
Lecture12 Support Vector Machines
Lecture12 Support Vector Machines
Alternative view of logistic regression

support vector machine:
hypothesis:
Large Margin Intuition
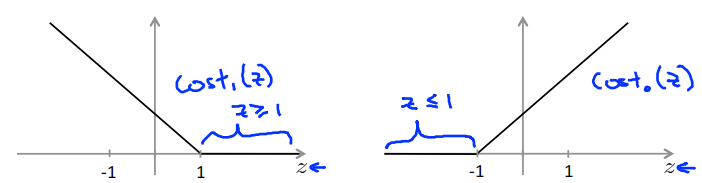
If y = 1,we want \(\theta^Tx\geq1\) (not just \(\geq0\))
If y = 1,we want \(\theta^Tx\leq-1\) (not just \(< 0\))
这里假设SVM的参数C为一个很大的数,比如10w,那么为了使损失函数尽可能的小,就要使得\(\sum^m_{i=1}[y^{(i)}cost_1(\theta^Tx^{(i)})+(1-y^{(i)})cost_0(\theta^Tx^{(i)})]\)尽可能的小,即每个样本都被正确的分类。
在此基础上,也要使\(\frac{1}{2}\sum^n_{i=1}\theta^2_j\)尽可能的小。
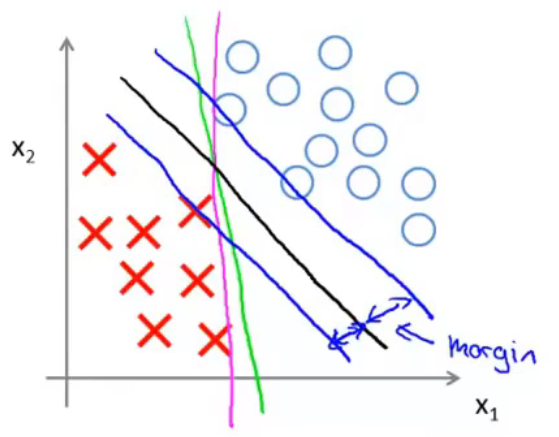
用图来进行表示。尝试用一条线来分隔两类样本。黑线的分隔效果比绿线、紫线的分隔效果更好,因为黑线有着比绿、紫二线更大的margin。此处的margin指的是距离分隔线最近的样本到分隔线的距离(即样本在\(\theta\)向量方向上的投影长度,\(\theta\)向量与分隔线是垂直的,具体见下)。这使得黑线拥有更好的鲁棒性。总而言之,SVM会选择一个模型尽量把正样本和负样本以最大的间距分开。
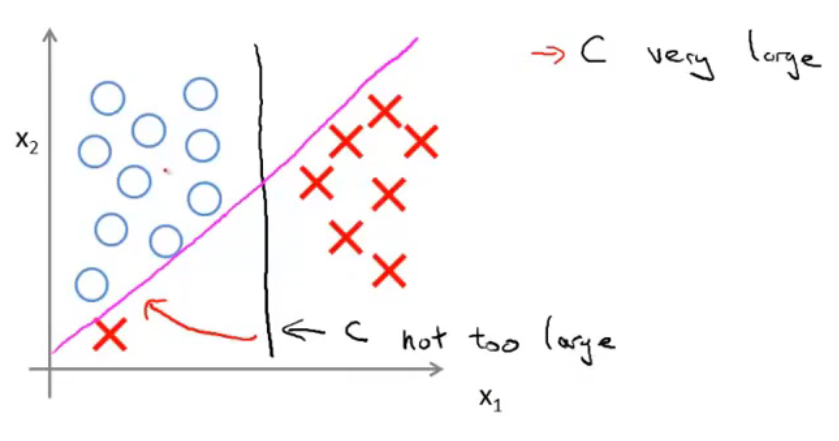
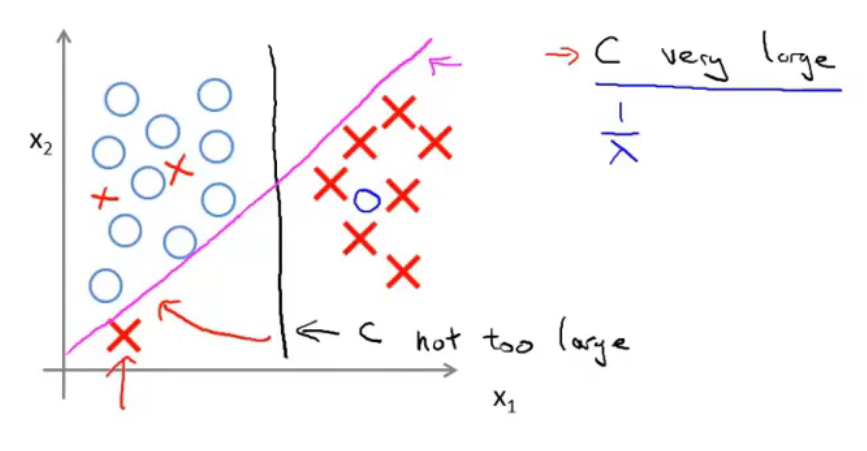
面对下图所示的情况,C较小时,分隔线是黑线。当C设置的非常大的时候,SVM会努力把所有样本都正常分类,分隔线会从黑线移动到紫线。
当数据不是线性可分的时候,如果C较小,那么SVM依然能够正常的进行分类。
