07. Kubernetes - 控制器
控制器
在实际应用中,一般不会直接使用 Pod,而是会使用各种 Pod 的上层封装 控制器 来满足使用需求。Kubernetes 中运行了一系列控制器来确保集群的当前状态与期望状态保持一致。
控制器会监听资源创建、更新、删除事件,并触发
Reconcile调谐函数,该过程称为Reconcile Loop(调谐循环)或Sync Loop(同步循环)。
整个过程就像下面这段伪代码:
for {
desired := getDesiredState() // 获取期望状态
current := getCurrentState() // 获取实际状态
if current == desired { // 如果状态一致则什么都不做
// nothing to do
} else { // 如果状态不一致则调整编排,到一致为止
// 调整当前状态到期望状态并更新集群状态
}
}
这个编排模型就是 Kubernetes 项目中的一个通用编排模式:控制循环(control loop)。
ReplicaSet
ReplicaSet,简称 RS,翻译成中文就是 副本集,它最重要的用途就是:控制副本数量。
以生产应用为例,假如现有一个 Pod 正提供服务,可能会遇到以下两种情况:
- 网站访问量突然暴增。
- 运行 Pod 的节点发生故障。
针对第一种情况,可以通过手动多启动几个 Pod 副本,流量降下来之后再将多余的 Pod 杀掉的方法来应对。
针对第二种情况,如果节点挂了,也可以通过在另外的节点上重新启动一个新的 Pod 来应对。
但这两种解决办法都存在一个问题,那就是非常多的人工干预。想要减少人的工作量,就需要一种工具来自动管理 Pod。ReplicaSet 这种资源对象就实现这个功能。
ReplicaSet 控制器通过持续监听一组 Pod 的运行状态,在 Pod 数量减少或增加时就会触发调谐过程,最终保证副本数量始终如期望一致。
可以通过 explain 展示 ReplicaSet 资源清单支持的参数:
kubectl explain rs
示例资源清单:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: rs-nginx
namespace: default
spec:
# 期望的副本数量
replicas: 3
# 标签选择器
selector:
matchLabels:
app: nginx
# 模板
template:
# Pod 的资源清单
# 注释掉的配置控制器是知道的,所以不需要专门定义
# apiVersion: v1
# kind: Pod
metadata:
# 由于多个副本,让它自己生成即可,一般为控制器的 name-(ID前几位)
# name: rs-nginx-xxx
# 命名空间必须和控制器一致,也不需要定义
# namespace: default
# 标签需要定义,且要满足上面标签选择器的需求
labels:
app: nginx
version: v1.0
spec:
containers:
- name: c-nginx
image: nginx
ports:
- containerPort: 80
特别说明:
- 和 Pod 不同,ReplicaSet 的 apiVersion 为
apps/v1。 replicas为 ReplicaSet 的核心配置,用于定义副本数。selector标签选择器为必选项,必须和 Pod 中的标签进行匹配,不同的 RS 可以有相同的标签,互不影响。- ReplicaSet 属于 Pod 的上层封装,其底层还是管理 Pod,所以 Pod 的知识一定要掌握。
template字段下面定义的其实就是 Pod 的资源清单,一般会对 Pod 的资源清单进行精简,去掉某些重复声明。
常用的 ReplicaSet 资源清单操作命令:
# 创建和更新
kubectl apply -f rs-nginx.yaml
# 查看
kubectl get rs
# 通过标签筛选查看 Pod
kubectl get pods -A -o wide -l app=nginx
