
YOLOV4所用到的一些tricks
原文链接:http://arxiv.org/abs/2004.10934
整体框架

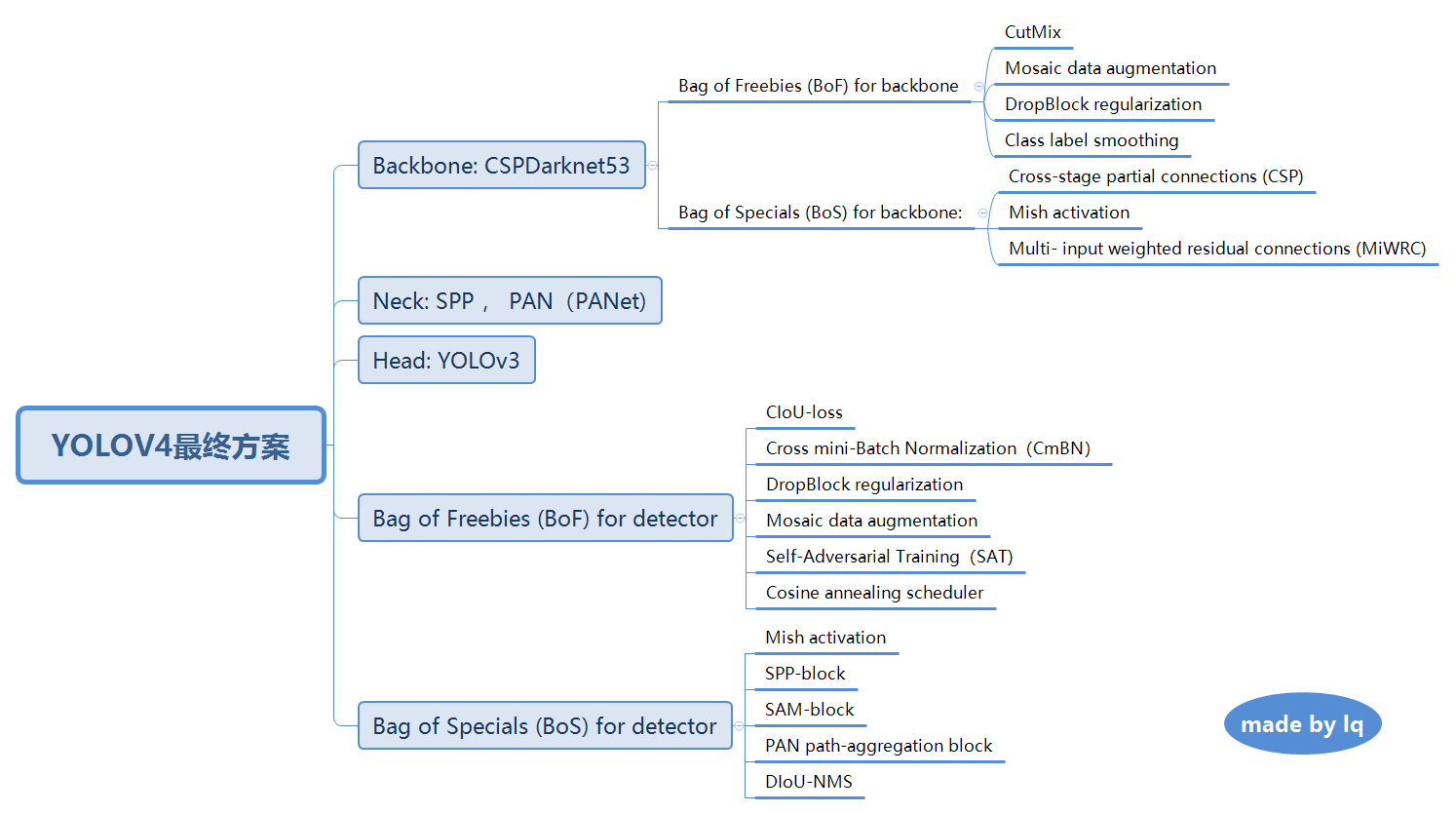
Bag of Freebies(BoF) & Bag of Specials (BoS)
Bag of Freebies(BoF) 指那些能够提高精度而不增加推断时间的技术。比如数据增广的方法图像几何变换、CutOut、grid mask等,网络正则化的方法DropOut、DropBlock等,类别不平衡的处理方法、难例挖掘方法、损失函数的设计等。
Bag of Specials (BoS)是指那些增加稍许推断代价,但可以提高模型精度的方法,比如增大模型感受野的SPP、ASPP、RFB等,引入注意力机制Squeeze-and-Excitation (SE) 、Spatial Attention Module (SAM)等 ,特征集成方法SFAM , ASFF , BiFPN等,改进的激活函数Swish、Mish等,或者是后处理方法如soft NMS、DIoU NMS等。
Backbone: CSPDarknet53
source: CSPNet: A new backbone that can enhance learning capability of cnn论文;
CSPNet提出主要是为了解决三个问题: a.增强CNN的学习能力,能够在轻量化的同时保持准确性。
b.降低计算瓶颈。
c.降低内存成本。
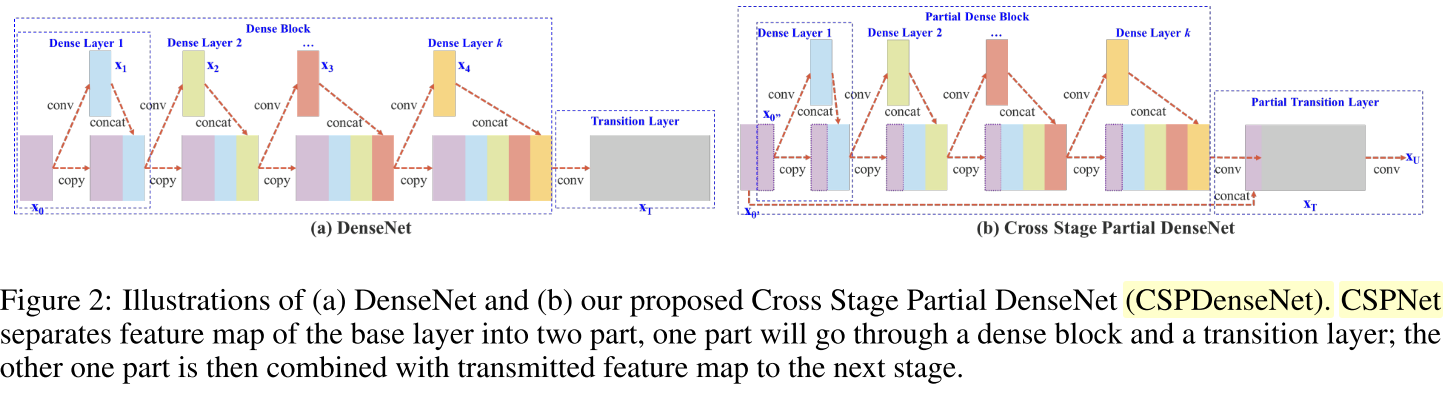 CSP 在 DenseNet的使用
CSP 在 DenseNet的使用
Neck: SPP(Spatial pyramid pooling) 、PANet(Path Aggregation Network)
source:
SPP:Spatial pyramid pooling in deep convolutional networks for visual recognition。
PANet: Path Aggregation Network for Instance Segmentation .(实力分割中提出)

