[论文阅读] CATENA-CAusal and TEmporal relation extraction from NAtural Language texts
CATENA-CAusal and TEmporal relation extraction from NAtural Language texts
Abstract
作者提出了一个基于筛选的系统CATENA,用于提取和分类英文文本中的时间关系、因果关系,利用时间和因果模型之间的交互作用。作者评估了每个筛的性能,表明基于规则组件、机器学习组件和推理组件都有助于在TempEval-3和TimeBank-Dense数据上实现最先进的性能。尽管因果关系要比时间关系稀疏很多,但系统结构和选择的特征大多数情况下都能够很好的完成这两个任务。时间成分和因果成分的交互作用虽然有限,但是却产生了很有希望的结果,并证实了文本在时间维度和因果维度之间的紧密联系
1 Introduction
2 Related Work
作者提出的关系提取方法是受到最近的混合方法提取时间关系的启发
- D’Souza and Ng (2013) 引入437条手写规则,以及使用词汇关系、语义和篇话语特征的监督分类模型
- CAEVO, 由Chambers et al. (2014)提出的一个级联事件顺序框架,将基于规则和数据驱动的分类器结合在基于筛选的体系结构中,用于时间排序。分类器(筛)根据它们各自的精度进行排序,并且在每个筛子后应用传递闭包,以保证时间图的一致性
检测事件之间的因果关系的问题就像识别它们的时间顺序一样具有挑战性,但很少从自然语言处理的角度进行分析。
- 之前的研究大多专注于特定的事件对和文本中因果关系的表达(Bethard et al., 2008; Do et al., 2011; Riaz and Girju, 2013).
- 有几篇文章利用特定思维连接词形成的平行时间与因果关系语料库(Bethard et al., 2008),对时间与因果关系的交互作用进行了分析(Bethard and Martin, 2008; Rink等人,2010)
- 利用黄金时间标签作为特征的因果关系分类器是有益的。Mirza等人(2014)受到TimeML的启发,提出了一些注释指南来捕捉事件对之间的显式因果关系。得到的语料库(causal - timebank),被用于建立提取因果关系的监督分类模型(Mirza和Tonelli, 2014a)。
上述系统都没有在基于筛选的体系结构中提出一种混合方法来处理此任务。CATENA是目前第一个可以进行时间和因果关系提取的集成系统。
3 System architecture
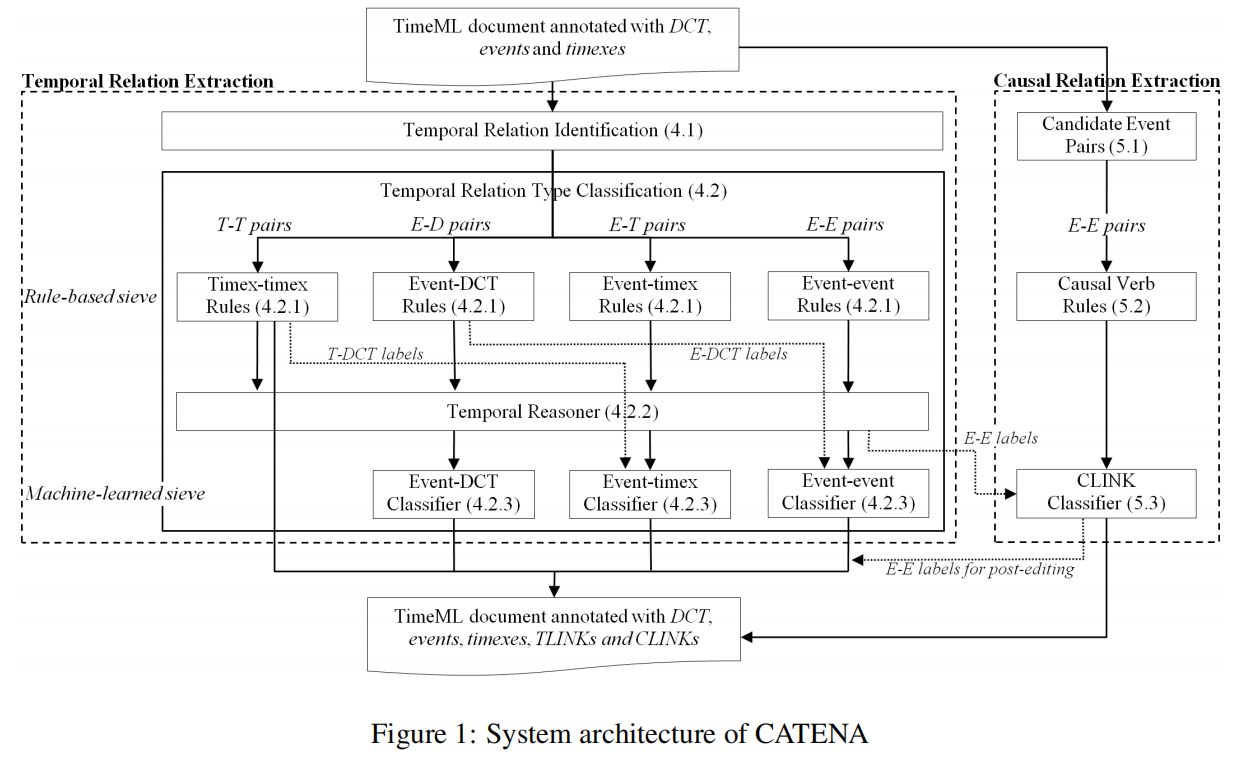
CATENA主要包括两个分类模型,一个用于时间关系,另一用于因果关系。
两个模型都将根据TimeML指南标注了事件实体的文章作为输入,标注包括文档创建时间(DCT),事件和事件表达式(timex)
输出内容是拥有事件实体对之间时间关系(TLINKS)的文档,每一个TLINK都被分配了一个TimeML时间关系类型,比如BEFORE,INCLUDES,SUMULTANEOUS,它们表示了时间顺序。文档同样也被标注了事件对之间的因果关系(CLINKS)
模型对时间关系和因果关系的分类依赖于基于筛的系统架构。在该系统架构中,经过基于规则的组件和/或传递推理机后,剩余的未被标注的对被输入到监督分类器中。
