
闲的无聊时候就手动写第一个漏洞扫描工具吧!
上课太无聊了,今天就用python写个漏洞扫描器玩玩,原理是先检测漏洞,在扫描备份,文件结果自动保存在当前目录
主要就是:信息获取、模拟攻击。
网络漏洞扫描对目标系统进行漏洞检测时,首先探测目标系统的存活主机,对存活主机进行端口扫描,确定系统开放的端口,同时根据协议指纹技术识别出主机的操作系统类型。然后扫描器对开放的端口进行网络服务类型的识别,确定其提供的网络服务。漏洞扫描器根据目标系统的操作系统平台和提供的网络服务,调用漏洞资料库中已知的各种漏洞进行逐一检测,通过对探测响应数据包的分析判断是否存在漏洞。
因此,只要我们认真研究各种漏洞,知道它们的探测特征码和响应特征码就可以利用软件来实现对各种已知漏洞的模拟。
由于漏洞模拟系统实际上是分析扫描器发出的探测包中的是否含有探测特征码并返回具有相应响应特征码的数据包。因此,对每一个漏洞,探测特征码和响应特征码是两项必需的描述。
采用数据库技术可以方便地向漏洞资料库中添加新发现的漏洞,使漏洞模拟软件能够不断地更新漏洞资料库,可以更加有效地测试扫描器对安全漏洞的检测能力。(我在这里,由于技术原因没有建立数据库而是用文本文件保存的特征码。)
config.txt是配置文件
url.txt是要扫描的url
内部配置相关的常见编辑器漏洞和svn源码泄露漏洞
多线程运行
程序的思路是
附上config.txt

/a.zip /web.zip /web.rar /1.rar /bbs.rar /www.root.rar /123.rar /data.rar /bak.rar /oa.rar /admin.rar /www.rar /2014.rar /2015.rar /2016.rar /2014.zip /2015.zip /2016.zip /1.zip /1.gz /1.tar.gz /2.zip /2.rar /123.rar /123.zip /a.rar /a.zip /admin.rar /back.rar /backup.rar /bak.rar /bbs.rar /bbs.zip /beifen.rar /beifen.zip /beian.rar /data.rar /data.zip /db.rar /db.zip /flashfxp.rar /flashfxp.zip /fdsa.rar /ftp.rar /gg.rar /hdocs.rar /hdocs.zip /HYTop.mdb /root.rar /Release.rar /Release.zip /sql.rar /test.rar /template.rar /template.zip /upfile.rar /vip.rar /wangzhan.rar /wangzhan.zip /web.rar /web.zip /website.rar /www.rar /www.zip /wwwroot.rar /wwwroot.zip /wz.rar /备份.rar /网站.rar /新建文件夹.rar /新建文件夹.zip
漏洞扫描工具.py
# -*- coding:utf-8 -*- import requests import time import Queue import threading import urllib2 import socket timeout=3 socket.setdefaulttimeout(timeout) q = Queue.Queue() time.sleep(5) headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102Safari/537.36'} f1 = open('url.txt','r') f2 = f1.readlines() f1.close() f3 = open('result.txt','a+') f9 = open('config.txt','r') #配置文件载入 f4 = f9.readlines() f9.close() def rarzip(): #开始构建扫描函数 try: #域名rarzip扫描 print yumingrar reqryumingrar = urllib2.Request(url=yumingrar,headers=headers) ryumingrar = urllib2.urlopen(reqryumingrar) if ryumingrar.code == 200: metarar = ryumingrar.info() sizerar = str(metarar.getheaders("Content-Length")[0]) #文件大小 sizerar1 = int(metarar.getheaders("Content-Length")[0]) if sizerar1 > 8888: print '★★★★★Found A Success Url Maybe backups★★★★★' print yumingrar print 'Size:' + sizerar + 'Kbs' f3.write(yumingrar + '----------' + sizerar + 'Kbs' + '\n') else: print '888 Safe Dog I Fuck You 888' else: print '[+]Pass.........................' except: pass try: print yumingzip reqryumingzip = urllib2.Request(url=yumingzip,headers=headers) ryumingzip = urllib2.urlopen(reqryumingrar) if ryumingzip.code == 200: metazip = ryumingrar.info() sizezip = str(metazip.getheaders("Content-Length")[0]) sizezip1 = int(metazip.getheaders("Content-Length")[0]) if sizezip1 > 8888: print '★★★★★Found A Success Url Maybe backups★★★★★' print yumingzip print 'Size:' + sizezip + 'Kbs' f3.write(yumingzip + '----------' + sizezip + 'Kbs' + '\n') else: print '888 Safe Dog I Fuck You 888' else: print '[+]Pass.........................' except: pass def svn(): try: #svn漏洞扫描 print yumingsvn ryumingsvn = requests.get(url=yumingsvn,headers=headers,allow_redirects=False,timeout=3) if ryumingsvn_status == 200: print '★★★★★Found A Success Url Maybe Vulnerability★★★★★' f3.write(yumingsvn + ' 【SVN源码泄露漏洞】' + '\n') else: print '[+]Pass.........................' except: print "[+]Can not connect url" pass def eweb(): try: #ewebeditor漏洞扫描 print '---------------Ewebeditor Vulnerability Scan---------------' print eweb1 reweb1 = requests.get(url=eweb1,headers=headers,allow_redirects=False,timeout=3) if reweb1_status == 200: print '★★★★★Found A Success Url Maybe Vulnerability★★★★★' f3.write(eweb1 + ' 【Ewebeditor编辑器漏洞】' + '\n') else: print '[+]Pass.........................' except: print "[+]Can not connect url" pass try: print eweb2 reweb2 = requests.get(url=eweb2,headers=headers,allow_redirects=False,timeout=3) if reweb2_status == 200: print '★★★★★Found A Success Url Maybe Vulnerability★★★★★' f3.write(eweb2 + ' 【Ewebeditor编辑器漏洞】' + '\n') else: print '[+]Pass.........................' except: print "[+]Can not connect url" pass try: print eweb3 reweb3 = requests.get(url=eweb3,headers=headers,allow_redirects=False,timeout=3) if reweb3_status == 200: print '★★★★★Found A Success Url Maybe Vulnerability★★★★★' f3.write(eweb3 + ' 【Ewebeditor编辑器漏洞】' + '\n') else: print '[+]Pass.........................' except: print "[+]Can not connect url" pass try: print eweb4 reweb4 = requests.get(url=eweb4,headers=headers,allow_redirects=False,timeout=3) if reweb4_status == 200: print '★★★★★Found A Success Url Maybe Vulnerability★★★★★' f3.write(eweb4 + ' 【Ewebeditor编辑器漏洞】' + '\n') else: print '[+]Pass.........................' except: print "[+]Can not connect url" pass try: print eweb5 reweb5 = requests.get(url=eweb5,headers=headers,allow_redirects=False,timeout=3) if reweb5_status == 200: print '★★★★★Found A Success Url Maybe Vulnerability★★★★★' f3.write(eweb5 + ' 【Ewebeditor编辑器漏洞】' + '\n') else: print '[+]Pass.........................' except: print "[+]Can not connect url" pass try: print eweb6 reweb6 = requests.get(url=eweb6,headers=headers,allow_redirects=False,timeout=3) if reweb6_status == 200: print '★★★★★Found A Success Url Maybe Vulnerability★★★★★' f3.write(eweb6 + ' 【Ewebeditor编辑器漏洞】' + '\n') else: print '[+]Pass.........................' except: print "[+]Can not connect url" pass #fckeditor漏洞扫描 def fck(): try: print '---------------Fckeditor Vulnerability Scan---------------' print fck1 rfck1 = requests.get(url=fck1,headers=headers,allow_redirects=False,timeout=3) if rfck1_status == 200: print '★★★★★Found A Success Url Maybe Vulnerability★★★★★' f3.write(fck1 + ' 