The mathematics behind large margin classification(optional)
Vector Inner Product
\(u=\left[\begin{matrix}u_1\\u_2\end{matrix}\right]\) , \(v=\left[\begin{matrix}v_1\\v_2\end{matrix}\right]\)
\(\left \|u\right\|\) = length of vector \(u\) = \(\sqrt{u_1^2+u_2^2}\)
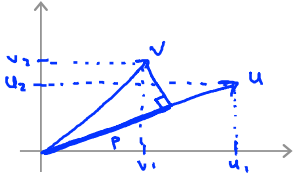
\(p\) = length of projection of \(v\) onto \(u\)
\(u^Tv=p \cdot \left \|u\right\|=u_1v_1+u_2v_2\)
SVM Decision Boundary
这里依旧假设C为一个极大的数,因此要正确的分类每一个数,即损失函数的前一项为0,目标函数变成
此处先假设\(\theta_0=0\),即\(\theta\)向量经过原点。\(\theta^Tx\)如下图所示。\(\theta^Tx^{(i)}=p^{(i)}\left\|\theta\right\|\)
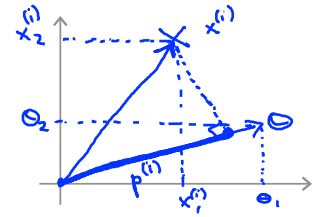
对于如下图所示的数据。绿色的线为分隔线,垂直与向量\(\theta\)。
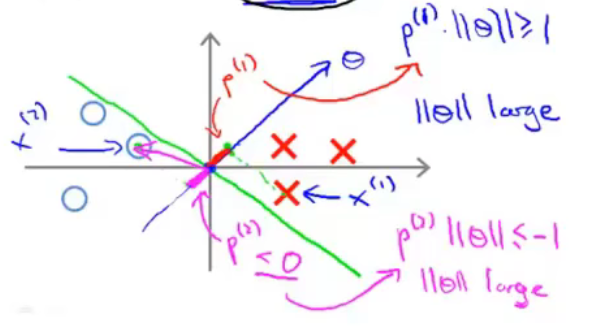
为了使得样本\(x^{(1)}\)被分类到正样本,需要\(\theta^Tx^{(i)}=p^{(i)}\left\|\theta\right\|\ge1\)。与此同时,我们还需要\(\left\|\theta\right\|\)尽可能的小(\(\underset{\theta}{min}\frac{1}{2}\sum^n_{j=1}\theta^2_j=\frac{1}{2}\left\|\theta\right\|\))。所以我们就需要投影\(p^{(i)}\)尽可能的大,这样\(\left\|\theta\right\|\)就可以尽可能的小。此处的投影长度与前面提到的样本到分隔线的间隔是同一个概念。所以SVM求得的\(\theta\)如下图所示。
