

网站架构结构的变迁史
前些天看到一篇不错的文章[1],讲的是网站架构的发展历史,这种综述的文章往往很难得,这里进行一个简化诉述和我个人的解读,详细的信息可以参看Ref的连接。首先,我先给一个通俗的理解,网站架构发展的驱动力是用户数和数据量的膨胀,压力瓶颈在websever连接和database之间来回切换,解决问题的三板斧:加缓存(精益求精地做缓存。。。)、加机器(多搞搞分布式,一台不行多台)和功能分离(读写分离、业务分离、动静分离等等)。下面是所读那篇文章的主要思路。
网站架构的演变主要经历了如下几个阶段:
1、物理分离webserver和数据库
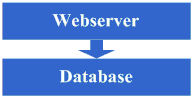
比较直观,不再赘述。
2、增加页面缓存
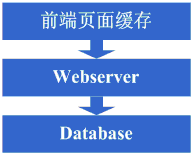
目的是减小数据库连接的资源竞争以及对数据库读访问的压力,此时会采用squid等机制将更新周期相对较长的静态页面做缓存,从而减少对webserver和databse的压力。
3、增加页面片段缓存
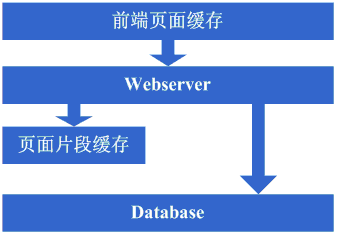
采用前端页面缓存类似的技术,不过这里更进一步将动态页面中相对静态的部分也做了缓存,使用ESI之类的页面片段缓存策略。进一步缓解database的读压力。
4、数据缓存
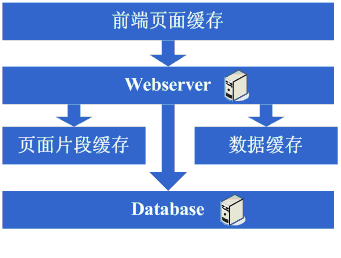 同样的思路,不过这里是将数据库中经常访问的、重复获取的数据放到缓存里,也就是数据缓存,进一步缓解数据库压力。由此可见,在网站发展的开始阶段,大家提高网站性能的主要途径就是加缓存,另外,在这些阶段,database的IO始终是限制并发和性能瓶颈。
同样的思路,不过这里是将数据库中经常访问的、重复获取的数据放到缓存里,也就是数据缓存,进一步缓解数据库压力。由此可见,在网站发展的开始阶段,大家提高网站性能的主要途径就是加缓存,另外,在这些阶段,database的IO始终是限制并发和性能瓶颈。
5、增加webserver
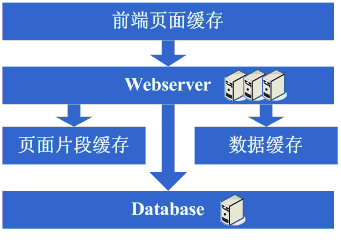
随着系统访问量的进一步增加,websever上的压力徒增,在高峰时无法保证稳定连接,这是为了解决可用性问题,避免单点,引入了多机。sever集群的介入带来一些新问题,也诞生了一些新技术:负载均衡问题(Apache自带的负载均衡或者lvs),可靠性问题(主备技术,heart-beat等),状态信息同步问题(用户session同步和共享技术、状态信息广播),缓存信息的同步(分布式缓存,缓存同步等),多机系统文件功能的保持(共享文件、共享存储等等)
