PBFT算法流程
转载原址:https://my.oschina.net/u/3620978/blog/3142775
1. 系统模型
本部分介绍PBFT算法运行的系统模型。
1.1 网络
PBFT工作在异步的分布式系统中,系统中各个节点彼此通过网络连接。 系统运行时,消息的传递允许出现下列情形:不能正确发送、延迟、重复、乱序
1.2 拜占庭错误节点
系统允许错误节点也就是拜占庭节点表现出任意行为,但是需要附加一个限定条件: 节点失效彼此应相互独立,从而大部分或全部节点不会同时失效。
在有恶意攻击存在的情况下,可以采取类似于下列措施来保证这个限制的成立:各节点运行的服务程序和操作系统的版本尽可能多样化;各节点的管理员帐号和密码不同。
1.3 消息加密属性
1.3.1 使用加密技术的目的
防止身份欺骗、重播攻击;监测错误消息
1.3.2 具体使用的加密技术
公钥签名:用于验证消息发送者身份,PBFT中,实际上只用于view-change和new-view消息,以及出现错误的情况。其他消息都采用下面将会提到的MAC(消息认证码)进行认证。这是算法设计中提出的一种优化措施,用于提升算法性能。
MAC:即消息认证码,用于算法正常操作流程中的消息认证
消息摘要:用于检测错误消息
1.4 敌手特性
算法限定敌手(adversary)可以:串通拜占庭节点;延迟通信或正常节点。
同时,敌手不可以:无限延迟正常节点的通信;伪造正常节点签名;从消息摘要反推原始消息;让不同消息产生相同摘要。
2. 服务属性
本部分介绍运行PBFT算法的系统的服务属性。
2.1 关于副本复制服务
PBFT算法可用于实现确定性的副本复制服务(Replicated service)。 副本复制服务拥有状态(state)和操作(operation)。
客户端(client)向服务发起请求,以执行操作,并等待响应。
服务由 n个节点组成。操作可以执行任何计算,只要这些计算始终产生确定性的结果。
节点和客户端如果遵循算法的预定步骤执行操作,则被称为正常节点或客户端。
2.2 关于Safety和Liveness
只要系统中失效节点的个数不超过容错数 ,系统就能提供safety和liveness。
2.2.1 Safety
Safety的提供,是系统能保证客户端请求的线性一致性(linearizability),即请求按顺序一次一条地被执行。
PBFT相对于之前的算法如Rampart等的一个显著的不同在于,其Safety不依赖于同步假设。
算法不需限定客户端一定是正常的,允许其发送不合法的请求,原因是各正常节点可以一致性地监测客户端请求的各种操作。并且算法可以通过权限控制的方式对客户端进行限制。
2.2.2 Liveness
由于算法不依赖于同步提供 Safety,因此必须通过同步假设来提供 Liveness。
这里的同步假设是,客户端的请求最终总能在有限的时间内被系统接收到。
客户端可能会通过多次重传的方式,发送请求到服务,确保其被服务接收到。
PBFT所依赖的同步假设其实是比较弱的假设,原因是在真实的系统中,网络错误最终总可以修复。
2.3 关于算法弹性
PBFT的算法弹性(resiliency)是最优的:假定系统中失效节点最大个数为f,则系统最少只需要 3f+1 个节点就可以保证Safety和Liveness。
简单证明:
考虑到最不理想的情况,系统有最大数量的失效节点,即f个。(总节点数为n) 客户端此时可以接收到的回复个数最坏情况是 n-f,因为失效节点可能都不会回复。 但是,由于网络等原因,客户端接收到的 n-f 个请求中,实际上有可能包含有失效节点的回复(有可能是错误的),而另外一些正常节点的回复还未及时收到。 这其中,最坏的情况是,n-f个结果中,有f个是失效节点发送的。按照PBFT算法的定义,客户端需要收到 f+1 个相同的回复,才被当作是正确的结果。因此 n-f 个结果中,出去f个失效节点的结果,即 n-f-f = n-2f 至少要是f+1, 即 n-2f = f+1,也就是说 n=3f+1是最少需要的节点数量。