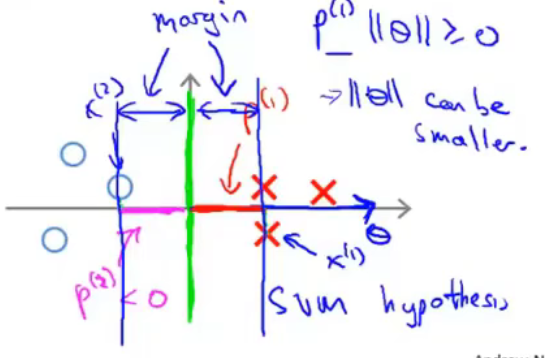
总结
SVM的目标函数的前一部分\(\sum^m_{i=1}[y^{(i)}cost_1(\theta^Tx^{(i)})+(1-y^{(i)})cost_0(\theta^Tx^{(i)})]\)的目标是尽量正确的划分每个样本。后面一部分\(\frac{1}{2}\sum^n_{i=1}\theta^2_j\)的目标是\(\theta\)向量的长度尽可能的小,从而使样本在\(\theta\)向量方向上的投影尽可能的大,即样本到分隔线的距离尽可能的大,从而使得SVM模型具有更好的鲁棒性。两者结合,整个函数的目的就是在尽可能正确划分样本的情况下,使模型具有更好的鲁棒性。参数C则是控制两个目标哪个目标更为重要
Kernels
Given x,compute new feature depending on proximity to landmarks \(l^{(1)},l^{(2)},l^{(3)}\)
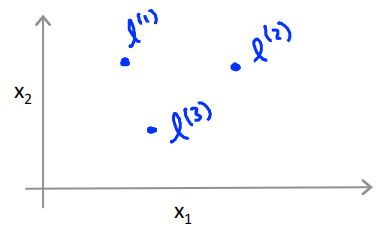
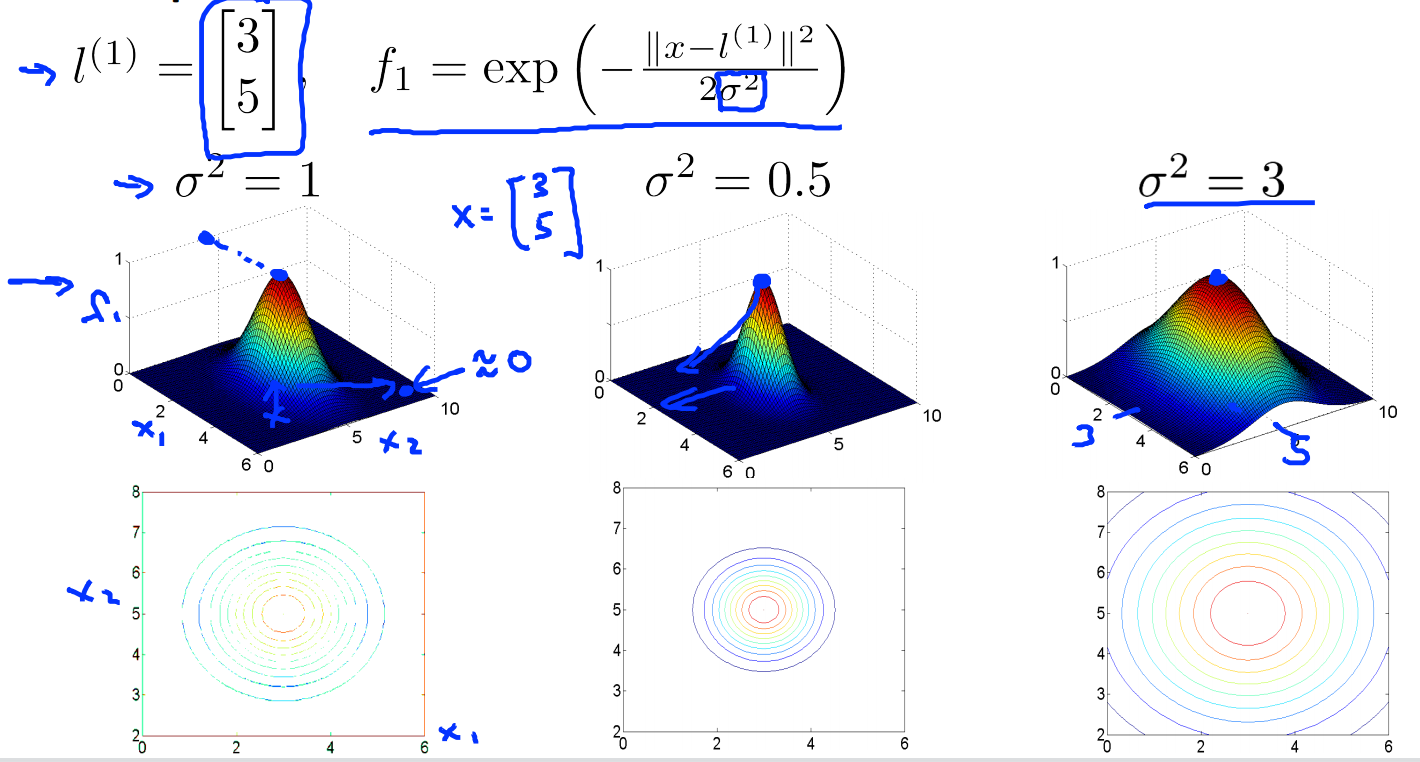
核函数指的就是similitary函数,\(exp(-\frac{\left \| x-l \right \|^2}{2\sigma^2})\)就是高斯核。
当\(x \approx l\) 时,\(f\approx exp(-\frac{0}{2\sigma^2}) \approx1\)
当\(x\)距离\(l\)很远时,\(f\approx exp(-\frac{(large\ number)^2}{2\sigma^2}) \approx0\)
\(\sigma^2\)的大小控制相似函数的平滑程度。\(\sigma^2\)越大,函数越平滑,\(\sigma^2\)越小,函数越陡峭
SVM with Kernels
