YOLO V1
YOLO V1简介
1、将一幅图分成S*S的网格,如果某个object落在这幅图片的中心,那么就让这个网格负责这个object!!
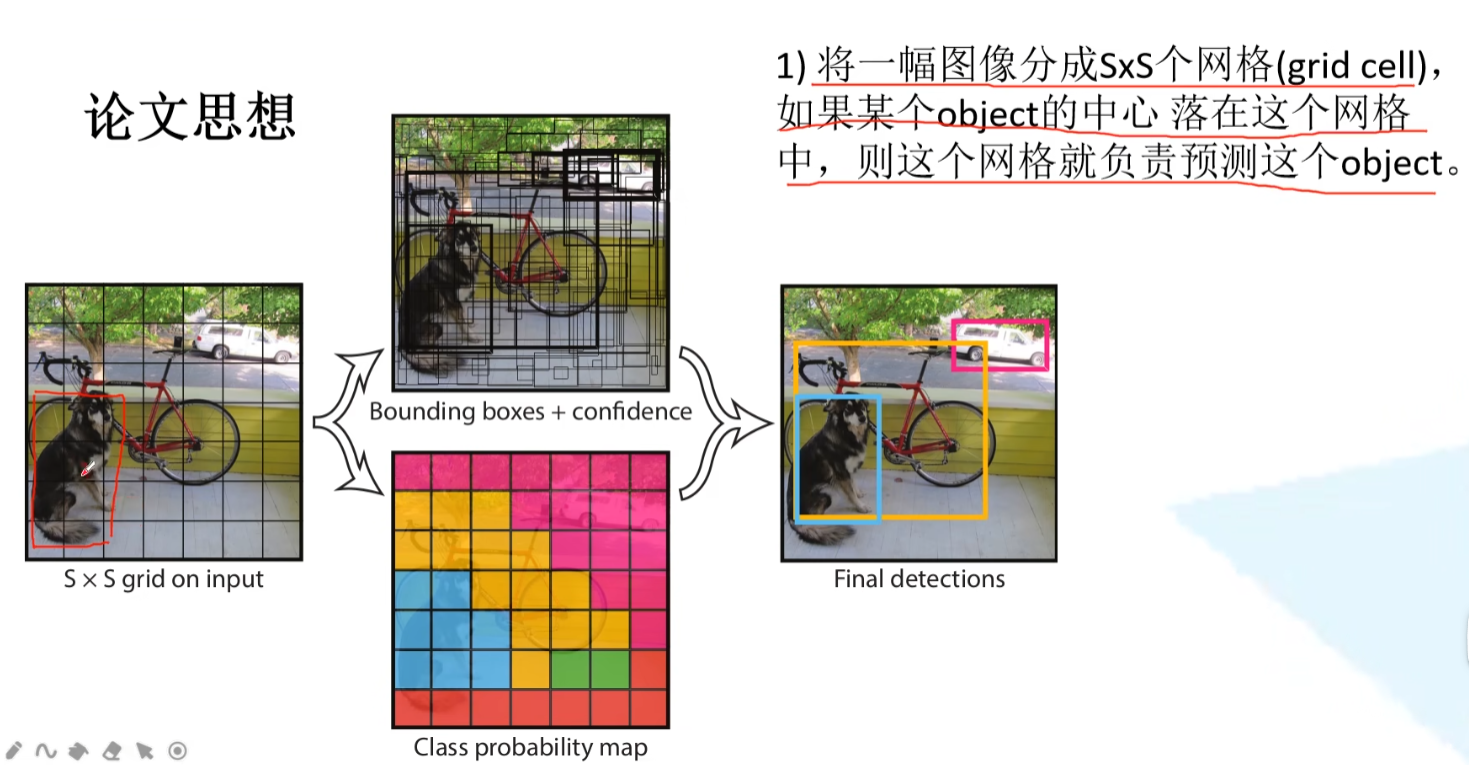
2、每一个网格都要负责预测B个bounding box,每个bounding box除了要预测位置之外,还是需要预测confident的值。除此之外每一个网格还需要预测C个类别的分数
例如在Pascal voc数据集上,我们取B = 2,这个数据集的种类是20个,则我们需要预测的类别个数为20,即C=20
最后,我们预测的向量维数为:7*7*30 :
7*7是S的值,也就是图片被分割的个数值;30 = (4+1)*2+20