2.4 关于信息保密性
一般情况下,为确保服务的高效性,不能提供容错的信息保密性。
可能可以使用secret sharing scheme来获得操作参数和部分对操作来说透明的状态的保密性。
3. 算法主流程
本部分介绍运行PBFT算法的主流程,即正常操作流程。
3.1 主流程简介
3.1.1 相关定义
算法是状态机副本复制技术的一种形式:服务被建模为状态机,其状态在分布式系统中的不同副本节点上被复制。每个状态机副本节点保存维护着服务状态,并实现服务的各种操作。
假设所有副本节点个数为n,算法中,每个节点依次编号为 0, 1, ..., n-1
方便起见,假设系统中的副本节点总数为 3f+1。可以有更多数量的节点,但是这不会使算法的弹性更优,只会使系统的性能降低。
系统在称为视图(view)的配置下工作。视图以整数编号,从0开始。在一个具体的视图 v 中,通过 p =v mod n,决定出主节点(primary),而其余节点成为副本节点(backup)。当主节点失效时,进行视图变更(view change)。视图的编号是连续递增的。
3.1.2 算法主流程简要描述
算法主流程可简要描述如下:
1. 客户端通过向主节点发送请求,以调用服务的操作;
2. 主节点向其他所有副本节点广播该请求;
3. 各节点执行客户请求,同时将回复发送到客户端;
4. 客户端收到 f+1 个来自不同节点的相同的回复后,此回复即为本次请求的结果。
因为算法基于状态机副本复制技术,所以节点需满足两个条件:必须是确定性的,即对于给定的状态,以及给定的参数集合,调用相同的操作后,将始终得到相同的结果。
各节点拥有相同的初始状态。
在满足上述两个条件的情况下,算法可以保证系统的Safety属性:即使存在失效的节点,各正常副本节点仍可以就不同的请求的执行顺序达成总体的一致。
3.2 算法主流程
接下来详细描述算法主流程。为方便起见,这里省略讨论以下细节:
节点因空间不足导致错误,以及如何恢复;
类似网络的原因等导致的客户端消息的重传。
另外,假设消息使用公钥签名进行认证,而不是更高效的 MAC 的方式。算法流程的启动从客户端发送请求开始。
3.2.1 客户端操作
客户端操作流程示意图如下:
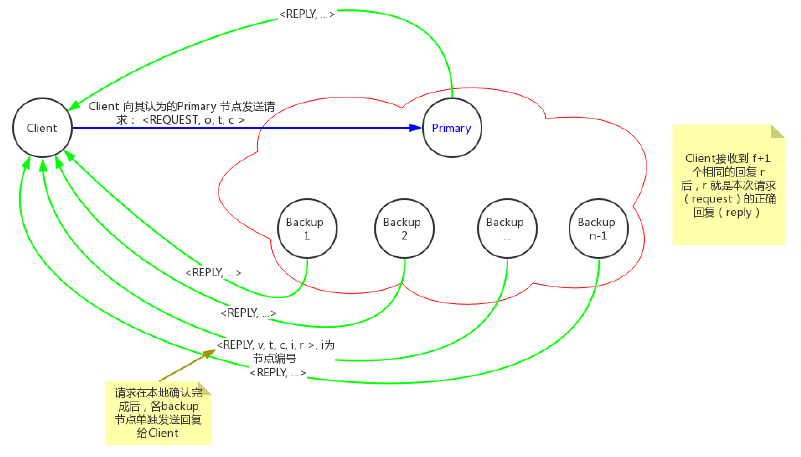
客户端向其认为的Primary节点发送请求:<REQUEST, o, t, c >。其中,o是请求的操作,t是时间戳,c代表客户端信息。这里省略了消息的签名,包括下文提到的所有消息都应该有发送方的签名,为了讨论方便,作了省略。
相关的几点说明:
请求中的时间戳用于保证请求只被执行一次的语义:所有的时间戳都严格排序,即后发送的请求比先发送的请求拥有更高的时间戳。
每个副本节点向客户端发送回复时,都会包含当前的视图编号。客户端可以通过该视图编号来确定当前的主节点,并且只向其认为的主节点发送请求。
每个副本节点执行完请求后,各自单独地向客户端发送回复,其格式为: <REPLY, v, t, c, i, r > 。v是当前的视图编号,t是请求发送时对应的时间戳,i是副本节点的编号,r是请求的操作的执行结果。
客户端等待来自 f+1 个不同副本节点的相同回复,即t和r要相同。如果客户端等到了 f+1 个相同回复,r即为请求的结果。 之所以该结果是有效的,是因为错误节点的个数最多为f个,因此必然至少有一个正常节点回复了正确结果,此结果就是 r。