虽然有些步骤可以并行运行,但基于因果关系的概念与时间维度紧密相连的假设,两个模块可以交互,并且一个模块的信息可以用来改进或检查另一个模块的一致性。特别的,(i) 由基于规则的筛和事件推理机模型产生的event-event(E-E)对的TLINK标签,可以用作CLINK分类器的特征 (ii) CLINK标签(即CLINK和CLINK-R)可以被TLINK分类器用作一种纠正错误的事件对标签的后期编辑方法。该步骤依赖于一系列基于因果关系上的时间约束的规则,比如(i) CLINK(e1,e2)→BEFORE(e1,e2) (ii)CLINK-R(e1,e2)→AFTER(e1,e2)。
4 Temporal Relation Extraction System
引言:提取时间关系的模型包含两个主要部分,(i) 基于一系列规则的时间关系识别 (ii) 时间关系类型识别,该部分组合了基于规则和监督分类的模型,中间是一个时间推理组件。这三个事件关系类型识别的步骤是根据各自的精度进行排序的。这种机制允许系统先使用规则对少量关系进行高精度的标注,然后根据推理机推断出新的关系,最后基于之前的输出,通过监督分类器提高召回率
4.1 Temporal Relation Identification
-
受到TempEval-3的人物描述的启发,所有满足下列规则其中之一的时间实体对被认为拥有时间关系(TLINKS)
- (i) 连续句子的两个主要事件
- (ii) 同一个句子中的两个事件
- (iii) 同一个句子中的事件和时间
- (iiii) 事件和文档创建时间
- (iiii) 相互连接的所有可能的时间对(包括文档创建时间)
-
然后将这些对分成四种不同的组: timex-timex (T-T), event-DCT (E-D), event-timex (E-T) and event-event (E-E)
4.2 Temporal Relation Type Classification
-
作者的基于筛的结构是受到了CAEVO的启发,尽管我们显著降低了系统的复杂性
-
将所有的基于规则的分类器合并成一个筛组件(基于规则的筛),并将所有的SVM合并到机器学习的筛选器中
-
作者不是在每个分类器之后运行传递推理,而是在基于规则的筛选器的输出上运行时间推理器模块,只运行一次。
-
除此之外,我们使用基于规则的筛(4.2.1)的输出作为机器学习筛(4.2.3)的特征
- timex-timex规则筛输出的timex-DTC关系标签被用作event-timex SVM的特征
- event-DCT规则筛输出的event-DCT关系标签被用作event-event SVM的特征
-
4.2.1 Temporal Rule-Based Sieve
-
基于时间规则的筛依赖于为各种时间实体对设计的特定的手写规则,并且将前一步的被识别出的实体对作为输入
-
Timex-timex Rules
- 对于timex-timex关系,我们考虑DATE和TIME类型的时间表示,并根据她们的归一化值判断关系类型。例如"今晚7点"(2015-12-12T19:00)被包含在"今天"(2015-12-12)中
-
Event-DCT Rules
- 给E-D对贴标签的方法基于事件单词的时态和(或)方面。例如,对于带有过去完成时的事件提及“(had) fallen”,它与DCT的关系被标注为BEFORE。
-
Event-timex Rules
-
对于E-T对,作者基于一些介词的时间含义建立了一套规则(Litkowski and Hargraves, 2006; Litkowski, 2014),事实上,作者分配标签时,只要一个事件介词建立了event(E) 和 timex(T)之间的依赖路径,其中T作为E的时间修饰语 。例如,如果T是由表示开始时间意义的时态介词引入的,例如from或since,则关系被标记为BEGUN BY