PANet 网络框架
关键:更好的利用特征融合 1.为了提高低层信息的利用率,加快低层信息的传播效率,提出了Bottom-up Path Augmentation; 2.通常FPN在多层进行选anchors时,根据anchors的大小,将其分配到对应的层上进行分层选取。这样做很高效,但同时也不能充分利用信息了,提出了Adaptive Feature Pooling。 3.为了提高mask的生成质量,将卷积-上采样和全连接层进行融合,提出了Fully-connected Fusion。
CutMix and Mosaic data augmentation, DropBlock regularization, Class label smoothing
source:
CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features (开源)
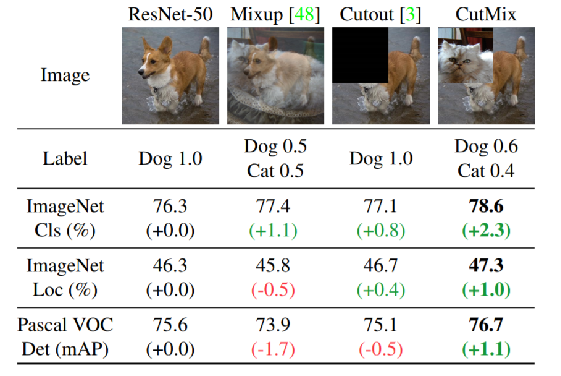
Mixup:将随机的两张样本按比例混合,分类的结果按比例分配(个人看法:如果是使用一个随机数来控制权重,可能AP会增);
Cutout:随机的将样本中的部分区域cut掉,并且填充0像素值,分类的结果不变;
CutMix:就是将一部分区域cut掉但不填充0像素而是随机填充训练集中的其他数据的区域像素值,分类结果按一定的比例分配
Mosaic data augmentation:可以见论文给的示例图,提出了一种混合四幅训练图像的数据增强方法。
DropBlock regularization(来自知乎):
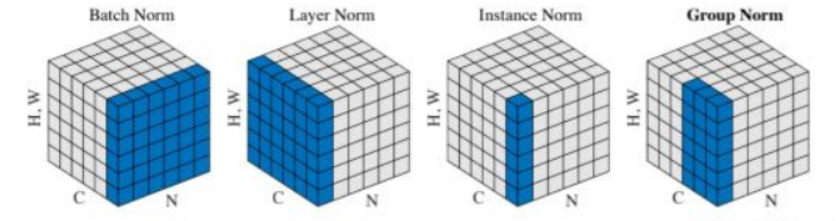

