201621123008 《Java程序设计》第八周学习总结
1. 本周学习总结
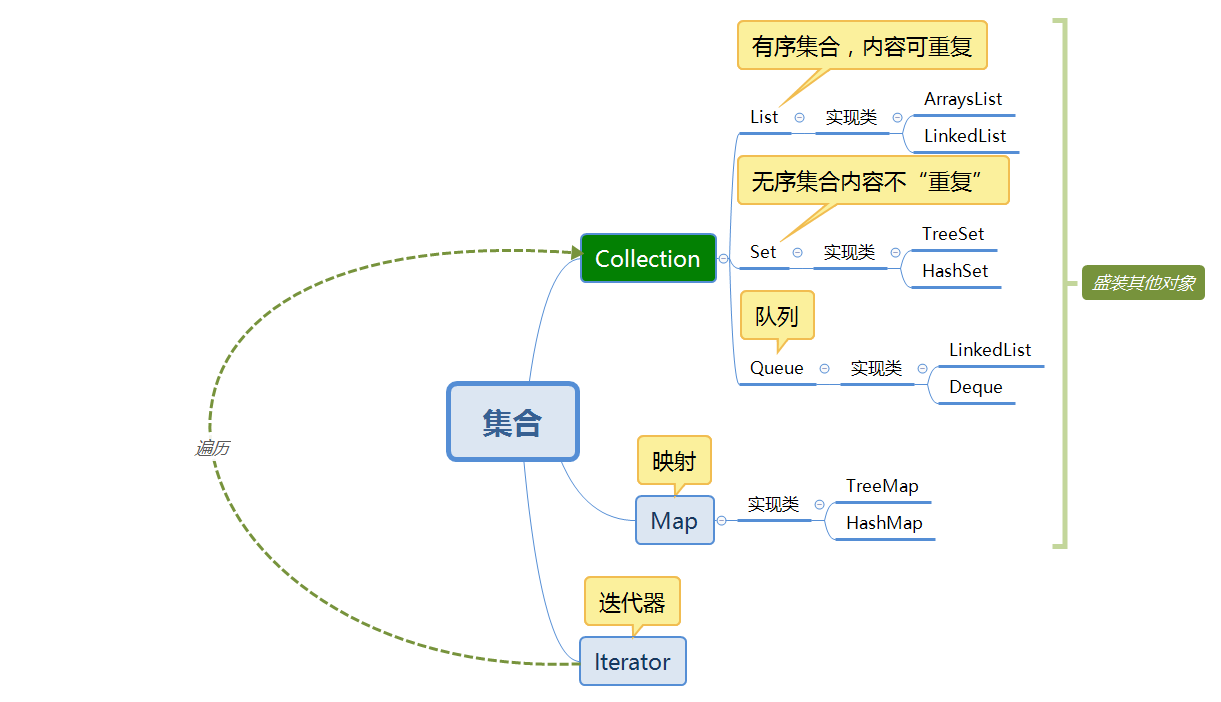
2. 书面作业
1. ArrayList代码分析
1.1 解释ArrayList的contains源代码
源代码:
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
分析:该方法通过返回被传入对象的下标值是否有效,来判断该对象是否被包含。
1.2 解释E remove(int index)源代码
源代码:
public E remove(int index) {
rangeCheck(index);
modCount++; //记录修改次数,避免对列表进行迭代时产生异常。
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
补充:
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
分析:该方法通过接收对象的下标,达到删除该对象的目的。首先通过rangeCheck(index);判断是否越界,若越界抛出IndexOutOfBoundsException异常;调用System的一个本地方法arraycopy将从index+1之后的元素复制到从index开始的位置。
1.3 结合1.1与1.2,回答ArrayList存储数据时需要考虑元素的具体类型吗?
分析:由以上分析可知ArrayList内部采用Object类型的数组来存储数据,所有类都继承自Object由多态的知识可知自然是不用考虑元素的类型的,查看ArrayList的源代码时也可以发现ArrayList支持泛型操作。
1.4 分析add源代码,回答当内部数组容量不够时,怎么办?
