
Codeforces 591B Rebranding
The name of one small but proud corporation consists of n lowercase English letters. The Corporation has decided to try rebranding — an active marketing strategy, that includes a set of measures to change either the brand (both for the company and the goods it produces) or its components: the name, the logo, the slogan. They decided to start with the name.
For this purpose the corporation has consecutively hired m designers. Once a company hires the i-th designer, he immediately contributes to the creation of a new corporation name as follows: he takes the newest version of the name and replaces all the letters xi by yi, and all the letters yi by xi. This results in the new version. It is possible that some of these letters do no occur in the string. It may also happen that xi coincides with yi. The version of the name received after the work of the last designer becomes the new name of the corporation.
Manager Arkady has recently got a job in this company, but is already soaked in the spirit of teamwork and is very worried about the success of the rebranding. Naturally, he can't wait to find out what is the new name the Corporation will receive.
Satisfy Arkady's curiosity and tell him the final version of the name.
The first line of the input contains two integers n and m (1 ≤ n, m ≤ 200 000) — the length of the initial name and the number of designers hired, respectively.
The second line consists of n lowercase English letters and represents the original name of the corporation.
Next m lines contain the descriptions of the designers' actions: the i-th of them contains two space-separated lowercase English letters xi and yi.
Print the new name of the corporation.
6 1
police
p m
molice
11 6
abacabadaba
a b
b c
a d
e g
f a
b b
cdcbcdcfcdc
In the second sample the name of the corporation consecutively changes as follows:
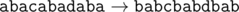
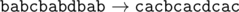
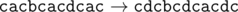
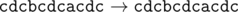
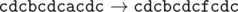
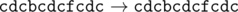
题目链接:http://codeforces.com/problemset/problem/591/B
这道题挺考思维的
详解:-1s1代表的本意abcdefg...0s1数组的下标和初始值0123456...1a-b1023456...2b-c1203456...3a-d3201456...4e-g3201654...5f-a5201634...6b-b5201634...7s1数组里面最终包含的值所对应的字符fcabgde...
表二:
| s2数组代表的本意 | a | b | c | d | e | f | g | ... |
| s2数组的下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | ... |
| s2数组里面存的值 | 2 | 3 | 1 | 5 | 6 | 0 | 4 | ... |
| s2数组里面最终包含的值所对应的字符 | c | d | b | f | g | a | e | ... |
定义两个int类型数组来保存26个英文字母所表示的标号,可以开辟30个空间,s1[30] , s2[30]; 第一次交换ch1='a'与ch2='b' ,就交换s1数组里s1[ch1-'a']与s1[ch2-'a']的值,之后的1-6做一样的操作;
肯定会有疑问,为什么要交换s1[ch1-'a']与s1[ch2-'a']的值?交换过后是代表第-1行所表示的字符转换为第7行所表示的字符吗?
其实不是,如果你认为交换过后就是代表“第-1行所表示的字符转换为第7行所表示的字符”是错误的。
每次交换你可以看做 例如:表三:
| -1 | s1代表的本意 | a | b | c | d | e | f | g | ... |
| 0 | s1数组的下标和初始值 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | ... |
| 1 | a-b | 1 | 0 | 2 | 3 | 4 | 5 | 6 | ... |
| 数组的值+'a'转换为相应的字符 | b | a | c | d | e | f | g | ... | |
| 其实交换过后代表 | 字符'a'是由字符'b'转化而来 | 字符'b'是由字符'a'转化而来 | |||||||
| 2 | b-c | 1 | 2 | 0 | 3 | 4 | 5 | 6 | ... |
| 数组的值+'a'转换为相应的字符 | b | c | a | d | e | f | g | ... | |
| 字符'a'是由字符'b'转化而来 | 字符'b'是由字符'c'转化而来 | 字符'c'是由字符'a'转化而来 |
你可以想想是不是这样的;这只是举了两个例子;
也就是说表四:
| -1 | s1代表的本意 | a | b | c | d | e | f | g | ...... |
| s1数组的下标和初始值 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | ...... | |
| 7 | s1数组里面最终包含的值所对应的字符 | f | c | a | b | g | d | e | ...... |
| s1数组里面最终的值 | 5 | 2 | 0 | 1 | 6 | 3 | 4 | ||
| 结论 | 字符'a'是由字符'f'转化而来 | 字符'b'是由字符'c'转化而来 | 字符'c'是由字符'a'转化而来 | 字符'd'是由字符'b'转化而来 | 字符'e'是由字符'g'转化而来 | 字符'f'是由字符'd'转化而来 | 字符'g'是由字符'e'转化而来 | ...... | |
| 推论 | 字符'f'最终转化为'a' | 字符'c'最终转化为'b' | 字符'a'最终转化为'c' | 字符'd'最终转化为'b' | 字符'g'最终转化为'e' | 字符'd'最终转化为'f' | 字符'e'最终转化为'g' | ...... |
我们现在已经知道字符最终由哪个字符转化而来,也就是说我们得出的是,知道最终的字符,我们能找到它是由哪个最初的字符转换而来的,之后的怎么办呢? 我们需要转化为 题意给出了最初字符,能找到他最终要转换为哪个字符 这个就要好好思考一下怎么转换了!
其实定义两个数组,可以理解为,表四: 做这样的处理: 之后就变为表二:
1 2 | for(i=0; i<26; i++) s2[s1[i]]=i; |
为什么要这样处理呢?这样处理过后就会简化很多;再加上下面这个步骤,这道题就算是解决了;
1 for(i=0; i<n; i++) 2 { 3 str[i]=s2[str[i]-'a']+'a'; 4 }
附上AC代码:

1 #include<bits/stdc++.h> 2 using namespace std; 3 #define N 2000010 4 int main() 5 { 6 char str[N],ch1,ch2; 7 int s1[30],s2[30]; 8 int n,m,i,x,y,t; 9 while(scanf("%d%d",&n,&m)!=EOF) 10 { 11 scanf("%s",str); 12 for(i=0;i<26;i++) 13 s1[i]=i; 14 for(i=0;i<m;i++) 15 { 16 scanf(" %c %c", &ch1, &ch2); 17 x=ch1-'a'; 18 y=ch2-'a'; 19 t=s1[x]; 20 s1[x]=s1[y]; 21 s1[y]=t; 22 } 23 for(i=0;i<26;i++) 24 s2[s1[i]]=i; 25 for(i=0;i<n;i++) 26 { 27 str[i]=s2[str[i]-'a']+'a'; 28 } 29 printf("%s\n",str); 30 } 31 return 0; 32 }
作 者:Angel_Kitty
出 处:https://www.cnblogs.com/ECJTUACM-873284962/
关于作者:阿里云ACE,目前主要研究方向是Web安全漏洞以及反序列化。如有问题或建议,请多多赐教!
版权声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。
特此声明:所有评论和私信都会在第一时间回复。也欢迎园子的大大们指正错误,共同进步。或者直接私信我
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是作者坚持原创和持续写作的最大动力!
欢迎大家关注我的微信公众号IT老实人(IThonest),如果您觉得文章对您有很大的帮助,您可以考虑赏博主一杯咖啡以资鼓励,您的肯定将是我最大的动力。thx.

我的公众号是IT老实人(IThonest),一个有故事的公众号,欢迎大家来这里讨论,共同进步,不断学习才能不断进步。扫下面的二维码或者收藏下面的二维码关注吧(长按下面的二维码图片、并选择识别图中的二维码),个人QQ和微信的二维码也已给出,扫描下面👇的二维码一起来讨论吧!!!

欢迎大家关注我的Github,一些文章的备份和平常做的一些项目会存放在这里。
















【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· [AI/GPT/综述] AI Agent的设计模式综述