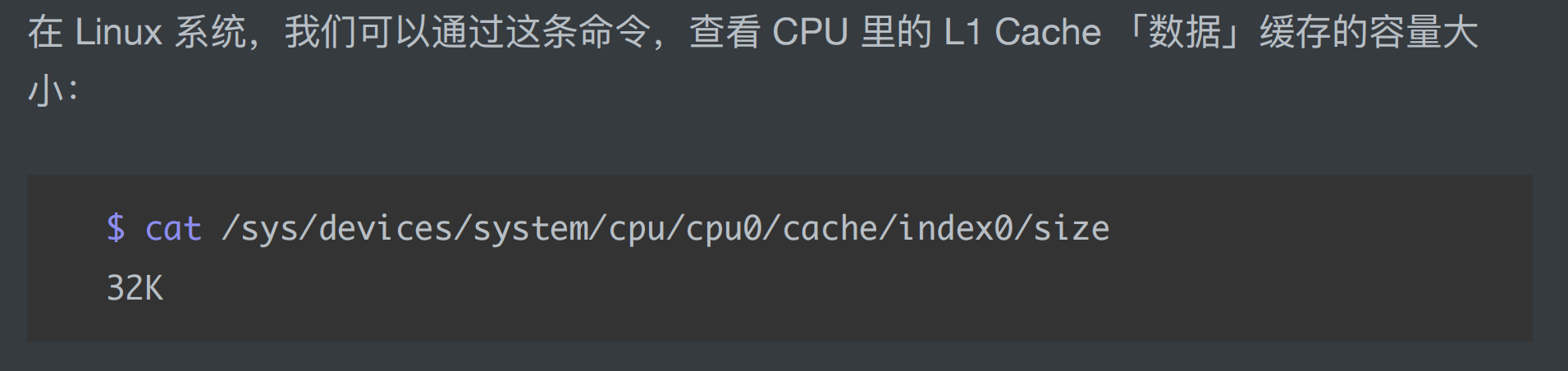
写直达的操作步骤是:
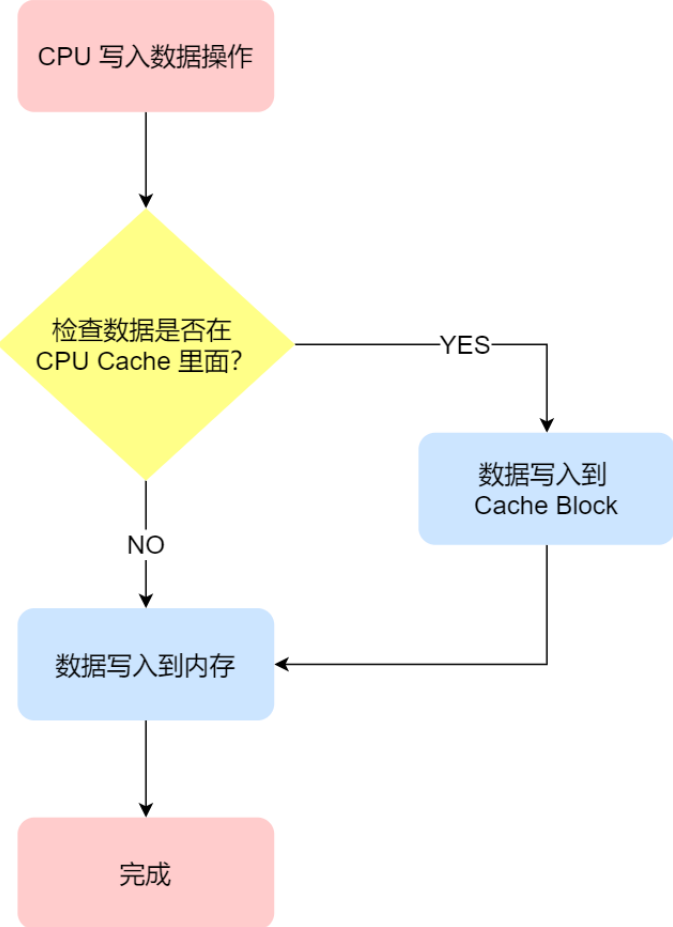
cpu数据写入
判断cpu cache中有没有数据
如果cpu cache中有数据,就将数据写入到cache block中
如果cpu cache中没有数据,则将数据直接写入内存
2----> 写回
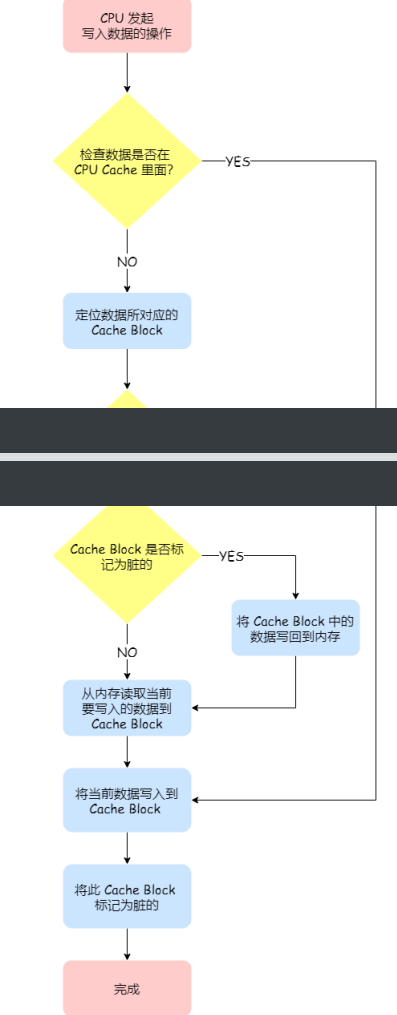
写回操作可以这样表述:
先判断数据有没有在cpu cache中;
如果cpu cache中有数据,直接更新cache block;
如果cpu cache中没有数据,则要判断cache block里面有没有数据;
如果cache block被标记为脏(有数据),则内存读入当前cache block中的数据,然后把数据写入到cache block 中,并且把cache block 标记为脏
如果cache block没有被标记为脏(没有数据),则直接把数据写入到cache block中,并把cache block标记为脏!!!
注:这个脏的标记代表这个时候,我们 CPU Cache ⾥⾯的这个 Cache Block 的数据和内存是不⼀致的,这种情况是不⽤把数据写到内存⾥的;
缓存一致性的问题:
现在的cpu都是多核从cpu,如何保证cpu的cache的缓存一致性呢?就要进行两个操作:
1、是写传播,某个cpu中的缓存变量更新之后,必须传播到其他的cpu的cache中去;
2、是事务的串行化:cpu核心中的操作顺序,必须在其他核心中看起来是一样的。
写传播很好理解