源代码:
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
分析:当我们调用add方法时其内部再通过ensureExplicit方法来判断是否需要扩容,若需要则调用grow进行扩容。
1.5 分析private void rangeCheck(int index)源代码,为什么该方法应该声明为private而不声明为public?
分析: rangeCheck方法只需为ArrayList类进行服务,当我们使用ArrayList时我们不需要把重点放到是否出现越界这种逻辑问题上,这中问题的检查应该在内部实现的,而我们不需要关心其具体的实现细节。
2. HashSet原理
2.1 将元素加入HashSet(散列集)中,其存储位置如何确定?需要调用那些方法?
分析:通过调用hashcode获得哈希码,依照哈希码将对象放入对应的哈希桶中,若哈希桶中没有对象则直接放入,否则调用该对象的equals方法进行比较,相同不收集,不相同收集。
2.2 将元素加入HashSet中的时间复杂度是多少?是O(n)吗?(n为HashSet中已有元素个数)
分析:时间复杂度为O(1),由上题分析可知将元素加入HashSet需调用HashCode计算哈希码来确定位置,而不是通过遍历。
2.3 选做:尝试分析HashSet源代码后,重新解释2.1
源代码:
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
分析:由此可知 HashSet内部是基于HashMap来实现的,接下来查看HashMap
源代码:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
分析: 看的不是很懂,不过好像是如果对象的映射已经存在则用新的值代替旧的值并返回旧的值,如果不存在则建立新的映射?
3. ArrayListIntegerStack
题集jmu-Java-05-集合之ArrayListIntegerStack
3.1 比较自己写的ArrayListIntegerStack与自己在题集jmu-Java-04-面向对象2-进阶-多态、接口与内部类中的题目自定义接口ArrayIntegerStack,有什么不同?(不要出现大段代码)
分析:不同之处在与内部的实现不同,之前用的是数组。这次用的是ArrayList,这也导致了内部一些具体的实现细节不同。用数组操作时需要一个top指针来判断栈顶的位置,从而进行是否为空,入栈出栈的操作;用ArrayList时要简化很多,不需要top指针,利用其自带的方法就可实现出栈入栈等操作。
3.2 结合该题简单描述接口的好处,需以3.1为例详细说明,不可泛泛而谈。
分析:在这两个例子中,将一些共有的行为抽象出来了形成IntegerStack接口(协议),两个实现类都具有该接口的功能(遵守协议),即,出栈,入栈,判断是否为空等,但是一个用数组实现一个用ArrayList实现,实现的细节不同。这就是接口的好处。
4. Stack and Queue
4.1 编写函数判断一个给定字符串是否是回文,一定要使用栈(请利用Java集合中已有的类),但不能使用java的Stack类(具体原因自己搜索)与数组。请粘贴你的代码,类名为Main你的学号。
代码:
package test;
import java.util.Deque;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.Scanner;
/**
* 回文检测
* @author 周文华 201621123008
*
*/
public class Main {
public static String[] strSplit(String str) {
String[] strList = str.split("");
return strList;
}
public static void main(String[] args) {
Deque dq = new LinkedList<String>();
Scanner in = new Scanner(System.in);
String[] strs = strSplit(in.nextLine());
String str1 = "";
String str2 = "";
for (int i = 0; i < strs.length; i++) {
dq.add(strs[i]);
}
Iterator descendingiterator = dq.descendingIterator();
Iterator iterator = dq.iterator();
while (iterator.hasNext()) {
str1 += iterator.next();
}
while (descendingiterator.hasNext()) {
str2 += descendingiterator.next();
}
//System.out.println(str1);
//System.out.println(str2);
System.out.println(str1.equals(str2));
}
}
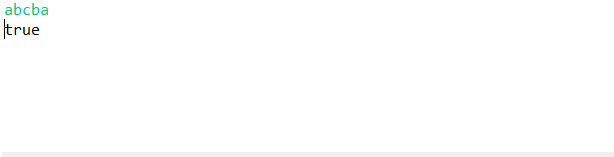
运行结果:

4.2 题集jmu-Java-05-集合之银行业务队列简单模拟(只粘贴关键代码)。请务必使用Queue接口,并说明你使用了Queue接口的哪一个实现类?
