Lee's NLP 语音验证(speech verification)
目的:输入语音,输出其他类的模型(class)
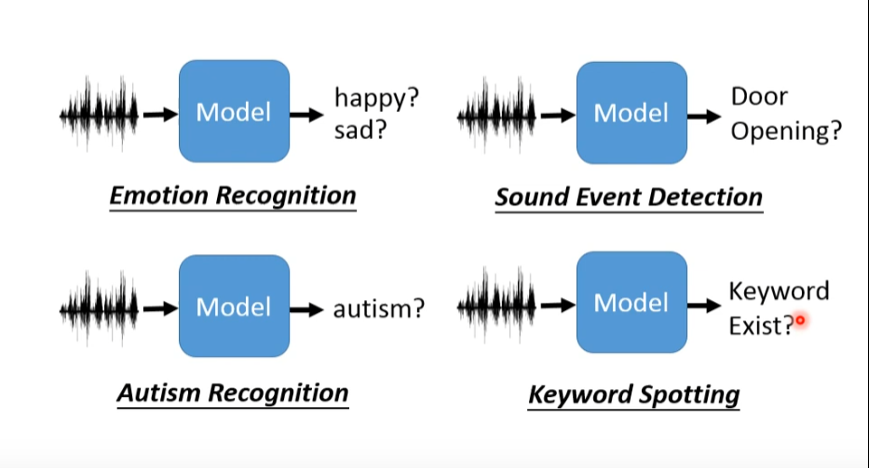
如下图:情感识别,声音物体探测,自闭症判断,关键词追踪等。。都属于speech verification
使用speaker verification(语者识别)
a mult classification problem 多分类问题!

model所作的事情就是 : 对比相似度
》threshold --> same
< threshold ---> different
判断是不是同一个语者所说的语句的时候,我们可以使用一个参数,叫做;equal error rate(EER)

threshold = 1.0 所有进来的声音都会被判定成不同语者(灵敏度太高)