-
在没有时态介词的情况下,T可能只是E的时态修饰语,例如"Police [confirmed] E [Friday] T that the body was found..."。在本例中,我们假设E-T标签是IS_INCLUDED,此外,有时候,事件会被时间表达式修改,以持续模式标记开始时间和结束时间,例如"between TBEGIN and TEND" 或 “from TBEGIN to/util TEND”。我们定义附加规则如下:
- (i) 如果T匹配TBEGIN,那么E-T标签为BEGUN_BY
- (i) 如果T匹配TEND,那么E-T标签为ENDED_BY
-
-
Event-event Rules
-
E-E对按照两组规则进行标记。
-
第一组规则基于事件1(e1)和事件2(e2)之间可能存在的依赖关系和e1中编码的谓词信息。例如"the chain reaction touched off by the collapse of Lehman Brothers”。e1和e2由AFTER关系连接起来
-
另一组规则来自CAEVO,包括:
- (i) 基于时态和方面的规则,将一个报告事件与另一个在语法上由报告事件主导的事情连接起来。
- (ii) 基于英语动词时态在时间语篇传递中所起作用的规则(Reichenbach, 1947)
-
-
4.2.2 Temporal Reasoner
-
基于前一个筛的输出,作者运行一个类似CAEVO的传递推理机层,从候选对中推理出新的时间链接。这缓解了基于规则筛选的典型的高精度和低查全率问题。
-
一个带注释的TimeML文档可以根据TLINKS映射到Allen关系(Allen,1983)的方式映射到约束问题中。我们采取以下映射
- < and > for BEFORE and AFTER
- o and o−1 for DURING and DURING INV
- d and d−1 for IS INCLUDED and INCLUDES
- s and s−1 for BEGINS and BEGUN BY
- f and f −1 for ENDS and ENDED BY
-
一旦文档被映射到约束问题,它们就会被一个自动时间推理器处理,对它们进行全局推理。作者依靠通用定性推理器(Generic Qualitative Reasoner , GQR)(Westphal et al.,2010),这是一个针对通用定性约束问题的快速求解器,如艾伦约束问题。选择GQR而不是其他解决方案,如快速布尔可满足性问题(Boolean Satisfiability Problem , SAT)求解器,是因为它的可伸缩性、使用简单性和高效性能(Westphal and W¨olfl, 2009)
4.2.3 Temporal Supervised Classifiers
-
作者建立了三个监督分类模型,分别用于event-DCT(E-D),event-timex(E-T),event-event(E-E)。作者使用LIBLINEAR (Fan et al., 2008) L2-loss linear SVM (default
parameters), and one-vs-rest strategy来处理多分类. -
Tools and Resources
- 一些外部工具和源被用来从各个时间实体对中提取特征
