
Lecture18 Application example:Photo OCR
Lecture18 Application example:Photo OCR
Problem description and pipeline
The Photo OCR problem

全称:Photo Optical Character Recognition。如何让计算机读出图片中的文字信息
Photo OCR pipeline
-
Text detection
![image-20211222102717998]()
-
Character segmentation
![image-20211222102752267]()
-
Character classification
![image-20211222102824248]()



photo OCR流水线如下所示。

Sliding windows
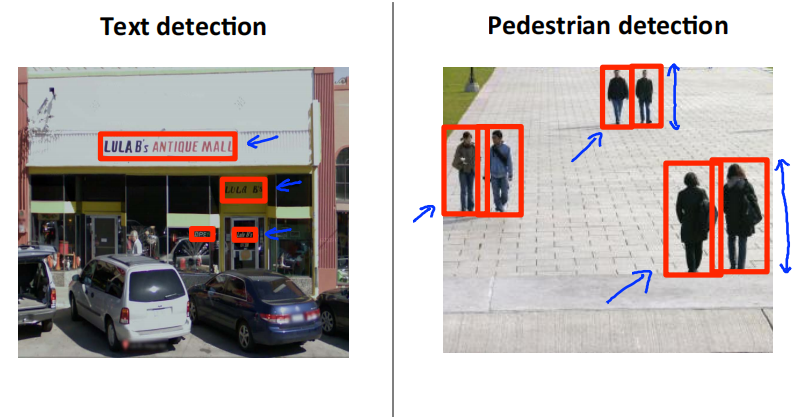
文字识别在计算机视觉中是一个比较难的问题,因为文字区域对应的矩形有着不同的长宽比。我们先从简单的行人检测开始。行人检测要识别的对象具有相似的长宽比,所以仅用一个固定长宽比的而矩形就可以了
supervised learning for pedestrian detection

定义矩形大小为82*36。从数据集中收集一些正样本和负样本。通过这些样本训练一个分类器,用来判断图中是否包含行人。
Sliding window detection

用一个固定大小的矩阵按照从上到下,从左到右的顺序,依次获取矩形中的图像,将其传递给分类器判断图像是否存在行人。矩形每次移动的距离称为步长,1px的步长效果最好,但是计算量较大,一般取4px,8px等。矩形的大小可以自定义,从而获取大小不同的图像。获取的图像通过一定的缩放之后,达到82*36的大小,再放入分类器中进行识别。