【Fckeditor编辑器漏洞】' + '\n') else: print '[+]Pass.........................' except: print "[+]Can not connect url" pass try: print fck2 rfck2 = requests.get(url=fck2,headers=headers,allow_redirects=False,timeout=3) if rfck2_status == 200: print '★★★★★Found A Success Url Maybe Vulnerability★★★★★' f3.write(fck2 + ' 【Fckeditor编辑器漏洞】' + '\n') else: print '[+]Pass.........................' except: print "[+]Can not connect url" pass try: print fck3 rfck3 = requests.get(url=fck3,headers=headers,allow_redirects=False,timeout=3) if rfck3_status == 200: print '★★★★★Found A Success Url Maybe Vulnerability★★★★★' f3.write(fck3 + ' 【Fckeditor编辑器漏洞】' + '\n') else: print '[+]Pass.........................' except: print "[+]Can not connect url" pass try: print fck4 rfck4 = requests.get(url=fck4,headers=headers,allow_redirects=False,timeout=3) if rfck4_status == 200: print '★★★★★Found A Success Url Maybe Vulnerability★★★★★' f3.write(fck4 + ' 【Fckeditor编辑器漏洞】' + '\n') else: print '[+]Pass.........................' except: print "[+]Can not connect url" pass try: print fck5 rfck5 = requests.get(url=fck5,headers=headers,allow_redirects=False,timeout=3) if rfck5_status == 200: print '★★★★★Found A Success Url Maybe Vulnerability★★★★★' f3.write(fck5 + ' 【Fckeditor编辑器漏洞】' + '\n') else: print '[+]Pass.........................' except: print "[+]Can not connect url" pass try: print fck6 rfck6 = requests.get(url=fck6,headers=headers,allow_redirects=False,timeout=3) if rfck6_status == 200: print '★★★★★Found A Success Url Maybe Vulnerability★★★★★' f3.write(fck6 + ' 【Fckeditor编辑器漏洞】' + '\n') else: print '[+]Pass.........................' except: print "[+]Can not connect url" pass for i in f2: c = i.strip('\n') print c try: ceshi = requests.get(url=c,headers=headers,allow_redirects=False,timeout=3) if ceshi.status_code == 200: a = c.split(".",2)[1] #获取主域名 yumingrar = c + '/' + a + '.rar' #构造域名 + zip 的备份 yumingzip = c + '/' + a + '.zip' rarzip() #开始对一系列特殊漏洞后缀构造url yumingsvn = c + '/.svn/entries' #svn漏洞 svn() eweb1 = c + '/editor/editor/filemanager/browser/default/connectors/test.html' #ewebeditor编辑器漏洞 eweb2 = c + '/editor/editor/filemanager/connectors/test.html' eweb3 = c + '/editor/editor/filemanager/connectors/uploadtest.html' eweb4 = c + '/html/db/ewebeditor.mdb' eweb5 = c + '/db/ewebeditor.mdb' eweb6 = c + '/db/ewebeditor.asp' eweb() fck1 = c + '/fckeditor/editor/filemanager/browser/default/connectors/test.html' #fckeditor编辑器漏洞 fck2 = c + '/fckeditor/editor/filemanager/connectors/test.html' fck3 = c + '/FCKeditor/editor/filemanager/connectors/uploadtest.html' fck4 = c + '/FCKeditor/editor/filemanager/upload/test.html' fck5 = c + '/fckeditor/editor/filemanager/browser/default/browser.html' fck6 = c + '/FCKeditor/editor/fckeditor.html' fck() else: pass except: print "NO USE URL WHAT FUCK A BIG