如果客户端没有及时收到回复,则会将请求广播给所有副本节点。副本节点收到请求后,如果发现已经执行过该请求,就只是将结果重新发送至客户端;否则,它会把请求转发到主节点。如果主节点没有把请求广播给其他节点,则最终会被足够多的副本节点认定为错误节点,从而触发视图变更。
在接下的流程讨论中,假定客户端等待一个请求完成后,才发送下一个请求。但是,算法允许客户端异步地发送请求,并且可以保证不同请求按顺序执行。
3.2.2 三阶段协议
主节点收到客户端请求后,将启动三阶段协议,也就是算法接下来的流程。
这三阶段是pre-prepare,prepare和commit。前两阶段,即 pre-prepare 和 prepare 用于保证当前视图中请求被排好序,而后两阶段 prepare 和 commit 保证请求在视图变更后,仍旧是排好序的。
3.2.2.1 pre-prepare阶段
pre-prepare 阶段流程示意图如下:
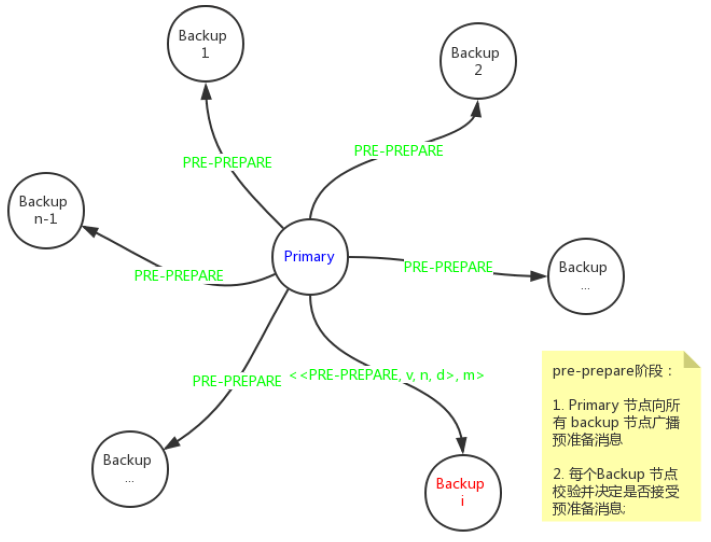
pre-prepare阶段中,主节点组装预准备消息,同时把客户端请求附加在其后:<<PRE-PREPARE, v, n, d>, m>,其中,v 指示当前消息当前在哪个视图中被编号和发送,m 是客户端的请求消息,n是主节点给 m 分配的一个序号(sequence number), d 是 m 的摘要。
这里需要注意的是,请求 m 并没有放在预准备消息中,这样做可以使预准备消息变得更简短。这样做有两个好处:
1、降低通信的负载:在视图变更时,由于各节点收到的预准备消息会被用来证明一个特定的请求确实在特定的视图中被赋予了一个序号,较简短的预准备消息将使数据传输量更少。
2、有助于传输优化:算法运行中,一方面需要向各节点发送客户端请求,另一方面需要传输协议消息以实现对客户请求的排序。通过对这两者解耦,可以实现对较小的协议消息的传输以及对应于较大的请求的大消息的传输分别进行优化。
每个副本节点接收到预准备消息后,会进行如下校验,如果条件都满足的话,就接受该消息;否则就什么也不做:
客户端请求和预准备消息的签名都正确;d 和 m的消息摘要一致;
当前节点的当前视图是v;
当前节点未曾接受另外一条预准备消息,其包含的视图编号和消息序号都和本条消息相同,但对应的是不同的客户端请求;
预准备消息中的序号 n 位于低水线 h 和高水线 H 之间。这是为了防止有可能出错的主节点随意地选择序号来耗尽序号空间,例如故意选择一个非常大的序号。
如果副本节点接受预准备消息,接下来就进入prepare 阶段,如下节所示。
3.2.2.2 prepare阶段
prepare 阶段流程示意图如下:
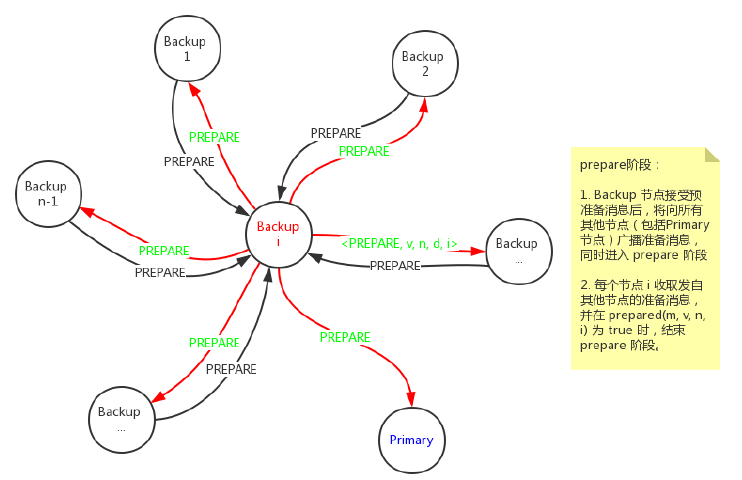
在 prepare 阶段,节点会组装并广播准备消息给其他所有副本节点,同时把预准备和准备消息写入到本地消息日志中。
准备消息格式如下: <PREPARE, v, n, d, i>。其中,i 为节点编号,其余参数和预准备消息中的含义相同。
对于副本节点(包括主节点)来说,当其收到其他节点发送过来的准备消息时,会对这些消息进行校验,如果这些消息满足下列条件:
签名正确
其视图编号和节点的当前视图编号相同
消息中的序号在 h 和 H 之间
则节点会接受准备消息,并写入消息日志中。
对于一个副本节点 i 来说,如果其消息日志中包含如下消息:
客户端请求 m
在视图 v 中将 m 分配序号 n 的预准备消息
2f个由不同的副本节点发送的、和预准备消息相匹配的准备消息;这里匹配的含义是,有相同的视图编号、请求序号,以及消息摘要。