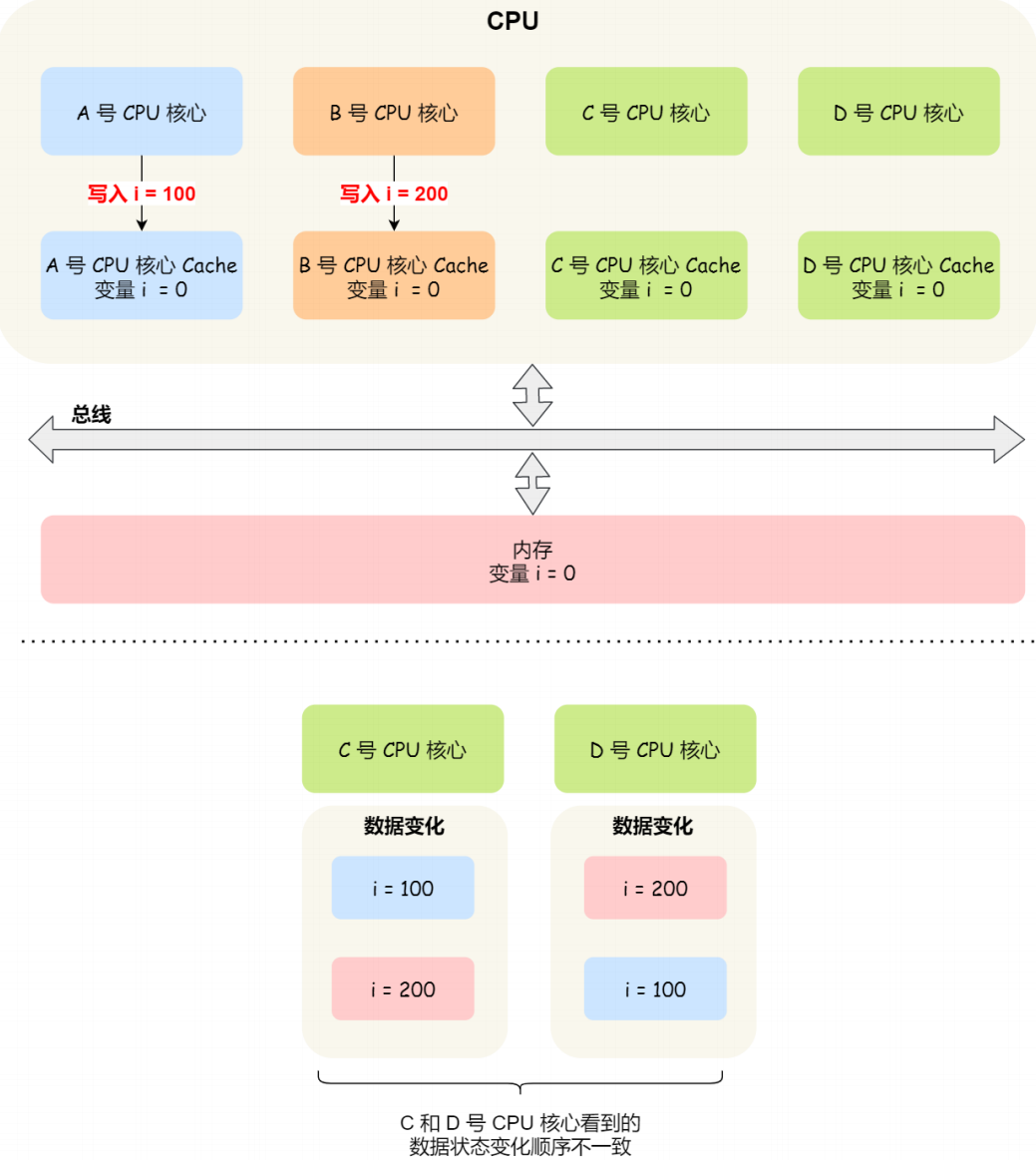
先将A中cache 写入i=100,将B中cache 写入 i=200;
于此同时c先看到i=100,在看到i=200,
d首先看到i=200,再看到i=100
两种cache变化不一样,所以必须要引入事务的串行化---> 锁的概念:如果在两个cpu核心中同时更新了某个元素的cache,那么对于这个数据的更新,只有拿到了<锁>才能继续更新,否则就是更新不了
总线嗅探:cpu某个核心模块更新了cache,则要通过总线嗅探的方式广而告之其他模块中的cache,如果其他模块中有cache,则更新cache当中的数据,---->实现写传播
MESI协议:modified,exclusive,shared,invalidated 已修改,已独占,已共享,已失效
「已修改」状态就是我们前⾯提到的脏标记,代表该 Cache Block 上的数据已经被更新过,
但是还没有写到内存⾥。⽽「已失效」状态,表示的是这个 Cache Block ⾥的数据已经失效
了,不可以读取该状态的数据。
「独占」和「共享」状态都代表 Cache Block ⾥的数据是⼲净的,也就是说,这个时候
Cache Block ⾥的数据和内存⾥⾯的数据是⼀致性的。
「独占」和「共享」的差别在于,独占状态的时候,数据只存储在⼀个 CPU 核⼼的 Cache
⾥,⽽其他 CPU 核⼼的 Cache 没有该数据。这个时候,如果要向独占的 Cache 写数据,就
可以直接⾃由地写⼊,⽽不需要通知其他 CPU 核⼼,因为只有你这有这个数据,就不存在缓
存⼀致性的问题了,于是就可以随便操作该数据。
