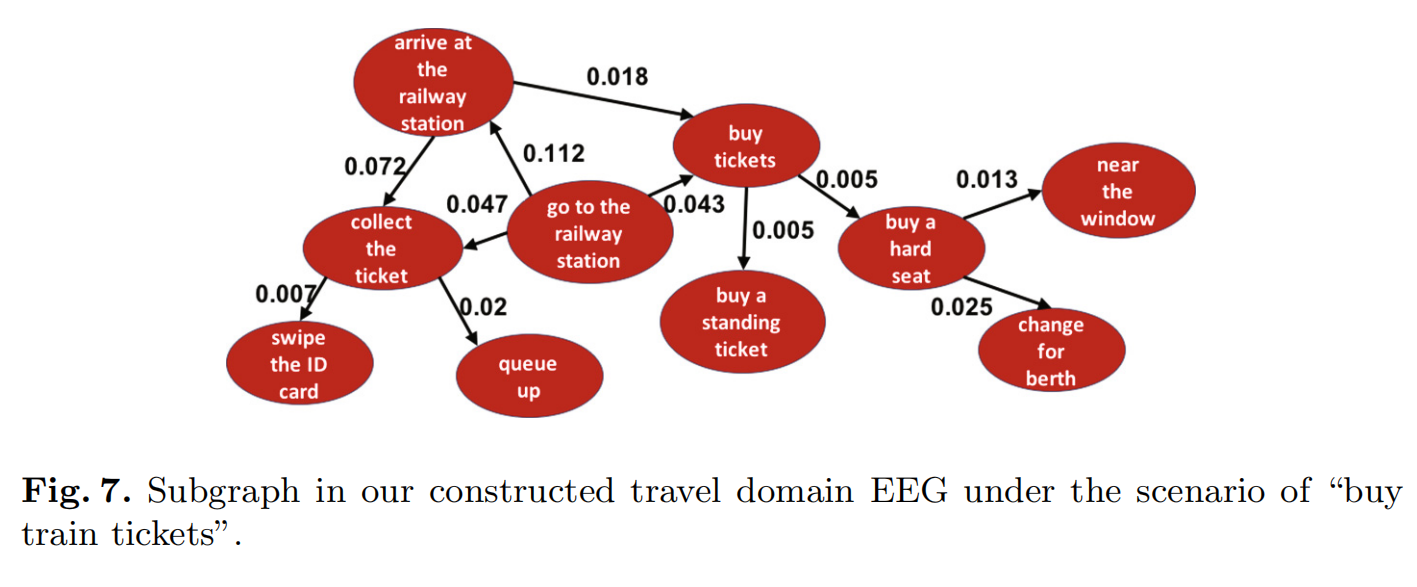
7 Conclusion and Future Work
本文来自博客园,作者:Un-Defined,转载请保留本文署名Un-Defined,并在文章顶部注明原文链接:https://www.cnblogs.com/EIPsilly/p/15854136.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号