4+1 : 4为bounding box的个数,1为confident值
20:为物体的类别
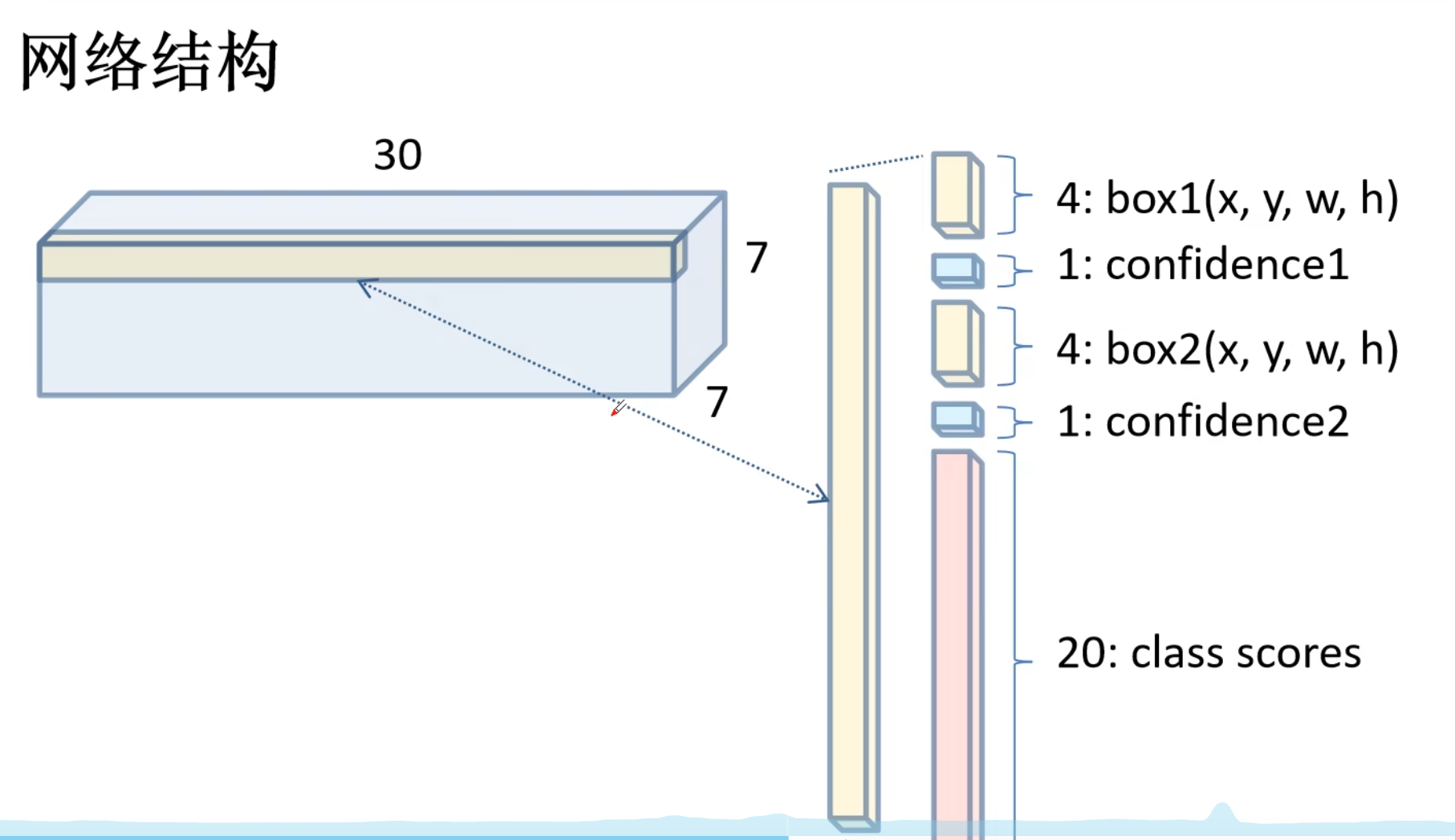
每一个bounding box 都有5个值,分别是(x,y,w,h)+ confident值(x,y为中心坐标);(w,h为长和宽)---->四组数据表明了一个bounding box
confident = (如果box中确实有object就为1)*IOU(true,union)
IOU = 交并比(相交的数据)/ (相并集的数据)
损失函数:
目标边界框的损失计算;confidence 损失;classes 损失

