第一次软工作业
第一次软工作业
| 项目 | 内容 |
|---|---|
| 第一次软工作业 | 作业要求 |
| 作业目的 | 提高编程能力 |
github地址:https://github.com/ECLE10/zuoye
P2P表格
| P2P2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 50 | 60 |
| Estimate | 估计这个任务需要多少时间 | 40 | 50 |
| Development | 开发 | 890 | 1500 |
| Analysis | 需求分析 (包括学习新技术) | 450 | 560 |
| Design Spec | 生成设计文档 | 40 | 50 |
| Design Review | 设计复审 | 60 | 70 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 80 | 90 |
| Design | 具体设计 | 70 | 80 |
| Coding | 具体编码 | 220 | 350 |
| Code Review | 代码复审 | 60 | 80 |
| Test | 测试(自我测试,修改代码,提交修改) | 70 | 80 |
| Reporting | 报告 | 80 | 100 |
| Test Repor | 测试报告 | 50 | 60 |
| Size Measurement | 计算工作量 | 40 | 45 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 50 | 60 |
| 合计 | 2250 | 3235 |
计算模块接口的设计与实现过程
实现原理:余弦值的范围在[-1,1]之间,值越趋近于1,文档越相似;接近于0,表示两篇文章没有相似之处。
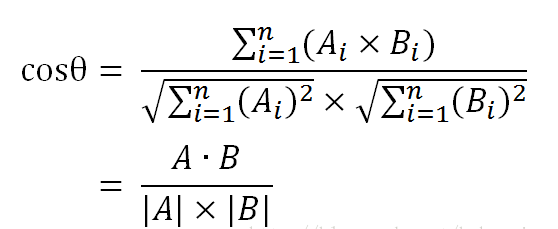
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
1 分词。
句子A:这只/皮靴/号码/大了。那只/号码/合适。
句子B:这只/皮靴/号码/不/小,那只/更/合适。
2 列出所有的词。
这只,皮靴,号码,大了。那只,合适,不,小,很
3 计算词频。
句子A:这只1,皮靴1,号码2,大了1。那只1,合适1,不0,小0,更0
句子B:这只1,皮靴1,号码1,大了0。那只1,合适1,不1,小1,更1
4 写出词频向量。
句子A:(1,1,2,1,1,1,0,0,0)
句子B:(1,1,1,0,1,1,1,1,1)
关键函数

计算模块部分单元测试
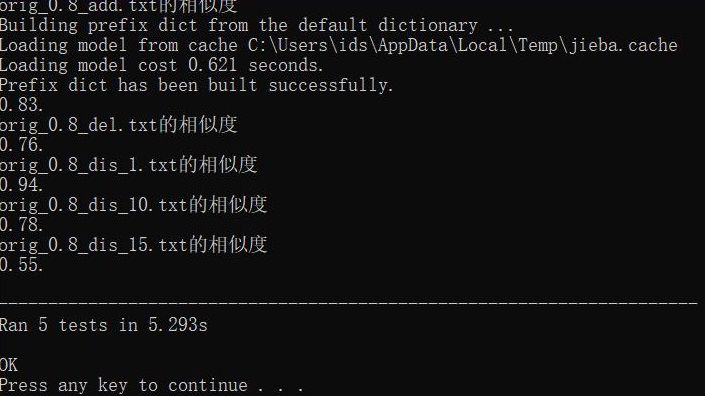
计算模块改进
使用工具测试性能
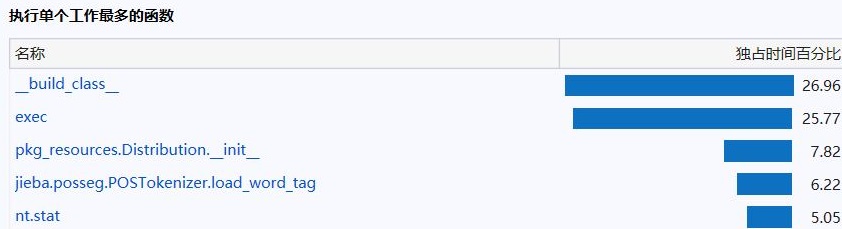
代码覆盖率

计算模块部分异常处理说明
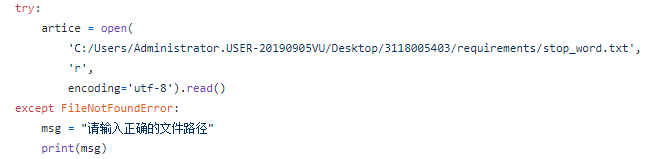
文本编码错误 出现异常
总结
本次任务对于我来说有点困难 所以在deadline之后才堪堪完成 难点在于分句函数的理解和使用 对比函数的使用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号