Mysql boy
2022.08.04 七夕节(TAT)
P7:use sql_store;//使用sql_store 库
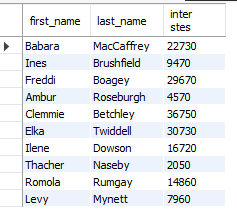
select * from customers //在customer这个表中选择全部的内容
where customer_id = 1// 查找customer_id = 1的人
order by first_name; // 然后将查找出来的数据 按照first_name 进行排序(首字母A的排在前面,首字母Z的排在后面)
P8:可以用as来重命名column的名字,例如说
select points,points*10 as discount_factor
from customers
还可以通过引号,(单引号,双引号来加空格,如果没有引号,必须得用下划线隔开单词)
如上图。
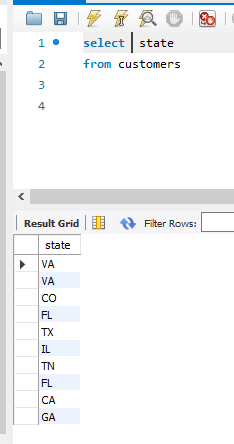
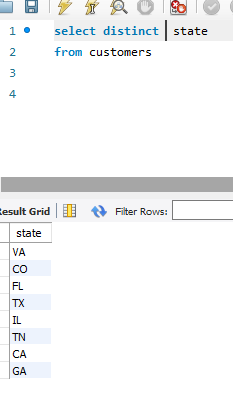
使用distinct来区别是不是唯一的数据,比如说我之前有2个顾客,都来自Virginia 州(VA),使用
select distinct state 将重复的州的名称去掉:
之前:
之后:
作业:
P9:
在where语句中,!= 和<>都可以表示不相等!!!
作业:
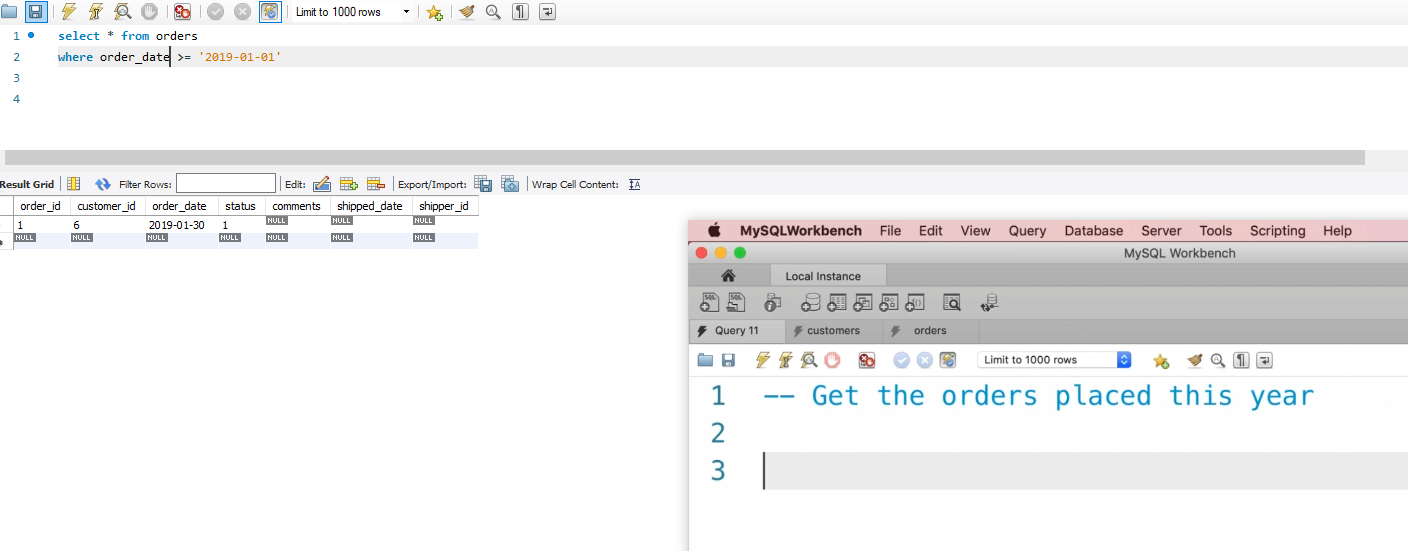
P10:查询条件,and or not 与,或 ,异或
异或是指:两个值不通异或为1,想相同异或为0
and 操作符是比or操作符优先的,比如说:
birth_data > '1990-01-01' or points > 1000 and state = 'VA'
指的是:出生日期大于1990-01-01的人 或者 (分数大于1000且 住在VA的人)
not就是非操作:直接否定一个句子,
作业:
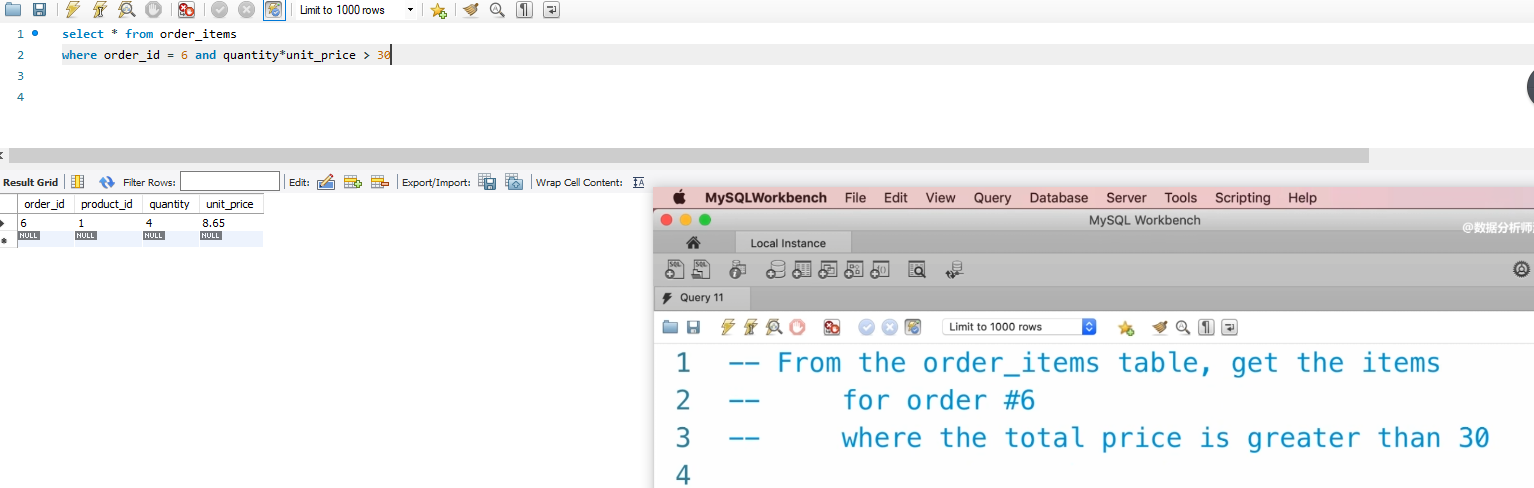
P11:
语句select * from customers
where state = “VA” or state = “GA” or state = “FL” 就等于 where state in (“GA”,“FL”,“GA”)
等于说 in 就是 确定一个范围,在这个范围内in就可以,查找出这个范围内所有的有效值
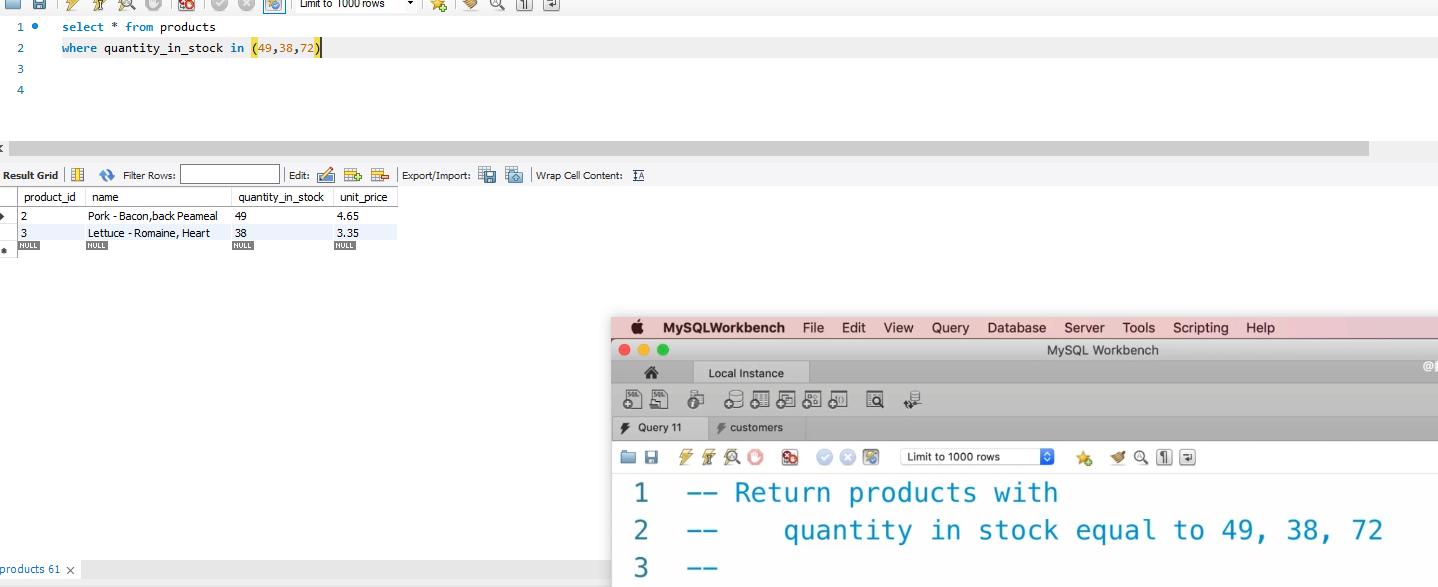
P11:
between 关键字 意思是 在两者之间,
select * from customers
where points>=1000 and points <=3000 的意思就等于 where points between 1000 and 3000
这个and很重要!!!
