Lee's NLP bert模型
speech seperation(言语分离)
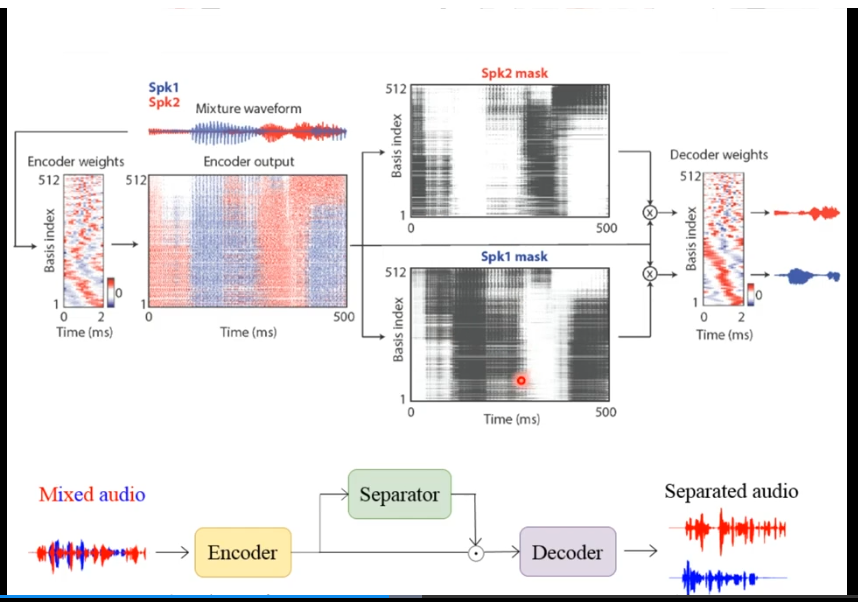
TAsnet 网络 ----可以将人说话的声音差不多15%的分离出来 (这是什么准确率。。。。泰拉)
先进过encoder编码器将混合的声音(0-2ms)变成一个spectrum(谱图),这个谱图分成speaker1的谱图和speaker2的谱图 speaker1's spectrum 和 speaker2's spectrum
通过decoder处理,(就是用原来的图片 乘以 生成的speaker1 和 speaker2 的spectrum(谱图!)) 最后 生成了分离之后的声音信号 speaker1 的voice 和 speaker2 的 voice!! ------TasNet 的基本思路
speech synthesis(语音合成)
deep voice(百度研发的一款语音合成软件,通过分离语音元素:例如音标 和 期待的读音时间 :比如说K音标期待的时间是 0.1s 之类 最后合成在一起 生成了合成的语音)----> 思路还是比较巧妙!!
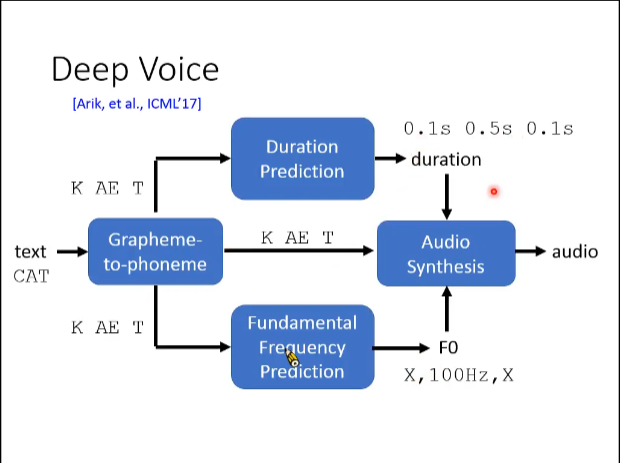
注:graptheme 实现的是识别每个字母怎么读;
duration是实现每一个字母所读出来的时间;
fundamental frequency prediction是预测每一个字母是用多大的声音频率来进行播放;
最后再生成一个audio synthesis 来讲duration 和fundamental进行合成输出语音结果!!!!
tacotron(因论文作者喜欢吃墨西哥卷饼而命名。。。)
语音合成网络!!!
