
大数据开发技术基础
《大数据开发技术基础》复习
题型:选择题(30分)、简答题(20分)、分析论述题(20分)、编程题(30分)
考试范围:
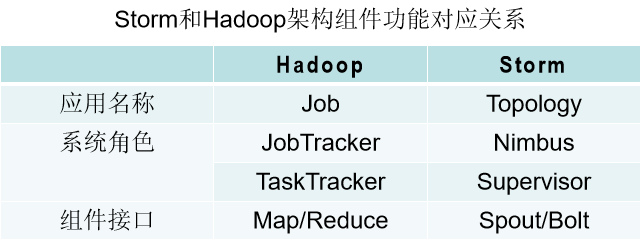
1、 大数据概述
2、 Linux基础知识及相关命令
3、 分布式文件系统HDFS
4、 分布式数据库HBase(含MySQL)
5、 NoSQL数据库
6、 MapReduce
7、 大数据处理架构Hadoop
8、 Spark
9、 流计算
10、数据仓库Hive
11、大数据在不同领域的应用
一、 Linux基本部分
ls, vi,rm, exit, top, cp, cat, tac, nl, mkdir, rmdir, tree, ls, pwd, ln, tail, mv, tar, file, find等等,详见课件。
mkdir
Linux mkdir(英文全拼:make directory)命令用于创建目录。
mkdir [-p] dirName
参数说明:
- -p 确保目录名称存在,不存在的就建一个。
rmdir
Linux rmdir(英文全拼:remove directory)命令删除空的目录。
rmdir [-p] dirName
参数:
- -p 是当子目录被删除后使它也成为空目录的话,则顺便一并删除。
cp
Linux cp(英文全拼:copy file)命令主要用于复制文件或目录。
cp [options] source dest
或
cp [options] source... directory
参数说明:
- -a:此选项通常在复制目录时使用,它保留链接、文件属性,并复制目录下的所有内容。其作用等于dpR参数组合。
- -d:复制时保留链接。这里所说的链接相当于 Windows 系统中的快捷方式。
- -f:覆盖已经存在的目标文件而不给出提示。
- -i:与 -f 选项相反,在覆盖目标文件之前给出提示,要求用户确认是否覆盖,回答 y 时目标文件将被覆盖。
- -p:除复制文件的内容外,还把修改时间和访问权限也复制到新文件中。
- -r:若给出的源文件是一个目录文件,此时将复制该目录下所有的子目录和文件。
- -l:不复制文件,只是生成链接文件。
实例
使用指令 cp 将当前目录 test/ 下的所有文件复制到新目录 newtest 下,输入如下命令:
$ cp –r test/ newtest
注意:用户使用该指令复制目录时,必须使用参数 -r 或者 -R 。
mv
Linux mv(英文全拼:move file)命令用来为文件或目录改名、或将文件或目录移入其它位置。
mv [options] source dest
mv [options] source... directory
参数说明:
- -b: 当目标文件或目录存在时,在执行覆盖前,会为其创建一个备份。
- -i: 如果指定移动的源目录或文件与目标的目录或文件同名,则会先询问是否覆盖旧文件,输入 y 表示直接覆盖,输入 n 表示取消该操作。
- -f: 如果指定移动的源目录或文件与目标的目录或文件同名,不会询问,直接覆盖旧文件。
- -n: 不要覆盖任何已存在的文件或目录。
- -u:当源文件比目标文件新或者目标文件不存在时,才执行移动操作。
mv 参数设置与运行结果
| 命令格式 | 运行结果 |
|---|---|
mv source_file(文件) dest_file(文件) |
将源文件名 source_file 改为目标文件名 dest_file |
mv source_file(文件) dest_directory(目录) |
将文件 source_file 移动到目标目录 dest_directory 中 |
mv source_directory(目录) dest_directory(目录) |
目录名 dest_directory 已存在,将 source_directory 移动到目录名 dest_directory 中;目录名 dest_directory 不存在则 source_directory 改名为目录名 dest_directory |
mv source_directory(目录) dest_file(文件) |
出错 |
实例
将文件 aaa 改名为 bbb :
mv aaa bbb
将 info 目录放入 logs 目录中。注意,如果 logs 目录不存在,则该命令将 info 改名为 logs。
mv info/ logs
再如将 /usr/runoob 下的所有文件和目录移到当前目录下,命令行为:
$ mv /usr/runoob/* .
top
Linux top命令用于实时显示 process 的动态。
使用权限:所有使用者。
tac
tac与cat命令刚好相反,文件内容从最后一行开始显示,可以看出 tac 是 cat 的倒着写!如:
nl
显示的时候,顺道输出行号!
语法:
nl [-bnw] 文件
选项与参数:
- -b :指定行号指定的方式,主要有两种:
-b a :表示不论是否为空行,也同样列出行号(类似 cat -n);
-b t :如果有空行,空的那一行不要列出行号(默认值); - -n :列出行号表示的方法,主要有三种:
-n ln :行号在荧幕的最左方显示;
-n rn :行号在自己栏位的最右方显示,且不加 0 ;
-n rz :行号在自己栏位的最右方显示,且加 0 ; - -w :行号栏位的占用的位数。
tar
参数:
-c :建立一个压缩文件的参数指令(create 的意思);
-x :解开一个压缩文件的参数指令!
-t :查看 tarfile 里面的文件!
特别注意,在参数的下达中, c/x/t 仅能存在一个!不可同时存在!
因为不可能同时压缩与解压缩。
-z :是否同时具有 gzip 的属性?亦即是否需要用 gzip 压缩?
-j :是否同时具有 bzip2 的属性?亦即是否需要用 bzip2 压缩?
-v :压缩的过程中显示文件!这个常用,但不建议用在背景执行过程!
-f :使用档名,请留意,在 f 之后要立即接档名喔!不要再加参数!
例如使用『 tar -zcvfP tfile sfile』就是错误的写法,要写成
『 tar -zcvPf tfile sfile』才对喔!
-p :使用原文件的原来属性(属性不会依据使用者而变)
-P :可以使用绝对路径来压缩!
-N :比后面接的日期(yyyy/mm/dd)还要新的才会被打包进新建的文件中!
--exclude FILE:在压缩的过程中,不要将 FILE 打包!
范例:
范例一:将整个 /etc 目录下的文件全部打包成为 /tmp/etc.tar
[root@linux ~]# tar -cvf /tmp/etc.tar /etc <==仅打包,不压缩!
[root@linux ~]# tar -zcvf /tmp/etc.tar.gz /etc <==打包后,以 gzip 压缩
[root@linux ~]# tar -jcvf /tmp/etc.tar.bz2 /etc <==打包后,以 bzip2 压缩
特别注意,在参数 f 之后的文件档名是自己取的,我们习惯上都用 .tar 来作为辨识。
如果加 z 参数,则以 .tar.gz 或 .tgz 来代表 gzip 压缩过的 tar file ~
如果加 j 参数,则以 .tar.bz2 来作为附档名啊~
上述指令在执行的时候,会显示一个警告讯息:
『tar: Removing leading `/' from member names』那是关於绝对路径的特殊设定。
范例二:查阅上述 /tmp/etc.tar.gz 文件内有哪些文件?
[root@linux ~]# tar -ztvf /tmp/etc.tar.gz
由於我们使用 gzip 压缩,所以要查阅该 tar file 内的文件时,
就得要加上 z 这个参数了!这很重要的!
范例三:将 /tmp/etc.tar.gz 文件解压缩在 /usr/local/src 底下
[root@linux ~]# cd /usr/local/src
[root@linux src]# tar -zxvf /tmp/etc.tar.gz
在预设的情况下,我们可以将压缩档在任何地方解开的!以这个范例来说,
我先将工作目录变换到 /usr/local/src 底下,并且解开 /tmp/etc.tar.gz ,
则解开的目录会在 /usr/local/src/etc 呢!另外,如果您进入 /usr/local/src/etc
则会发现,该目录下的文件属性与 /etc/ 可能会有所不同喔!
范例四:在 /tmp 底下,我只想要将 /tmp/etc.tar.gz 内的 etc/passwd 解开而已
[root@linux ~]# cd /tmp
[root@linux tmp]# tar -zxvf /tmp/etc.tar.gz etc/passwd
我可以透过 tar -ztvf 来查阅 tarfile 内的文件名称,如果单只要一个文件,
就可以透过这个方式来下达!注意到! etc.tar.gz 内的根目录 / 是被拿掉了!
范例五:将 /etc/ 内的所有文件备份下来,并且保存其权限!
[root@linux ~]# tar -zxvpf /tmp/etc.tar.gz /etc
这个 -p 的属性是很重要的,尤其是当您要保留原本文件的属性时!
范例六:在 /home 当中,比 2005/06/01 新的文件才备份
[root@linux ~]# tar -N '2005/06/01' -zcvf home.tar.gz /home
范例七:我要备份 /home, /etc ,但不要 /home/dmtsai
[root@linux ~]# tar --exclude /home/dmtsai -zcvf myfile.tar.gz /home/* /etc
范例八:将 /etc/ 打包后直接解开在 /tmp 底下,而不产生文件!
[root@linux ~]# cd /tmp
[root@linux tmp]# tar -cvf - /etc | tar -xvf -
这个动作有点像是 cp -r /etc /tmp 啦~依旧是有其有用途的!
要注意的地方在於输出档变成 - 而输入档也变成 - ,又有一个 | 存在~
这分别代表 standard output, standard input 与管线命令啦!
这部分我们会在 Bash shell 时,再次提到这个指令跟大家再解释啰!
tree
Linux tree命令用于以树状图列出目录的内容。
执行tree指令,它会列出指定目录下的所有文件,包括子目录里的文件。
ln
https://www.runoob.com/linux/linux-comm-ln.html
Linux ln(英文全拼:link files)命令是一个非常重要命令,它的功能是为某一个文件在另外一个位置建立一个同步的链接。
当我们需要在不同的目录,用到相同的文件时,我们不需要在每一个需要的目录下都放一个必须相同的文件,我们只要在某个固定的目录,放上该文件,然后在 其它的目录下用ln命令链接(link)它就可以,不必重复的占用磁盘空间。
语法
ln [参数][源文件或目录][目标文件或目录]
命令参数:
- 必要参数:
- -b 删除,覆盖以前建立的链接
- -d 允许超级用户制作目录的硬链接
- -f 强制执行
- -i 交互模式,文件存在则提示用户是否覆盖
- -n 把符号链接视为一般目录
- -s 软链接(符号链接)
- -v 显示详细的处理过程
- 选择参数:
- -S "-S<字尾备份字符串> "或 "--suffix=<字尾备份字符串>"
- -V "-V<备份方式>"或"--version-control=<备份方式>"
- --help 显示帮助信息
- --version 显示版本信息
tail
tail 命令可用于查看文件的内容,有一个常用的参数 -f 常用于查阅正在改变的日志文件。
tail -f filename 会把 filename 文件里的最尾部的内容显示在屏幕上,并且不断刷新,只要 filename 更新就可以看到最新的文件内容。
命令格式:
tail [参数] [文件]
参数:
- -f 循环读取
- -q 不显示处理信息
- -v 显示详细的处理信息
- -c<数目> 显示的字节数
- -n<行数> 显示文件的尾部 n 行内容
- --pid=PID 与-f合用,表示在进程ID,PID死掉之后结束
- -q, --quiet, --silent 从不输出给出文件名的首部
- -s, --sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒
file
https://www.runoob.com/linux/linux-comm-file.html
Linux file命令用于辨识文件类型。
通过file指令,我们得以辨识该文件的类型。
语法
file [-bcLvz][-f <名称文件>][-m <魔法数字文件>...][文件或目录...]