作业:
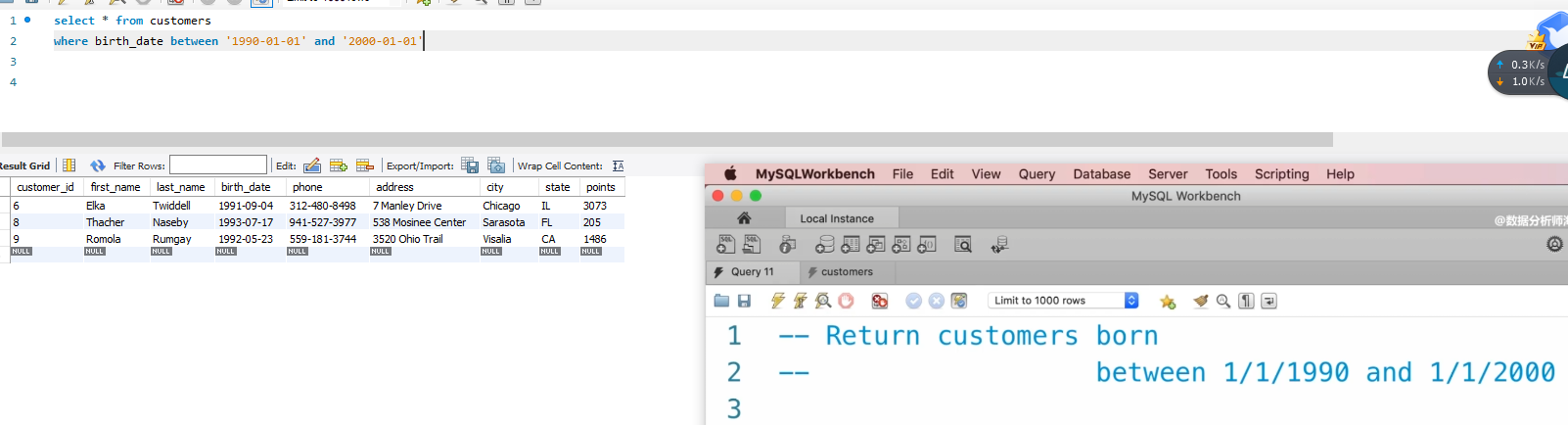
P12:
select * from customers
where last_name like 'b%' :意思是从customers这个表中,选出last_name 是以b开头的人的选项!而且是任意长度的字符串
%的意思是,可以有任何长度的字符串在 指定的character前面或者后面,比如说:%b%就是在字符串当中含有b字母的就可以了,
b%的意思是,已b字母打头;%b是以b字母结尾
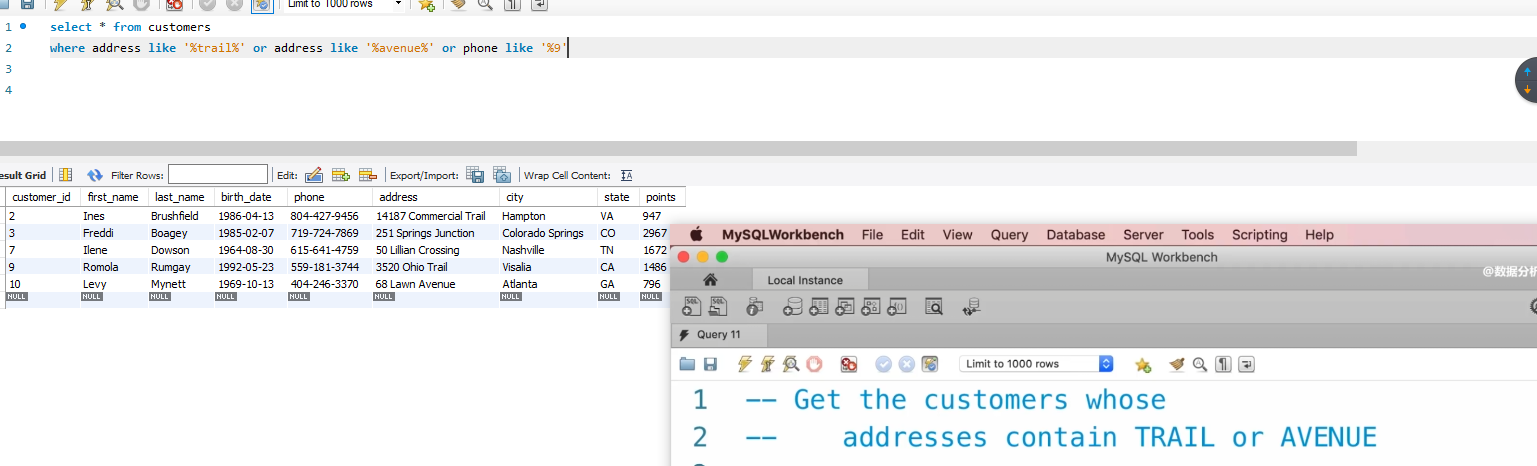
P13:REGEXP:regular expression 正则表达式 ---> REGEXP
上述两个式子表达的是样的:
select * from customers
where last_name like '%field%' == where last_name regexp 'field' regexp表达的是这个字符是否存在在整个字符串里面!!!