输入是:character(文字)
输出是:spectrum(谱图)
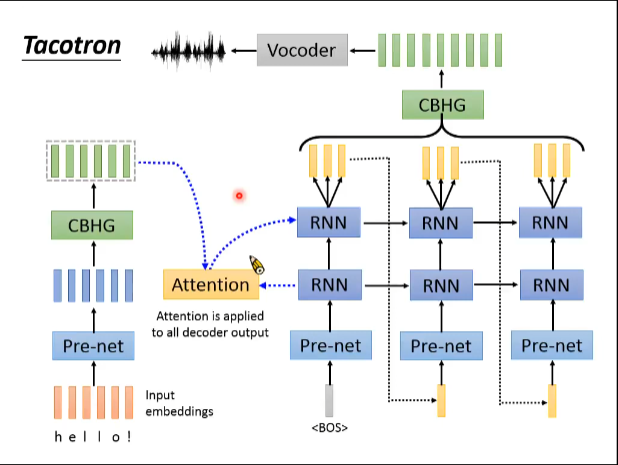
input :character ---> Pre-net ----> CBHG ------> attention(注意力机制) ------->CBHG ------> Vocoder ----->output:spectrum(谱图)
encoder --- attention -----decoder(加码器 --- 注意力机制 --- 解码器!!!!) 解码器是由Pre-net 和 RNN串合成的网络图谱!!!
Tacotron 测试的时候一定要加dropout(不然输出会效果不好,老师也无法解释。。。。无语:( )
之前必须输入的是lexicon上的词语。现在可以使用hybrid input(混合输入),可以自己输入一些没有读过或者字典里面没有的句子,然后进行输入(使用character 和 phoneme 合成输入)
可以在tacotron中加入一些文法的咨询进去,比如说:动词片语和名词片语之类的(for example)
暂时还不太清楚 attention机制,之后了解了回来补上!!
HTS :基于HMM/DNN网络的语音合成系统(直接在database里面找语音,然后丢到HMM or DNN网络中训练,得到parameters;根据label来合成语音。。。。也挺无语的)
model 2 voice(模型合成是声音)
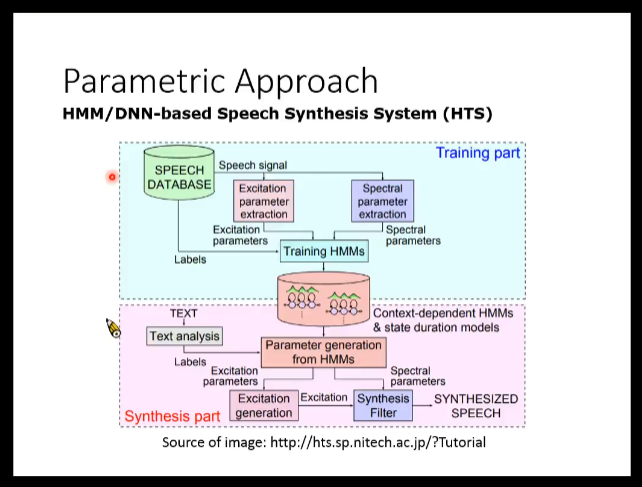
注:通过Speech Database中寻找相似(合适)的语音信号,然后通过Training HMM(训练网络)来进行合成;
再通过HMM生成的parameters和之前标注好的label(怎么又是这个东西,淦)来生成语音合成的filters(滤波器)
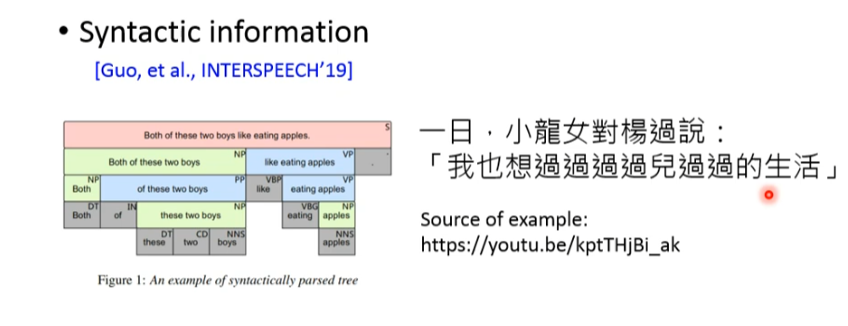
NP,PP,VBP,VP,NP,NNS之类的东西,也相当于做标注
bert 有可以当做 tacotron的输入,bert有很多的representation,可以当做是tacotron的输入!!!