threshold = 0.0 所有进来的声音都会被判断成同一语者(灵敏度太低)
真正的threshold应该介于0-1之间的一个数
还有一个point 就是speaker diarization 标记语者在什么时候,什么地点,什么语者在进行说话!(语者分段标记)
Framework
通常分为三个stage:stage1:development 目的是产生speaker embeding 这是一个生成 语者vector 的模型,第一步主要是建造模型!!!
stage2:enrollment(注册)目的是产生自己speaker的 speaker embeding vector
stage3:evaluation(验证)目的是产生刚刚说话的speaker的embeding vector ,然后于之前的vector进行比对 scalar!!!
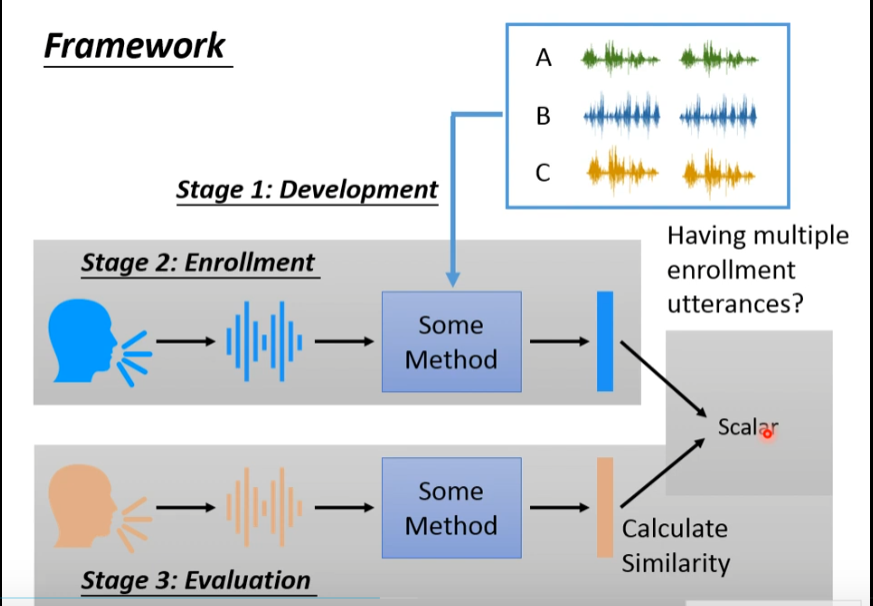
第一步 development 需要用 180k的语者
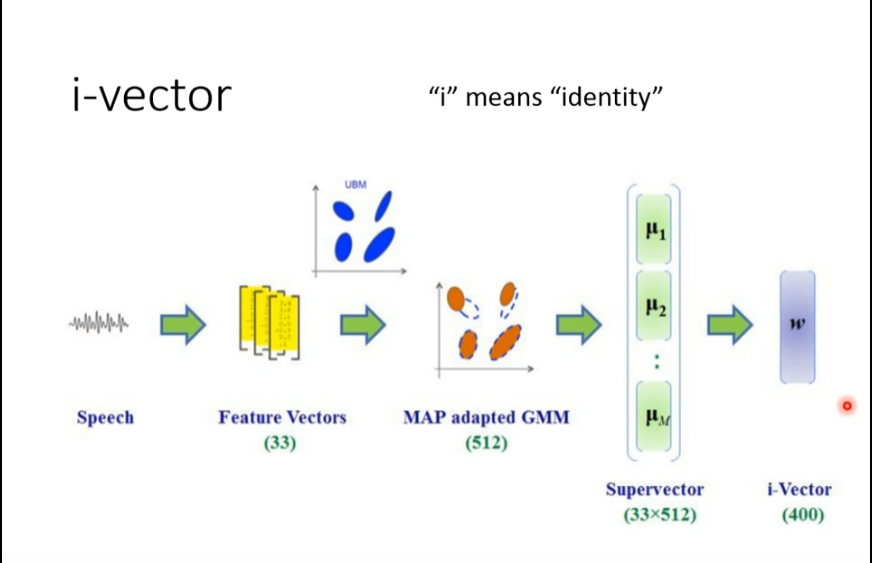
vector一般是400 维度的向量,用来表示speaker的特征
最早被使用的model是 d-vector 来实现speaker embeding 的 training
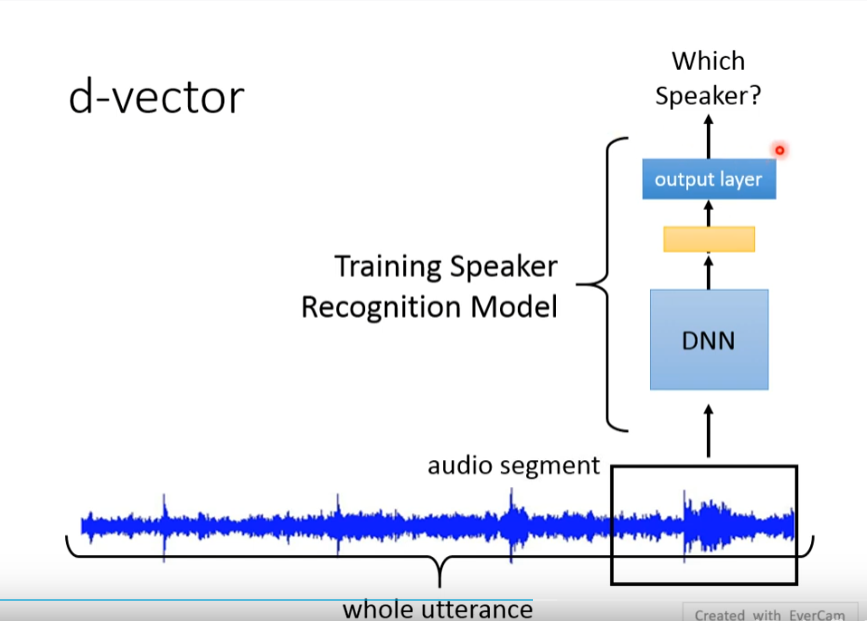
抽出最后一个layer的output
X-vector
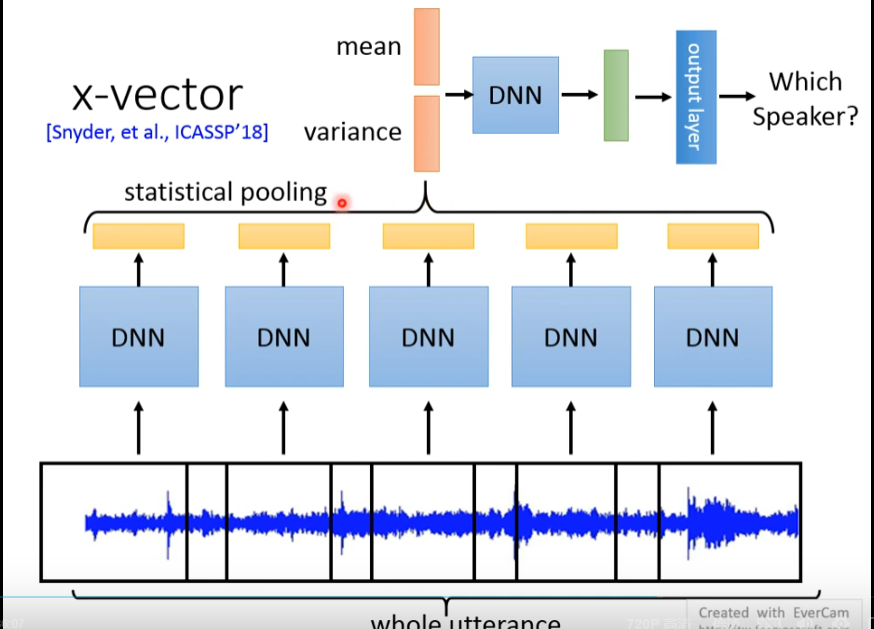
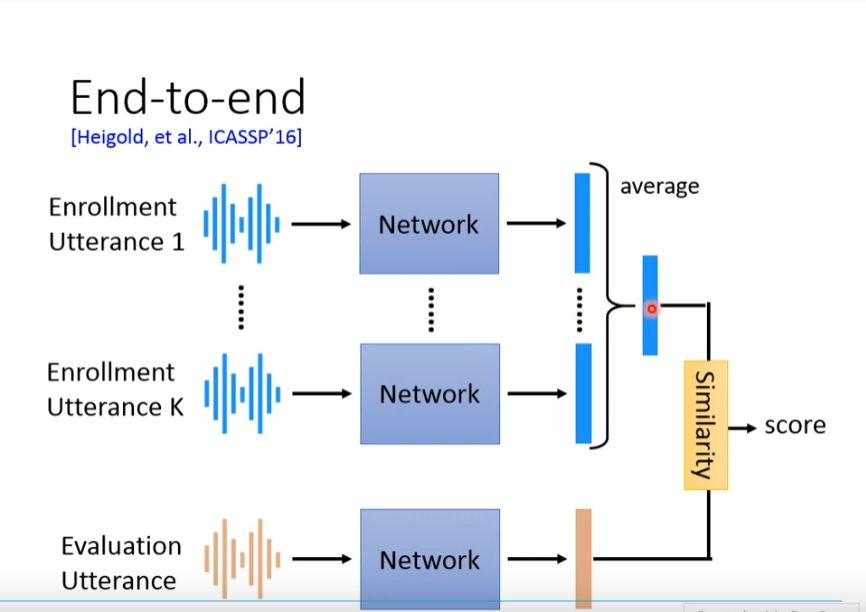
End2End 模型!