另外,在「独占」状态下的数据,如果有其他核⼼从内存读取了相同的数据到各⾃的 Cache
,那么这个时候,独占状态下的数据就会变成共享状态。
那么,「共享」状态代表着相同的数据在多个 CPU 核⼼的 Cache ⾥都有,所以当我们要更
新 Cache ⾥⾯的数据的时候,不能直接修改,⽽是要先向所有的其他 CPU 核⼼⼴播⼀个请
求,要求先把其他核⼼的 Cache 中对应的 Cache Line 标记为「⽆效」状态,然后再更新当
前 Cache ⾥⾯的数据。
举个例子:A 号cpu核心从内存读入i值,此时其他号的cpu没有该数据,所以cpu_line 标记为独占-----> exclusive
之后B号cpu核心从内存中读入i值,此时会发送消息给其他的cpu,发现A号cpu的cache中有i的数据,之后把cpu_line改成共享-----> shared
当A号cpu要改变i的值的时候,发现cpu_line是共享状态,所以要打开广播,将其他(指B号cpu)的cpu_line改为无效状态(指invalidated),然后A号cpu中的i值在进行更新,最后将A号cpu_line的值改为已修改(modified)
如果A号cpu继续修改i的值,那么此时A号cpu_line的状态是已修改,所以不需要再进行广播,直接修改就完事了
1.5 cpu是如何执行任务的
cache上伪共享问题:
前提条件:
现在假设有⼀个双核⼼的 CPU,这两个 CPU 核⼼并⾏运⾏着两个不同的线程,它们同时从
内存中读取两个不同的数据,分别是类型为 long 的变量 A 和 B,这个两个数据的地址在物
理内存上是连续的,如果 Cahce Line 的⼤⼩是 64 字节,并且变量 A 在 Cahce Line 的开头