参数:
- -b 列出辨识结果时,不显示文件名称。
- -c 详细显示指令执行过程,便于排错或分析程序执行的情形。
- -f<名称文件> 指定名称文件,其内容有一个或多个文件名称时,让file依序辨识这些文件,格式为每列一个文件名称。
- -L 直接显示符号连接所指向的文件的类别。
- -m<魔法数字文件> 指定魔法数字文件。
- -v 显示版本信息。
- -z 尝试去解读压缩文件的内容。
- [文件或目录...] 要确定类型的文件列表,多个文件之间使用空格分开,可以使用shell通配符匹配多个文件。
find
https://www.runoob.com/linux/linux-comm-find.html
Linux find 命令用来在指定目录下查找文件。任何位于参数之前的字符串都将被视为欲查找的目录名。如果使用该命令时,不设置任何参数,则 find 命令将在当前目录下查找子目录与文件。并且将查找到的子目录和文件全部进行显示。
语法
find path -option [ -print ] [ -exec -ok command ] {} \;
参数说明 :
find 根据下列规则判断 path 和 expression,在命令列上第一个 - ( ) , ! 之前的部份为 path,之后的是 expression。如果 path 是空字串则使用目前路径,如果 expression 是空字串则使用 -print 为预设 expression。
expression 中可使用的选项有二三十个之多,在此只介绍最常用的部份。
-mount, -xdev : 只检查和指定目录在同一个文件系统下的文件,避免列出其它文件系统中的文件
-amin n : 在过去 n 分钟内被读取过
-anewer file : 比文件 file 更晚被读取过的文件
-atime n : 在过去n天内被读取过的文件
-cmin n : 在过去 n 分钟内被修改过
-cnewer file :比文件 file 更新的文件
-ctime n : 在过去n天内被修改过的文件
-empty : 空的文件-gid n or -group name : gid 是 n 或是 group 名称是 name
-ipath p, -path p : 路径名称符合 p 的文件,ipath 会忽略大小写
-name name, -iname name : 文件名称符合 name 的文件。iname 会忽略大小写
-size n : 文件大小 是 n 单位,b 代表 512 位元组的区块,c 表示字元数,k 表示 kilo bytes,w 是二个位元组。
-type c : 文件类型是 c 的文件。
d: 目录
c: 字型装置文件
b: 区块装置文件
p: 具名贮列
f: 一般文件
l: 符号连结
s: socket
-pid n : process id 是 n 的文件
概念与分析论述(见书后习题)
1. 大数据决策与传统的基于数据仓库的决策
数据仓库具备批量和周期性的数据加载以及数据变化的实时探测、传播和加载能力,能结合历史数据和实时数据实现查询分析和自动规则触发,从而提供战略决策和战术决策。 大数据决策可以面向类型繁多的、非结构化的海量数据进行决策分析
2. 大数据、云计算和物联网
大数据
大数据的特点
数据量大
数据类型繁多:包括结构化数据和非结构化数据
处理速度快
价值密度低
大数据的影响
对科学研究的影响:实验->理论->计算->数据。
在思维方式方面,大数据具有”全面而非抽样、效率而非精确、相关而非因果“三大显著特征。
社会、就业、人才培养等方面的影响
云计算
1. 云计算概念
云计算实现了通过网络提供可伸缩的、廉价的分布式计算能力,用户只需要在具备网络接入条件的地方,就可以随时随地获得所需的各种IT资源
云计算包括三种典型服务 :IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)。
云计算包括公有云、私有云、混合云三种类型
2.云数据关键技术
虚拟化、分布式存储、分布式计算、多租户
3.云计算数据中心
数据中心是云计算的重要载体,为云计算提供计算、存储、带宽等各种硬件资源
物联网
1.物联网概念
物联网是物物相连的互联网,是互联网的延伸,它利用局部网络或互联网等通信技术把传感器、控制器、机器、人员和物等通过新的方式联在一起,形成人与物、物与物相联,实现信息化和远程管理控制
云计算、大数据和物联网代表了IT领域最新的技术发展趋势,三者既有区别又有联系
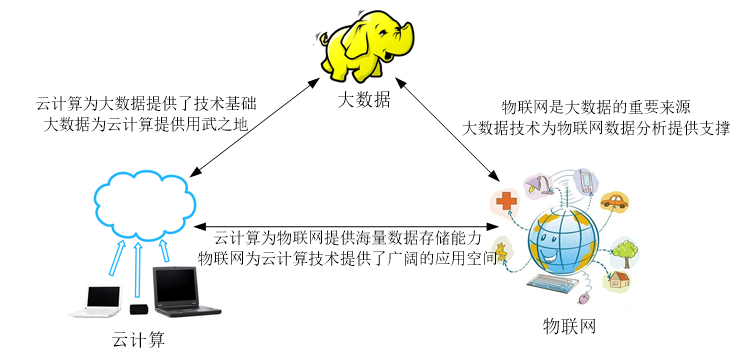
区别:
大数据侧重于对海量数据的存储、处理和分析,从海量数据中发现价值,服务于生产和生活;
云计算本质上旨在整合和优化各种IT资源,并通过网络以服务的方式廉价地提供给用户;
物联网的发展目标是实现物物相连,应用创新是物联网发展的核心
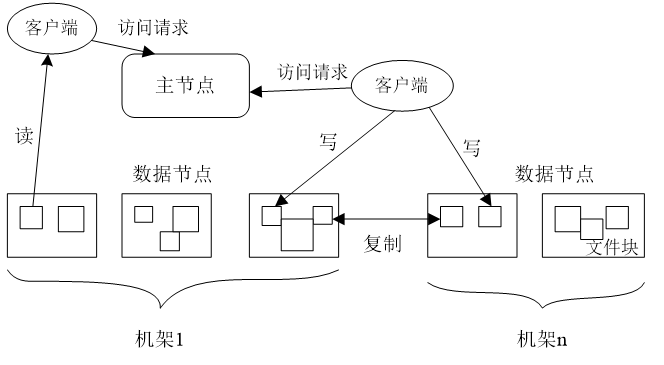
3. HDFS中的名称节点和数据节点
分布式文件系统在物理结构上是由计算机集群中的多个节点构成的。这些节点分为两类。
名称节点负责文件和目录的创建、删除和重命名等,同时管理着数据节点和数据块的映射关系,因此客户端只有访问名称节点才能找到请求的数据块所在的位置,进而到相应位置读取所需数据块。
数据节点负责数据的存储和读取。在存储时,名称节点分配存储位置,然后由客户端把数据直接写入相应的数据节点;在读取时,客户端从名称节点获得数据节点和文件块的映射关系,然后就可以到相应位置访问文件块。数据节点也要根据名称节点的命令创建、删除数据块和冗余复制。数据节点会向名称节点定期发送自己所存储的块的列表。
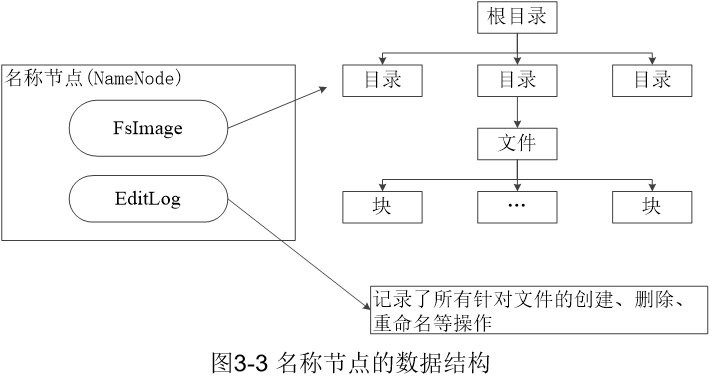
名称节点负责管理分布式文件系统的命名空间,保存了两个核心的数据结构(FsImage和EditLog)。FSImage用于维护文件系统树以及文件系统树中所有的文件与文件夹的元数据;操作日志文件EditLog中记录了所有针对文件的创建、删除、重命名操作。名称节点记录了每个文件中各个块所在的数据节点的位置信息,在系统每次启动时扫描所有数据节点重构得到这些信息。
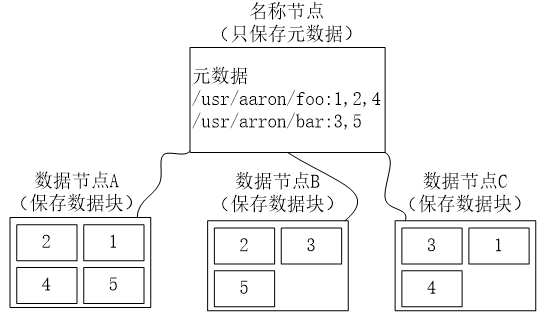
4. HDFS的冗余数据保存策略
采用多副本方式对数据进行冗余存储,通常一个数据块的多个副本会被分到不同的数据节点上。
- 加快数据传输速度:让客户端分别从不同的数据块副本中读取数据
- 容易检查数据错误:多副本容易判断是否出错
- 保证数据的可靠性:某个节点出现故障也不会造成数据丢失
5. HDFS是探测错误发生以及恢复
1. 名称节点出错
Hadoop采用两种机制来确保名称节点的安全:
- 把名称节点上的元数据信息同步存储到其他文件系统
- 运行一个第二名称节点,名称节点宕机之后,利用第二名称节点中的原数据信息进行系统恢复(仍然会丢失部分数据)
2. 数据节点出错
数据节点定期向名称节点发送“心跳”信息。发生故障或断网时,名称节点收不到“心跳”,把数据节点标记为“宕机”,节点上的所有数据标记为“不可读”,不再发送I/O请求。
名称节点定期检查一些数据块的副本数量是否小于冗余因子,如果小于,名称节点启动数据冗余复制,生成新的副本。
3. 数据出错
文件被创建时,客户端就会对每一个文件块进行信息摘录,并把这些信息写入同一个路径的隐藏文件中。客户端读取文件时,会先读取该信息文件,然后利用该信息文件对每个读取的数据块进行md5和sha1校验,如果校验出错,客户端就会请求到另一个数据节点读取该文件块,并向名称节点报告这个文件块有错误,名称节点会定期检查并重新复制这个块。
6. HDFS在正常情况下读\写文件过程
读数据的过程
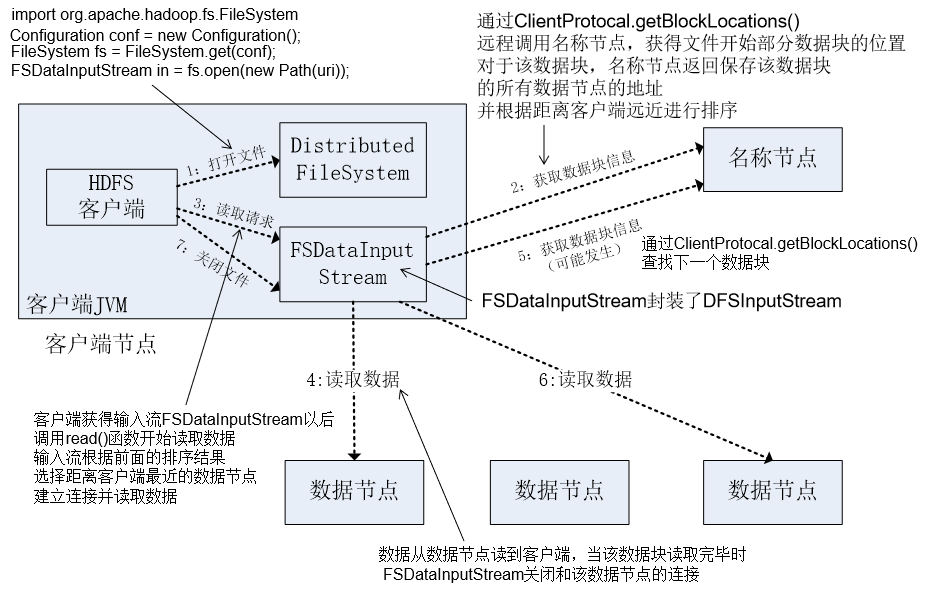
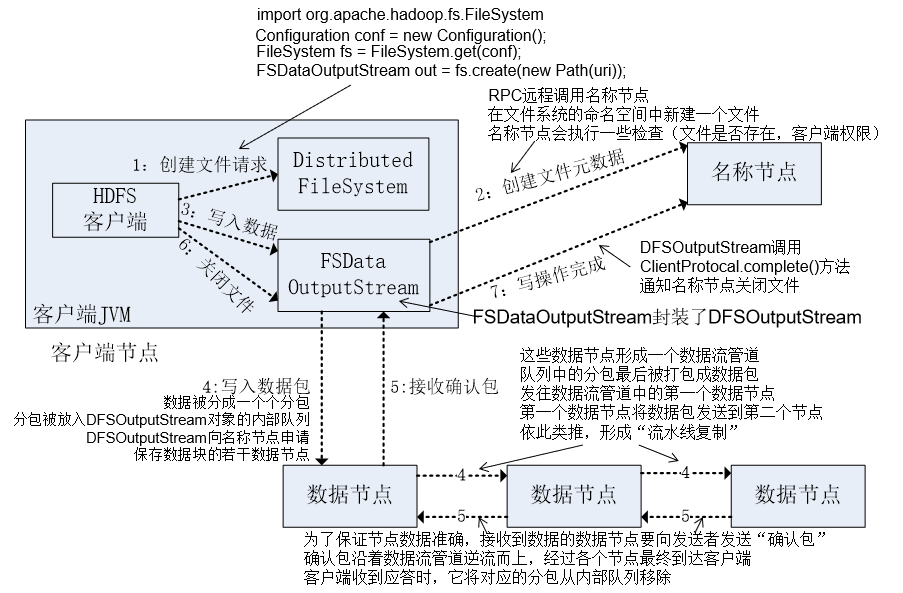
写数据的过程
7. HBase和BigTable
HBase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,是谷歌BigTable的开源实现,主要用来存储非结构化和半结构化的松散数据。Hbase的目标是处理非常庞大的表。
HBase利用Hadoop MapReduce来处理HBase中的海量数据,实现高性能计算;利用Zookeeper作为协同服务,实现稳定服务和失败恢复;使用HDFS作为高可靠的底层存储,利用廉价集群提供海量数据存储能力; Sqoop为HBase提供了高效便捷的RDBMS数据导入功能,Pig和Hive为HBase提供了高层语言支持。
| 项目 | BigTable | HBase |
|---|---|---|
| 文件存储系统 | GFS | HDFS |