在regexp中 ‘^ field’表示的是以 field打头的字符串,‘field$’表示的是以field结尾的字符串!(有点记不住TAT)
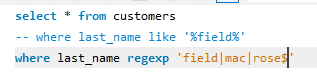
还可以这么写:where last_name regexp 'field | mac | rose' 表示这个字符串中可以含有 field 或者 可以含有 mac 或者可以含有 rose!
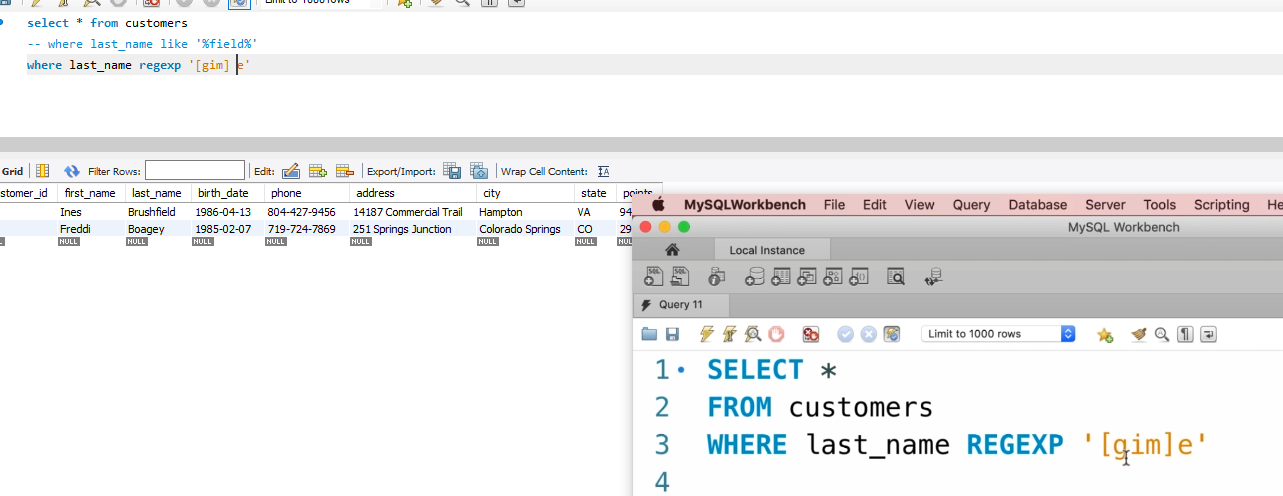
可以用方括号,来进行字母的组合,[gim]e的说明是:可以有ge,ie,me的组合字母出现在需要找的字符串当中!!!

P14:如果想找到那个值是null的话,使用is null 语句就可以了
如果想找到哪个的电话号码是 null 的话,那么就可以表示成:where phone is null 就可以了
P15:排序可以使用order by
因为customers_id 是排在第一位的,所以table总是使用customer_id 来排序,
使用order_items 选择order_items == 2 的产品进行排序,最后按照总价降序排列(总价 = quantity * unit_price)
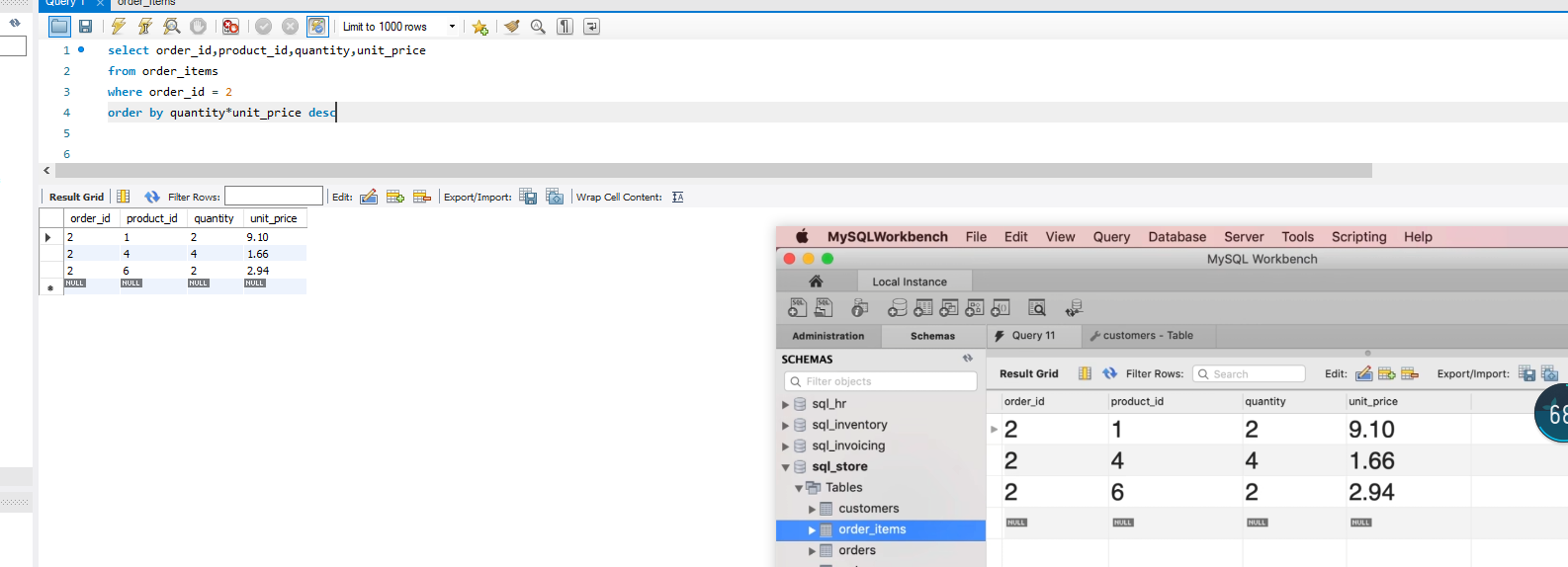
代码如上图所示!