我们就称prepared(m, v, n, i)为true。
算法的预准备和准备阶段用于保证所有的正常副本节点就同一视图中的所有请求的顺序达成一致。具体来说,这两阶段能确保以下不变式:
如果prepared(m, v, n, i)为true,则对任意一个正常的副本节点j(包含i)来说,prepared(m', v, n, j)肯定为false,这里m'是不同于m的一个请求。
简单证明如下:
因为prepared(m, v, n, i)为true,而错误节点最多为f个,所以至少有f个正常节点发送了准备消息,再加上主节点,这样至少有f+1个节点已经就m在视图v中被编号为n达成了一致。因此,如果prepared(m', v, n, j)为true,意味着上述f+1个节点中至少有一个节点发送了两个相互矛盾的预准备或准备消息,也就是说,这些消息拥有相同的视图编号和序号,但是对应着不同的请求消息。但这是不可能的,因为该节点是正常节点,因此prepared(m', v, n, j)一定为false。
对于副本节点i来说,prepared(m, v, n, i)变为true,则其将进入commit阶段,如下节所示。
3.2.2.3 commit阶段
commit 阶段流程示意图如下: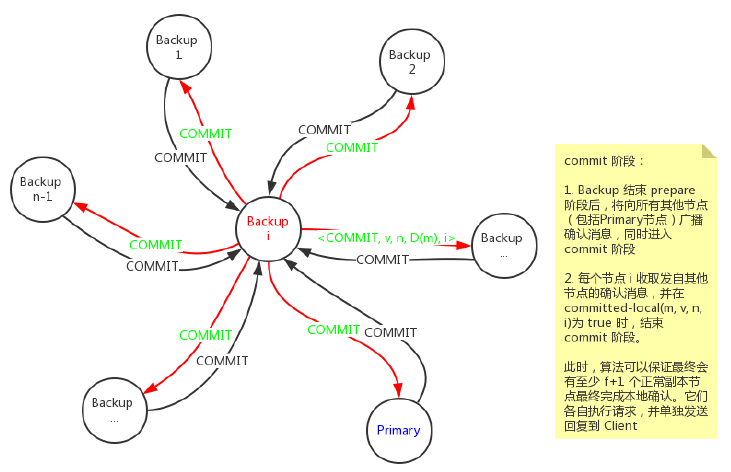
节点进入 commit 阶段时,副本节点i将向其他所有副本节点广播确认消息:
<COMMIT, v, n, D(m), i>,
对于副本节点来说,当其收到其他节点发来的确认消息的时候,会判断其是否满足下列条件:
签名正确;
消息中的视图编号等于当前节点的视图编号;
消息中的请求序号在h和H之间。
如果以上条件均满足,则节点则会接受确认消息并写入本地的日志消息中。
对于副本节点i来说,如果:prepared(m, v, n, i)为true,并且已经接受了 2f+1 个来自不同节点的、和 m 对应的预准备消息相匹配的确认消息(可能包含它自己的)。则我们称 committed-local(m, v, n, i) 为 true。这里确认消息和预准备消息匹配的含义是,它们有相同的视图编号、消息序号,以及消息摘要。
另外,如果至少存在 f+1 个节点,对于其中每一个节点i来说,如果 prepared(m, v, n, i) 为true,我们则称committed(m, v, n) 为 true。
commit 阶段能保证以下不变式:如果对某个副本节点来说,committed-local(m, v, n, i) 为 true,则 committed(m, v, n) s也为true。
上述不变式和视图变更协议一起能够保证:所有正常节点能够就所有本地确认的请求的序号达成一致,即使这些请求是在不同的视图中确认的。对应的证明将在另外一篇文档中给出。
另外,该不变式也能保证:任何一个请求如果在一个副本节点被确认,那么它最终也会被至少 f+1 个副本节点确认。
对于任何一个副本节点i来说,如果:committed-local(m, v, n, i) 为 true,i 的状态反映了所有序号小于 n 的请求顺序执行的结果。此时,它就可以执行 m 所请求的操作。这就保证了所有的正常节点,按相同的顺序执行请求,从而保证算法的安全性。
在执行了请求的操作后,每个节点单独地给客户端发送回复。对于同样内容的请求,节点会忽略那些时间戳更早的,以保证请求只被执行一次。
此外,算法并不要求消息按顺序投递,因此,节点可以乱序确认请求。这样做没有问题,因为算法只在一个请求对应的预准备、准备和确认消息都收集完全时才会执行该请求。
以下是 f=1,即失效节点数为1个,总共节点数为 4个时,PBFT 算法的运行示意图:

4.视图变更、垃圾回收及状态机不确定性
4.1垃圾回收
本部分介绍PBFT算法的垃圾回收机制。
4.1.1 概述
本节介绍从本地日志中删除历史消息的机制。
对算法来说,为了保证安全性,每个副本节点需要保证如下两点:
对于每个请求来说,在被至少f+1个正常节点执行之前,所有相关的消息都必须记录在消息日志中;
同时,如果一条请求被执行,节点能够在视图变更中向其他节点证明这一点。
此外,如果某个副本节点缺失的一些消息正好已经被所有正常节点删除,则需要通过传输部分或全部的服务状态来使节点状态更新到最新。因此,节点需要某种方式来证明状态的正确性。
如果每执行一次操作,都生成一个状态证明,代价将会很大。因此可以每执行一定数量的请求后生成一次状态证明,例如:只要节点序号是某个值比如100的整数倍时,就生成一次,此时称这个状态为检查点。如果一个检查点带有相应的证明,我们则称其为稳定的检查点。
4.1.2 稳定检查点的生成
如上所述,一个带有证明的检查点被称为稳定的检查点,这种证明的生成过程如下:
1、副本节点i生成一个检查点之后,会组装检查点消息,并全网广播给其他所有副本节点,检查点消息格式如下:
<CHECKPOINT, n, d, i>,
这里n指的是生成目前最新状态的最后一条执行请求的序号,d是当前服务状态的摘要。
2、每个副本节点等待并收集 2f+1 个来自其它副本节点的检查点消息(有可能包括自己的),这些消息有相同的序号 n 和摘要 d。这 2f+1 个检查点消息就是该检查点的正确性证明。
一旦一个检查点成为稳定检查点后,节点将从本地消息日志中删除所有序号小于或等于n的请求所对应的预准备、准备和确认消息。同时,会删除所有更早的检查点和对应的检查点消息。
检查点的生成协议可以用来移动低水线 h 和高水线 H:
h的值就是最新稳定检查点所对应的稳定消息序号;
高水线 H = h+k,这里k要设置足够大,至少要大于检查点的生成周期,比如说:假如每隔100条请求生成检查点,k就可以取200。
4.2 视图变更
PBFT算法运行过程中,如果主节点失效了,为了保持系统的活性(liveness),就需要用到视图变更协议。
4.2.1 视图变更的触发
由于主节点失效时,客户端最终会将请求发送到所有其他副本节点。每个节点收到客户端请求后,如果该请求没有执行过,副本节点判断自己是否为主节点,不是的话就会把请求转发给主节点,同时启动一个定时器(假如之前没有启动过的话)。
如果请求在定时器时间间隔内执行完,则节点会停止定时器(不过如果此时节点恰好在等待执行另外一个请求,则会重启定时器);否则,节点会尝试触发视图的变更,具体过程如下节所示。
4.2.2 视图变更协议
对于副本节点i来说,假设其当前所处的视图编号为 v ,经由视图变更协议,从视图 v 变更到 v+1。
视图变更过程中,节点将不再接受其他任何类型的消息,只接受 checkpoint, view-change, 和 new-view 消息。
视图变更过程如下:
1. 节点组装 VIEW-CHANGE 消息并广播给全网其他所有副本节点。
VIEW-CHANGE消息的格式如下:
<VIEW-CHANGE, v+1, n, C, P, i>
消息中的各字段含义如下:
v+1: 要变更到的目标视图编号;
n: 对应于节点已知的、最新的检查点 s 的请求序号;
C:包含 2f+1 个检查点消息的集合。这些检查点消息用于证明检查点 s 的正确性;
P:是一个集合,现在来解释一下其包含的信息。