给定m个样本\((x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),\cdots,(x^{(m)},y^{(m)})\),选择每个x作为标记点,即\(l^{(1)}=x^{(1)},l^{(2)}=x^{(2)},\cdots,l^{(m)}=x^{(m)}\)
对于给定的样本x,计算
输入\(x^{(i)}\)从原来的\(x^{(i)}\in\mathbb{R}^n\)变成了\(f^{(i)}=\left[\begin{matrix}f_0^{(i)}\\f_1^{(i)}\\\vdots\\f_m^{(i)}\end{matrix}\right]\) ,此处\(f_0^{(i)}=1\),\(f^{(i)} \in\mathbb{R}^{m+1}\)
Hypothesis:Given x,compute features \(f \in \mathbb{R}^{m+1}\),predict "y=1" if \(\theta^Tf=\theta_0f_0+\theta_1f_1+\dots+\theta_mf_m\ge0(\theta\in\mathbb{R}^{m+1})\)
Training:
最后一项\(\frac{1}{2}\sum^m_{i=1}\theta^2_j\)也可以写作\(\theta^T\theta\)(忽略\(\theta_0\))。实际实现时最后一项会优化成\(\theta^TM\theta\),矩阵\(M\)取决于你的核函数,这意味着我们缩小了一种类似的度量,从而使SVM更有效率的运行。
SVM parameters
C偏大,低偏差,高方差,过拟合
C偏小,高偏差,低方差,欠拟合
\(\sigma^2\)偏大,特征\(f_i\)变化平滑,高偏差,低方差,欠拟合
\(\sigma^2\)偏小,特征\(f_i\)变化迅速,低偏差,高方差,过拟合
本文来自博客园,作者:Un-Defined,转载请保留本文署名Un-Defined,并在文章顶部注明原文链接:https://www.cnblogs.com/EIPsilly/p/15698197.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号