代码:
import java.util.Deque;
import java.util.LinkedList;
import java.util.Queue;
import java.util.Scanner;
public class Main7 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
Queue<Integer> arrAQueue = new LinkedList<>();
Queue<Integer> arrBQueue = new LinkedList<>();
String[] strs = sc.nextLine().split(" ");
if (Integer.parseInt(strs[0]) <= 1000) {
for (int i = 1; i < strs.length; i++) {
int temp1 = Integer.parseInt(strs[i]);
if (temp1 % 2 == 0) {
arrBQueue.add(temp1);
} else {
arrAQueue.add(temp1);
}
}
}
int i=0;
if(!arrAQueue.isEmpty())
System.out.print(arrAQueue.poll());
else {
System.out.print(arrBQueue.poll());
}
while(!arrAQueue.isEmpty()||!arrBQueue.isEmpty()) {
i++;
if(i%2==0) {
if(!arrAQueue.isEmpty())
System.out.print(" "+arrAQueue.poll());
}else {
if(!arrAQueue.isEmpty())
System.out.print(" "+arrAQueue.poll());
if(!arrBQueue.isEmpty())
System.out.print(" "+arrBQueue.poll());
}
}
}
}
使用了LinkedList,便于出栈操作。
5. 统计文字中的单词数量并按单词的字母顺序排序后输出
题集jmu-Java-05-集合之5-2统计文字中的单词数量并按单词的字母顺序排序后输出 (作业中不要出现大段代码)
5.1 实验总结
总结:
-
使用TreeMap按单词的字母顺序排序。key为单词,value为单词数量。
-
一行一行读入,使用split("\s+")分割多空格。
-
判断是否包含,不包含则加入,value置为1,否则不加入value+1。
-
使用迭代器输出。