# 查看 rs 信息
kubectl describe rs rs-nginx
# 删除 Pod,RS 会新建 Pod 以满足期望的副本数
kubectl delete pod rs-nginx-25wg5
# 删除 RS
kubectl delete -f rs-nginx.yaml
# 另外一种删除方式
kubectl delete rs rs-nginx
# 第三种删除方式就是将资源清单中副本数调整为 0 再更新一次
# yaml 格式输出 Pod 的资源清单,metadata.ownerReferences 可以看到所属的 RS,该字段类似 RS 的外键
kubectl get pod rs-nginx-6ng5l -o yaml
# yaml 格式输出 RS 的资源清单
kubectl get rs rs-nginx -o yaml
Replication Controller(扩展了解)
Replication Controller 简称 RC,实际上 RC 和 RS 的功能几乎一致,RS 算是对 RC 的改进。
目前唯一的一个区别就是 RC 只支持基于等式的 selector(env=dev或env!=qa),RS 支持基于集合的 selector。
比如 RC 的 selector 是这样的,只支持单个 Label 的等式:
selector:
app: nginx
而 RS 中的 Label Selector 支持 matchLabels 和 matchExpressions 两种形式:
# matchLabels 格式
selector:
matchLabels:
app: nginx
# matchExpressions 格式
selector:
matchExpressions:
- key: app
operator: In
values:
- nginx
总的来说,RS 是新一代的 RC,所以 RC 几乎被废弃,直接使用 RS 即可。
Deployment
已经知道 ReplicaSet 控制器是用来维护集群中运行的 Pod 数量,但生产中一般不会直接使用它,而是会使用更上层封装的控制器,比如 Deployment。
Deployment(部署),和名字一样,其核心的功能就是实现了 Pod 的滚动更新。这对于线上的服务做到不中断发布非常重要。
通过命令可以查看到 Deployment 的资源清单参数(deployment 可以像 replicaset 一样简写为 deploy):
kubectl explain deploy
以一个 Deployment 的资源清单为例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-nginx
namespace: default
spec:
# 等待指定时间后才升级,默认 0,意味着容器启动起来后就提供服务,在某些情况下可能会造成服务不正常
minReadySeconds: 10
# 副本数
replicas: 3
# 历史版本保留个数,用于回滚
revisionHistoryLimit: 10
# 标签选择器
selector:
matchLabels:
app: nginx
# 更新策略
strategy:
# 支持 RollingUpdate(滚动更新)和 Recreate(重建)
type: RollingUpdate
# 滚动更新策略配置
rollingUpdate:
# 滚动更新过程中,不可用的副本数或者占期望值的最大比例,可以是具体值也可以是百分比
maxUnavailable: 1
# 滚动更新过程中,副本总数超过期望值的上限,可以是具体值也可以是百分比,两个值不能同时为 0
maxSurge: 1
# Pod 模板
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: c-nginx
image: nginx:latest
ports:
- containerPort: 80
配置方式和 ReplicaSet 几乎一致,只是多了 strategy 更新策略的配置。
查看创建的相关信息:
# 获取创建的 Deployment
kubectl get deploy