位置,那么这两个数据是位于同⼀个 Cache Line 中,⼜因为 CPU Line 是 CPU 从内存读取
数据到 Cache 的单位,所以这两个数据会被同时读⼊到了两个 CPU 核⼼中各⾃ Cache 中。
1)1,2号cpu都没有A,B再cache里面,假设1绑定了A,2绑定了B。1先读入A,由于从cpu中从内存到数据读取单位是cache_line ,正好A和B同属于一个cache_Line 所以A和B都会被读入到1号cpu
此时,1号cpu的cache_line 标记为exclusive(独占)
2)紧接着,2号cpu开始读入数据,因为A和B同属于一个cache_line,所以cpu再读入数据的时候,也将A读入进来了,cache_line的标记改为shared(共享状态)--->所有有A和B数据的cache_line 都会被改成共享状态
3)此时,1号cpu中A需要进行更改数据,所以1号cpu发出广播,要求2号cpu将状态改成invalidated(失效),然后1号cpu进行更改数据的操作,更改完毕之后,将1号cpu的cache_line 状态改成modified
4)此时,2号cpu中B需要进行更改数据,但是2号cpu的cache_line 已经失效了(invalidated);且由于cpu1的cache_line是已经修改的状态,且已经有数据A和B,所以将cpu1的cache_line写入内存,再有cpu2进行读取;
5)cpu2的cache_line进行数据读取的时候,cache_line状态变成shared(共享),以后cpu2的B数据再次需要更改的时候就会重复上述步骤。即cpu1和cpu2的cache_line正在交替失效!!!