各种Dropout 组合
Mish activation, Cross-stage partial connections (CSP), Multi- input weighted residual connections (MiWRC)
source:
Mish: A Self Regularized Non-Monotonic Neural Activation Function论文(开源)
激活函数公式:Mish=x * tanh(ln(1+e^x))
描述:x轴无边界(即正值可以达到任何高度)避免了由于封顶而导致的饱和。理论上对负值的轻微允许允许更好的梯度流,而不是像ReLU中那样的硬零边界。最后,平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化。

Mish 激活函数的曲线
CSP、MiWRC 都是一种让网络更好训练的跳接方式。
CIoU-loss, CmBN
发展历程: IoU loss -> Giou loss -> Diou loss & Cious loss
主要依据:geometric factors:overlap area, central point distance and aspect ratio
IOU loss :依据交并比的loss, 不做介绍了。
Giou loss:

GIOU核心算法
Diou loss
切入点:
第一:直接最小化预测框与目标框之间的归一化距离是否可行,以达到更快的收敛速度。
第二:如何使回归在与目标框有重叠甚至包含时更准确、更快。

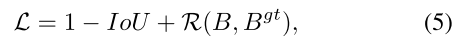
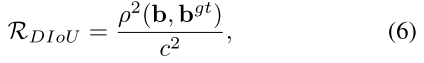
R(B, Bgt)为预测框与真实框的惩罚项。
b, bgt分别为框的中心,P^2即两个点的欧式距离,c^2为包含两个框的最小框的对角线长度。
Ciou loss

在Diou loss 的基础上考虑了—— the consistency of aspect ratio 即公式中的 ν参数,α 为权衡参数。
CmBN
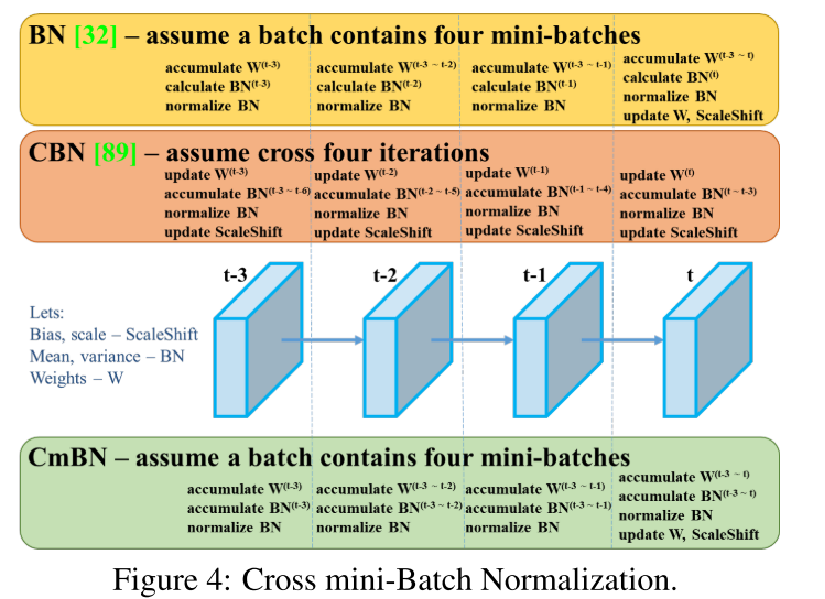
CMBN示意图
Self-Adversarial Training (SAT)
SAT 为一种新型数据增强方式。在第一阶段,神经网络改变原始图像而不是网络权值。通过这种方式,神经网络对其自身进行一种对抗式的攻击,改变原始图像,制造图像上没有目标的假象。在第二阶段,训练神经网络对修改后的图像进行正常的目标检测。
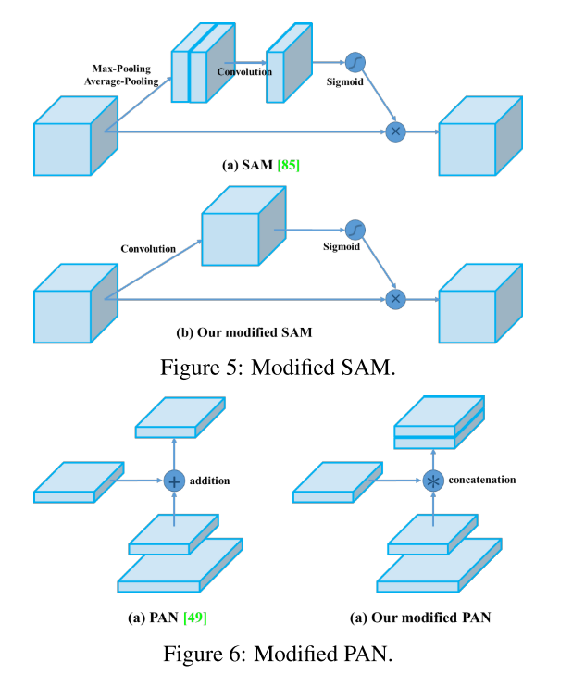
注意力机制——SAM、PAN
所做改进: 将SAM从空间注意力机制修改为点上的注意力机制,并将PAN的相加模块改为级联。
读完结论
一系列堆料,结果建立在好的backbone 上面,好的backbone 再加入一系列训练提高方式, 必然长点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号