# 获取 Deployment 管理的 RS
kubectl get rs
# 获取 Deployment 详细信息
kubectl describe deploy deploy-nginx
# 获取 RS 详细信息
kubectl describe rs deploy-nginx-6bf679967d
# 查看相关 Pod 详细信息
kubectl describe pod deploy-nginx-6bf679967d-nzr86
通过上面的查看方式可以发现:
- Deployment 详细信息中
Annotations中的revision表示当前的版本。可以根据它实现版本回滚。 - ReplicaSet 详细信息中的
Controlled By: Deployment/deploy-nginx说明了它是被 Deployment 管理的资源对象。 - Pod 详细信息中的
Controlled By: ReplicaSet/deploy-nginx-6bf679967d说明了实际是 ReplicaSet 管理 Pod。
Deployment、ReplicaSet,Pod 的关系如图所示:
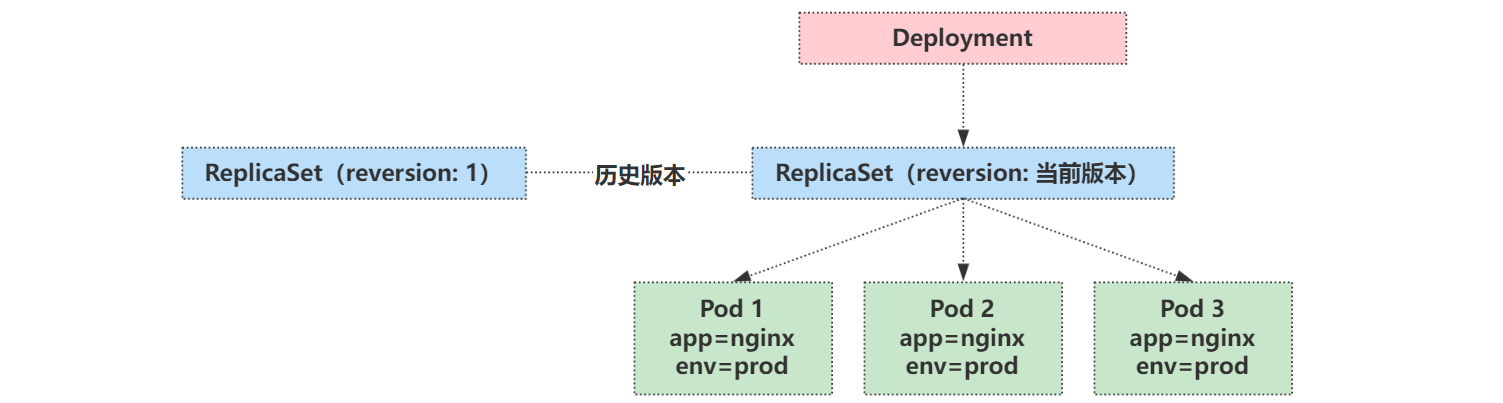
Deployment 中的容器重启策略必须是 restartPolicy=Always 。必须保证自己处于 Running 状态,ReplicaSet 才可以去明确调整 Pod 的个数。
Deployment 通过管理 ReplicaSet 的数量和属性来实现 水平扩展/收缩 以及 滚动更新。
水平扩展 / 收缩
水平扩展 / 收缩一般有两种方式:
- 修改资源清单中 Pod 副本数量,然后 apply,让 ReplicaSet 去更新。也可以通过命令来直接修改 Deployment 的镜像:
# 直接设置某些配置
kubectl set image deploy deploy-nginx nginx=nginx:1.9.1
# 直接编辑配置修改
kubectl edit deploy deploy-nginx
- 过命令行指定副本数进行扩缩容:
kubectl scale deploy deploy-nginx --replicas=4
通过命令进行的修改更适合临时调整,因为下一次修改资源清单 apply 的时候就会按照资源清单中定义重新变回原来的样子。
滚动更新
相对于 ReplicaSet 的资源配置清单,Deployment 中主要新增了滚动更新相关参数:
minReadySeconds: 5
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
参数说明:
minReadySeconds:等待指定的时间后才进行升级,默认为 0。- 配置这个值的作用在于,某些应用可能启动完成后过几秒钟就挂了,如果直接就接入流量过去,可能出现服务无法访问。
type:设置更新策略为滚动更新。- 支持
Recreate(重新创建,一次性杀掉全部 Pod,然后启动一批新的)和RollingUpdate(滚动更新)两个值。默认 RollingUpdate。
- 支持
maxSurge:升级过程中最多可以比原先设置多出的 Pod 数量。- 例如 maxSurage=1,replicas=5,更新就会先启动一个新的 Pod,完成后才删掉一个旧的 Pod,整个升级过程中最多会有 6 个 Pod。
maxUnavaible:升级过程中最多有多少个 Pod 处于无法提供服务的状态,当 maxSurge 不为 0 时,该值也不能为 0。- 例如 maxUnavaible=1,则整个升级过程中最多会有 1 个 Pod 处于无法服务的状态。
滚动更新示意图:
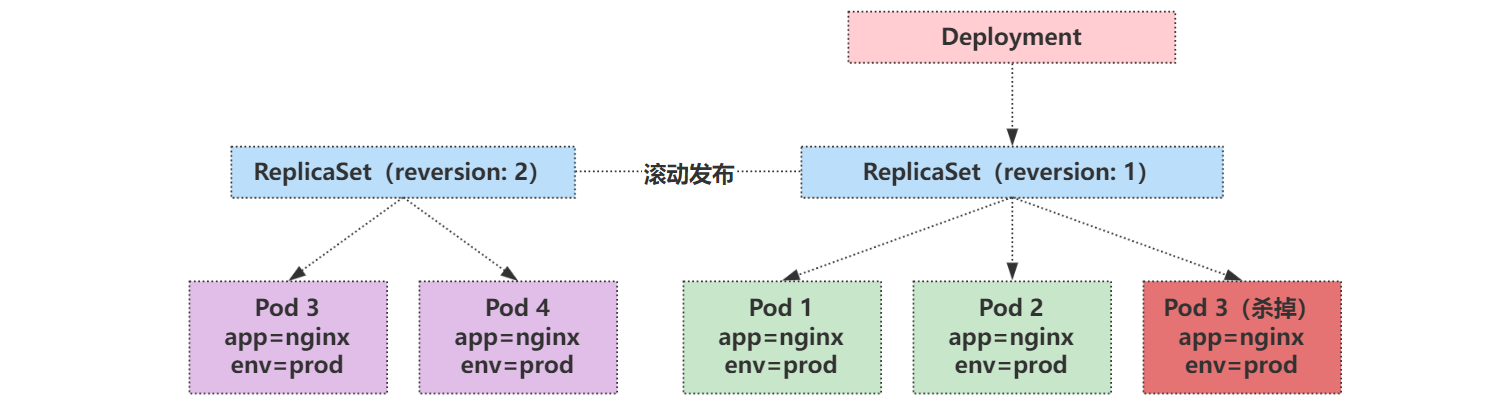
滚动更新其实就是 Deployment 新建一个 ReplicaSet,然后滚动着慢慢往新的 RS 中迁移。
版本回滚
通过调整 Deployment 的资源清单多执行几次发布,然后查看历史版本:
# 查看历史版本
kubectl rollout history deploy deploy-nginx