对于任何一条客户端请求 m ,如果 m 在当前副本节点 i 上已经准备好, 即 prepared(m, v, n', i) 为 true, 并且 n' > n,那么根据定义,节点上已经存储了对应的预准备消息和 2f 个与之匹配的、有效的发自不同的节点的准备消息。这里,匹配的含义是:拥有相同的视图,消息序号以及 m 的摘要。我们把这些预准备
消息和准备消息组成的集合记为 。
P 就是所有 组成的集合。因此,P 包含了所有在副本节点上准备好的、序号大于 n 的请求的预准备和准备消息。在视图变更中,其提供的信息便于在新的视图中重新分配每条请求的消息序号。
2. 每个节点相继广播各自组装的 view-change 消息。同时,新视图中对应的新的主节点将收集来自其他副本节点的 view-change 消息。当其收集到 2f 个有效的 对应新视图 v+1 的 view-change 消息后,将组装并广播 new-view 消息,格式如下:
<NEW-VIEW, v+1, V, O>
其中,V是一个消息集合,包含所有有效的、对应于新视图 v+1 的 2f+1 个 view-change 消息(包括主节点自己组装的)。而 O 则是主节点为各 view-change 消息中包含的、符合要求的请求组装的预准备消息的集合。 O中的消息按如下方式组装:
首先,根据 V 中各条view-change 消息中包含的预准备和准备消息,主节点先找到最新的稳定检查点,将其对应的消息序号赋值给 min-s;然后从所有准备消息中找到最大的那个消息序号,将其赋值给 max-s;
然后,对于min-s 和 max-s 之间的每一个消息序号 n, 主节点为其组装位于视图 v+1 上的预准备消息,这分为两种情况:
a) 在 V 中存在某个或多个 view-change 消息, 它们的 P 集合中的某个集合元素包含的准备消息中包含有对应于序号 n 的消息。
此时,主节点组装的预准备消息如下:
<PRE-PREPARE, v+1, n, d>
其中,d 是V中特定请求消息的摘要,并且该请求在 V 中的一个最新视图上的预准备消息中被分配了序号 n 。
b) 另外一种情况,是 V 中不存在和 n 对应的准备消息。此时,主节点只是模拟为一个特殊的空请求(null request)组装一个预准备消息:
<PRE-PREPARE, v+1, n, D(null)>
其中,D(null) 为空请求的摘要。空请求和其他请求一样进行三阶段协议,但是其执行就是一个空操作(noop)。
3. 主节点广播 new-view 消息后,也会把 O 中的消息写入本地消息日志中。同时,如果主节点本地的最新稳定检查点的消息序号落后于 min-s 的话,则会将 min-s 对应的检查点的证明,也就是相应的检查点消息写入消息日志,并按之前介绍的垃圾回收机制删除所有的历史消息。
4. 此时,主节点正式变更到新视图 v+1, 开始接收消息。
5. 每个副本节点收到针对 v+1 视图的 new-view 消息后,会进行校验,是否满足以下条件:
签名正确;
其中包含的 view-change 消息是针对 v+1 视图,并且有效;
集合 O 中的信息正确、有效。节点判断有效与否的方法是进行类似于主节点生成 O 那样的计算。
如果校验通过,副本节点会将相关信息写入到本地日志中。 同时,针对 O 中的每一条预准备消息,组装并广播对应的准备消息,并且把准备消息写入到本地消息日志中。
此时,副本节点也如同主节点那样,进入到新视图 v+1 中。
之后,在新的视图中,针对所有序号位于 min-s 和 max-s 之间的请求,系统会重新运行三阶段协议。只不过对于每一个副本节点来说,如果当前确认的请求之前已经执行过的话,节点就不再执行该请求。每条被执行的请求,其相关信息会被存储在本地。节点根据这些信息确定请求的执行情况。
以上完成了对视图变更的介绍。