| 海量数据处理 | MapReduce | Hadoop MapReduce |
| 协同服务管理 | Chubby | Zookeeper |
8. HBase和传统关系数据库
| 区别 | 传统关系数据库 | HBase |
|---|---|---|
| 数据类型 | 关系模型 | 数据模型 |
| 数据操作 | 增删查改、多表连接 | 增删查,无法实现表与表之间关联 |
| 存储模式 | 基于行模式存储,元组或行会被连续地存储在磁盘也中 | 基于列存储,每个列族都由几个文件保存,不同列族的文件是分离的 |
| 数据索引 | 针对不同列构建复杂的多个索引 | 只有一个行键索引 |
| 数据维护 | 用最新的当前值去替换记录中原来的旧值 | 更新操作不会删除数据旧的版本,而是生成一个新的版本 |
| 可伸缩性 | 很难实现横向扩展,纵向扩展的空间也比较有限 | 轻易地通过在集群中增加或者减少硬件数量来实现性能的伸缩 |
HBase不支持事务,无法实现跨行的原子性
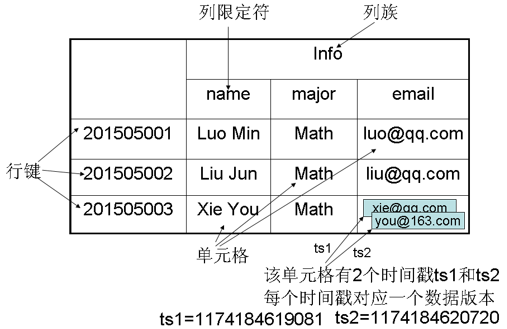
9. HBase中行键、列族和时间戳
HBase实际上就是一个稀疏、多维、持久化存储的映射表,它采用行键、列族、列限定符和时间戳进行索引,每个值都是byte[]
1.行
每个HBase都由若干行组成,每个行由行键来表示。访问表中的行有3种方式:通过单个行键访问;通过一个行键的区间来访问;全表扫描。行键可以是任意字符串,在HBase中,行键保存为字节数组。存储时,数据按照行键的字典序排序存储。
2.列族
一个HBase表被分组成许多“列族”的集合,它是基本的访问控制单元。列族需要在表创建时就定义好,数量不宜太多(限制于几十个),不需要频繁修改。
在HBase中,访问控制、磁盘和内存的使用统计都是在列族层面上进行的。
3.时间戳
每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引。
10. HBase的概念视图和物理视图
概念视图
稀疏、多维的映射关系
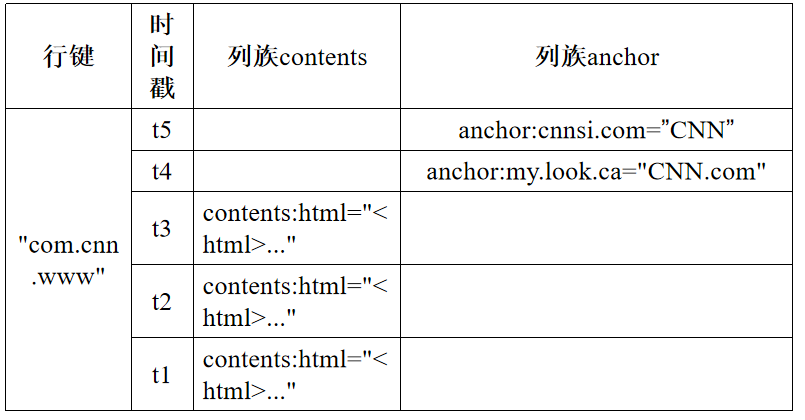
物理视图
属于同一个列族的数据保存在一起,和每个列族一起存放的还包括行键和时间戳

11. HBase的数据分区机制
根据行键的值对表中的行进行分区,每个行区构成一个分区,被称为“Region”,包含了位于某个值域区间内的所有数据,它是负载均衡和数据分发的基本单位,这些Region会被Master服务器分发到不同的Region服务器上。
初始每个表只包含一个Region,随着数据的不断插入,Region持续增大,达到阈值时就被自动等分成两个新的Region。
Region的默认大小是100MB到200MB。通常每个Region服务器放置10~1000个Region
12. 在HBase的三层结构下,客户端访问数据
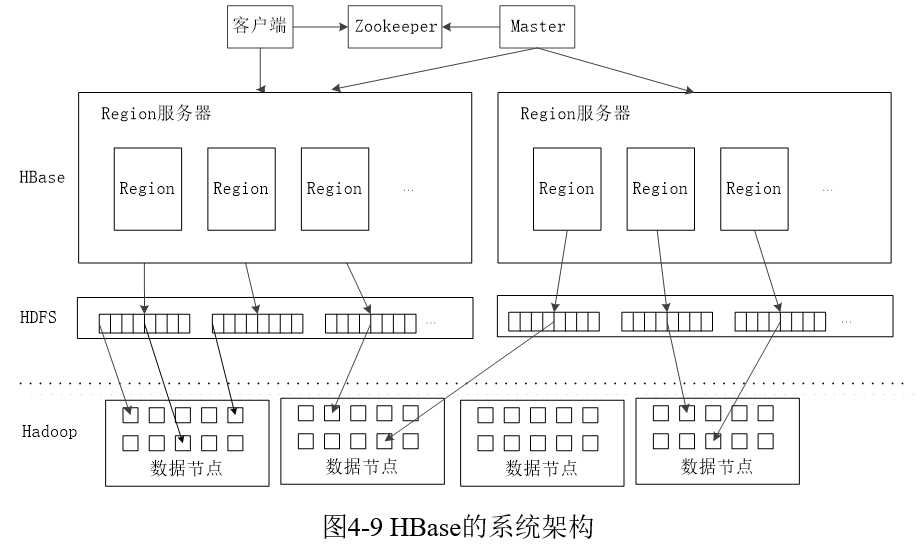
每个Region有一个RegionID来标识它的唯一性,一个Region的标识符可以表示成”表名+开始主键+RegionID“。
.META.表:又称元数据表。维护一张记录Region标识符和Region服务器标识关系的映射表。可以知道某个Region被保存在哪个Region服务器中。
-ROOT-表:又称根数据表。.META.表的条目非常多的时候,.META.表需要分割成多个Region。为了定位这些Region,需要在构建一个新的映射表即-ROOT-表,记录所有元数据的位置。-ROOT-表不能分割,只存在一个Region,该Region的名字在程序中写死,Master主服务器永远知道它的位置。
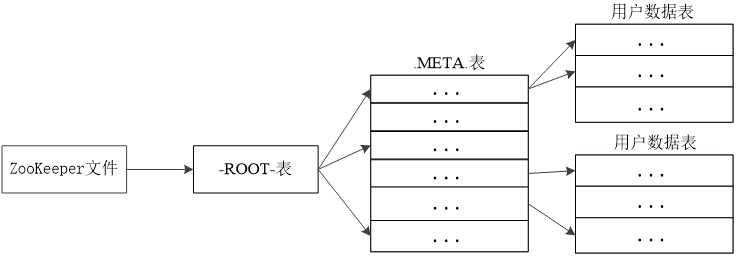
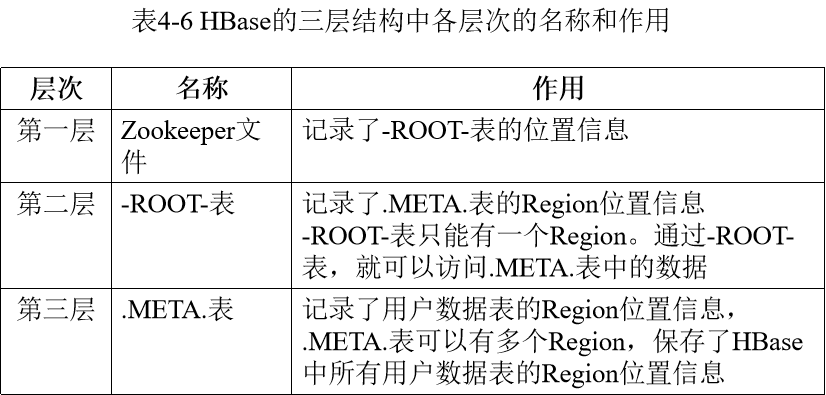
首先访问Zookeeper,获取-ROOT表的位置信息,然后访问-Root-表,获得.MATA.表的信息,接着访问.MATA.表,找到所需的Region具体位于哪个Region服务器,最后才会到该Region服务器读取数据。
13. Region服务器向HDFS文件系统中读写数据的基本原理
Region服务器内部管理了一系列Region对象和一个HLog文件,其中HLog是磁盘上面的记录文件,它记录着所有的更新操作。每个Region对象又是由多个Store组成的,每个Store对应了表中的一个列族的存储。每个Store又包含一个MemStore和若干个StoreFile。其中MemStore是在内存中的缓存,保存最近更新的数据;StoreFile是磁盘中的文件,这些文件都是B树结构,其底层实现方式是HDFS文件系统中的HFile,HFile的数据块通常采用压缩方式存储,大大减少网络I/O和磁盘I/O。
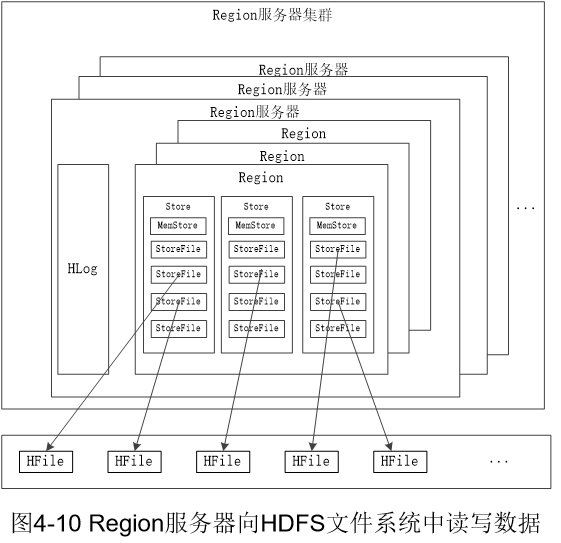
当用户写入数据时,会被分配到相应的Region服务器取执行操作。用户数据首先被写入到MemStore和HLog中,当操作写入HLog之后,commit()调用才会将其返回给客户端
当用户读取数据时,Region服务器会首先访问MemStore,如果数据不再缓存中,才会到磁盘上面的StoreFile中去找
14. HLog的工作原理
HBase系统为每个Region服务器配置了一个HLog文件,它是一种预写式日志(Write Ahead Log),用户更新数据必须首先写入日志后,才能写入MemStore缓存,并且,直到MemStore缓存内容对应的日志已经写入磁盘,该缓存内容才能被刷写到磁盘。
15. 在HBase中,每个region服务器维护一个HLog的优缺点
缺点:如果一个Region服务器发生故障,为了恢复其上次的Region对象,需要将Region服务器上的HLog按照其所属的Region对象进行拆分,然后分发到其他Region服务器上执行恢复操作。
优点:多个Region对象的更新操作所发生的日志修改,只需要不断把日志记录追加到单个日志文件中,不需要同时打开、写入到多个日志文件中,因此可以减少磁盘寻址次数,提高对表的写操作性能。
16. Region服务器意外终止情况的处理
Region发生故障时,Zookeeper通知Master,Master首先处理HLog文件。系统根据每条日志记录所属的Region对象将HLog数据进行拆分,分别放到相应Region对象的目录下,然后再将失效的Region重新分配到可用的Region服务器中,并把与该Region对象相关的HLog日志记录也发送给相应的Region服务器。Region服务器领取到分配给自己的Region对象以及与之相关的HLog日志记录以后,会重新做一遍日志记录中的各种操作,把日志记录中的数据写入MemStore缓存,然后刷新到磁盘的StoreFIle文件中,完成数据恢复。
17. 关系数据库和NoSQL数据库
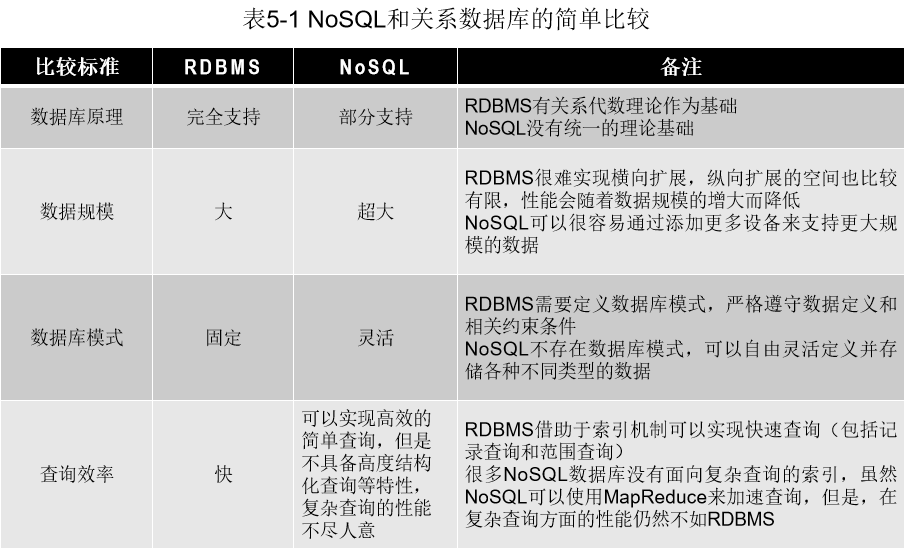
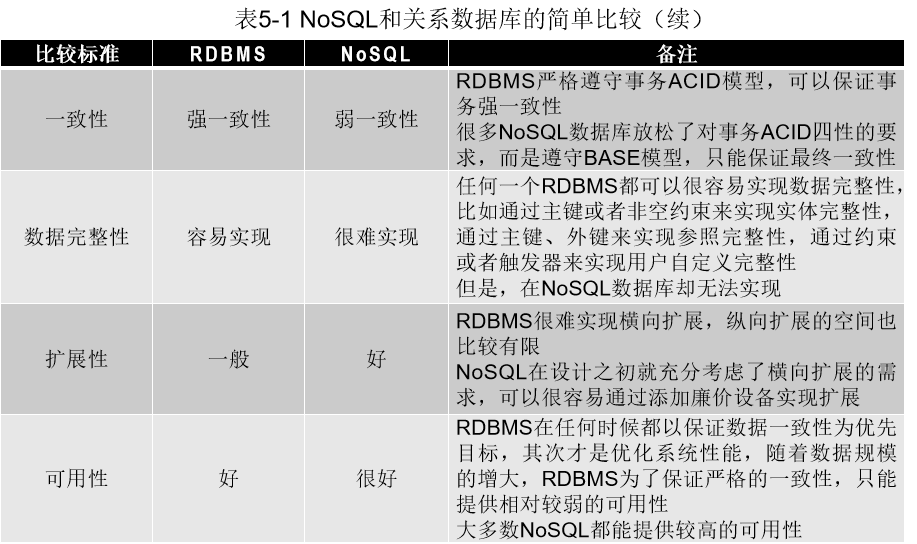
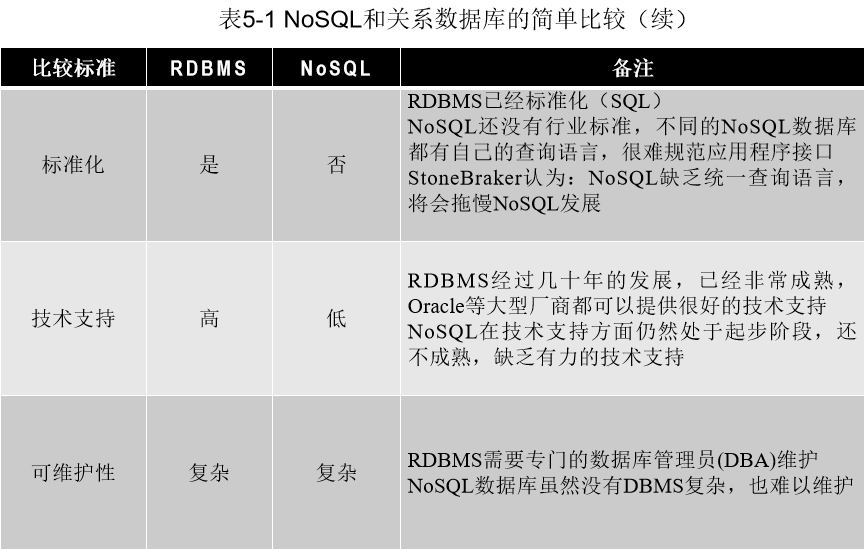
18. 键值数据库、列族数据库、文档数据库和图数据库的适用场合和优缺点
| 数据库 | 适用场合 | 优点 | 缺点 |
|---|---|---|---|
| 键值数据库 | 涉及频繁读写、拥有简单数据模型的应用 内容缓存,比如会话、配置文件、参数、购物车等 存储配置和用户数据信息的移动应用 | 扩展性好,灵活性好,大量写操作时性能高 | 无法存储结构化信息,条件查询效率较低 |
| 列族数据库 | 分布式数据存储与管理 数据在地理上分布于多个数据中心的应用程序 可以容忍副本中存在短期不一致情况的应用程序 拥有动态字段的应用程序 拥有潜在大量数据的应用程序,大到几百TB的数据 | 查找速度快,可扩展性强,容易进行分布式扩展,复杂性低 | 功能较少,大都不支持强事务一致性 |
| 文档数据库 | 存储、索引并管理面向文档的数据或者类似的半结构化数据 比如,用于后台具有大量读写操作的网站、使用JSON数据结构的应用、使用嵌套结构等非规范化数据的应用程序 | 性能好(高并发),灵活性高,复杂性低,数据结构灵活 提供嵌入式文档功能,将经常查询的数据存储在同一个文档中 既可以根据键来构建索引,也可以根据内容构建索引 | 缺乏统一的查询语法 |
| 图形数据库 | 专门用于处理具有高度相互关联关系的数据,比较适合于社交网络、模式识别、依赖分析、推荐系统以及路径寻找等问题 | 灵活性高,支持复杂的图形算法,可用于构建复杂的关系图谱 | 复杂性高,只能支持一定的数据规模 |
19. JobTracker和TaskTracker的功能