注:bert非常重要!!!
Fast Speech == DurIAN
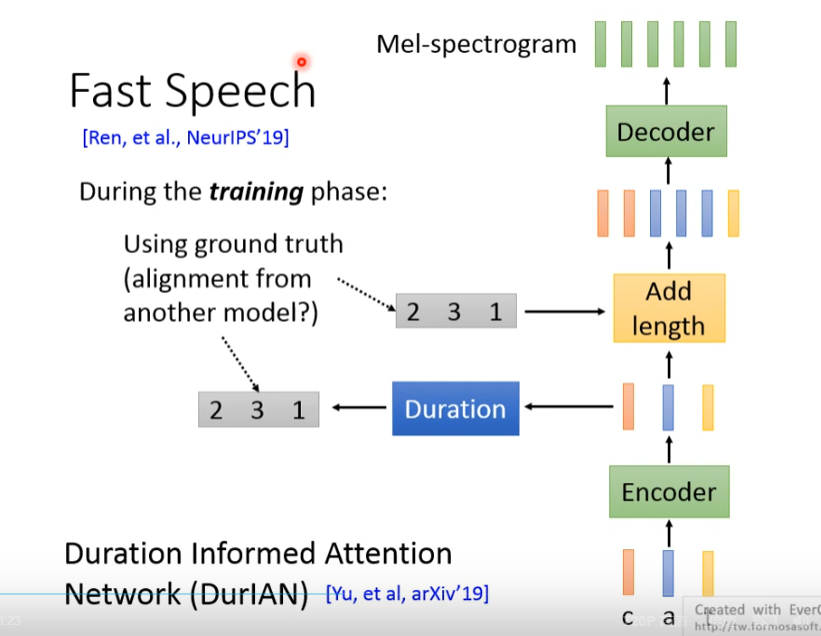
运行,生成出一个Duration,Duration中输出为numbers,duration就是复制vector长度的目标!!(感觉这个就相当于是deep voice的duration 期待值,只不过使用vector值来替代)
没有数据可以自己造数据:先得到语音信号(随便讲几句话,然后通过speech2text转换成本文文件;
这样文本信息--> label 和 语音信息---> voice 就都可以得到了)!(不愧是 白嫖大师!)