P16:limit 函数的用法
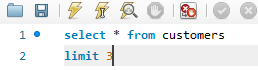
limit 3就表示如果表中有大于三的数据,那么只返回前三条!
如果使用了limit 6,3 就可以表示跳过前面的6条消息,显示6条消息之后的3条消息!!
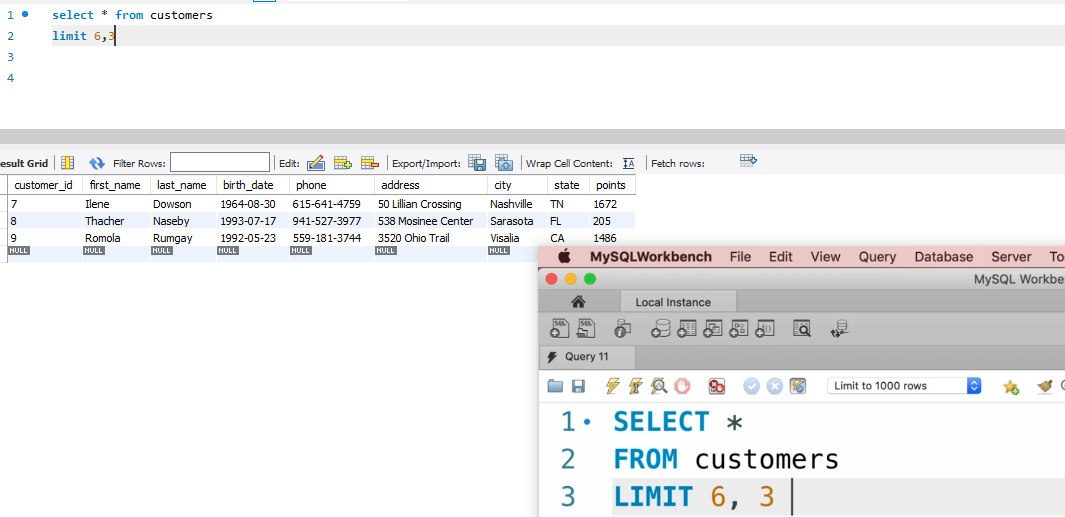
找到最忠实的三位客户,意思是points榜上前三名的客户
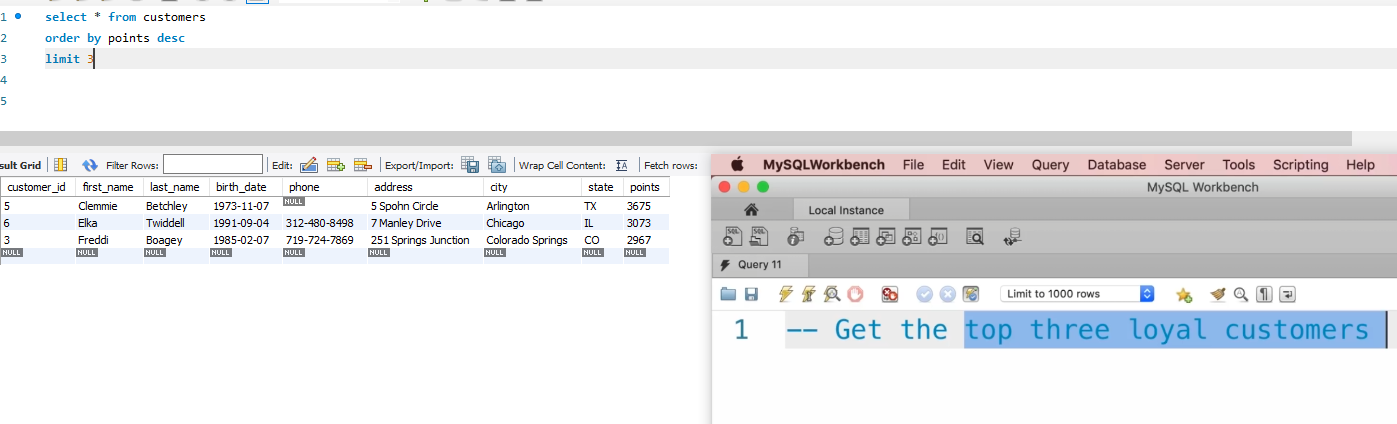
limit 语句必须最后加以使用才可以!!!
P17: inner joins 内连接
使用内连接时:一般是inner join 都要有条件限制,一般是加限定词汇 on
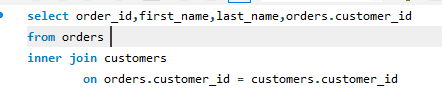
这个句子就是表示:合并orders 和 customers两个表 ,通过orders的customers id和customers 的customer id相同的条件来进行合并的!!