MapReduce框架采用了Master/Slave架构,包括一个Master和若干个Slave。Master上运行JobTracker,Slave上运行TaskTracker
MapReduce体系结构主要由四个部分组成,分别是:Client、JobTracker、TaskTracker以及Task
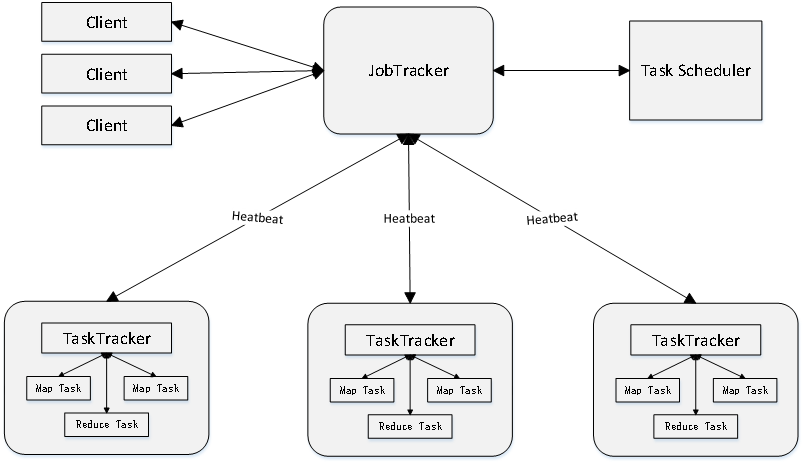
-
Client
用户编写的MapReduce程序通过Client提交到JobTracker端
用户可通过Client提供的一些接口查看作业运行状态
-
JobTracker
JobTracker负责资源监控和作业调度
JobTracker 监控所有TaskTracker与Job的健康状况,一旦发现失败,就将相应的任务转移到其他节点
JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器(TaskScheduler),而调度器会在资源出现空闲时,选择合适的任务去使用这些资源
-
TaskTracker
TaskTracker 会周期性地通过“心跳”将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)
TaskTracker 使用“slot”等量划分本节点上的资源量(CPU、内存等)。一个Task 获取到一个slot 后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot 分为Map slot 和Reduce slot 两种,分别供MapTask 和Reduce Task 使用
-
Task
Task 分为Map Task 和Reduce Task 两种,均由TaskTracker 启动。在Hadoop MapReduce的实现中该进程的名称为Child
MapReduce框架采用了Master/Slave架构,包括一个Master和若干Slave,Master上运行JobTracker,Slave上运行TaskTracker,用户提交的每个计算作业,会被划分成若干个任务。JobTracker负责资源管理、任务调度和任务监控,会重新调度已经失败的任务。TaskTracker负责执行由JobTracker指派的任务。
MapReduce应用程序执行流程
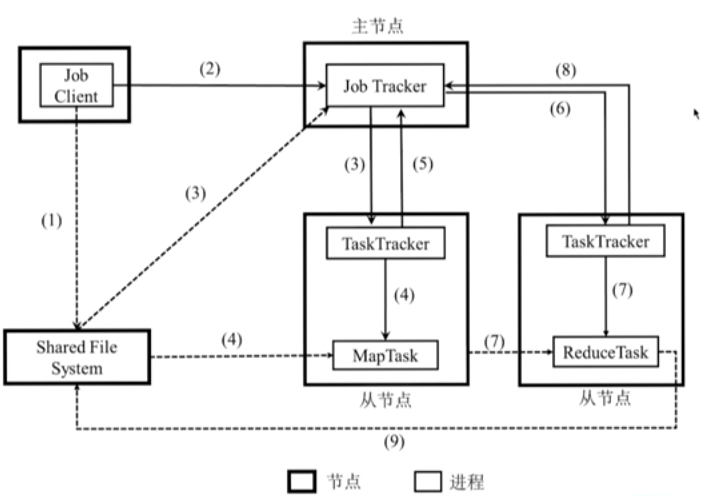
- Client将用户编写的MapReduce作业的配置信息、jar包等信息上传到共享文件系统,通常是HDFS。
- Client提交作业给JobTracker,即告知作业信息的位置。
- JobTracker读取作业的信息,生成一系列Map和Reduce任务,调度给拥有空闲slot的TaskTracker。
- TaskTracker根据JobTacker的指令启动Child进程执行Map任务,Map任务将从共享文件系统读取输入数据。
- JobTracker从TaskTracker处获得Map任务进度信息。
- 一旦Map任务完成后,JobTacker将Reduce任务分发给TaskTracker。
- TaskTracker根据JobTacker的指令启动Child进程执行Reduce任务,Reduce任务将从Map任务所在节点的本地磁盘拉取Map的输出结果。
- JobTracker从TaskTracker处获得Reduce任务进度信息。
- 当Reduce任务运行结束并将结果写入共享文件系统,则意味着整个作业执行完毕。
20. Map函数和Reduce函数的输入、输出以及处理过程
Map函数
Map函数的输入来自于分布式文件系统的文件块,这些文件块的格式是任意的,可以是文档,也可以是二进制格式的。文件块是一系列元素的集合,这些元素也是任意类型的,同一个元素不能跨越文件块存储。
Map函数将输入的元素转换成<key,value>形式的键值对,键和值的类型也是任意的,其中键没有唯一性,不能作为输出的身份标识。
Reduce函数
将输入的一系列具有相同键的键值对以某种方式组合起来,输出处理后的键值对,输出结果会合并成一个文件。
用户指定Reduce任务的个数(如n个),并通知实现系统,然后主控进程通常会选择一个Hash函数,Map任务输出的每个键都会经过Hash函数计算,并根据哈希结果将该键值对输入相应的Reduce任务来处理。对于处理键为k的Reduce任务的输入形式为<k,<v1,v2,...,vn>>,输出为<k,V>
21. MapReduce的工作流程(需包括提交任务、Map、Shuffle、Reduce的过程)
- MapReduce框架使用InputeFormat模块做Map前的预处理,比如验证输入的格式是否符合输入的定义;然后,将输入文件切分成逻辑上的多个InputSplit,InputSplit是MapReduce对文件进行处理和运算的输入单位,只是一个逻辑概念,每个InputSplit并没有对文件进行实际切割,只是记录了要处理的数据的位置和长度
- 因为InputSplit是逻辑切分而非物理切分,所以还需要通过RecordReader(RR)根据InputSplit中的信息来处理InputSplit中的具体记录,加载数据并转换为适合Map任务读取的键值对,输入给Map任务。
- Map任务会根据用户自定义的映射规则,输出一系列的<key,value>作为中间结果
- 为了让Reduce可以并行处理Map的结果,需要对Map的输出进行一定的分区、排序、合并、归并等操作,得到<key,value-list>形式的中间结果,再交给对应的Reduce进行处理。
- Reduce以一系列<key,value-list>中间结果作为输入,执行用户定义的逻辑,输出结果给OutputFormat模块
- OutputFormat模块会验证输出目录是否已经存在以及输出结果类型是否符合配置文件中的配置类型,如果都满足,就输出Reduce的结果到分布式文件系统
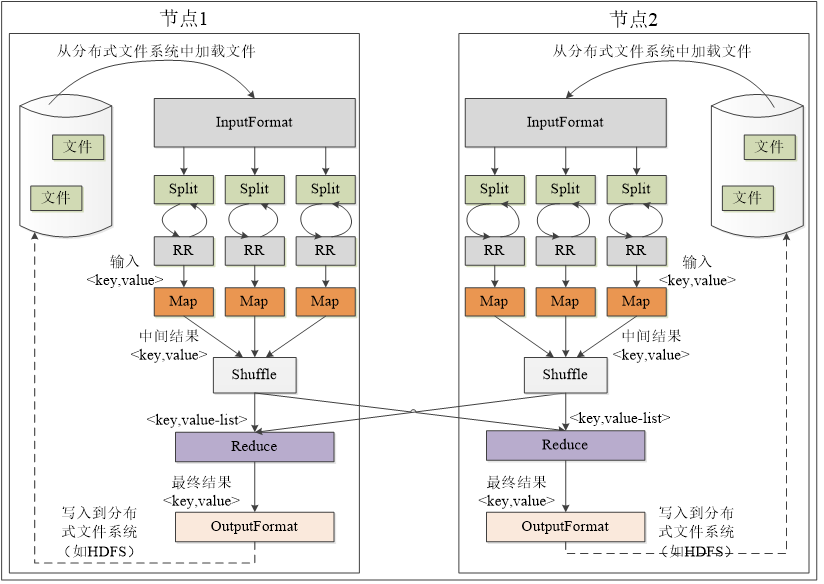
22. Map端和Reduce端的Shuffle过程(包括Spill、Sort、Merge、Fetch的过程)
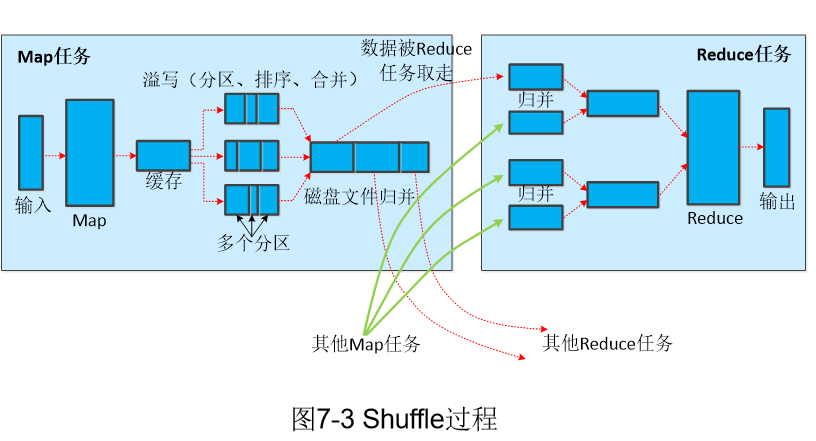
1.Map端的shuffle过程
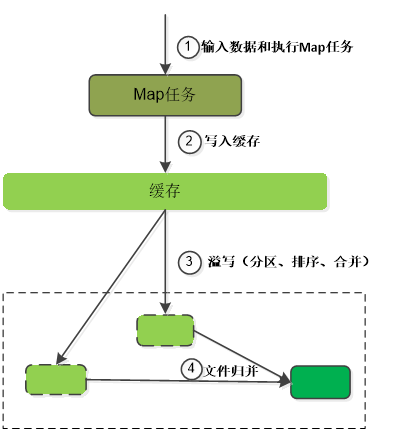
-
输入数据和执行Map任务
-
写入缓存
每个Map任务都分配有一个缓存,Map的输出结果不是立即写入磁盘,而是首先写入缓存。在缓存中累积一定数量的Map输出结果以后,在一次性批量写入磁盘,大大减少磁盘I/O开销。在写入缓存之前,key与value值都会被序列化成字节数组
-
溢写(分区、排序、合并)
缓存默认大小100MB。通常会设置一个溢写比例(比如0.8),缓存达到阈值时(100MB用了80MB),就会启动溢写操作(Spill),把缓存中的内容一次性写入磁盘并清空缓存。溢写的过程由另外一个单独的后台线程来完成,不影响Map结果写入缓存。
在溢写到磁盘之前,缓存中的数据首先会被分区。缓存中的数据是<key,value>键值对,MapReduce通过partitioner接口对这些键值进行分区,默认采用Hash函数对key进行哈希后再用Reduce任务的数量取模。
对于每个分区内的键值对,后台线程会根据key对他们进行内存排序(sort),排序是MapReduce的默认操作。排序结束后,还包含一个可选的合并(combine)操作。
“合并”是指将那些具有相同key的<key,value>的value加起来。比如<"xmu",1>和<"xmu",1>,经过合并操作以后得到一个键值对<"xmu",2>,减少了键值对的数量。Map端的合并操作与Reduce类似,但是由于操作发生在Map段,所以称之为“合并”,从而有别于Reduce。
经过分区、排序以及可能发生的合并操作之后,缓存中的键值对就可以被写入磁盘,并清空缓存。每次溢写操作都会生成一个新的溢写文件
-
文件归并
溢写文件会越来越多,在Map任务全部结束之前,系统会对所有溢写文件中的数据进行归并(Merge),生成一个大的溢写文件,大的溢写文件中的所有键值对也是经过分区和排序的。
“归并”是指具有相同key的键值对会被归并成一个新的键值对。具体而言,对于若干个具有相同key的键值对<k,v1>,<k,v2>,......,<k,vn>会被归并成一个新的键值对<k,<v1,v2,...,vn>>
另外进行文件归并时,如果磁盘中生成的溢写文件的数量超过参数min.num.spills.forcombine的值(默认是3),那么就可以再次运行Combiner函数,对数据进行合并操作,从而减少写入磁盘的数据量。