6. 选做:统计文字中的单词数量并按出现次数排序
题集jmu-Java-05-集合之5-3统计文字中的单词数量并按出现次数排序(不要出现大段代码)
6.1 伪代码
创建**TreeMap**对象
进入循环按行读入字符串,以!!!!!跳出循环。
对每行字符串使用split("\\s+")分割。
判断单词是否存在,不存在则加入,value置为1,存在则不加入,value+1;
输出该对象的长度。
创建List对象:List<Entry<String,Integer>> list=new ArrayList<Map.Entry<String, Integer>>(map.entrySet());
使用Collection.sort对List对象进行排序,按照value进行升序。
使用Entry<String,Integer>entry=list.get(i);输出。
6.2 实验总结
总结: 新学的知识点
- Map.Entry<K,V>接口: Map的内部接口,表示一个Map实体,即key-value键值对。内含有getKey(), getValue方法。
3.码云及PTA
题目集:jmu-Java-05-集合
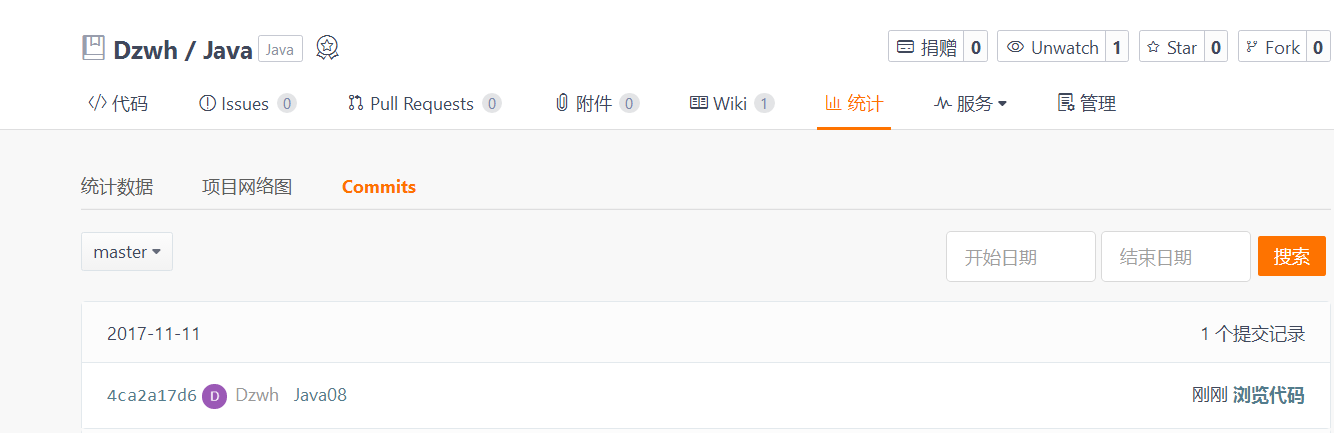
3.1. 码云代码提交记录