# 查看更新过程
kubectl rollout status deploy deploy-nginx
# 暂停更新
kubectl rollout pause deploy deploy-nginx
# 恢复更新
kubectl rollout resume deploy deploy-nginx
# 查看指定历史版本的信息
kubectl rollout history deploy deploy-nginx --revision=1
# 回滚到上个版本
kubectl rollout undo deploy deploy-nginx
# 回滚到指定版本
kubectl rollout undo deploy deploy-nginx --to-revision=1
如果资源清单跟历史的某个版本调整为一致,Kubernetes 就会认为是在做回滚。需要注意的是,回滚的操作滚动的 revision 始终是递增的。
StatefulSet
Deployment 控制器对于无状态的服务的编排很容易,但是对于有状态的服务就显得无能为力了。
当然,在使用 docker 的时候就有提到过,对于有状态的服务,是不建议放到容器中的。
无状态服务(Stateless Service):服务不会在本地存储持久化数据,多个实例对于同一个请求响应的结果完全一致,管理员可以随意的增删副本数。有状态服务(Stateful Service):与之相反,服务需要在本地存储持久化数据。类似 MySQL、Redis 这类,多副本运行在集群上数据会不一致。
以开发中遇到的问题为例:
在以前开发以 Tomcat 运行 Java 项目时,用户在登录后,处理登录逻辑的那台后端服务器会在本地缓存目录存放用户登录的 Session,标记用户已经登录成功。如果此时后端是多个节点,用户下次请求进来,经过负载均衡的调度算法可能会被分配到另外的节点上,但那台机器的缓存目录却没该用户的 Session。此时用户就会因为验证失败而退出登录。这在使用中是绝对不允许出现的。此时的 Tomcat 服务就是有状态服务。
为了解决这个问题,一般都会通过修改 Tomcat 的配置文件,通过第三方 Redis 进行节点之间 Session 共享。这样对于各个节点而言,本地就不再存储数据。用户的每次请求,不管被分配到哪个节点,获取 Session 都是去 Redis 中拿取,也就不会出现验证失败的问题。此时的 Tomcat 就变成了无状态服务。
有状态的服务部署往往非常复杂。可能需要关注每个节点的启动顺序,配置文件差异,唯一性保证等。如果想要继续用 Deployment 来管理就会非常困难。此时就需要一种新的控制器专门用于处理有状态服务,这就是 StatefulSet。
StatefulSet 控制器为 Pod 提供唯一的标识。它可以保证部署和 scale 的顺序。具有以下几个特点:
- 稳定的持久化存储,即 Pod 重新调度后还是能访问到相同的持久化数据,基于 PVC 来实现。
- 稳定的网络标志,即 Pod 重新调度后其 PodName 和 HostName 不变,基于 Headless Service 来实现。
- 有序部署,有序扩展,即 Pod 是有顺序的,在部署或扩展的时候依据定义的顺序依次进行(即从 0 到 N-1,在下一个 Pod 运行之前所有排在前面的 Pod 必须都是 Running 和 Ready 状态),基于 init containers 来实现。
- 有序收缩,有序删除(即从 N-1 到 0)
StatefulSet 必须事先拥有以下组件:
- Headless Service,用于负责 Pod 的网络身份,控制网络域。
- 提供给 PersistentVolume Claim(PVC)绑定的 PersistentVolume Provisioner(PV),用于给 Pod 提供稳定的存储。
Headless Service
Service 是应用服务的抽象,后续会专门详细的说明,这里只是简单的了解。
它的作用在于通过 Labels 为应用提供负载均衡和服务发现,每个 Service 都会自动分配一个 Cluster IP 和 DNS 域名解析,在集群内部可以通过它们直接访问后端 Pod。