-
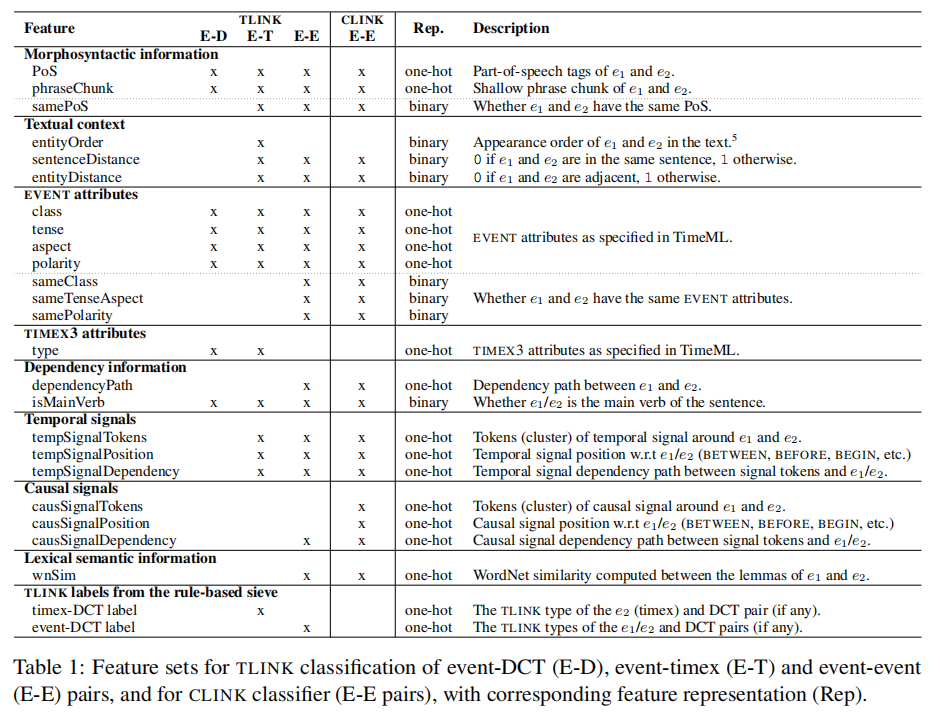
Feature Set
![image-20220128232655806]()
- 为了提高分类器在处理带有不同词汇的全新文本时的鲁棒性,我们将时态实体的标记/词汇等词汇特征从特征集中排除。 相反,我们在特征集中包含WordNet相似性,以捕获事件单词之间的语义关系
-
Label Simplification
- 为了训练分类模型,我们将其中一些类型折叠起来,只考虑TimeML中定义的14种关系类型中的10种:IBEFORE为BEFORE, IAFTER为AFTER, DURING和DURING INV为SIMULTANEOUS,因为这些标签在数据集中是稀疏标注的
5 Causal Relation Extraction System
作者采用了Causal-TimeBank注释指南中提出的因果关系概念(Mirza et al., 2014; Mirza和Tonelli, 2014a),它解释了在文本中公开表达的CAUSE、ENABLE和PREVENT现象(Wolff, 2007; Wolff and Song, 2003)。事实上,作者的目的是在以下情况下给事件对分配一个因果联系:(i) 因果关系由affect,link 和 causative 动词(CAUSE-,ENABLE- and PREVENT-type verbs),表示的,以下简称因果动词 (ii)因果关系由因果标志标注(例如because of)
这两种情况需要不同的方法:虽然包含因果动词的因果结构很容易识别,但因果信号非常模糊,可以出现在不同的句法结构中 。因此我们通过基于规则的方法解决第一个问题,而第二个问题最好利用免费的causal-TimeBank,通过监督学习来解决。
5.1 Causal Relation Identification
- 对于已经注释了事件的文档,我们将以正向方式考虑句子中每一个可能的事件组合作为候选事件对。例如我们拥有一个句子"e1,triggered by e2,cause them to e3",候选事件对是(e1,e2),(e1,e3),(e2,e3)。我们还将一个句子中的每个事件与下一个句子中的事件的组合作为候选事件对,以解释句间的因果关系,在简化的假设下,事件之间的因果关系也可以在两个连续的句子中表示。
5.2 Causal Rule-Based Sieve
- 在基于规则的筛选中,我们对包含因果动词的因果结构进行分类。这些有很强的规律性:给定一个因果动词v,第一个事件e1通常是v的主语,第二个事件e2要么是v的宾语,要么是v的谓语补语。这种事件与因果动词之间的关系通常在语句构成上表示出来,因此我们的规则目的是通过观察它们的依赖路径,在因果结构中确定与因果动词相关的成对事件
- 作者将Mirza等人(2014)提出的56个影响(affect)动词、连接(link)动词和使役(causative)动词作为因果动词表。作者使用释义数据库(Paraphrase Database)(Ganitkevitch et al., 2013)和原始动词作为种子进一步扩展了这个列表,结果总共有97个动词。然后,作者将具有相同句法行为的因果动词手动聚为一组,并为每个动词组定义一组规则,考虑到v和e1/e2之间可能存在的依赖路径,以及动词v表达的因果方向意义。
5.3 Causal Supervised Classifier
-