作业:
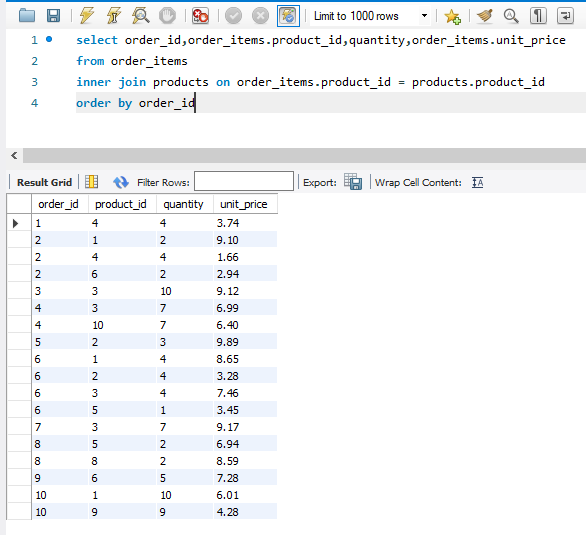
如果使用了别名: from order_items oi 则之后的情况下都要使用oi作为order_items的别名,不然会报错!!
P22:复合连接条件
条件和条件之间使用AND连接
join something on
and on
P23:隐式连接语法
不被推荐使用,因为如果忘记打where语句的话,将会造成数据冗余,10条记录的
P24:outer join(外连接)
使用left join 的时候,left join前面的表格例如 customers c必须要进行一个返回值的操作,即使这个值为null
right join 的时候,前面的表格例如 customers c如果有null的值,那就不能进行一个返回操作,之后的表格就显示没有
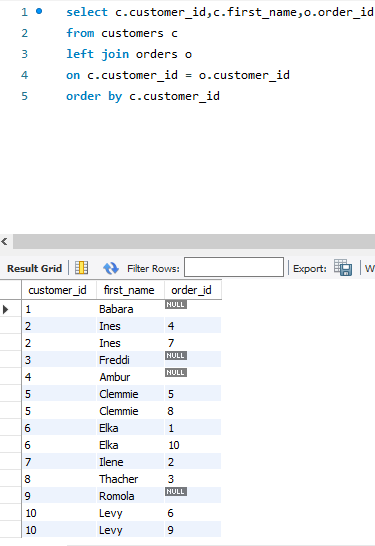
可以看出来,返回来的值有null,
使用right join的时候,有null值不返回。
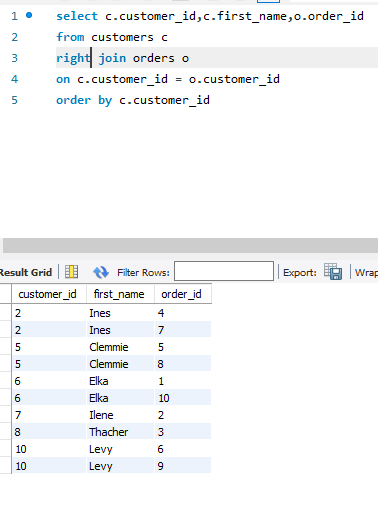
也不是right join = join
left join是返回左边的值,都符合条件的值,不管有没有null;right join是返回右边的值,不管有没有null
left outter join 和right outter join都一样,outter都是可有可无的东西
P25:
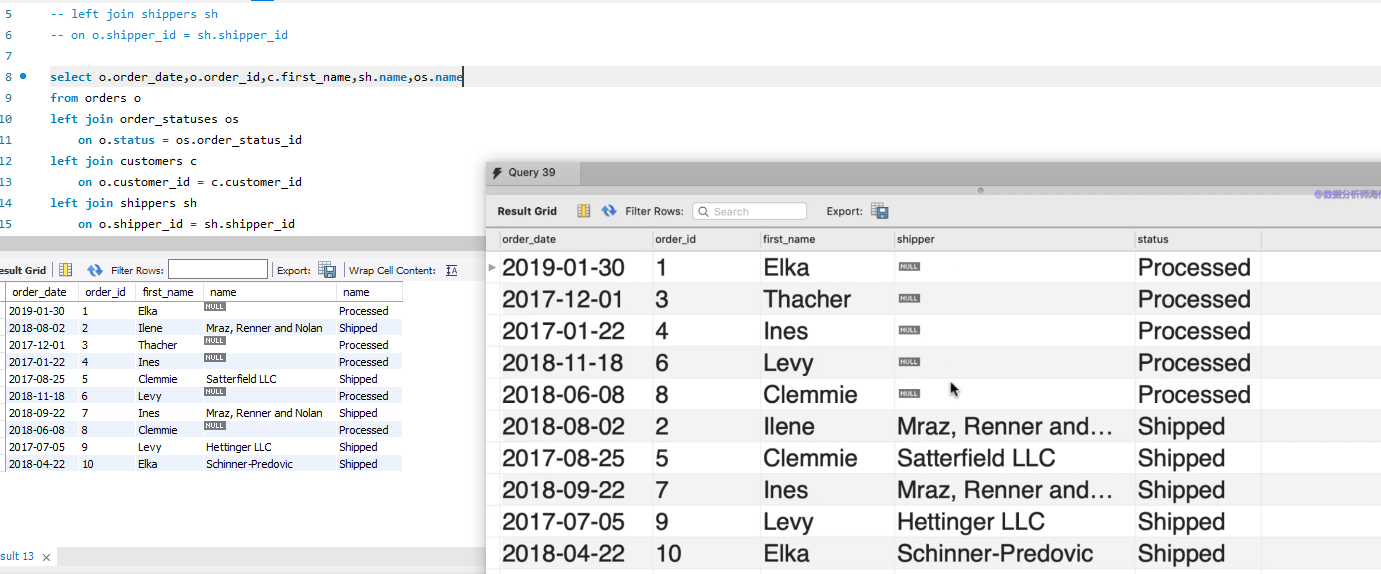
作业。
P26:自外连接。
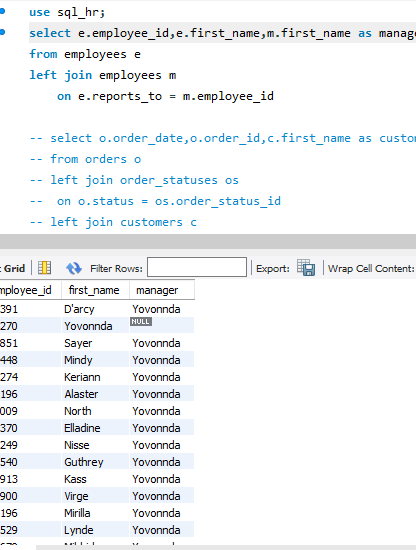
P27:using 语句
在两个表中都有相同的列的时候,比如说1表中有client_id , 2表中也有client_id 这时候可以使用using(client_id)使两者相等;当然,列不同的不允许使用,会造成歧义!!!
P28:Natual join 自然连接
最好不要使用Natual join ,这会造成不知道的错误!
P29:cross join 交叉连接
为了使用每一条数据进行连接的话,可以使用cross join,这就是每一条数据都会和其他表的每一条数据结合了
P30:Unions 联合
P31:列属性
P32:GROUP BY
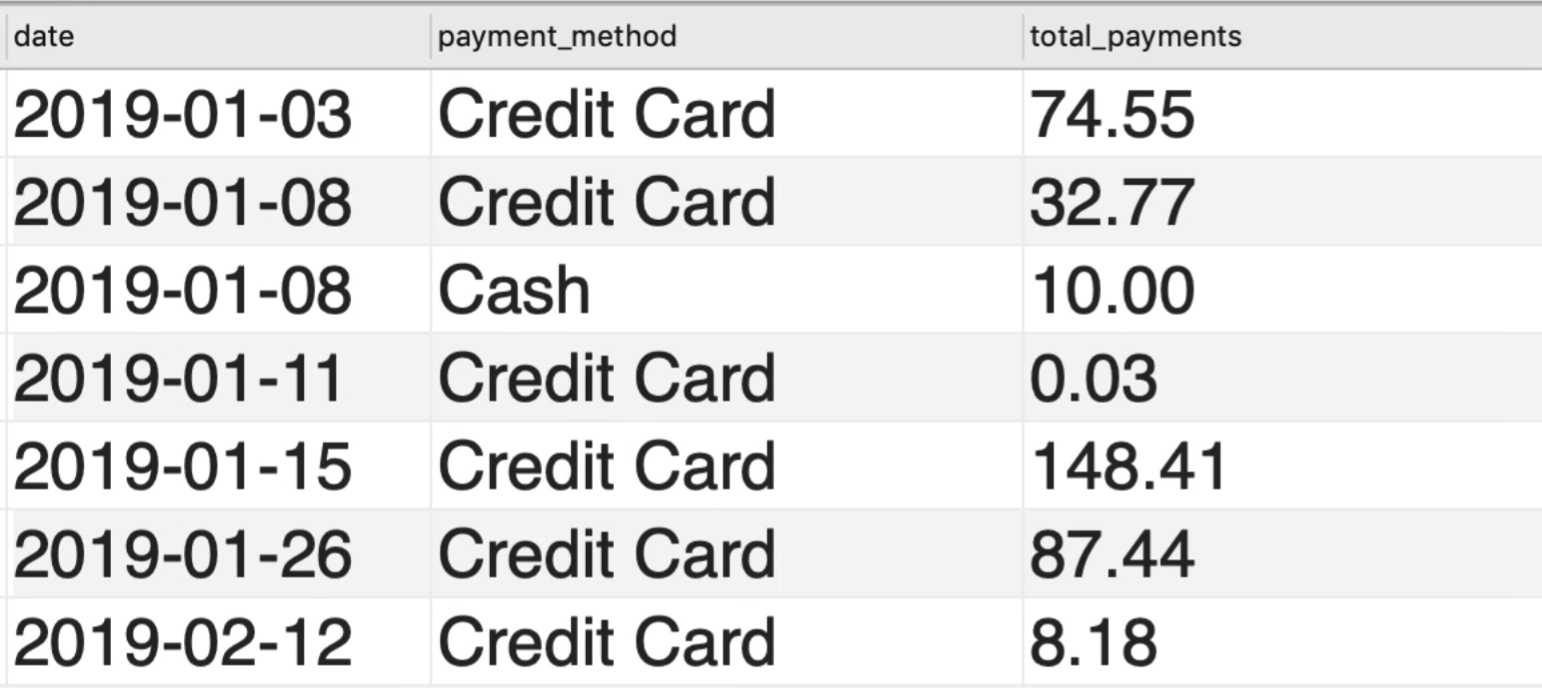
得使用group by函数来与之对应
通过group by date 和 payment_method来看
最后的代码是:

select date, payment_method.name sum(amount) as total_payments from payments p join payments_methods pm on p.payment_method = pm.payment_method_id group by date,payment_method order by date