比如,一个 Deployment 有 3 个 Pod,可以定义一个 Service 来作为它的访问入口:
- Cluster IP:当访问 Service 分配的 Cluster IP(VIP)地址时,它会把请求转发到该 Service 所代理的 Endpoints 列表中的某一个 Pod 上。
- DNS:当访问
Service名称.命名空间.svc.cluster.local这条 DNS 记录,就可以访问到指定命名空间下面对应的 Service,然后再代理的某一个 Pod。
对于 DNS 这种方式,不同类型的 Service 访问 Service名称.命名空间.svc.cluster.local 的原理不同:
- 普通的 Service,通过集群中的 DNS 服务解析到的 Service 的 Cluster IP。
- Headless Service,由于没有 Cluster IP,请求直接解析到代理的某一个具体的 Pod 的 IP 地址。
Headless Service 资源清单示例:
apiVersion: v1
kind: Service
metadata:
name: svc-nginx
namespace: default
spec:
ports:
- name: svc-http
port: 80
# 不设置 Cluster IP 地址
clusterIP: None
selector:
app: nginx
创建完成后可以通过命令查看:
kubectl get svc
可以看到 Cluster IP 没分配,是 None,证明这是一个 Headless Service。
Headless Service 会在集群 DNS 中增加解析:svc-nginx.default.svc.cluster.local
如果后端代理了 Pod,则会为每个 Pod IP 增加解析:pod名称.svc-nginx.default.svc.cluster.local
这样子就实现了在集群中通过 DNS 访问 Service 和 Pod,而不是 IP 地址访问。
PV 和 PVC
由于是测试,所以采用 HostPath 的的 volume 方式提供 PV 存储卷。
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-nginx-001
spec:
capacity:
storage: 1Gi
accessModes: [ "ReadWriteOnce" ]
hostPath:
path: /data/pv-nginx-001
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-nginx-002
spec:
capacity:
storage: 1Gi
accessModes: [ "ReadWriteOnce" ]
hostPath:
path: /data/pv-nginx-002
注意,后面使用几个副本就需要多少个 PV 提供绑定,完成后查看:
kubectl get pv
此时可以看到所有的 PV 处于的状态:Available
有了 Headless Service 和 PV 就能创建 StatefulSet 资源清单:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: sts-nginx
namespace: default
spec:
# 指定 Service
serviceName: svc-nginx
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: pvc-nginx
mountPath: /usr/share/nginx/html
# 配置 PVC
volumeClaimTemplates:
- metadata:
name: pvc-nginx
spec:
accessModes:
- "ReadWriteOnce"
resources:
requests:
storage: 1Gi