为了识别和确定由因果信号发出的CLINK的因果方向,作者采用了监督方法,使用LIBLINEAR (Fan et al. , 2008) L2-loss linear SVM(默认参数) 和 one-vs-rest策略建立了一个多分类模型。分类器只能使用CLINK,CLINK-R标记含有因果关系的事件对(e1,e2),用O标记其他的。
只有当事件对中因果信号通过依赖路径与e1或e2或两者都连接时,才将该事件对当做候选事件对。此外,我们排除了通过主语、宾语、协调词或位置状语等关系直接连接两个事件的事件对,因为在这些情况下因果关系通常不成立。 -
Tools and Resources
- 和4.2.3节一样的用于时间分类的外部工具和资源也被用来从每一个事件对中提取特征。除此之外,我们也从Mirza等人(2014)提出的注释指南中获取因果信号列表。我们再次使用释义数据库(Paraphrase Database,Ganitkevitch at al.,2013)扩展了这个列表,最终得到了200个信号。我们也手动将一些信号聚合在一起,例如{therefore,thereby,hence,consequently},就像我们对事件信号所做的那样
-
Feature Set
- 提取的特征列举在表1中。如图1所示,时间关系提取模块中基于规则的筛选器和推理器添加的event-event标签也被用作CLINK分类器的特征
6 Evaluation
做评价的目的主要有两个方面:(i) 分别评价提取出的时间和因果关系的质量 (ii) 研究在集成架构中时间与因果关系提取系统之间的交互作用
6.1 Temporal and Causal Relation evaluation
-
作者执行了两个评估,一个遵循TempEval-3,另一个是TimeBank-Dense评价方法
-
Dataset
- 对于遵循TempEval-3的时间关系提取模块的评估,我们使用了共享任务发布的相同的训练和测试数据,即TBAQ-cleaned(清理和改进版的TimeBank 1.2和AQUAINT语料库)和TempEval-3-platinum。 TimeBank 1.2语料库包含183个来自各种新闻报道的文档,特别是ACE program和PropBank;AQUAINT语料库包含73个新闻报道文档,通常被称为Opinion语料库。 TempEval-3-platinum语料库包含20篇新闻文章,由TempEval-3组织者进行注解/评审
- TimeBank-Dense语料库(Chambers et al., 2014)的创建是为了解决现有TimeML语言语料库中的稀疏性问题。 得到的语料库包含来自TimeBank 1.2的36个文档中的12,715个时间关系。 对于TimeBank-Dense评估,我们遵循Chambers等人(2014)的实验设置,其中TimeBank-Dense语料库被分割为22个文档训练集、5个文档开发集和9个文档测试集
- 为了评估因果关系提取模块,我们使用Causal-TimeBank语料库(Mirza and Tonelli, 2014a)进行训练。 对于TimeBank-Dense评估,测试集是TimeBank的子集,因此我们在训练期间从Causal-TimeBank中排除了9个测试文档。 对于TempEval-3评估,我们按照Causal-TimeBank的注释指南,手工标注了20个具有因果链接的TempEval-3-platinum文档。因果关系比时间关系稀疏得多,我们只发现了26个CLINKs。
-
Label Adjustment