Text detection
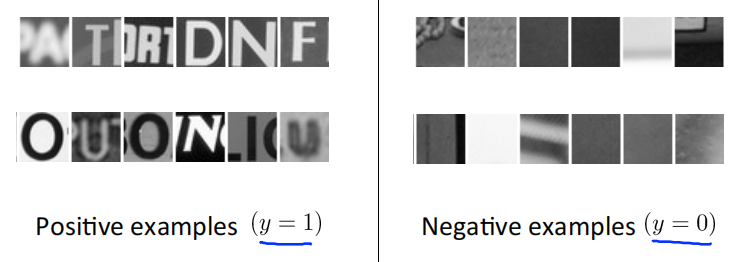
文字识别也训练出一个分类器来,判断图像中是否存在文字。
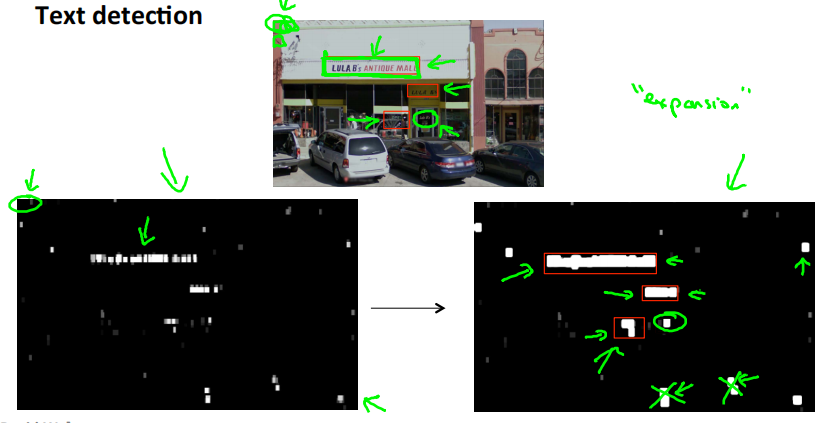
使用滑动窗口,识别出图中存在文字的地方,识别结果如左下图所示。白色的部分表示文本检测系统发现了文本;黑色部分表示没有发现文字; 深浅不同的灰色表示分类器认为该处有文字的概率。
将分类器的结果应用到一个叫放大算子的东西上。它把每个白色区域都进行扩大。具体地说,如果左边图片中,某个像素的一定范围内存在白色像素,那么就在右图中把它变成白色。即原来白色的区域向外扩大一部分。
完成之后,在右图白色区域周围绘制边框。同时也可以过滤一些比例很奇怪的矩形,因为文本周围的框,宽度应该大于高度。
处理完成之后,把这些区域剪切出来,进入流水线的下一个阶段
1D sliding window for character segmentation
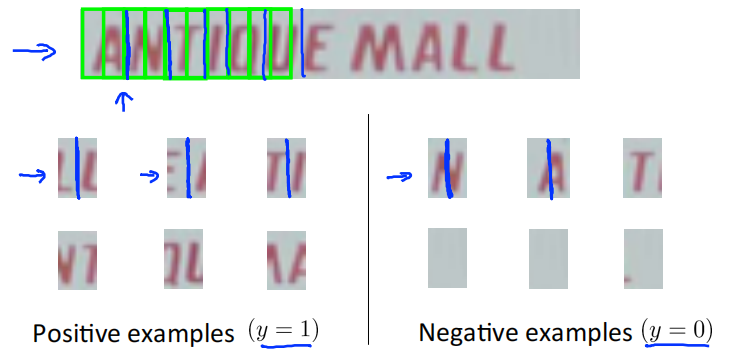
再次使用监督学习,用一些正样本和负样本,训练出一个分类器,判断是否存在字符分割的地方。
使用滑动窗口,从左到右移动,判断窗口内的图像是否存在字符分割的地方,然后对图像进行分割。
Getting lots of data : Artificial data synthesis
一个最可靠的得到高性能机器学习系统的方法是使用一个低偏差机器学习算法,并且使用庞大的训练集去训练它。
为了获取更多的数据可以使用人工数据合成,但它并不适用于所有问题,而且将其运用于特定问题时,经常需要思考改进并且深入了解它。
人工数据合成主要有两种形式:一种是自己创造数据,即从零开始创造新数据;第二种是我们已经有小的标签训练集,然后以某种方式扩充训练集。
Artificial data synthesis for photo OCR

用不同的字体生成字符,然后将其粘贴到任意不同的背景。可以应用一点模糊算子或者仿射变换(等分、缩放、旋转等操作)

新生成的数据与原来的真实数据非常相似,那么使用合成的数据,就可以为训练提供无限的数据样本。如果合成的数据做的不好,那训练的效果也会不好。
Synthesizing data by introducing distortions
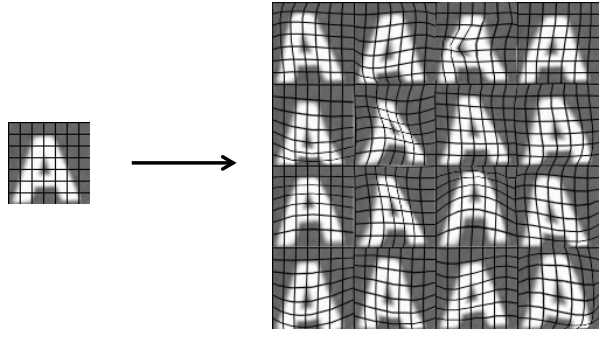
对图片进行人工拉伸、人工扭曲从而获得更大的数据集。
对于一些音频片段,想从中学习、识别语音片段中出现的单词。假定有一个带标签的训练样本,可以引入额外的语音失真到数据集中。比如增加背景音模拟在街道上,在工厂,手机信号不好。
Distortion introduced should be representation of the type of noise/distortion in the test set。
在引入失真合成数据时,引入的失真应该具有代表性,这些噪音和扭曲是有可能出现在测试集中的。