特殊字段说明:
serviceName:指定管理当前 StatefulSet 的 Service 名称,该服务必须在 StatefulSet 之前存在,并且负责该集合的网络标识。volumeMounts:这里关联的不是 volume 而是volumeClaimTemplates(PVC)。volumeClaimTemplates:该属性会自动创建 PVC 对象,PVC 被创建后会自动去关联当前系统中合适的 PV 进行绑定。
此时查看系统中 PV 和 PVC 状态:
kubectl get pvc
kubectl get pv
可以看到:
- 系统创建了两个 PVC 对象,名称为:
pvc-nginx-sts-nginx-索引,状态为Bound,分别绑定到之前创建的 PV 上面。 - 此时 PV 的状态也变更称为了
Bound。 - 如果此时副本数多余 PV 数量,多出来的副本就会一直处于 Pending 状态,对应的 PVC 也处于 Pending 状态。
关系示意图如下:
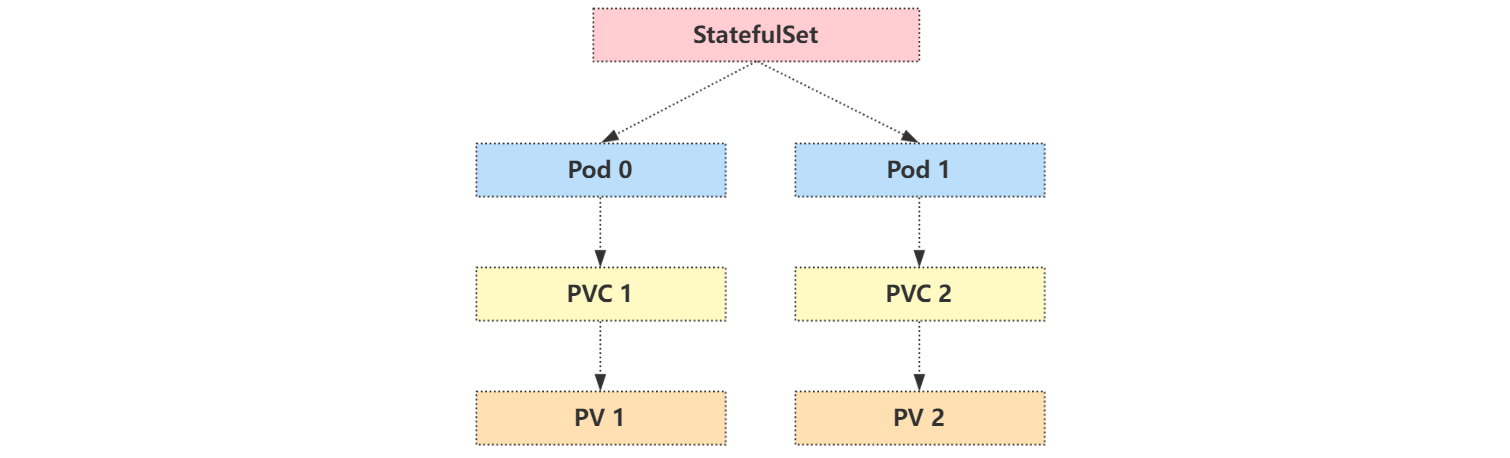
可以创建一个 busybox 的 Pod 来测试容器内部的解析:
kubectl run -it --image busybox test --restart=Never --rm /bin/sh
执行 nslookup 操作,看是否能正常解析:
# 解析 Service
# 当前名称空间
nslookup svc-nginx
# 指定名称空间
nslookup svc-nginx.default
# 完整地址
nslookup svc-nginx.default.svc.cluster.local
# 解析 Pod
# 简写地址
nslookup sts-nginx-0.svc-nginx
# 完整地址
nslookup sts-nginx-0.svc-nginx.default.svc.cluster.local
nslookup sts-nginx-1.svc-nginx.default.svc.cluster.local
可以发现由于是 Headless Service,解析 Service 的时候其实际是解析到了后端代理的 Pod。
删除 Pod 测试,测试稳定性和持久化:
kubectl delete pods -l app=nginx
Pod 删除之后会自动重建,可以发现 Pod IP 已经变了,但是 Pod 的名称没变,这意味着使用 DNS 访问的地址也不会变。
但是由于使用的是 hostPath 方式的 volume,下次调度可能就在其它节点上了,之前节点上数据还在,但是新节点上数据就没了,想要数据持久化需要使用其它的 volume。
对于某些分布式系统来说,StatefulSet 的顺序性不那么重要,更重要的是唯一性和身份标志。
可以在声明 StatefulSet 的时候设置 spec.podManagementPolicy 修改 Pod 管理策略,目前支持两种策略:
OrderedReady:默认,表示让 StatefulSet 控制器遵循上文的顺序管理 Pod。Parallel:表示让 StatefulSet 控制器并行的终止所有 Pod,在启动或终止另一个 Pod 前,不必等待这些 Pod 变成 Running 和 Ready 或者完全终止状态。
StatefulSet 可以通过设置 spec.updateStrategy.type 指定升级策略:
OnDelete:当更新 StatefulSet 模板后,只有手动删除旧的 Pod 才会创建新的 Pod。RollingUpdate:当更新 StatefulSet 模板后,会自动删除旧的 Pod 并创建新的 Pod,如果更新发生了错误,这次滚动更新就会停止。不过需要注意,StatefulSet 的 Pod 在部署时是顺序从 0~n 的,而在滚动更新时,这些 Pod 则是按逆序的方式即 n~0 一次删除并创建。