在码云的项目中,依次选择“统计-Commits历史-设置时间段”, 然后搜索并截图
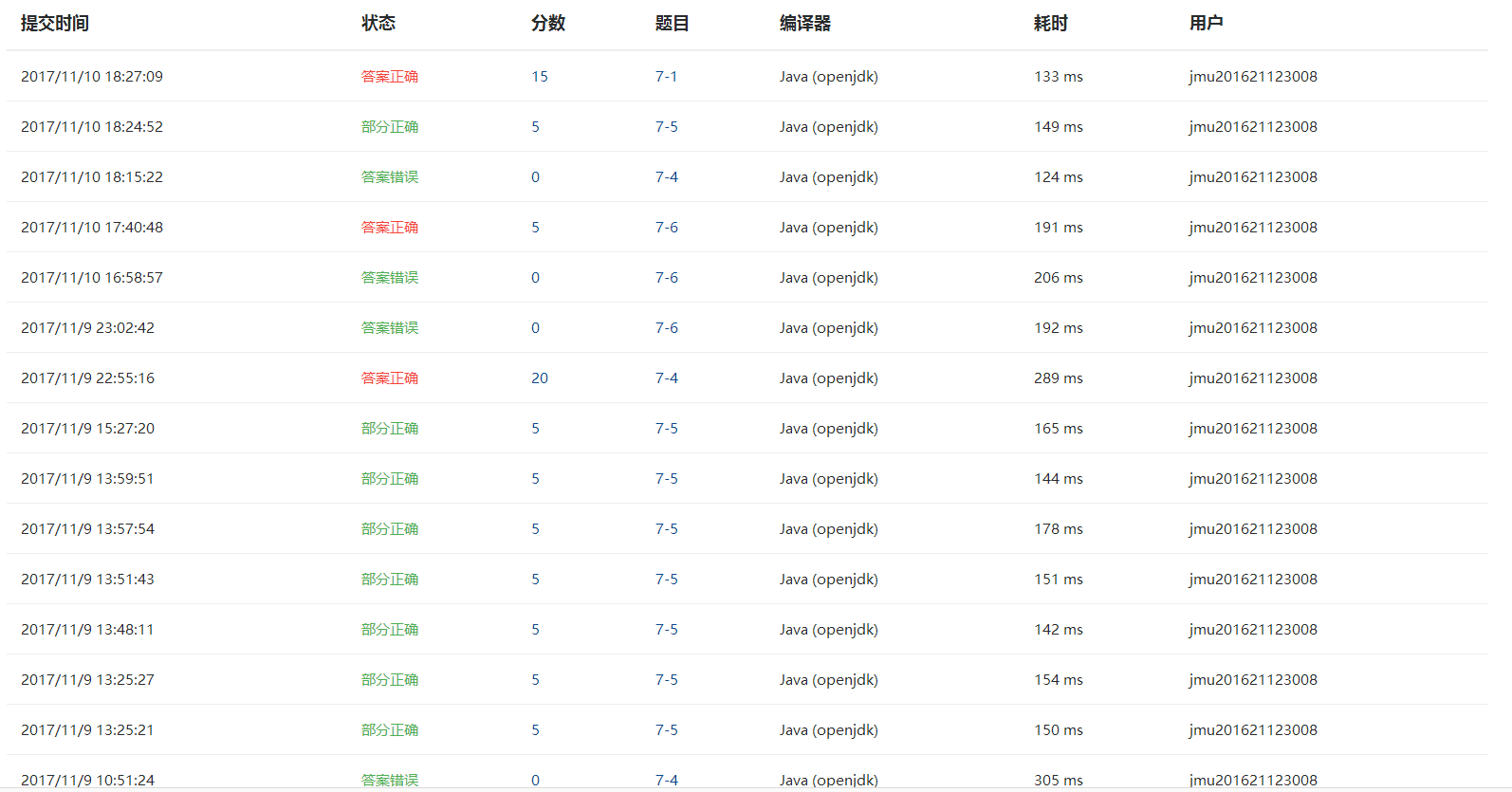
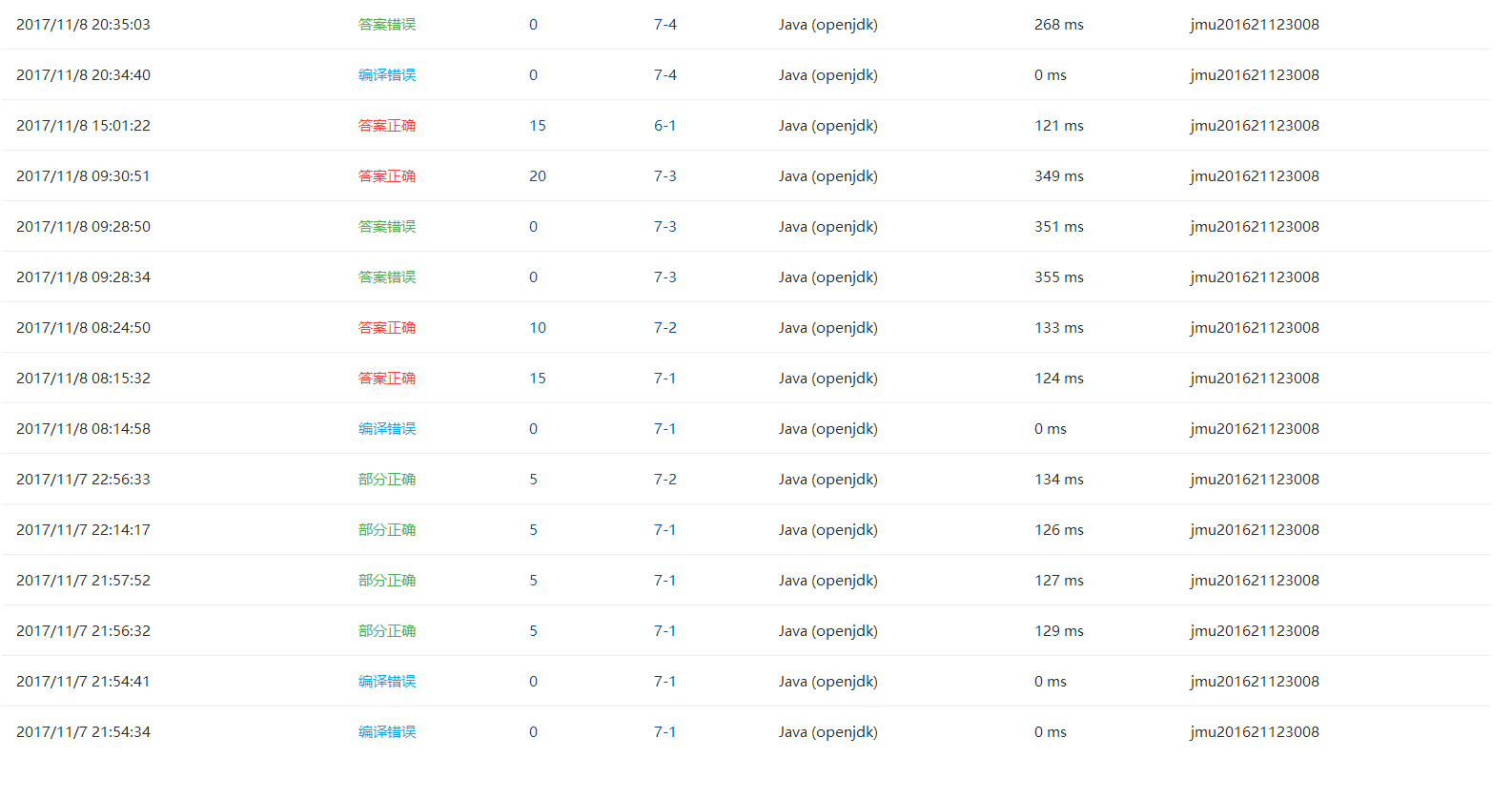
3.2 截图PTA题集完成情况图

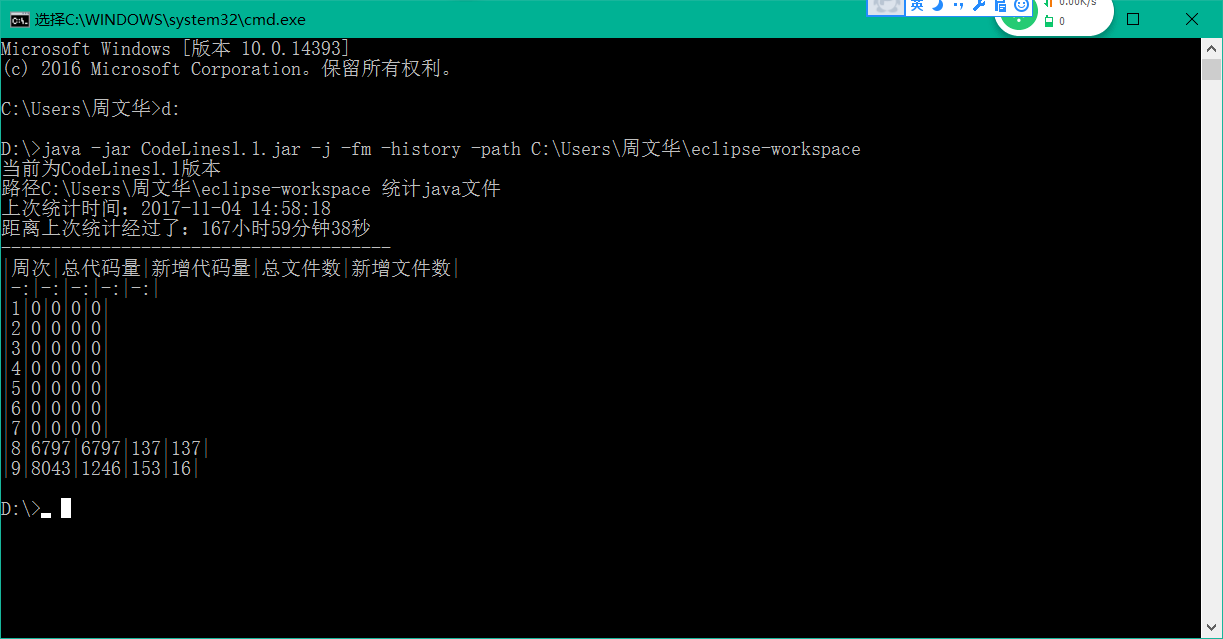
3.3 统计本周完成的代码量
| 周次 | 总代码量 | 新增文件代码量 | 总文件数 | 新增文件数 |
|---|---|---|---|---|
| 1 | 665 | 20 | 20 | 20 |
| 2 | 1705 | 23 | 23 | 23 |
| 3 | 1834 | 30 | 30 | 30 |
| 4 | 1073 | 1073 | 17 | 17 |
| 5 | 1073 | 1073 | 17 | 17 |
| 6 | 2207 | 1134 | 44 | 27 |
| 7 | 3292 | 1085 | 59 | 15 |
| 8 | 3505 | 213 | 62 | 3 |
| 9 | 8043 | 1246 | 153 | 16 |
统计的路径换了一下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号