4.2.3 视图变更中节点的信息同步
视图变更时,由于 new-view 消息中并不包含原始的客户端请求,因此副本节点可能缺失某条客户端请求 m ,或者某个稳定的检查点。
此时节点可以从其他副本节点同步缺失的信息。例如,假如节点 i 缺失某个稳定检查点 s ,这个检查点在 V 中可以找到相应的证明,也就是 对应的 checkpoint 消息。由于总共有 2f+1个这样的消息,而错误节点最多 f个,因此至少有 f+1 个正常节点发送过这样的消息。因此,可以从这些正常节点获取到对应的检查点状态。
对于副本复制服务的状态来说,可以通过生成不同的检查点来划分状态。当节点需要同步状态时,只需按检查点来获取即可。这可以避免一次发送整个服务状态。
4.3 关于状态机的不确定性
PBFT算法基于状态机副本复制服务,状态机要求每个节点的状态必须是确定性的。而大多数服务有时会有某种形式的不确定性。例如,对于网络文件系统而言,如果不基于状态机副本复制的话,文件的最后修改时间这个属性可以设置为服务器的本地时间。但如果是每个副本节点独自设置这个时间的话,就会导致各节点状态的不一致。
因此,需要相应机制来确保各节点使用相同的值。一般情况下,这个值不应该由客户端来决定,因为客户端拥有的信息并不完全。例如,多个客户端并发发送请求时,它们并不知晓其请求如何被排序。
可以由主节点来选取这个值,具体有两种方法:
1. 第一种方法适用于大多数服务,由主节点独立选取非确定的值。
主节点将该值和客户端请求拼接在一起,然后运行三阶段协议,确保所有正常节点就请求和该值的序号达成一致。这可以防止出现下列情况:
失效的主节点故意向不同的副本节点发送不同的值,从而使各个节点上的状态出现不一致。
对于这种方法来说,虽然所有正常节点使用相同的值,但这个由主节点发送的值可能是错误的。这种情况下,要求每个副本节点必须能够基于其状态来明确地判断该值的正确性,以及如何处理可能的错误值。
2. 第二种方法是该值的选取由各副本节点一起参与。这种方法要求在三阶段协议基础上额外增加一个阶段:主节点收集各副本节点发过来的、可验证来源的、共计 2f+1 个值,并把这些值和客户端请求拼接在一起,然后运行三阶段协议。 之后,每个副本节点基于这些值和各自的状态进行确定的计算,从而得到所需选取的值。这种计算可以是类似于求中位数等。
5.算法正确性证明及优化
5.1 PBFT算法正确性证明
本部分介绍PBFT算法的正确性证明。
5.1.1 安全性(Safety)证明
PBFT算法提供的安全性(safety)的具体含义是,对于所有本地确认(commit locally)的客户端请求来说,系统中所有正常副本节点都会就这些请求的消息序号达成一致。
上述的“达成一致”,其含义又分为两种:
同一视图中的消息序号一致:对于所有在同一视图中本地确认的客户端请求来说,各正常副本节点就其消息序号会达成一致。
新旧视图中的消息序号一致:对于在新旧视图中本地确认的客户端请求来说,各正常副本节点就其消息序号会达成一致。
接下来分别证明上述两种“一致”是成立的。
1. 在同一视图中,任何一个请求 m ,如果其已经本地确认过,也就是说,至少对于某一个正常副本节点 i 来说,prepared(m, v, n, i) 为 true , 之前已经证明过,此时,对于任意的正常副本节点 j (j也可以是 i) 来说,prepared(m’, v, n, j) 都为 false 。这里 m’ 是不同于 m 的另一个请求,也就是说 D(m’) 不等于 D(m) 。这就意味着对于所有在同一视图中本地确认的客户端请求来说,各正常副本节点就其消息序号会达成一致,第一个性质成立。