为什么要对bounding box进行开方处理,
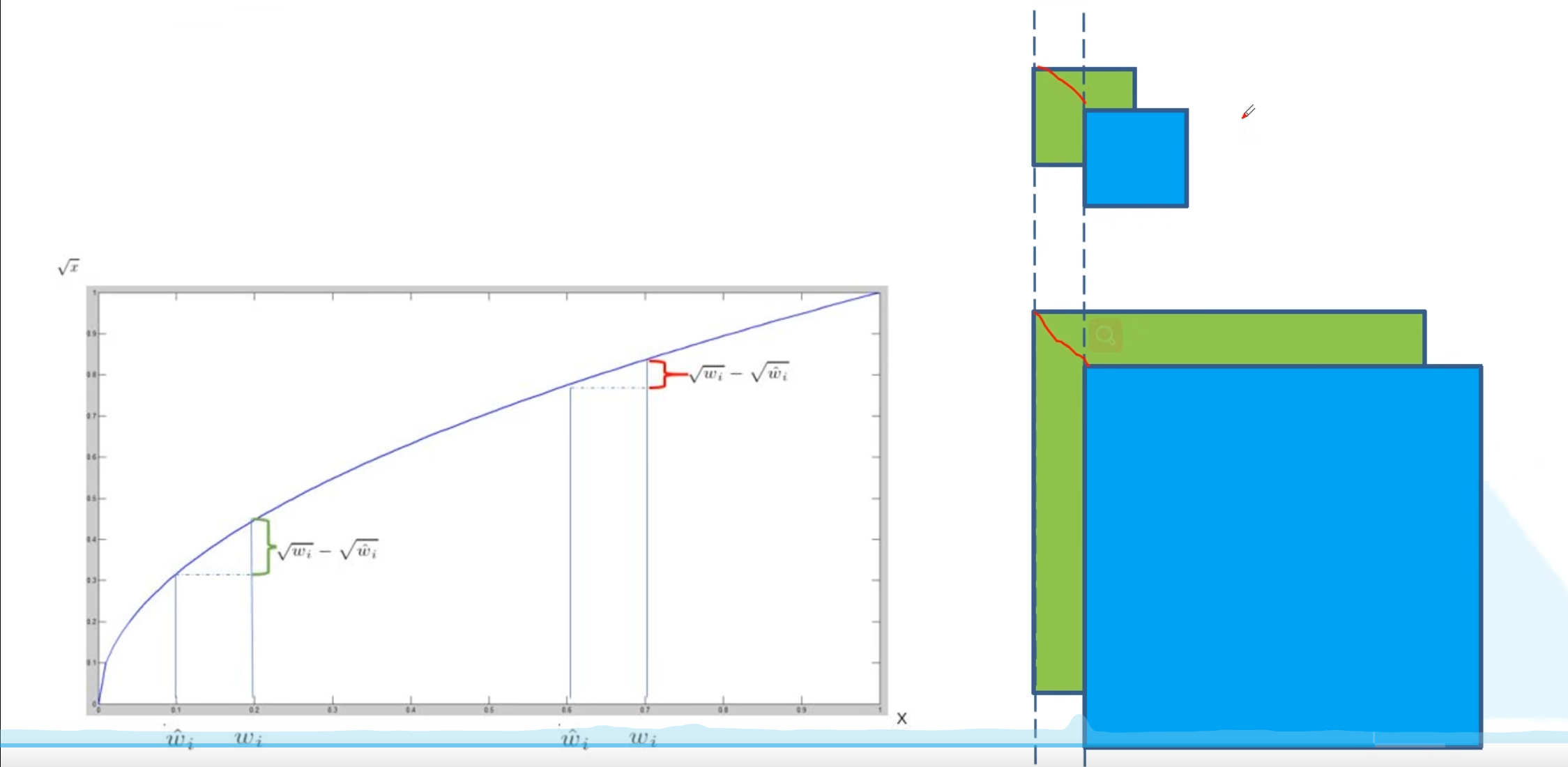
对于不同尺度的IOU,对于不同尺寸的图片损失都是不同的
偏移相同的距离,尺寸较大的图片,IOU值比较大!!,尺寸较小的图片IOU小
YOLOV1 缺点:
1、对群体性的小目标,预测性很差!!!,因为在YOLOV1中,每一个cell只预测两次,所以如果是很小的object那么IOU必然就会很小,那么损失函数必然会很大,因为损失函数很大之后,可能会被当作误差,被正则函数清理掉了!!!
2、当同一个物体出现了新的大小的时候,预测效果会比较的差!! ---> 主要来自于定位不准确!