URL" pass for i in f2: c = i.strip('\n') try: ce = requests.get(url=c,headers=headers,allow_redirects=False,timeout=3) if ce.status_code == 200: q.put(c) else: pass except: print "NO USE URL WHAT FUCK A BIG URL" pass def starta(): print '---------------Start Backups Scan---------------' #开始从字典载入了~ while not q.empty(): zhaohan = q.get() #url网址载入队列了 for f5 in f4: f6 = f5.strip('\n') #正确的备份内容 urlx = zhaohan + f6 #正确的网址 + 备份 print urlx try: req = urllib2.Request(url=urlx,headers=headers) response = urllib2.urlopen(req) if response.code == 200: meta = response.info() sizes = str(meta.getheaders("Content-Length")[0]) sizess = int(meta.getheaders("Content-Length")[0]) if sizess < 8888: print '888 Safe Dog I Fuck You 888' else: print '★★★★★Found A Success Url Maybe backups★★★★★' print 'Size:' + sizes + 'Kbs' f3.write(urlx + '----------' + sizes + '\n') else: print '[+]Pass.........................' except: pass thread1 = threading.Thread(target = starta()) thread1.start() f3.close() print '--------------------------------------------------------------------' print '--------------------------------OVER--------------------------------' print '--------------------------------------------------------------------' time.sleep(10) exit()
看样子效果还是挺明显的:
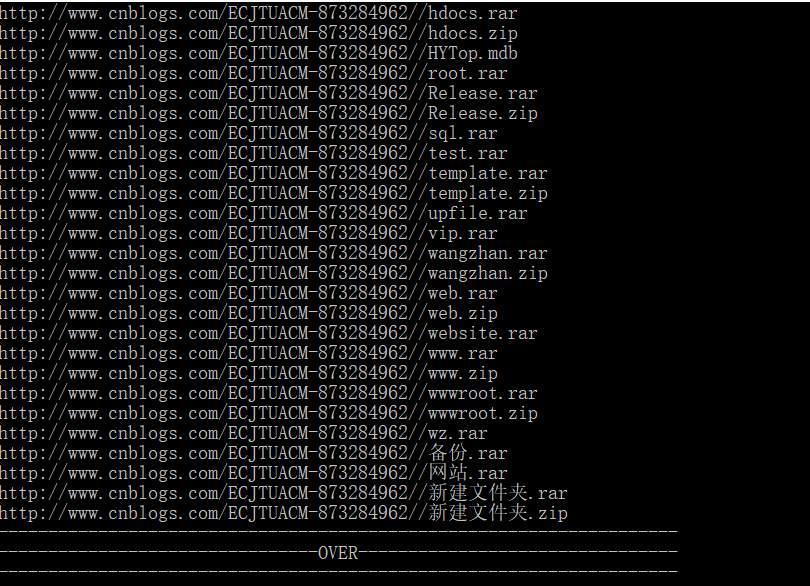
然后看了看大神们写的,发现了一种比较精简的写法:
/wls-wsat/CoordinatorPortType /wls-wsat/CoordinatorPortType11 :9443/wls-wsat/CoordinatorPortType :9443/wls-wsat/CoordinatorPortType11 :8470/wls-wsat/CoordinatorPortType :8470/wls-wsat/CoordinatorPortType11 :8447/wls-wsat/CoordinatorPortType :8447/wls-wsat/CoordinatorPortType11 :8080 :8007 /asynchPeople /manage /script :8080/jenkins :8007/jenkins /jenkins /.svn/entries /.svn /console/ /manager :8080/manager :8080/manager/html /manager/html /invoker/JMXInvokerServlet /invoker :8080/jmx-console/ /jmx-console/ /robots.txt /system /wls-wsat/CoordinatorPortType /wsat/CoordinatorPortType /wls-wsat/CoordinatorPortType11 /wsat/CoordinatorPortType11 /examples/ /examples/servlets/servlet/SessionExample /solr/ /.git/config /.git/index /.git/HEAD /WEB-INF/ /core /old.zip /old.rar /old.tar.gz /old.tar.bz2 /old.tgz /old.7z /temp.zip /temp.rar /temp.tar.gz /temp.tgz /temp.tar.bz2 /package.zip /package.rar /package.tar.gz /package.tgz /package.tar.bz2 /tmp.zip /tmp.rar /tmp.tar.gz /tmp.tgz /tmp.tar.bz2 /test.zip /test.rar /test.tar.gz /test.tgz /test.tar.bz2 /backup.zip /backup.rar /backup.tar.gz /backup.tgz /back.tar.bz2 /db.zip /db.rar /db.tar.gz /db.tgz /db.tar.bz2 /db.log /db.inc /db.sqlite /db.sql.gz /dump.sql.gz /database.sql.gz /backup.sql.gz /data.zip /data.rar /data.tar.gz /data.tgz /data.tar.bz2 /database.zip /database.rar /database.tar.gz /database.tgz /database.tar.bz2 /ftp.zip /ftp.rar /ftp.tar.gz /ftp.tgz /ftp.tar.bz2 /log.txt /log.tar.gz /log.rar /log.zip /log.tgz /log.tar.bz2 /log.7z /logs.txt /logs.tar.gz /logs.rar /logs.zip /logs.tgz /logs.tar.bz2 /logs.7z /web.zip /web.rar /web.tar.gz /web.tgz /web.tar.bz2 /www.log /www.zip /www.rar /www.tar.gz /www.tgz /www.tar.bz2 /wwwroot.zip /wwwroot.rar /wwwroot.tar.gz /wwwroot.tgz /wwwroot.tar.bz2 /output.zip /output.rar /output.tar.gz /output.tgz /output.tar.bz2 /admin.zip /admin.rar /admin.tar.gz /admin.tgz /admin.tar.bz2 /upload.zip /upload.rar /upload.tar.gz /upload.tgz /upload.tar.bz2 /website.zip /website.rar /website.tar.gz /website.tgz /website.tar.bz2 /package.zip /package.rar /package.tar.gz /package.tgz /package.tar.bz2 /sql.log /sql.zip /sql.rar /sql.tar.gz /sql.tgz /sql.tar.bz2 /sql.7z /sql.inc /data.sql /qq.sql /tencent.sql /database.sql /db.sql /test.sql /admin.sql /backup.sql /user.sql /sql.sql /index.zip /index.7z /index.bak /index.rar /index.tar.tz /index.tar.bz2 /index.tar.gz /dump.sql /old.zip /old.rar /old.tar.gz /old.tar.bz2 /old.tgz /old.7z /1.tar.gz /a.tar.gz /x.tar.gz /o.tar.gz /conf/conf.zip /conf.tar.gz /qq.pac /tencent.pac /server.cfg /deploy.tar.gz /build.tar.gz /install.tar.gz /secu-tcs-agent-mon-safe.sh /password.tar.gz /site.tar.gz /tenpay.tar.gz /rsync_log.sh /rsync.sh /webroot.zip /tools.tar.gz /users.tar.gz /webserver.tar.gz /htdocs.tar.gz /admin/ /admin.php /admin.do /login.php /login.do /admin.html /manage/ /server-status /login/ /fckeditor/_samples/default.html /ckeditor/samples/ /fck/editor/dialog/fck_spellerpages/spellerpages/server-scripts/spellchecker.php /fckeditor/editor/dialog/fck_spellerpages/spellerpages/server-scripts/spellchecker.php /app/config/database.yml /database.yml /sqlnet.log /database.log /db.log /db.conf /db.ini /logs.ini /upload.do /upload.jsp /upload.php /upfile.php /upload.html /upload.cgi /jmx-console/HtmlAdaptor /cacti/ /zabbix/ /jira/ /jenkins/static/f3a41d2f/css/style.css /static/f3a41d2f/css/style.css /exit /memadmin/index.php /phpmyadmin/index.php /pma/index.php /ganglia/ /_phpmyadmin/index.php /pmadmin/index.php /config/config_ucenter.php.bak /config/.config_ucenter.php.swp /config/.config_global.php.swp /config/config_global.php.1 /uc_server/data/config.inc.php.bak /config/config_global.php.bak /include/config.inc.php.tmp /access.log /error.log /log/access.log /log/error.log /log/log.log /logs/error.log /logs/access.log /error.log /errors.log /debug.log /log /logs /debug.txt /debug.out /.bash_history /.rediscli_history /.bashrc /.bash_profile /.bash_logout /.vimrc /.DS_Store /.history /.htaccess /htaccess.bak /.htpasswd /.htpasswd.bak /htpasswd.bak /nohup.out /.idea/workspace.xml /.mysql_history /httpd.conf /web.config /shell.php /1.php /spy.php /phpspy.php /webshell.php /angle.php /resin-doc/resource/tutorial/jndi-appconfig/test?inputFile=/etc/profile /resin-doc/viewfile/?contextpath=/&servletpath=&file=index.jsp /application/configs/application.ini /wp-login.php /wp-config.inc /wp-config.bak /wp-config.php~ /.wp-config.php.swp /wp-config.php.bak /.ssh/known_hosts /.ssh/known_hosts /.ssh/id_rsa /id_rsa /.ssh/id_rsa.pub /.ssh/id_dsa /id_dsa /.ssh/id_dsa.pub /.ssh/authorized_keys /owa/ /ews/ /readme /README /readme.md /readme.html /changelog.txt /data.txt /CHANGELOG.txt /CHANGELOG.TXT /install.txt /install.log /install.sh /deploy.sh /install.txt /INSTALL.TXT /config.php /config/config.php /config.inc /config.inc.php /config.inc.php.1 /config.php.bak /db.php.bak /conf/config.ini /config.ini /config/config.ini /configuration.ini /configs/application.ini /settings.ini /application.ini /conf.ini /app.ini /config.json /output /a.out /test /tmp /temp /user.txt /users.txt /key /keys /key.txt /keys.txt /pass.txt /passwd.txt /password.txt /pwd.txt /php.ini /sftp-config.json /index.php.bak /.index.php.swp /index.cgi.bak /config.inc.php.bak /.config.inc.php.swp /config/.config.php.swp /.config.php.swp /app.cfg /setup.sh /../../../../../../../../../../../../../etc/passwd /../../../../../../../../../../../../../etc/hosts /../../../../../../../../../../../../../etc/sysconfig/network-scripts/ifcfg-eth1 /%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/hosts /..%2F..%2F..%2F..%2F..%2F..%2F..%2F..%2F..%2Fetc%2Fpasswd /..%252F..%252F..%252F..%252F..%252F..%252F..%252F..%252F..%252Fetc%252Fpasswd /%2e%2e%2f%2e%2e%2f%2e%2e%2f%2e%2e%2f%2e%2e%2f%2e%2e%2f%2e%2e%2f%2e%2e%2f%2e%2e%2fetc%2fpasswd //././././././././././././././././././././././././../../../../../../../../etc/passwd /etc/passwd /file:///etc/passwd /etc/hosts /aa/../../cc/../../bb/../../dd/../../aa/../../cc/../../bb/../../dd/../../bb/../../dd/../../bb/../../dd/../../bb/../../dd/../../ee/../../etc/hosts /proc/meminfo /etc/profile /resource/tutorial/jndi-appconfig/test?inputFile=/etc/passwd /WEB-INF/web.xml /WEB-INF/web.xml.bak /WEB-INF/applicationContext.xml /WEB-INF/applicationContext-slave.xml /WEB-INF/config.xml /WEB-INF/spring.xml /WEB-INF/struts-config.xml /WEB-INF/struts-front-config.xml /WEB-INF/struts/struts-config.xml /WEB-INF/classes/spring.xml /WEB-INF/classes/struts.xml /WEB-INF/classes/struts_manager.xml /WEB-INF/classes/conf/datasource.xml /WEB-INF/classes/data.xml /WEB-INF/classes/config/applicationContext.xml /WEB-INF/classes/applicationContext.xml /WEB-INF/classes/conf/spring/applicationContext-datasource.xml /WEB-INF/config/db/dataSource.xml /WEB-INF/spring-cfg/applicationContext.xml /WEB-INF/dwr.xml /WEB-INF/classes/hibernate.cfg.xml /WEB-INF/classes/rabbitmq.xml /WEB-INF/database.properties /WEB-INF/web.properties /WEB-INF/log4j.properties /WEB-INF/classes/dataBase.properties /WEB-INF/classes/application.properties /WEB-INF/classes/jdbc.properties /WEB-INF/classes/db.properties /WEB-INF/classes/conf/jdbc.properties /WEB-INF/classes/security.properties /WEB-INF/conf/database_config.properties /WEB-INF/config/dbconfig /WEB-INF/conf/activemq.xml /server.xml /config/database.yml /configprops /phpinfo.php /phpinfo.php5 /info.php /php.php /pi.php /mysql.php /sql.php /shell.php /apc.php /test.sh /logs.sh /test/ /test.php /temp.php /tmp.php /test2.php /test2.php /test.html /test2.html /test.txt /test2.txt /debug.php /a.php /b.php /t.php /i.php /x.php /1.php /123.php /test.cgi /test-cgi /cgi-bin/test-cgi /cgi-bin/test /cgi-bin/test.cgi /zabbix/jsrpc.php /jsrpc.php
dirFinder.py
#!/usr/bin/env python # -*- coding:utf-8 -*- #from flask import Flask, request, json, Response, jsonify import json import threading import requests import urllib2 import sys import threading from time import ctime,sleep import threadpool #app = Flask(__name__) #@app.route('/', methods = ['GET','POST']) def main(): #if request.method == 'GET': #geturl = request.args.get('geturl') f = open("url.txt") line = f.readlines() global g_list g_list = [] urllist = [] list1 = [] for u in line: u = u.rstrip() #dir = ['/admin','/t/344205'] dir = open("rule.txt") dirline = dir.readlines() for d in dirline: d = d.rstrip() scheme = ['http://','https://'] for s in scheme: #print type(s) #print type(geturl) #print type(d) url = s + u + d list1.append(url) thread_requestor(list1) #return json.dumps(g_list) f = open('vulurl.txt','w') f.write(json.dumps(g_list)) f.close() def res_printer(res1,res2): if res2: g_list.append(res2) else: pass def thread_requestor(urllist): pool = threadpool.ThreadPool(200) reqs = threadpool.makeRequests(getScan,urllist,res_printer) [pool.putRequest(req) for req in reqs] pool.wait() def getScan(url): try: requests.packages.urllib3.disable_warnings() status = requests.get(url, allow_redirects=False, timeout=3,verify=False).status_code print "scanning " + url if status == 200: return url else: pass except: pass if __name__ == "__main__": main()
扫描结果如下:
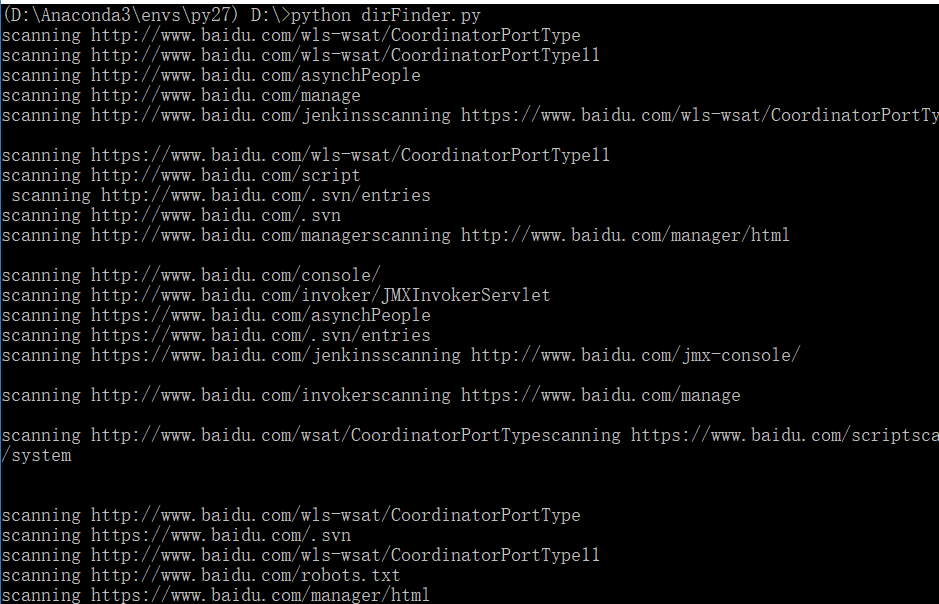
总结一点,功能还是挺强大的,互相学习~~~
作 者:Angel_Kitty
出 处:https://www.cnblogs.com/ECJTUACM-873284962/
关于作者:阿里云ACE,目前主要研究方向是Web安全漏洞以及反序列化。如有问题或建议,请多多赐教!
版权声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。
特此声明:所有评论和私信都会在第一时间回复。也欢迎园子的大大们指正错误,共同进步。或者直接私信我
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是作者坚持原创和持续写作的最大动力!
欢迎大家关注我的微信公众号IT老实人(IThonest),如果您觉得文章对您有很大的帮助,您可以考虑赏博主一杯咖啡以资鼓励,您的肯定将是我最大的动力。thx.

我的公众号是IT老实人(IThonest),一个有故事的公众号,欢迎大家来这里讨论,共同进步,不断学习才能不断进步。扫下面的二维码或者收藏下面的二维码关注吧(长按下面的二维码图片、并选择识别图中的二维码),个人QQ和微信的二维码也已给出,扫描下面👇的二维码一起来讨论吧!!!

欢迎大家关注我的Github,一些文章的备份和平常做的一些项目会存放在这里。
















【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· [AI/GPT/综述] AI Agent的设计模式综述
2017-03-15 HDU 5144 NPY and shot(物理运动学+三分查找)
2017-03-15 HDU 2438 Turn the corner(三分查找)