经过上述4个步骤,Map段的Shuffle过程全部完成,最终生成的一个大文件会被存放在本地磁盘上。这个大文件中的数据是被分区的,不同分区会被发送到不同的Reduce任务进行并行处理。JobTracker会一直监测Map任务的执行,当检测到一个Map任务完成后,就会立刻通知相关的Reduce任务来领取数据,然后开始Reduce段的Shuffle
2.Reduce端的Shuffle
从Map端读取Map结果,然后执行归并操作,最后输送给Reduce任务进行处理。
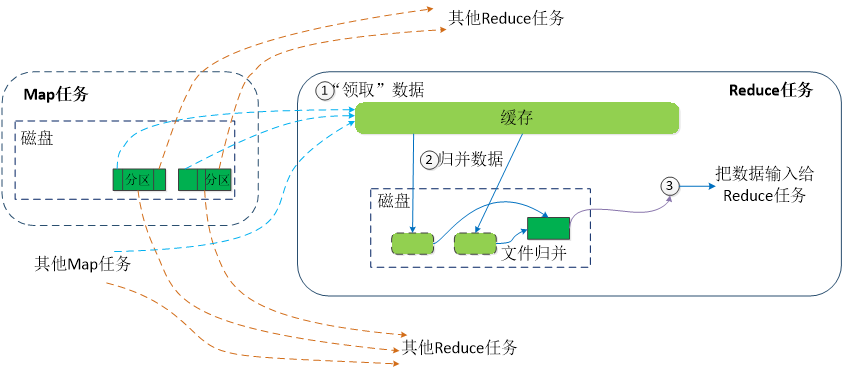
-
“领取”数据
Map端的Shuffle过程结束后,所有Map输出结果都保存在Map机器的本地磁盘上,Reduce任务需要把这些数据“领取”(Fetch)回来存放在自己所在机器的本地磁盘上。因此,在每个Reduce任务真正开始之前,它大部分时间都在从Map端把属于自己处理的那些分区的数据“领取”过来。每个Reduce任务会不断地通过RPC向JobTracker询问Map任务是否已经完成;JobTracker检测到一个Map任务完成后,就会通知相关的Reduce任务来“领取数据”;一旦一个Reduce任务收到JobTracker的通知,它就会到Map任务所在机器上把属于自己处理的分区数据领取到本地磁盘中。一般系统中会有多个Map机器,因此Reduce任务会使用多个线程同时从多个Map机器领回数据
-
归并数据
从Map端领回的数据首先被存放在Reduce任务所在机器的缓存中,如果缓存被占满,就溢写到磁盘中。当溢写过程启动时,具有相同key的键值对会被归并(Merge),如果用户定义了Combiner,则归并后的数据还可以执行合并操作,减少写入磁盘的数据量。溢写结束后会在磁盘上生成一个溢写文件。当所有数据都被领回时,多个溢写文件会被归并成一个大文件,归并时还会对键值对进行排序。每轮归并操作可以归并的文件数量是由参数io.sort.factor的值来控制(默认10)。(假设50个溢写文件,每轮归并10个,则需要经过5轮归并,得到5个归并后的大文件,不会继续归并成一个新的大文件)
-
把数据输入给Reduce任务
磁盘中经过多轮归并后得到若干大文件,直接输入给Reduce任务。
23. MapReduce程序的中间结果存储在本地磁盘而不是HDFS上有何优缺点
因为Map的输出是中间的结果,这个中间结果是由reduce处理后才产生最终输出结果,而且一旦作业完成,map的输出结果就可以删除。如果把它存储在hdfs中就并备份,有些小题大作,如果运行map任务的节点将map中间结果传送给reduce任务之前失败,hadoop将在另一个节点上重新运行这个map任务以再次构建中间结果。
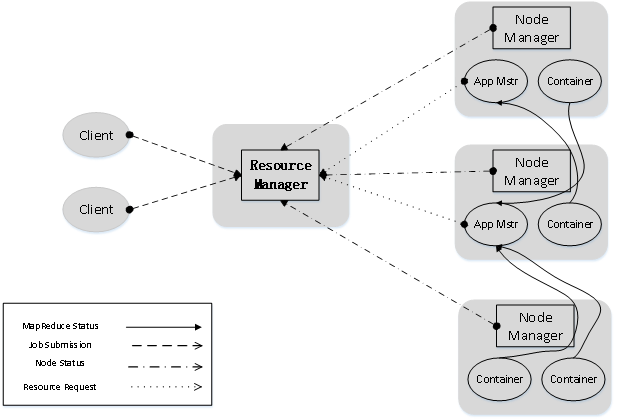
24. 在YARN框架中执行一个MapReduce程序时,从提交到完成需要经历的具体步骤
YARN包括ResourceManager、ApplicationMaster和NodeManager。ResourceManage负责资源管理,ApplicationMaster负责任务调度和监控,NodeManager负责执行原TaskTracker的任务。
ResourceManager
功能:
- 处理客户端请求
- 启动/监控ApplicationMaster
- 监控NodeManager
- 资源分配与调度
包括两个组件:调度器(Scheduler)和应用程序管理器(Applications Manager)。
调度器主要负责资源管理和分配。调度器接受来自ApplicationMaster的应用程序资源请求,并根据容量、队列等限制条件,把集群中的资源以“容器”的形式分配给提出申请的应用程序,容器的选择通常会考虑应用程序所要处理的数据的位置,就近选择(计算向数据靠拢)。每个容器封装有一定数量的CPU、内存、磁盘等资源。
应用程序管理器负责系统中所有应用程序的管理工作,主要包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动等
在Hadoop平台上,用户的应用程序是以作业(Job)的形式提交的,然后一个作业会被分解成多个任务(包括Map任务和Reduce任务)进行分布式执行。ResourceManager接受用户提交的作业,按照作业的上下文信息以及从NodeManager收集来的容器状态信息,启动调度过程,为用户作业启动一个ApplicationMaster。
ApplicationMaster
- 为应用程序申请资源,并分配给内部任务
- 任务调度、监控与容错
主要功能:
- 当用户作业提交时,ApplicationMaster与ResourceManager协商获取资源,ResourceManager会以容器的形式为ApplicationMaster分配资源
- 把获得的资源进一步分配给内部的各个任务(Map任务和Reduce任务),实现资源的“二次分配”
- 与NodeManager保持交互通信进行应用程序的启动、运行、监控和停止,监控申请到的资源的使用情况,对所有任务的执行进度和状态进行监控,并在任务发生失败时执行失败恢复(重新申请资源重启任务)
- 定时向ResourceManager发送“心跳”消息,报告资源的使用情况和应用的进度信息;
- 当作业完成时,ApplicationMaster向ResourceManager注销容器,执行周期完成。
NodeManager
- 单个节点上的资源管理
- 处理来自ResourceManger的命令
- 处理来自ApplicationMaster的命令
NodeManager是驻留在一个YARN集群中的每个节点上的代理,主要负责:
- 容器生命周期管理
- 监控每个容器的资源(CPU、内存等)使用情况
- 跟踪节点健康状况,并以“心跳”的方式与ResourceManager保持通信
- 向ResourceManager汇报作业的资源使用情况和每个容器的运行状态
- 接收来自ApplicationMaster的启动/停止容器的各种请求
需要说明的是,NodeManager主要负责管理抽象的容器,只处理与容器相关的事情,而不具体负责每个任务(Map任务或Reduce任务)自身状态的管理,因为这些管理工作是由ApplicationMaster完成的,ApplicationMaster会通过不断与NodeManager通信来掌握各个任务的执行状态
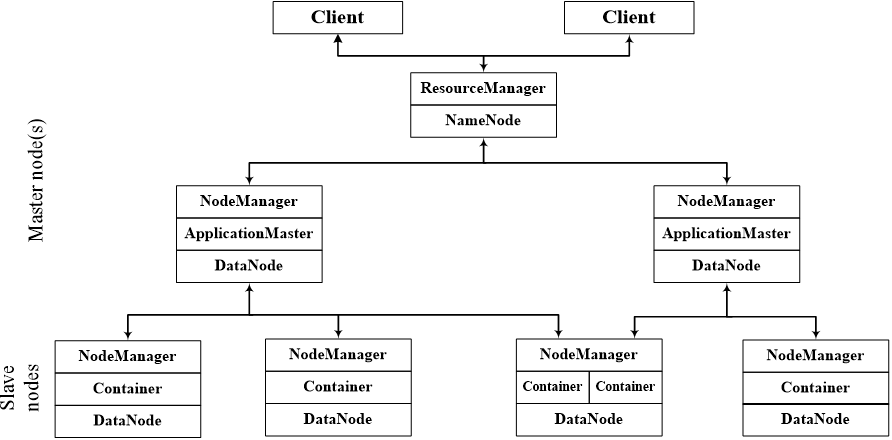
在集群部署方面,YARN的各个组件是和Hadoop集群中的其他组件进行统一部署的
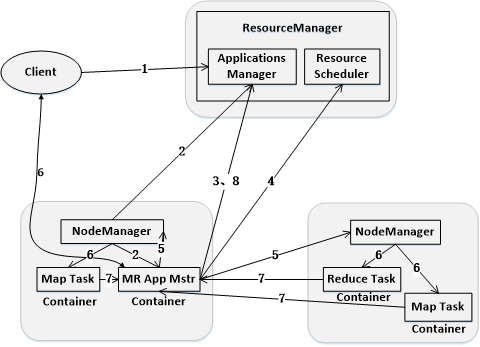
-
用户编写客户端应用程序,向YARN提交应用程序,提交的内容包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等。
-
YARN中的ResourceManager负责接收和处理来自客户端的请求。接到客户端应用程序请求后,ResourceManager里面的调度器会为应用程序分配一个容器。同时,ResourceManager的应用程序管理器会与该容器所在的NodeManager通信,为该应用程序在该容器中启动一个ApplicationMaster
-
ApplicationMaster被创建后会首先向ResourceManager注册,从而使得用户可以通过ResourceManager来直接查看应用程序的运行状态
-
ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请资源。
-
ResourceManager以“容器”的形式向提出申请的ApplicationMaster分配资源,一旦ApplicationMaster申请到资源后,就会与该容器所在的NodeManager进行通信,要求它启动任务。
-
当ApplicationMaster要求容器启动任务时,它会为任务设置好运行环境(包括环境变量、JAR包、二进制程序等),然后将任务启动命令写到一个脚本中,最后通过在容器中运行该脚本来启动任务。
-
各个任务通过某个RPC协议向ApplicationMaster汇报自己的状态和进度,让ApplicationMaster可以随时掌握各个任务的运行状态,从而可以在任务失败时重启任务。
-
应用程序运行完成后,ApplicationMaster向ResourceManager的应用程序管理器注销并关闭自己。若ApplicationMaster因故失败,ResourceManager中的应用程序管理器会监测到失败的情形,然后将其重新启动,直到所有任务执行完毕。