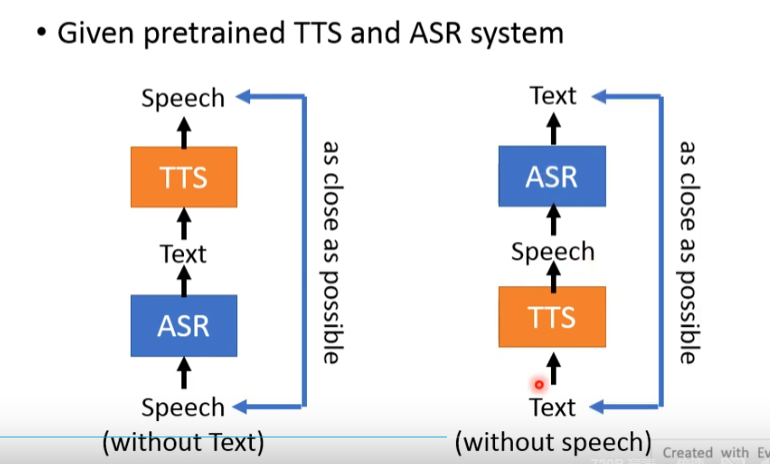
tips:让输入输出越接近越好!!! ---> dual learning(但是,引出下面的问题,直接copy过去,一模一样的,loss肯定小,一定要预防这个)
注:ASR :automatic speech recognition(自动语音识别)
TTS :text to speech(合成语音)
controllable TTS(可以控制的text to speech)
谁在说? 怎么说? 说什么? (top3 questions)
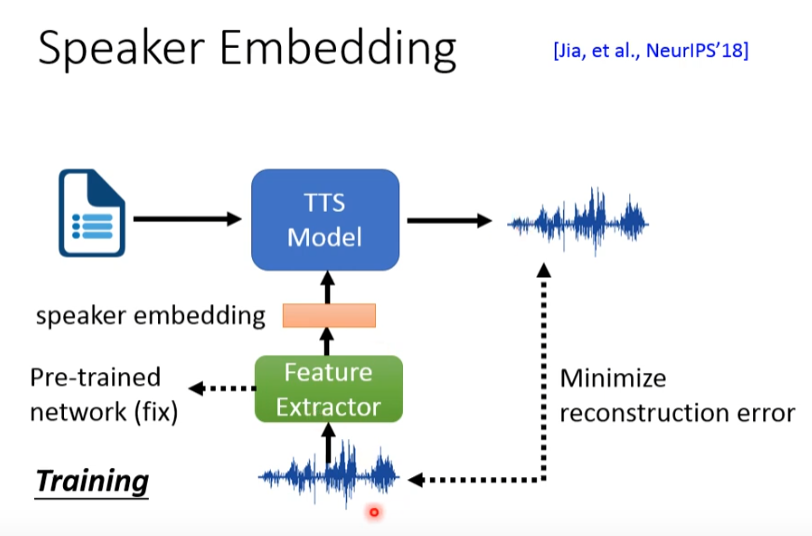
怎么防止机器直接copy过去(上面的问题)
答案:在TTS model中加feature 提取器,提取出point!
提取出的feature,就是token,是语音输出的参数!!!
通过改变token来改变讲话的不通方式!!!
或者使用2 second training :两阶段训练,可以刻意的不一样的text和voice,所以可以使用2 stages 的方法。
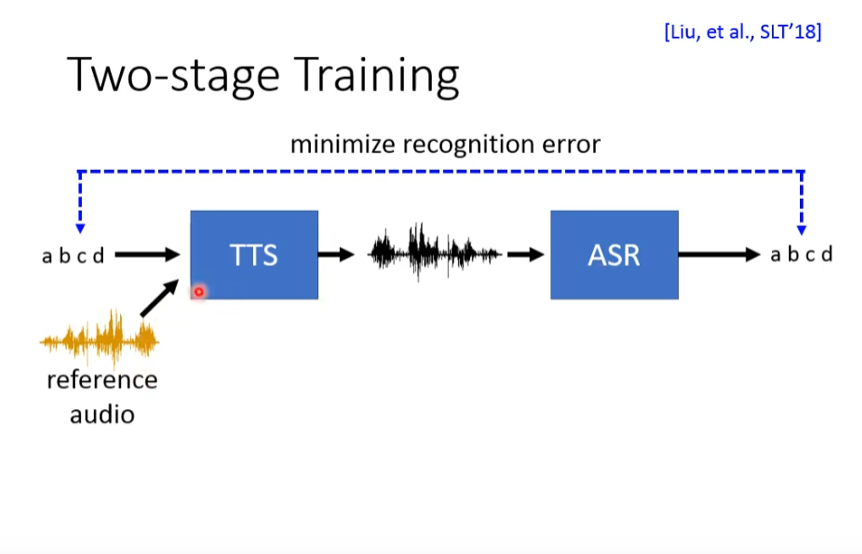
避免训练过程中,直接copy语音文字 两种方法!
(speech synthesis 语音合成 完)