- 因为在TimeBank-Dense语料库和TempEval-3语料库中使用的TLINK类型略有不同,所以作者将被CATENA的规则筛(4.2.1节)所标记的TLINK的关系类型按照如下规则进行映射:(i) BEGINS,ENDED_BY→BEFORE (ii) BEGUN BY, ENDS →AFTER (iii) DURING, IDENTITY → SIMULTANEOUS。TLINK分类器(4.2.3节)使用的标签集合也会根据TimeBank-Dense训练数据中的标签进行相应调整。
-
Evaluation Results
- 在表2中,作者将CATENA的性能与参与TempEval-3 TaskC(给定黄金实体的关系注释)和任务C“仅关联类型”(给定黄金实体和相关对的关系注释)的两个性能最好的系统进行了比较。作者还将第二个任务的结果与Laokulrat等人(2015)的结果进行了比较,Laokulrat等人最近提出了一个基于时间图和堆叠学习的最先进的关系分类系统。在CATENA中,Task C的“relation type only”是通过禁用模块来执行的,该模块用于识别章节4.1中描述的时间关系。
评估表明,在两个任务中,CATENA都是表现最好的系统,即使在任务C中,Bethard(2013)和Laokulrat et al.(2013)分别得出了最佳precision和最佳recall。 任务C中的召回率下降(从.613下降到.595)是因为我们从最终注释的文档中删除了timex-timex对,以避免精度的相关下降,因为在黄金标准中只有很少的timex-timex对被注释。 明显的精度下降表明,很难匹配注释器在实体对之间设置TLINKs的决定,尽管CATENA实现了注释指南中必须遵循的指令
我们还在表2中报告了CATENA在TimeBank-Dense评估中的性能,并将其与CAEVO进行了比较。 我们只报告F1-score,因为所有可能的链接都被标记,产生相同的P和R值。 我们在f1总分上取得了小小的进步,即0.511比0.507。 如果考虑不同的实体对,CATENA在time -timex和event-timex关系上表现最好,CAEVO在event-DCT和event-event对上仍然表现最好。 其中一个可能的原因是,在CATENA中缺乏对E-E对之间的VAGUE TLINKs进行分类的规则,这种关系类型只出现在时间银行密集(TimeBank-Dense)中。
- 在表2中,作者将CATENA的性能与参与TempEval-3 TaskC(给定黄金实体的关系注释)和任务C“仅关联类型”(给定黄金实体和相关对的关系注释)的两个性能最好的系统进行了比较。作者还将第二个任务的结果与Laokulrat等人(2015)的结果进行了比较,Laokulrat等人最近提出了一个基于时间图和堆叠学习的最先进的关系分类系统。在CATENA中,Task C的“relation type only”是通过禁用模块来执行的,该模块用于识别章节4.1中描述的时间关系。
-
为了测量每个组成部分对CATENA整体性能的贡献,我们还评估了在时间和因果模块中每个筛的性能。 结果报告在表3中,评估了TempEval-3和时间银行密集测试数据。 正如预期的那样,在基于时间规则的筛选(RB + TR)之后运行传递闭包模块可以改善召回率,但总体表现仍然缺乏(低于0.30 F1-score)。