group by 指在自己分内的领域里面处理函数
1 | group by customer_id |
就是在customer_id相同的情况下,来处理自身函数 ----> sum,max,min等等
P43:HAVING 子句
where的意思是对数据进行原始的筛选
having的意思是对数据进行处理之后的筛选
P44:ROLLUP
用rollup是将最后的结果累加起来的函数
1 2 3 4 5 6 | select pm.name, sum(p.amount) as totalfrom payments pjoin payment_methods pm on p.payment_method = pm.payment_method_idgroup by pm.name with rollup |
最后得到的结果是

有一个最后的累加起来的结果
P46:子查询
在查询里面写查询就是子查询
P47:子查询vs连接
一样的实现方法,只是可读性不同,不同场景用不同的方法
P48:all 关键词
all和max是通用的关键词,能用all的也可以用max来实现
P49:any关键词
>all()就是大于括号里面的最大值,大于任何一个all值,当然指最大值
>any()就是大于括号里面的最小值,大于其中的任意一个值,指的是any的值
选出支票数目大于2张的客人id
“select clients with at least 2 invoices”
1 2 3 4 | select client_id,count(*)from invoicesgroup by client_idhaving count(*)>=2 |
先选出client_id和计算每个client_id下有多少个支票(count(*)的意思是出现了多少个client_id的意思,出现一次就是一次支票)
再根据client_id进行分组
最后用having分支语句来判断最后的数目大于2的个数
P51:相关子查询
P52:exist函数
exist函数就是简化了查询的时间复杂度or空间复杂度
本来先要计算where后面的表达式的,通过exist可以直接得出相应的结论
P53:子句中的子查询
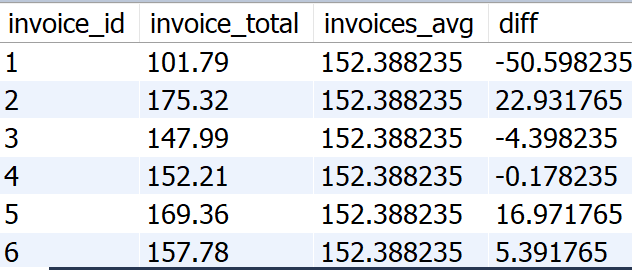
要达成这样的效果,除了每次遍历之后打印平均值外,
还需要进行diff的演化
1 2 3 4 5 6 | select invoice_id, invoice_total, (select avg(invoice_total)from invoices) as invoices_avg, invoice_total-(select invoices_avg) as difffrom invoices |
P55:数值函数
P60:数值函数