25. HDFS中“块池”的概念,HDFS联邦中的一个名称节点失效会否影响为其他名称节点提供服务?
HDFS联邦中拥有多个独立的命名空间,其中每一个命名空间管理属于自己的一组块,这些属于同一个命名空间的块构成一个“块池”(Block Pool)。每个数据结点会为多个块池提供块的存储。数据结点是一个物理概念,块池是逻辑概念,一个块池是一组块的逻辑集合,块池中的各个块实际上是存储在各个不同的数据节点中的。因此HDFS联邦中的一个名称节点的失效也不会影响到与它相关的数据节点继续为其他名称节点服务
26. Spark的几个主要概念:RDD、DAG、阶段、分区、窄依赖、宽依赖
RDD:弹性分布式数据集(Resilient Distributed Dataset),是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型
DAG:有向无环图(Directed Acyclic Graph),反映RDD之间的依赖关系
Executor:运行中工作结点(Worker Node)上的一个进程,负责运行任务,并为应用程序存储数据
应用:用户编写的Spark程序
作业(Job):一个作业包含多个RDD及作用于相应RDD上的各种操作
阶段(Stage):作业调度的基本单位,一个作业会分为多组任务,每组任务被称为“阶段”,或者也被称为“任务集”
任务(Task):运行在Executor上的工作单元
分区:一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段。
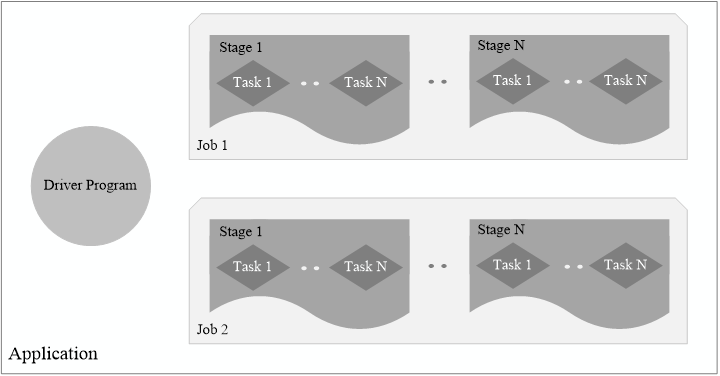
窄依赖:一个父RDD的分区对应一个子RDD的分区,或者多个父RDD的分区对应一个RDD的分区。
宽依赖:一个父RDD的分区对应一个子RDD的多个分区
27. Spark对RDD的操作主要分为:行动和转换
行动(Action):在数据集上进行运算,返回计算结果。(接受RDD返回非RDD)如count,collect
转换(Transformation):指定RDD之间的相互依赖关系。(接受RDD并返回RDD)如map,filter,groupBy
28. Hadoop MapReduce的缺陷,并说明Spark具有哪些优点?
Hadoop MapReduce
- 表达能力有限。计算都必须要转换成Map和Reduce两个操作,难以描述复杂的数据处理过程
- 磁盘IO开销大。每次执行时候都需要从磁盘读取数据,并且在计算完成后需要将中间结果写入到磁盘。
- 延迟高。以此计算可能需要分解成一系列按顺序执行的MapReduce任务,任务之间的衔接由于涉及到IO开销,会产生较高延迟。而且,在前一个任务开始之前,其他任务无法开始,因此难以胜任复杂、多阶段的计算任务
Spark
- Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比MapReduce更灵活;
- Spark提供了内存计算,中间结果直接存放内存中,带来更高的迭代运算效率;
- Spark基于DAG的任务调度执行机制,要优于MapReduce的迭代执行机制
Spark采用的Executor利用多线程来执行具体任务(Hadoop MapReduce采用进程模型),减少任务的启动开销
Executor中有一个BlockManager存储模块,会将内存和磁盘共同作为存储设备,当需要多轮迭代计算时,可以将中间结果存储到这个存储模块里,不需要读写到HDFS等文件系统里,减少IO开销;或者在交互式查询场景下,预先将表缓存到该存储系统上,提高读写IO性能
29. MapReduce的框架、小批量处理、以及流数据处理
30. 流计算流程与传统的数据处理流程
传统的数据处理流程:采集数据,存储在关系数据库等数据管理系统中,用户通过查询操作与数据管理系统进行交互

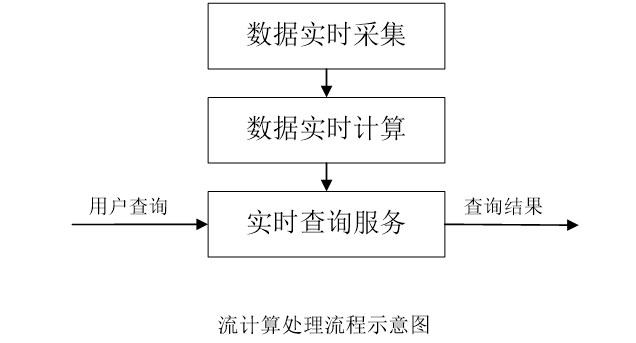
流计算处理流程:数据实时采集、数据实时计算和实时查询服务。
数据实时采集
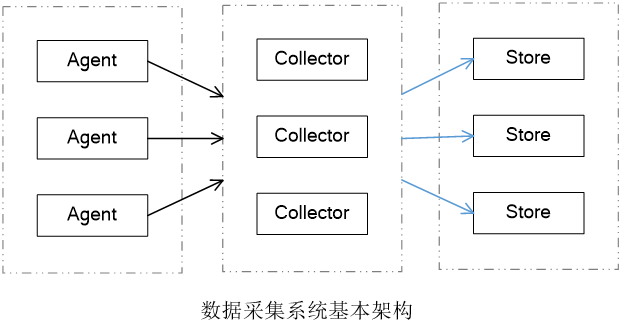
数据采集系统的基本架构一般有以下三个部分:
- Agent:主动采集数据,并把数据推送到Collector部分
- Collector:接收多个Agent的数据,并实现有序、可靠、高性能的转发
- Store:存储Collector转发过来的数据(对于流计算不存储数据)
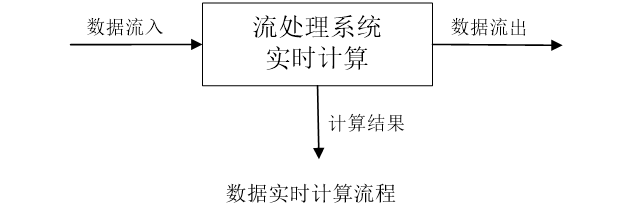
数据实时计算
数据实时计算阶段对采集的数据进行实时的分析和计算,并反馈实时结果
经流处理系统处理后的数据,可视情况进行存储,以便之后再进行分析计算。在时效性要求较高的场景中,处理之后的数据也可以直接丢弃
实时查询服务
- 实时查询服务:经由流计算框架得出的结果可供用户进行实时查询、展示或储存
- 传统的数据处理流程,用户需要主动发出查询才能获得想要的结果。而在流处理流程中,实时查询服务可以不断更新结果,并将用户所需的结果实时推送给用户
- 虽然通过对传统的数据处理系统进行定时查询,也可以实现不断地更新结果和结果推送,但通过这样的方式获取的结果,仍然是根据过去某一时刻的数据得到的结果,与实时结果有着本质的区别
流处理系统与传统的数据处理系统有如下不同:
- 流处理系统处理的是实时的数据,而传统的数据处理系统处理的是预先存储好的静态数据
- 用户通过流处理系统获取的是实时结果,而通过传统的数据处理系统,获取的是过去某一时刻的结果
- 流处理系统无需用户主动发出查询,实时查询服务可以主动将实时结果推送给用户
31. 单词统计:采用MapReduce框架与采用Storm框架区别?