另外 SatefulSet 的滚动升级还支持部分变更,可以通过 spec.updateStrategy.rollingUpdate.partition 进行设置。在设置 partitions 后,SatefulSet 的 Pod 中序号大于或等于 partitions 的 Pod 会在 StatefulSet 的模板更新后进行滚动升级,而其余的 Pod 保持不变,这个功能类似实现 灰度发布,新旧版本同时在线。
在实际应用中,一般不会使用 StatefulSet 来部署有状态服务的,出问题容易挂壁。对于一些特定的持久化服务,确实需要放在 Kuberntes 集群中部署的,可能会使用更加高级的 Operator 来部署,比如 etcd-operator、prometheus-operator 等等,这些应用都能够很好的来管理有状态的服务。
永远记得一件事,在生产环境中,数据的安全性,稳定性才是第一位。
DaemonSet
通过控制器名称可以看出:Daemon,就是用来部署守护进程的。
DaemonSet 用于在每个 Kubernetes 节点中将守护进程的副本作为后台进程运行,说白了就是在每个节点部署一个 Pod 副本,当新的节点加入到 Kubernetes 集群中,Pod 会被调度到该节点上运行,当节点从集群只能够被移除后,该节点上的这个 Pod 也会被移除。当然,如果删除 DaemonSet,所有和这个对象相关的 Pods 都会被删除。
基于这种特性,DaemonSet 常被用于:
- 集群存储守护程序,如 glusterd、ceph 要部署在每个节点上以提供持久性存储。
- 节点监控守护进程,如 Prometheus 监控集群,可以在每个节点上运行一个 node-exporter 进程来收集监控节点的信息。
- 日志收集守护程序,如 fluentd 或 filebeat,在每个节点上运行以收集日志。
- 节点网络插件,比如 flannel、calico,在每个节点上运行为 Pod 提供网络服务。
正常情况下,Pod 运行在哪个节点上是由 Kubernetes 的调度器策略来决定的,然而 DaemonSet 控制器创建的 Pod 实际上提前已经确定了在哪个节点上了,所以即使调度器还没有启动,依旧可以创建 Pod。
DaemonSet 的资源清单和其它控制器几乎一样:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: ds-nginx
namespace: default
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
查看 Pod 状态:
kubectl get pods -A -o wide
可以发现每个 Worker 节点都运行了一个 Pod。
如果是 kubeadm 安装的 Kubernetes 集群,那么 Master 节点将不会启动该 Pod。因为 Master 节点默认被标记了 污点。
DaemonSet 运行的示意图如下:
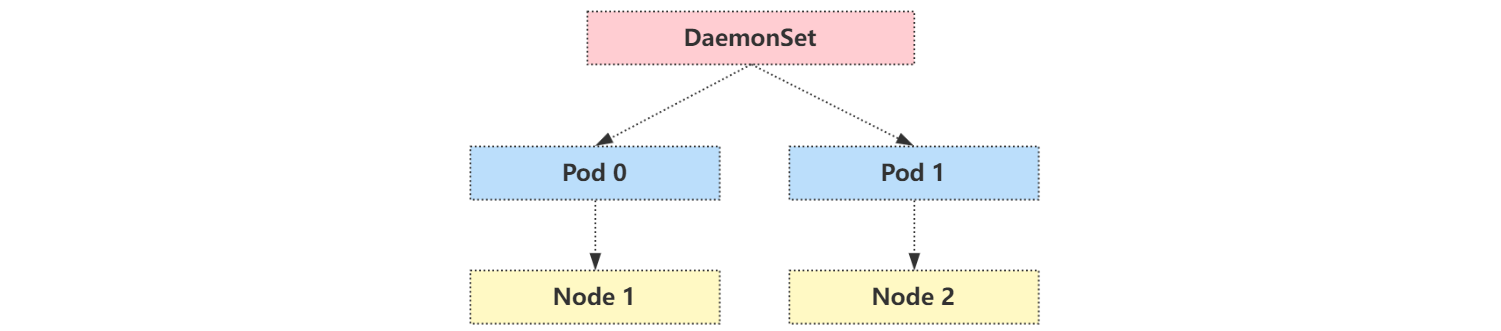
集群中的 Pod 和 Node 是一一对应d的,而 DaemonSet 会管理全部机器上的 Pod 副本,负责对它们进行更新和删除。
DaemonSet 控制器保证每个 Node 上有且只有一个被管理的 Pod 的实现原理:
- 首先 DaemonSet 从 ETCD 获取到 Node 列表,然后遍历所有的 Node。
- 根据资源对象定义是否有调度相关的配置,然后分别检查 Node 是否符合要求。
- 在可运行 Pod 的节点上检查是否已有对应的 Pod,如果没有,则在这个 Node 上创建该 Pod,如果有不止一个,就删除多余的 Pod ,如果只有一个 Pod,就不管。
在后面学习了资源调度后,也可以用 Deployment 来实现 DaemonSet 的效果。
同时 DeamonSet 也支持 OnDelete 和 RollingUpdate 两种更新方式,默认是滚动更新。
Job
Job 负责处理任务,主要为仅执行一次的任务,它保证批处理任务的一个或多个 Pod 成功结束。
Job 的资源清单如下所示:
apiVersion: batch/v1
kind: Job
metadata:
name: job-demo
namespace: default
spec:
# 限制任务运行的最长时间
activeDeadlineSeconds: 100
# 任务失败重建 Pod 的次数,默认 6,重建 Pod 的间隔呈指数增加,即 10s、20s、40s...
backoffLimit: 10
# 定义 Job 最多可以有多少 Pod 同时运行
parallelism: 2
# 定义 Job 至少要完成的 Pod 数目
completions: 5
template:
spec:
# 重启策略必须是 Never,设置 OnFailure,则 Job 执行失败后不会创建新的 Pod,只会不断重启 Pod
restartPolicy: Never
containers:
- name: demo
image: busybox
command:
- "/bin/sh"
- "-c"
- "echo 'Hello World'"
配置清单参数说明:
apiVersion:Job 类的属于batch/v1而不是apps/v1。activeDeadlineSeconds:限制任务运行时间,如果运行超过该时间,这个 Job 的所有 Pod 都会终止,Pod 的终止原因为:DeadlineExceeded。backoffLimit:当重启策略设置为Never时,Job 在执行失败后会不断创建新 Pod,但不会一直创建下去,可以通过该参数进行限制,默认为 6。同时 Job 重建 Pod 的间隔是呈指数增加的,即 10s、20s、40s… 后。parallelism:并行控制,定义 Job 能有多少个 Pod 同时运行。completions:定义 Job 至少要完成的 Pod 数目。RestartPolicy:重启策略,仅支持Never和OnFailure两种,不支持Always。
需要注意的是:Job 和 Deployment、StatefulSet 之类不同的地方在于,Pod 中的容器要求是一个任务,而不是一个常驻前台的进程。执行 apply 之后 Pod 会很快的退出,如果没出错,状态就处于 Completed。
CronJob
CronJob 相当于在 Job 的基础上加上了时间调度,使得任务可以在给定的时间点运行,也可以周期性地在给定时间点运行。类似于 Linux 中的 crontab。它的时间配置也和 crontab 一样。
时间格式为:分 时 日 月 周
- 分:支持 0~59,每分钟配置为
*/1。 - 时:支持 0~23
- 日:支持 1~31
- 月:支持 1~12
- 周:支持 0~7,0 和 7 都表示星期天
使用 CronJob 来管理 Job 任务的资源清单:
apiVersion: batch/v1
kind: CronJob
metadata:
name: cronjob-demo
namespace: default
spec:
# 定时任务
schedule: "*/1 * * * * "
successfulJobsHistoryLimit: 3
failedJobsHistoryLimit: 3
# 配置 Job 资源清单,省略了某些重复项
jobTemplate:
spec:
template:
spec:
restartPolicy: OnFailure
containers:
- name: demo
image: busybox
command:
- "/bin/sh"
- "-c"
- "echo AAAA"
配置清单参数说明:
schedule:指定任务运行的周期,格式和 crontab 一样。jobTemplate:指定需要运行的任务,格式就是 Job 资源清单。successfulJobsHistoryLimit:历史限制,指定可以保留多少完成的 Pod,默认为 3。failedJobsHistoryLimit::历史限制,指定可以保留多少失败的 Pod,默认为 1。
如果不再需要 CronJob,可以使用 kubectl 命令删除它:
kubectl delete cronjob cronjob-demo
不过需要注意:将会终止正在创建的 Job,但是运行中的 Job 将不会被立即终止。





【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· DeepSeek “源神”启动!「GitHub 热点速览」
· 我与微信审核的“相爱相杀”看个人小程序副业
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库
· 上周热点回顾(2.17-2.23)