ifnull函数,如果是空值,就会附上对应的字符串的结果
1 2 3 4 | select customer_id, ifnull(shipper_id,'not assighed')from orders |
P61:if函数
很简单就是:if函数有三层方式
if(1,2,3)
1:表示要判断的东西,例如 year()>? year(now()) or 其他的
2:表示1成立该怎么办
3:表示2成立该怎么办
P62:case函数
1 2 3 4 | case when () then () when () then ()end |
当when的括号里面成立的时候,那么就执行then的括号里面的内容,
如果这个不是when里面的内容,那么就执行下一个when判断
P63:创建视图
P66:check 子句
with check options 防止在更新update or delete的时候误删数据
P69:创建一个存储过程
delimiter $$
意思就是将两个$符号视为结束符,用完了之后应该再将结束符改回去
delimiter ;才可以
创建view完之后一定得记得加分号
P72:参数 parameters
如果参数是字符 且知道字符的数量是多少的话,可以使用char(number)
如果不知道输入的字符是多少的话,就可以使用varchar(number),其中的number是最大数目的字符
P73:默认参数值
P74:参数验证
记得验证一下参数是否存在就可以了
学会抛出异常,然后设置一些参数返回即可
P79:触发器 trigger
触发器,其实可以也被看成是一个函数
1 2 3 4 5 6 7 8 9 | delimiter $$create trigger payment_after_insert//插入之后更新 after insert on payments for each rowbegin<br> update payments set payment_total = payment_total + new.amount where invoice_id = new.invoice_id;end$$//意思就是插入之后更新payments |
1 2 3 4 5 6 7 8 9 | delimiter $$create trigger payment_after_delete after delete on payments for each rowbegin update payments set payment_total = payment_total-old.amount where invoice_id = old.invoice_idend$$ |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 提示词工程——AI应用必不可少的技术
· 字符编码:从基础到乱码解决
· 地球OL攻略 —— 某应届生求职总结