与仅启用系统中的机器学习筛选(ML)相比,结合基于规则和机器学习筛选(RB + ML)产生了轻微的改进。 在两个筛之间引入时间推理器模块(RB + TR + ML)被证明是更有益的。 这在TimeBank-Dense评估中尤为明显。 CAEVO也观察到了相同的现象; 表3(右)显示了Chambers et al.(2014)报告的相关数字。 注意,在CAEVO中,机器学习筛选器不是最后一个筛选器,相反,AllVague筛选器最终被激活,将所有剩余未标记的对标记为VAGUE。 -
在因果关系提取方面,基于规则与机器学习筛(RB + ML)的组合在TempEval-3评价中达到0.622 F1-score,其中ML成分有助于提升高精度的RB部分的召回率。 ML模块的低精度主要是由于依赖解析信号歧义中的错误和问题 ,例如在“ ...passenger cars in China was on track to hit [400 million] T by 2030, up from [90 million]s now”中的from。不幸的是,在TimeBank-Dense测试集的20个文档中,总共有5个gold CLINKs,但没有一个被CATENA识别出来。
6.2 Interaction between Temporal and Causal Relations
- 如图1所示,CLINK分类器使用时间推理器返回的E-E标签作为特征,这些特征的因果关系随后用于事后编辑TLINK标签。 我们通过ablation test,从CLINK分类器使用的特征中去除TLINK类型,来评估第一步的影响。 我们只分析TempEval-3评估的结果,因为在TimeBank-Dense测试语料中没有发现因果联系。 在没有TLINK类型的情况下,f1得分从0.622下降到0.571,召回率从0.538下降到0.462。 这表明时间信息有利于事件间因果关系的分类,特别是在召回率方面。
- 对于使用CLINKs对TLINK后期编辑的评价,系统在测试集中识别出19个因果链接,并将它们传递给时态模块。 其中15个已经与BEFORE/AFTER标签一致,3个会添加新的正确的TLINKs,这些TLINKs目前没有标注在评价语料库中,并且被CATENA的时态模块错误标注,如表4所示。 第四个则是在“cloaked”和“coughin”之间加上“BEFORE”的关系,“一种类似于火山烟雾的烟雾[遮蔽]S首都,导致抽搐的[咳嗽]T…”。 这种关系在gold standard中被称为INCLUDES,但我们相信BEFORE也将是正确的。
7 Conclusions
我们提出了CATENA,一个混合系统,用于提取和分类文本中的时间和因果关系,我们免费提供给研究团体。 我们在时序和因果模块上采用了基于筛选的架构,集成了基于规则和机器学习组件。 这两个模块分别进行了评估,结果显示,它们在不同的任务上都取得了最先进的性能。 此外,还分析了时间和因果成分之间的交互作用,特别是从一个模块传递信息到另一个模块的好处。
该系统依赖于TimeML标准中定义的事件概念,因此可以很容易地将时间和因果信息联系起来。 虽然因果性和时间性之间的相互作用从理论的观点看来可能是显而易见的,但CATENA允许系统的研究和量化这一现象。 如果同时考虑了隐含的因果关系,本文提出的方法可能会产生更大的影响,但我们没有考虑到这一点,因为它没有在Causal-TimeBank语料库中进行注释。 然而,我们计划在不久的将来调查这个问题。
本文来自博客园,作者:Un-Defined,转载请保留本文署名Un-Defined,并在文章顶部注明原文链接:https://www.cnblogs.com/EIPsilly/p/15854123.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号