6、分库
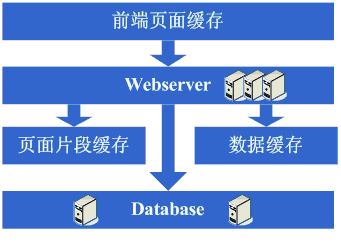
此时应对的数据量的膨胀,数据库需要进行分库和调优,database也分摊到多机上面。
7、分表、DAL和分布式缓存
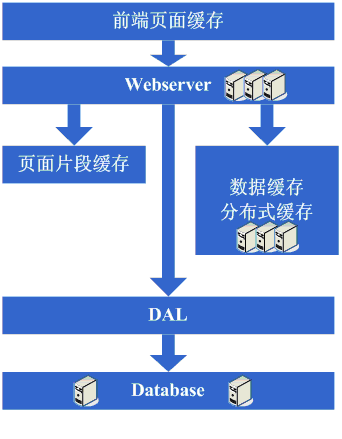
数据量继续大幅增长,于是出现了通用的框架来实现分库分表的数据访问(例如ebay架构中对一个的DAL),并且由于数据量过大,不太可能再缓存在本地,于是采用了分布式缓存。动态hash算法、一致性hash以及DAL技术得到了广泛的应用。
8、增加更多的server
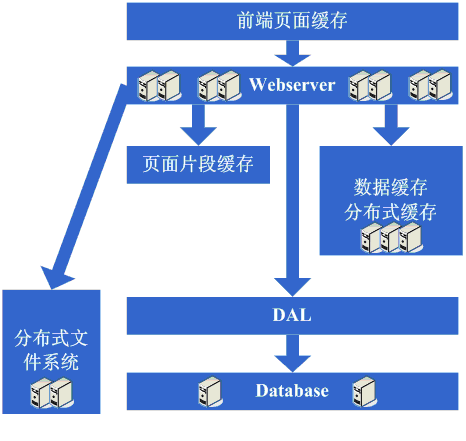
当上面的技术缓解了database的压力时,webserver又成为瓶颈,尤其是面临越来越多的连接请求,过高的请求数会被apache服务器阻塞排队,从而响应速度变慢。此时就需要进一步的增加websever的数量,这带来了新的挑战,例如之前的负载均衡方法hold不住了(硬件负载,如F5、Netsclar、Athelon之类的开始成为选择,但价格昂贵,或者采用逻辑分类的方法,将请求分散到不同的软负载集群)、文件共享瓶颈(分布式文件系统迎来了大规模应用)
9、数据读写分离和廉价存储方案
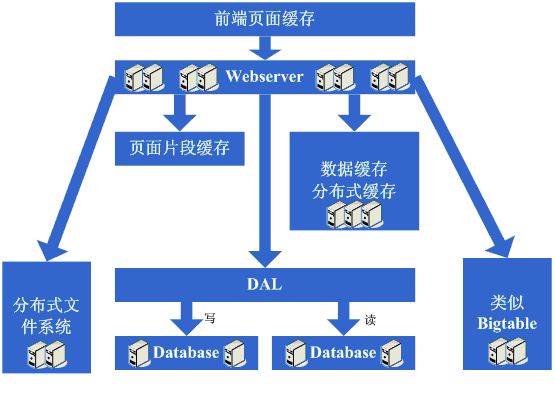
websever连接的问题得到缓和了,数据库又出问题了,此时分析数据库的压力情况,发现其读写比很高,因此想到了读写分离方案,另外编写一些更为廉价的存储方案,例如BigTable。
10、大型分布式应用时代和廉价服务器群的时代
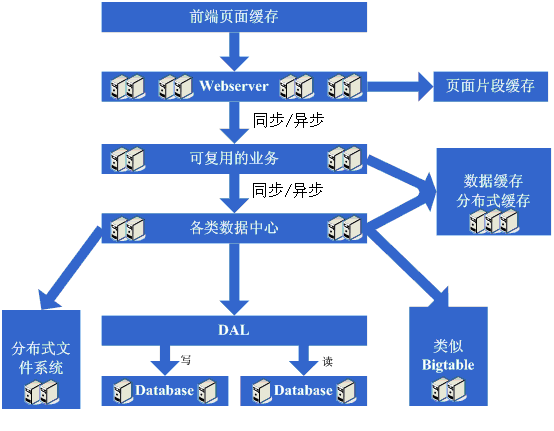
这时做的主要事情是将系统进行业务职责才分,形成大型的分布式应用,这个步骤相当艰难和耗时,主要挑战有(下面三点摘的原话):
1)、拆成分布式后需要提供一个高性能、稳定的通信框架,并且需要支持多种不同的通信和远程调用方式;
2)、将一个庞大的应用拆分需要耗费很长的时间,需要进行业务的整理和系统依赖关系的控制等;
3)、如何运维(依赖管理、运行状况管理、错误追踪、调优、监控和报警等)好这个庞大的分布式应用。
Ref:
[1] http://www.blogjava.net/BlueDavy/archive/2008/09/03/226749.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号