Streams
Storm将流数据Stream描述成一个无限的Tuple序列,这些Tuple序列会以分布式的方式并行地创建和处理

每个tuple是一堆值,每个值有一个名字,并且每个值可以是任何类型
Tuple本来应该是一个Key-Value的Map,由于各个组件间传递的tuple的字段名称已经事先定义好了,所以Tuple只需要按序填入各个Value,所以就是一个Value List(值列表)
spout
Storm认为每个Stream都有一个源头,并把这个源头抽象为Spout
通常Spout会从外部数据源(队列、数据库等)读取数据,然后封装成Tuple形式,发送到Stream中。Spout是一个主动的角色,在接口内部有个nextTuple函数,Storm框架会不停的调用该函数

Bolts
Storm将Streams的状态转换过程抽象为Bolt。Bolt既可以处理Tuple,也可以将处理后的Tuple作为新的Streams发送给其他Bolt
Bolt可以执行过滤、函数操作、Join、操作数据库等任何操作
Bolt是一个被动的角色,其接口中有一个execute(Tuple input)方法,在接收到消息之后会调用此函数,用户可以在此方法中执行自己的处理逻辑
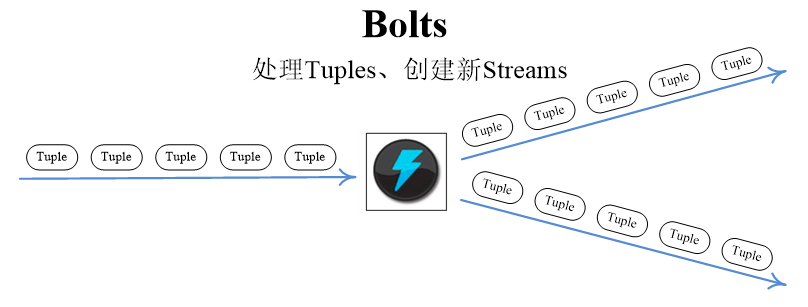
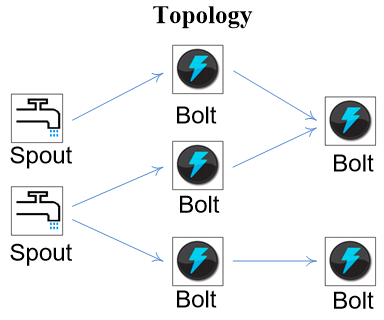
Topology
Storm将Spouts和Bolts组成的网络抽象成Topology,它可以被提交到Storm集群执行。Topology可视为流转换图,图中节点是一个Spout或Bolt,边则表示Bolt订阅了哪个Stream。当Spout或者Bolt发送元组时,它会把元组发送到每个订阅了该Stream的Bolt上进行处理
Topology里面的每个处理组件(Spout或Bolt)都包含处理逻辑, 而组件之间的连接则表示数据流动的方向
Topology里面的每一个组件都是并行运行的
在Topology里面可以指定每个组件的并行度, Storm会在集群里面分配那么多的线程来同时计算
在Topology的具体实现上,Storm中的Topology定义仅仅是一些Thrift结构体(二进制高性能的通信中间件),支持各种编程语言进行定义
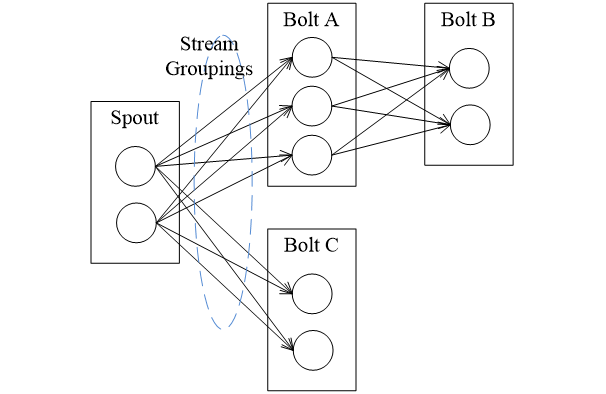
Stream Groupings
Storm中的Stream Groupings用于告知Topology如何在两个组件间(如Spout和Bolt之间,或者不同的Bolt之间)进行Tuple的传送。箭头表示Tuple的流向,圆圈表示任务。每一个Spout和Bolt都可以有多个分布式任务,一个任务在什么时候、以什么方式发送Tuple就是由Stream Groupings来决定的
Mapreduce使用的是Map和Reduce的抽象,而Storm使用的是Spout和Bolts 的抽象,Mapreduce作业(Job)会最终完成计算并结束任务,而Storm框架的Topology会一直处理消息直到人为停止
32. Storm集群中的Master和Worker节点各自运行什么后台进程,这些进程又分别负责什么工作?
Storm集群采用“Master-Worker”的节点方式。
Master节点运行名为“Nimbus”的后台程序,负责在集群范围内分发代码,为Worker分配任务和监测故障
每个Worker节点运行名为“Supervisor”的后台程序,负责监听分配给它所在机器的工作,即根据Nimbus分配的任务来决定启动或停止Worker进程。一个Worker节点上同时运行若干个Worker进程。
33. Nimbus进程和Supervisor进程意外终止后,重启时是否能恢复到终止之前的状态,为什么?
重启时能恢复到终止之前的状态
Master节点并没有直接和Worker节点通信而是借助Zookeeper将信息状态存放在Zookeeper中或本地磁盘中,以便节点故障时快速恢复。这意味着若Nimbus进程或Supervisor进程意外终止,重启时也能读取、恢复之前的状态并继续工作。这种设计使得Storm极其稳定。
34. MapReduce Job与Storm Topology
Mapreduce作业最终会完成计算并结束运行,而Topolopy将持续处理消息直到人为停止。
35. 协同过滤算法:基于用户的协同过滤和基于物品的协同过滤
基于用户的协同过滤(UserCF)
1992年被提出,是推荐系统中最古老的算法
UserCF算法符合人们对于“趣味相投”的认知,即兴趣相似的用户往往有相同的物品喜好:当目标用户需要个性化推荐时,可以先找到和目标用户有相似兴趣的用户群体,然后将这个用户群体喜欢的、而目标用户没有听说过的物品推荐给目标用户
UserCF算法的实现主要包括两个步骤:
第一步:找到和目标用户兴趣相似的用户集合
第二步:找到该集合中的用户所喜欢的、且目标用户没有听说过的物品推荐给目标用户
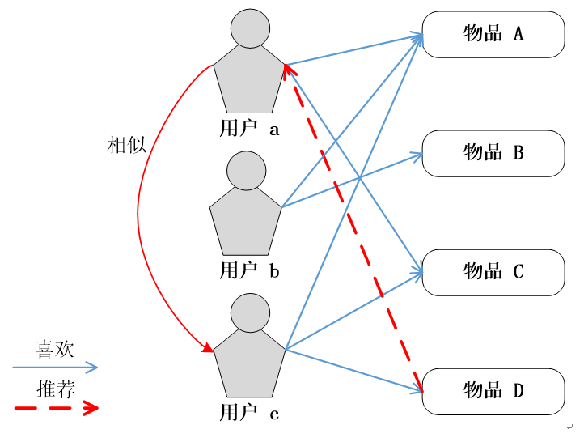
实现UserCF算法的关键步骤是计算用户与用户之间的兴趣相似度。目前较多使用的相似度算法有:
- 泊松相关系数(Person Correlation Coefficient)
- 余弦相似度(Cosine-based Similarity)
- 调整余弦相似度(Adjusted Cosine Similarity)
给定用户u和用户v,令N(u)表示用户u感兴趣的物品集合,令N(v)为用户v感兴趣的物品集合,则使用余弦相似度进行计算用户相似度的公式为:
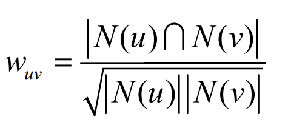
由于很多用户相互之间并没有对同样的物品产生过行为,因此其相似度公式的分子为0,相似度也为0
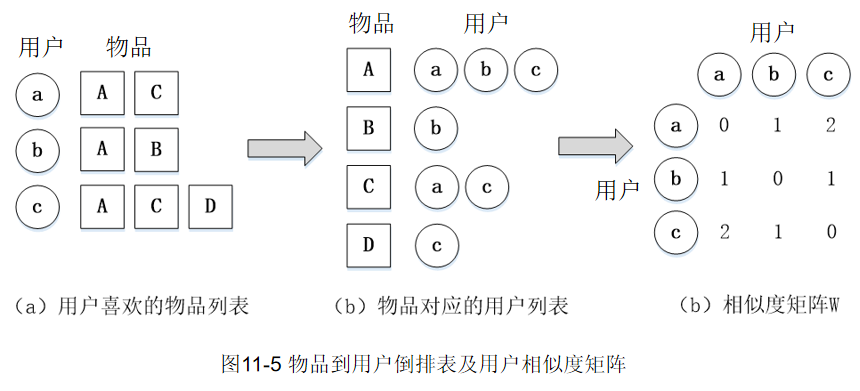
我们可以利用物品到用户的倒排表(每个物品所对应的、对该物品感兴趣的用户列表),仅对有对相同物品产生交互行为的用户进行计算
如图,喜欢物品C的用户包括a,c,因此w[a][c]和w[c][a]都加1。对每个物品计算的用户列表计算完成后,得到用户相似度矩阵W。w[u][v]即为\(w_{uv}\)的分子部分,将w[u][v]除以分母便可得到用户相似度\(w_{uv}\)
得到用户相似度后,再用如下公式来度量用户u对物品i的兴趣程度p(u,i)。
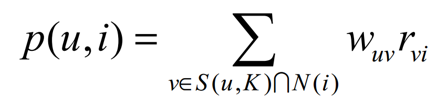
其中,S(u, K)是和用户u兴趣最接近的K个用户的集合,N(i)是喜欢物品i的用户集合,\(w_{uv}\)是用户u和用户v的相似度,\(r_{vi}\)是隐反馈信息,代表用户v对物品i的感兴趣程度,为简化计算可令\(r_{vi}=1\)
对所有物品计算\(p_{ui}\)后,可以对\(p_{ui}\)进行降序处理,取前N个物品作为推荐结果展示给用户u(称为Top-N推荐)
基于物品的协同过滤
基于物品的协同过滤算法(简称ItemCF算法)是目前业界应用最多的算法。
ItemCF算法是给目标用户推荐那些和他们之前喜欢的物品相似的物品。ItemCF算法主要通过分析用户的行为记录来计算物品之间的相似度
该算法基于的假设是:物品A和物品B具有很大的相似度是因为喜欢物品A的用户大多也喜欢物品B。例如,该算法会因为你购买过《数据挖掘导论》而给你推荐《机器学习实战》,因为买过《数据挖掘导论》的用户多数也购买了《机器学习实战》
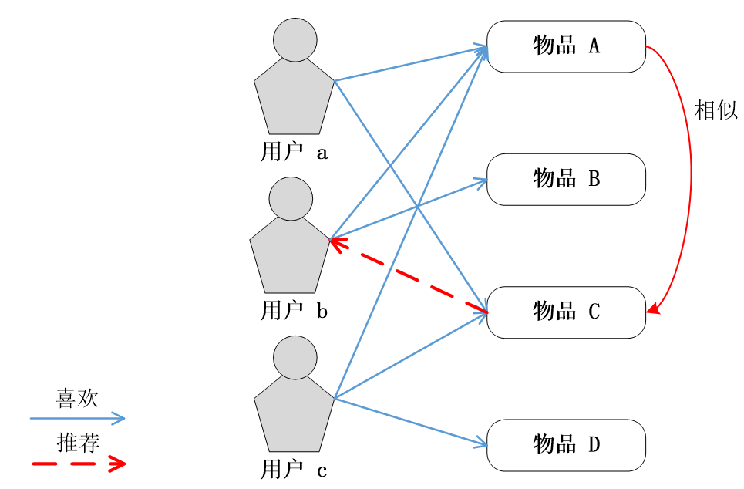
ItemCF算法与UserCF算法类似,计算也分为两步:
第一步:计算物品之间的相似度;
第二步:根据物品的相似度和用户的历史行为,给用户生成推荐列表。
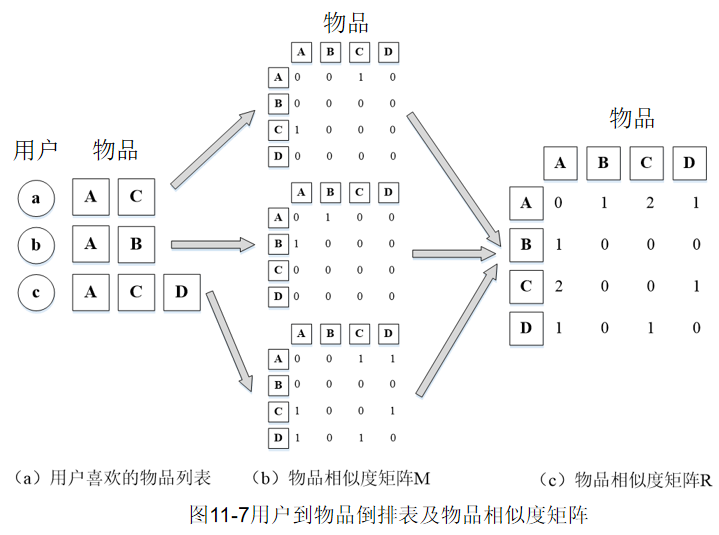
ItemCF算法通过建立用户到物品倒排表(每个用户喜欢的物品的列表)来计算物品相似度
如果用户a喜欢物品A和C,则在\(M_a[A][C]\)和\(M_a[C][A]\)上都加1。得到每个用户的物品相似度矩阵。将所有用户的物品相似度矩阵\(M_u\)相加得到最终的物品相似度矩阵R,其中\(R[i][j]\)记录了同时喜欢物品i和物品j的用户数。将矩阵R归一化,便可得到物品间的余弦相似度矩阵W。
得到物品相似度后,在使用如下公式来度量用户u对物品j的兴趣程度
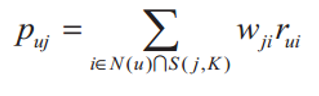
其中,S(j, K)是和物品j最相似的K个物品的集合,N(u)是用户u喜欢的物品的集合,\(w_{ji}\)代表物品 \(i\) 和物品 \(j\) 的相似度,\(r_{ui}\) 是隐反馈信息,代表用户 \(u\) 对物品 \(i\) 的感兴趣程度,为简化计算可令\(r_{ui}=1\)
36. UserCF算法和ItemCF算法的实现步骤、应用场景、以及优缺点
应用场景:
UserCF算法的推荐更偏向于社会化:适合应用于新闻推荐、微博话题推荐等应用场景,推荐结果在新颖性方面有一定优势
ItemCF算法的推荐更偏向于个性化:适合用于电子商务、电影、图书等应用场景,可以利用用户的历史行为给推荐结果做出解释,让用户更为信服推荐的结果
缺点:
UserCF:随着用户数目的增大,用户相似度计算复杂度越来越高,而且UserCF推荐结果相关性较弱,难以对推荐结果作出解释,容易受大众影响而推荐热门物品
ItemCF:倾向于推荐于用户已购买商品相似的商品,往往会出现多样性不足、推荐新颖度较低的问题
四、编程题
Scala编程、读取HDFS中指定文件(包括读写权限、大小、创建时间、路径等信息,以及创建目录,创建,删除文件)、使用MapReduce编程技术对文档内容建立索引库、统计单词、创建表格(包括插入、求值等)运用HBase的API创建表格、MySQL数据库创建数据库、创建表等。
基础HDFS操作
hdfs dfs -mkdir [-p] path
创建文件夹在path路径上
hdfs dfs -ls [path]
读取hdfs中全部目录/[path]路径下所有目录,包括文件的读写权限、大小、生成时间、路径
hdfs dfs -rm -r path
删除目录path,-r表示删除目录下所有子目录和内容。
hdfs dfs -put localpath/file hdfspath
将本地file文件上传到hdfs的hdfspath目录下
hdfs dfs -cat hdfspath/file
查看hdfspath下的file文件
hdfs dfs -get hdfspath/file localpath
将hdfspath下的file文件下载到localpath本地路径下
hdfs dfs -cp hdfspath/file hdfspath2
将hdfspath下的file复制到hdfspath2目录下
Java api操作
设置路径等初始化(获取文件系统 get file system:fs)
//包 org.apache.hadoop.conf.Configuration
Configuration conf = new Configuration();
conf.set(“fs.defaultFS”,”hdfs://localhost:9000”); //设置file system路径
FileSystem fs = FileSystem.get(new URI(“hdfs://localhost:9000”), conf, “username”)
上传文件
fs.copyFromLocalFile(new Path(“C:/test.txt”),new Path(“/test.txt”));
下载文件
/***
parameters
Boolean delSrc 是否删除原文件
Path src 要下载的文件
Path dst 文件下载到的路径
Boolean useRawLocalFileSystem 是否开启文件校验
***/
fs.copyToLocalFile(false, new Path(“/test.txt”), new Path(“C:/test.txt”), true);
删除文件夹
参数2为true时,删除非空目录才能成功
fs.delete(new Path(“/path/”), true);
修改文件命名
fs.rename(new Path(“/test.txt”) , new Path(“/test2.txt”));
查看文件详情
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(New Path(“/”), true);
while(listFiles.hasNext()){
LocatedFileStatus status = listFiles.next();
status.getPath();//路径
status.getPath().getName();//文件名
status.getLen();//长度
status.getPermission();//权限
status.getGroup();//分组
}
文件上传
//创建输入流
FileInputStream fis = new FileInputStream(new File(“C:/test.txt”));
//创建输出流
FSDataOutputStream fos = fs.create(new Path(“/test.txt”));
//流对拷
IOUtils.copyBytes(fis, fos, conf);
文件下载
//创建输出流
FileOutputStream fos = new FileOutputStream(new File(“C:/test.txt”));
//创建输入流
FSDataInputStream fis = fs.create(new Path(“/test.txt”));
//流对拷
IOUtils.copyBytes(fis,fos, conf);
Mapreduce操作
wordcount
Map过程
//首先继承Mapper实现Map过程
public static class Map extends Mapper<Object,Text, Text, IntWritable>{
private static Text text = new Text();
//重载map方法
public void map(Object key, Text value, Context context) throw IOException,InterruptException{
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens){
this.text.set(itr.nextToken());
context.write(text, 1);
}
}
}
得到<word,1>的若干中间结果
Reduce过程
//继承实现Reducer
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable>{
private Intwritable result = new Intwritable();
//重写reduce方法
public void reduce (Text key, Iterable<IntWritable>values, Context context ){
int sum = 0;
IntWritable val;
for(Iterator i$=values.iterator();i$.hasNext();sum+=val.get()){
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key,result);
}
}
Main函数中
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
conf.set(“fs.defaultFS”,”hdfs://localhost:9000”);
//声明job
Job job = Job.getInstance(conf);
job.setJarByClass(类名.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,new Path(“hdfs://localhost:9000/input”));
FileOutputFormat.addOutputPath(job,new Path(“hdfs://localhost:9000/output”));
System.exit(job.waitForCompletion(true)?0:1);