Usually does not help to add purely random/meaningless noise to your data
如果只是将随机的无意义的噪音加入到数据中,则并没有多大帮助。下图中,右边4张图中的每个像素随机加入了一些高斯噪音,即改变每个像素的亮度,这样的噪音是完全没有意义的。除非你觉得可能在测试集中看到这种像素级别的噪音,不然很可能就是无用的。
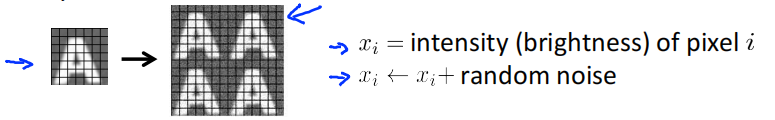
Discussion on getting more data
- Make sure you have a low bias classifier before expending the effort.(Plot learning curves).E.g. keep increasing the number of features/number of hidden units in neural network until you have a low bias classifier.
- "How much work would it be to get 10x as much data as we currently have"
- Artifical data synthesis
- Collect/label it yourself
- "Crowd source"(E.g. Amazon Mechanical Turk)
Ceiling analysis:What part of the pipeline to work on next
Estimating the error due to each component (ceiling analysis)

What part of the pipeline should you spend the most time trying to improve?
在测试集上,一开始整个系统的正确率在72%。
文本检测模块:
模拟文本检测模块是100%的正确率,观察其对整个系统的影响。对于测试集,对于每一个测试集样本都提供一个正确的文本检测结果,即遍历每个测试集样本,人为地告诉算法每个测试样本中文本的位置。或者说我们模拟100%正确地检测出图片中的文本信息,然后将它传递给下一个模块。然后继续运行完后两个模块,测量整个系统的准确率。假设正确的文本检测模块将系统的准确率提高到了89%。
字符分割模块:
模拟字符分割模块是100%的正确率,观察其对整个系统的影响。对于得到的准确的文本检测结果,人为地把文本分割成单个字符,得到100%正确的字符分割结果,然后把它传递给下一个模块。然后继续运行下一个模块,测量整个系统的准确率。假设正确的字符分割模块将系统的准确率提高到了90%。
字符识别模块:
同样是人工给出这一模块的正确标签,理所当然得到100%的正确率。
进行上限分析的好处是我们知道了如果对每一个模块进行完善,它们各自的上升空间是多少。 比如完美的文本检测模块提高了17%的正确率,所以值得花费大量精力去提升;完美的字符分割模块提升了1%的正确率,不值得花费大力气去完善。
| Component | Accuracy |
|---|---|
| Overall system | 72% |
| Text detection | 89% |
| Character segmentation | 90% |
| Character recognition | 100% |
another ceiling analysis example
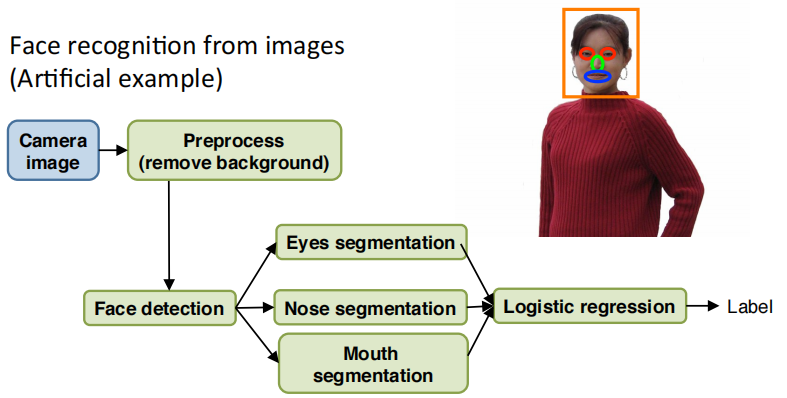
假如用图片做人脸识别。这是一个偏人工智能的例子,当然这并不是现实中的人脸识别技术。
首先是图像预处理,去除背景。
然后是用滑动窗口进行人脸检测。
然后分割出眼睛,分割出鼻子,分割出嘴巴
把所有特征输入给某个逻辑回归分类器
最终给出标签。
| Component | Accuracy |
|---|---|
| Overall system | 85% |
| Preprocess (remove background) | 85.1% |
| Face detection | 91% |
| Eye segmentation | 95% |
| Nose segmentation | 96% |
| Mouth segmentation | 97% |
| logistic regression | 100% |
不要相信直觉,如果要解决某个机器学习问题,最好能把问题分成多个模块,然后做一下上限分析,这通常会给你更好的方法,来决定往哪个方向努力,该提高哪个模块的效果
本文来自博客园,作者:Un-Defined,转载请保留本文署名Un-Defined,并在文章顶部注明原文链接:https://www.cnblogs.com/EIPsilly/p/15719523.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号