这就是cache上的伪共享问题
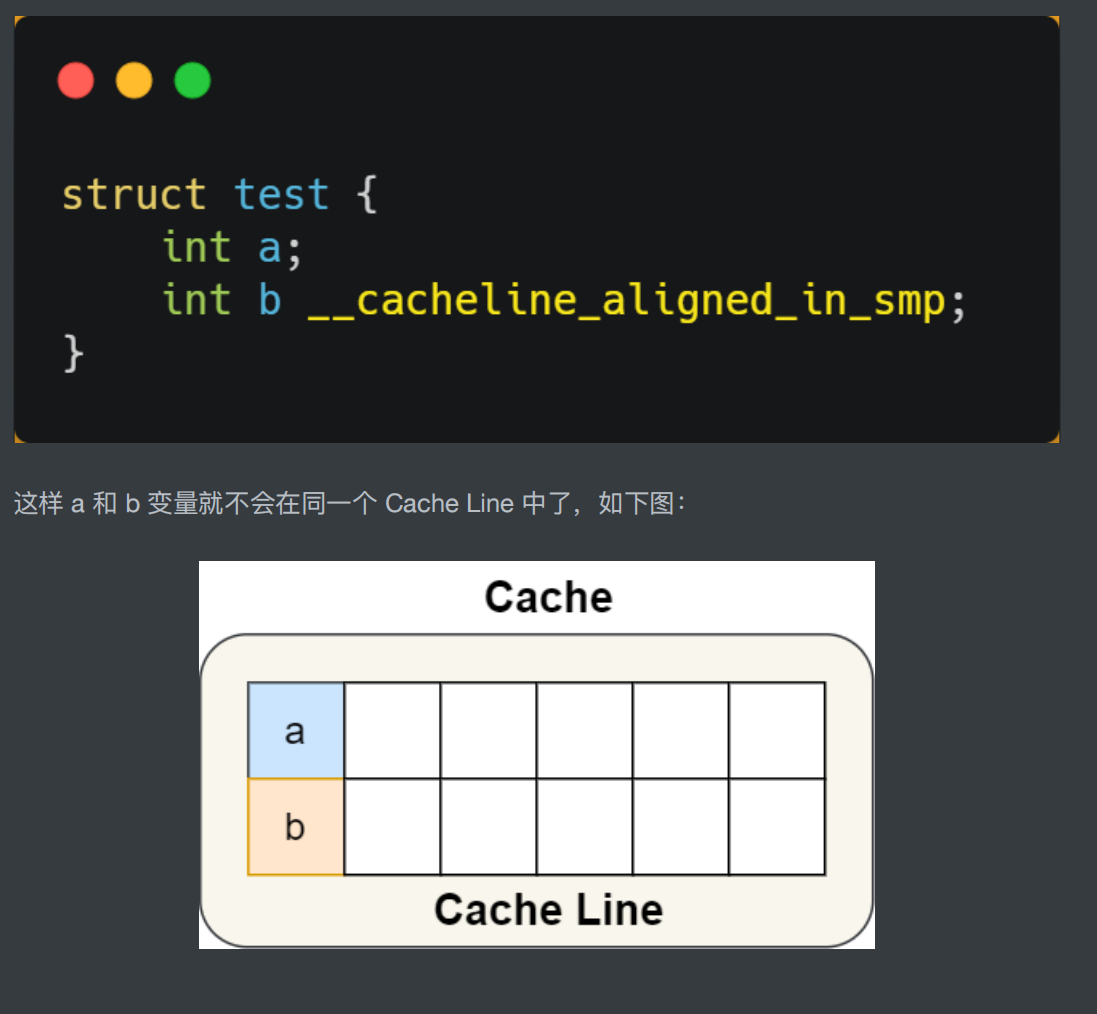
如何解决cache上的伪共享问题呢?
答案是:使用__cacheline__aligned_in_smp---->使用这种方法可以让连续地址的变量分开到两个cache_Line中去!!!!
1.6 软中断
中断处理有上下两部分:硬中断和软中断
硬中断是指:直接处理硬件方面的中断,直接处理硬件请求,会打断cpu正在执行的任务,立即处理中断程序(由硬件触发的中断),
软中断是指:软件方面的中断,主要负责硬中断没有处理完的事情,通常都是一些耗时间比较长的事情。软中断通常指的是内核线程的方式执行,(由内核触发中断)
并且每⼀个 CPU 都对应⼀个软中断内核线程
1.7 为什么负数要使用补码进行运算?
如果负数不是使⽤补码的⽅式表示,则在做基本对加减法运算的时候,还需要多⼀步操作来
判断是否为负数,如果为负数,还得把加法反转成减法,或者把减法反转成加法,这就⾮常
不好了,毕竟加减法运算在计算机⾥是很常使⽤的,所以为了性能考虑,应该要尽量简化这
个运算过程。
float--> 单精度浮点数 ------> 有效位数7-8位
1 8 23
符号位 指数位 尾数位
double ----> 双精度浮点数 ------> 有效位数 15-16位
1 11 52
符号位 指数位 尾数位
0.1 + 0.2 != 0.3
因为计算机在储存0.1和0.2的情况下,有存储溢出,存储的只可能是近似值,所以相加起来看才可能是近似值
----------> 第一章结束,还是挺累的,第一章满打满算看了两天,解决了一些从大一开始都没有弄明白的东西,非常棒!!!