}
合并、去重
package MapReduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Merge {
public static class Map extends Mapper<Object, Text, Text, Text> {
private static Text text = new Text();
public void map(Object key, Text value, Context content) throws IOException, InterruptedException {
text = value;
content.write(text, new Text(""));
}
}
public static class Reduce extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
context.write(key, new Text(""));
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://BigData1:9000");
Job job = Job.getInstance(conf);
job.setJarByClass(Merge.class);
job.setJobName("Merge");
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path("hdfs://BigData1:9000/ex/ex2/input"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://BigData1:9000/ex/ex2/output"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
HBase
Shell编程
create ‘表名’,’列族1’,’列族2’,…’列族n’
craete 'user','info1','info2'
查看所有表
list
判断表是否存在
exists 'user'
扫描整个表
scan 'user'
描述表
describe 'user'
查询记录数,rowkey相同只算一条
count 'user'
查询某一行
get 'user','1'
查询某行的某个列族
get 'user','1','info'
查询某行的某个列
get 'user','1','info:Age'
删除列族下的某一列
delete 'user','1','info:age'
删除某一列族
delete 'user','1','info'
删除一行
deleteall 'user','1'
清空表
truncate 'user'
查询表中rowkey行列族info的num个历史版本
get ‘user’ , ‘1’ , {COLUMN=>’info’ , VERSIONS=>NUM}
API编程
初始化
public static Configuration conf;
public static Connection connection;
public static Admin admin;
public static void init() {
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","127.0.0.1");
conf.set("hbase.zookeeper.property,clienPort","2181");
try {
connection = ConnectionFactory.createConnection(conf);
admin = connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void close() {
try {
if (admin != null) {
admin.close();
}
if (null != connection) {
connection.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
删除行
/*
* 删除表tableName中row指定的行的记录。
*/
public static void deleteRow(String tableName, String row) throws IOException {
Table table = connection.getTable(TableName.valueOf(tableName));
Delete delete = new Delete(row.getBytes());
table.delete(delete);
table.close();
System.out.println("刪除行:" + row + " 成功");
}
修改表
/*
* 修改表tableName,行row(可以用学生姓名S_Name表示),列column指定的单元格的数据
*/
public static void modifyData(String tableName, String row, String column, String data) throws IOException {
Table table = connection.getTable(TableName.valueOf(tableName));
Put put = new Put(row.getBytes());
String[] cols = column.split(":");
put.addColumn(cols[0].getBytes(),cols[1].getBytes(),data.getBytes());
table.put(put);
table.close();
System.out.println("修改成功!");
}
扫描某一列
/*
* 浏览表tableName某一列的数据,如果某一行记录中该列数据不存在,则返回null。
* 要求当参数column为某一列族名称时,如果底下有若干个列限定符,则要列出每个列限定符代表的列的数据;
* 当参数column为某一列具体名称(例如“Score:Math”)时,只需要列出该列的数据
*/
public static void scanColumn(String tableName, String column) throws IOException {
Table table = connection.getTable(TableName.valueOf(tableName));
Scan scan = new Scan();
String[] cols = column.split(":");
if (cols.length == 1){
scan.addFamily(column.getBytes());
}
else{
scan.addFamily(cols[0].getBytes());
scan.addColumn(cols[0].getBytes(),cols[1].getBytes());
}
ResultScanner scanner = table.getScanner(scan);
for (Result result = scanner.next(); result != null; result = scanner.next()) {
Cell[] cells = result.rawCells();
for (Cell cell : cells) {
System.out.print("行键" + Bytes.toString(CellUtil.cloneRow(cell)));
System.out.print("\t列族" + Bytes.toString(CellUtil.cloneFamily(cell)));
System.out.print("\t列" + Bytes.toString(CellUtil.cloneQualifier(cell)));
System.out.println("\t值" + Bytes.toString(CellUtil.cloneValue(cell)));
}
}
table.close();
}
添加数据
/*
* 向表tableName、行row(用S_Name表示)和字符串数组fields指定的单元格中添加对应的数据values。
* 其中,fields中每个元素如果对应的列族下还有相应的列限定符的话,用“columnFamily:column”表示。
* 例如,同时向“Math”、“Computer Science”、“English”三列添加成绩时,
* 字符串数组fields为{“Score:Math”, ”Score:Computer Science”, ”Score:English”},数组values存储这三门课的成绩。
*/
public static void addRecord(String tableName, String row, String[] fields, String[] values) throws IOException {
Table table = connection.getTable(TableName.valueOf(tableName));
for (int i = 0; i < fields.length; i++) {
Put put = new Put(row.getBytes());
String[] cols = fields[i].split(":");
put.addColumn(cols[0].getBytes(), cols[1].getBytes(), values[i].getBytes());
table.put(put);
}
table.close();
System.out.println("添加成功!");
}
创建表
/*
* 创建表,参数tableName为表的名称,字符串数组fields为存储记录各个字段名称的数组。
* 要求当HBase已经存在名为tableName的表的时候,先删除原有的表,然后再创建新的表
*/
public static void createTable(String tableName, String[] fields) throws IOException {
HBaseAdmin hBaseAdmin = new HBaseAdmin(conf);
if (admin.tableExists(TableName.valueOf(tableName))){ //表已存在则删除表
System.out.println("表已存在!\n删除已存在的表");
hBaseAdmin.disableTable(tableName);
hBaseAdmin.deleteTable(tableName);
}
HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf(tableName));
for (String item:fields)
hTableDescriptor.addFamily(new HColumnDescriptor(item));
hBaseAdmin.createTable(hTableDescriptor);
System.out.println("创建 " + tableName + " 成功");
}
Spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object work1 {
def main(args: Array[String]):Unit={
println("Hello Spark")
val sparkConf = new SparkConf().setMaster("local").setAppName("Ex4_Work1")
val sc : SparkContext = new SparkContext(sparkConf)
val fileRDD: RDD[String] = sc.textFile("Data01.txt")
// (1)该系总共有多少学生;
println("(1)该系总共有多少学生;")
val nameRDD = fileRDD.map(Item=>{Item.split(",")(0)})
val User_Count = nameRDD.distinct()
println(User_Count.count)
// (2)该系共开设来多少门课程;
println("(2)该系共开设来多少门课程;")
val courseRDD = fileRDD.map(Item=>{Item.split(",")(1)})
val Course_Count = courseRDD.distinct()
println(Course_Count.count)
// (3)Tom同学的总成绩平均分是多少;
println("(3)Tom同学的总成绩平均分是多少;")
val TomRDD = fileRDD.filter(Item=>{Item.split(",")(0)=="Tom"})
val Tom_Grade = TomRDD.map(Item=>(Item.split(",")(0),(Item.split(",")(2).toInt,1)))
val Tom_AVG_GRADE = Tom_Grade.reduceByKey((a,b)=>(a._1+b._1,a._2+b._2))
println(Tom_AVG_GRADE.mapValues(Item=>Item._1/Item._2).first())
// (4)求每名同学的选修的课程门数;
println("(4)求每名同学的选修的课程门数;")
val User_Course = fileRDD.map(Item=>(Item.split(",")(0),(Item.split(",")(1),1)))
val User_Course_Num = User_Course.reduceByKey((a,b)=>("course_num",a._2+b._2))
User_Course_Num.mapValues(Item=>(Item._2)).foreach(println)
// (5)该系DataBase课程共有多少人选修;
println("(5)该系DataBase课程共有多少人选修;")
val DataBase = fileRDD.filter(Item=>{Item.split(",")(1)=="DataBase"})
println(DataBase.count)
// (6)各门课程的平均分是多少;
println("(6)各门课程的平均分是多少;")
val Course_Score = fileRDD.map(Item=>(Item.split(",")(1),(Item.split(",")(2).toInt,1)))
val Course_Score_SUM = Course_Score.reduceByKey((a,b)=>(a._1+b._1,a._2+b._2))
val Course_Score_AVG = Course_Score_SUM.mapValues(a=>a._1/a._2)
Course_Score_AVG.foreach(println)
// (7)使用累加器计算共有多少人选了DataBase这门课。
println("(7)使用累加器计算共有多少人选了DataBase这门课。")
val User_DataBase = fileRDD.filter(Item=>{Item.split(",")(1) == "DataBase"}).map(Item=>((Item.split(",")(1),1)))
val acc = sc.longAccumulator("Acc")
User_DataBase.values.foreach(x => acc.add(x))
println(acc.value)
sc.stop()
}
}
本文来自博客园,作者:Un-Defined,转载请保留本文署名Un-Defined,并在文章顶部注明原文链接:https://www.cnblogs.com/EIPsilly/p/15728192.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号