Lecture9 Neural Networks Learning
Lecture9 Neural Networks:Learning
Cost function
Neural Network (Classifification)
\(L\) = total no. of layer in network
\(S_l\) = no. of units (not counting bias unit) in layer \(l\)
Binary classification
y = 0 or 1 , 1 output unit
Multi-class classification (K classes)
\(y \in \mathbb{R}^K\) e.g. \(\left[\begin{matrix}1\\0\\0\\0\end{matrix}\right]\),\(\left[\begin{matrix}0\\1\\0\\0\end{matrix}\right]\),\(\left[\begin{matrix}0\\0\\1\\0\end{matrix}\right]\),\(\left[\begin{matrix}0\\0\\0\\1\end{matrix}\right]\),K output units
Cost function
logistic regression
Neural network:
Backpropagation algorithm
Gradient computation
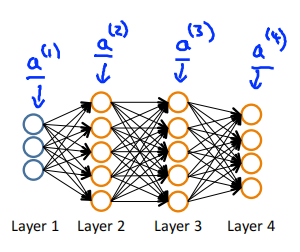
Given one training example(x,y),Forward propagation:
Backpropagation algorithm
Intuition: \(\delta_j^{(l)}\) = "error" of node \(j\) in layer \(l\) ,Formally
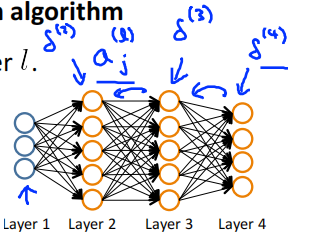
For each output unit (layer L = 4)
Step of Algorithm
set \(\Delta_{ij}^{(l)} = 0\) (for all l,i,j)
For i = 1 to m
Set \(a^{(1)} = x^{(i)}\)
Perform forward propagation to compute \(a^{(l)}\) for \(l=2,3,\cdots,L\)
Using \(y^{(i)}\),compute \(\delta^{(L)} = a^{(L)}-y^{(i)}\)
compute \(\delta^{(L-1)},\delta^{(L-2)},\cdots,\delta^{(2)}\)
\(\Delta^{(l)}_{ij} += a^{(l)}_j\delta^{(l+1)}_i\)
\(D_{ij}^{(l)} = \frac{1}{m}\Delta_{ij}^{(l)}+\lambda\Theta_{ij}^{(l)}\ \ if\ j \neq 0\)
\(D_{ij}^{(l)} = \frac{1}{m}\Delta_{ij}^{(l)}\ \ if\ j = 0\)
\(\frac{\partial}{\partial\Theta_{ij}^{(l)}}J(\Theta)=D_{ij}^{(l)}\)
Backpropagation intuition
对\(\delta^{(L)} = a^{(L)}-y\)的推导
损失函数选择 交叉熵函数,激活函数选择sigmoid函数。
对于如下图所示的神经网络求$$\delta^{(3)}$$
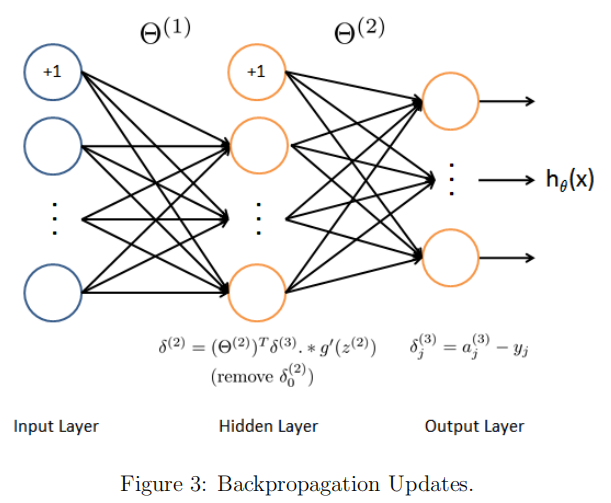
即对下函数求导。此处选用一个样本作为例子,y为该样本的真实值的向量,z3也为向量。
求导过程如下
对\(((\Theta^{(l)})^T\delta^{(l+1)})\)的理解
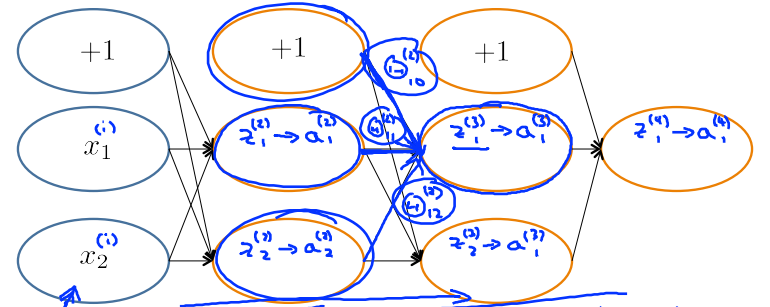
求得\(\delta^{(l+1)}\)之后,要求得\(\delta^{(l)}\),需要求得\(\frac{\partial}{\partial a^{(l)}}J\)。使用链式法则进行推导
前向传播过程中,\(z_1^{(3)}=\Theta^{(2)}_{10}\times1+\Theta^{(2)}_{11}a^{(2)}_1+\Theta^{(2)}_{12}a^{(2)}_2\),\(z_2^{(3)}\)同理
所以反向传播时候,\(\frac{\partial}{\partial a_1^{(2)}}J = \Theta_{11}^{(2)} \delta^{(3)}_1 + \Theta_{21}^{(2)} \delta^{(3)}_2\),\(\frac{\partial}{\partial a_2^{(2)}}J\)同理
所以
求\(\delta^{(l)}\)时,再次运用链式法则
因为\(a^{(l)}=g(z^{(l)})\),即\(a_i^{(l)}=\frac{1}{1+e^{(-z^{(l)}_i)}}\)所以
Gradient Checking
gradApprox = (J(theta+EPSILON) - J(theta-EPSILON))/(2*EPSILON)
\(\theta \in \mathbb{R}^n\) (E.g. \(\theta\) is "unrolled" version of \(\theta^{(1)}\), \(\theta^{(2)}\), \(\theta^{(3)}\))
Random initialization
Zero initialization
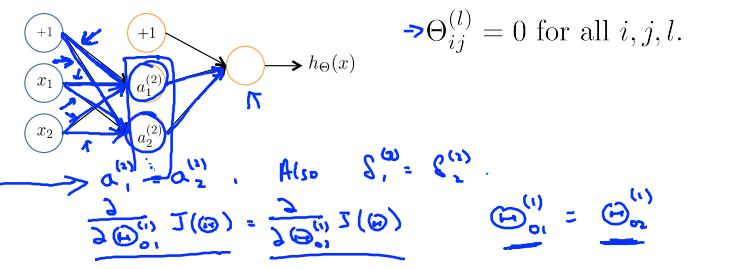
正向传播的时候,\(a_1^{(2)} = a_2^{(2)}\),所以
After each update,parameters corresponding to inputs going into each of two hidden units are identical
Symmetry breaking
Initialize each \(\Theta_{ij}^{(l)}\) to a random value in \([-\epsilon,\epsilon]\)
本文来自博客园,作者:Un-Defined,转载请保留本文署名Un-Defined,并在文章顶部注明原文链接:https://www.cnblogs.com/EIPsilly/p/15698218.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号