2. 现在考虑存在视图变更的情况。首先,在视图 v 中,对于任意一个请求 m 来说,如果其在 某个正常副本节点 i 完成了本地确认,假设其消息序号为 n 。那么,就有 committed(m, v, n) 为 true 。 这也意味着存在一个节点集合R1, 其中至少含有 f+1 个正常副本节点,并且对于其中每一个节点 i ,prepared(m, v, n, i) 为 true。
然后,考虑系统最终变更视图到 v' 的情况。在从视图 v 变更到 v' 的过程中,此时变更没有完成,正常副本节点在接收到 new-view 消息之前,不会接受视图 v' 上的预准备消息。
但是,对于视图 v 变更到 v'的任意一个有效的 new-view 消息来说,其中包含 2f+1 个有效的view-change 消息。这些消息来自不同的副本节点,记它们组成的集合为R2。R1和R2至少有一个相同的元素,也就是相同的节点。不然的话,它们总的节点个数将为(f+1) + (2f+1) = 3f+2,这与我们假定的系统总节点个数 3f+1 不符。
因此,假设这个共同的正常副本节点为 k 。对于请求 m 来说,只有可能存在下面两种情况:new-view 消息中,存在 view-change 消息,其中包含的最新稳定检查点对应的消息序号大于 m 的序号 n 。new-view 消息中所有的 view-change 消息中包含的最新稳定检查点对应的消息序号不大于m的序号n。
对于第一种情况,根据视图变更协议,新视图 v' 中,所有正常副本节点不会接受序号为n或小于n的消息。
对于第二种情况,m 将会被传播到新视图 v'中,因为根据视图变更协议,min-s≤n。视图变更完成后,在 v' 中,算法将针对编号为 n 的请求 m 重新运行三阶段协议。这就使得所有正常副本节点会达成一致,而不会出现下面这种情况:
另一个不同于 m 的请求 m' , 其在视图 v 中分配的序号为 n ,且在新视图中 v' 完成本地确认。
综合上面 1 和 2 的证明,就证明了算法在同一视图和视图变更过程中,都会保证本地确认的请求的序号在所有正常副本节点中会达成一致,从而保证了算法的安全性(safety)。
5.1.2 活性(Liveness)保证
对于PBFT算法来说,为了保证系统的活性(liveness),当节点无法执行客户端请求时,需要变更到新的视图。同时,视图变更也需要进行合理控制,只在需要时才进行,否则频繁的视图变更会影响到系统的活性。这就需要保证以下两点:
系统中至少 2f+1 个正常副本节点处于同一视图中时,这种状态尽可能长时间地保持;
每次视图变更时,上述时间间隔需要快速增长,比如以指数形式增长。
PBFT算法通过如下三种方法来保证上述两点:
1. 为了防止视图变更太快开始,当一个节点发送 view-change 消息后,在等待接收 2f+1 个 view-change消息时,会同时启动定时器,其超时时间设置为 T。如果视图变更没有在 T 时间内完成,或者在新视图中请求没有在该时间间隔内完成,则会触发新的视图变更。此时,算法会调整超时时间,将其设置为原来的两倍,即 2T 。
2. 除了上述的定时器超时触发节点发送 view-change 消息外,当其接收到来自 f+1 个不同节点的有效view-change 消息,并且变更的目标视图大于节点当前视图时,也会触发节点发送 view-change 消息。这可以防止节点过晚启动视图变更。
3. 基于上述第二点的规则,失效节点无法通过故意发送 view-change 消息来触发频繁的视图变更从而干扰系统的运行。因为失效节点最多只能发送 f 条消息,达不到 f+1 的触发条件。失效节点是主节点时,可能会触发视图变更,但是连续的视图变更最多只会是 f 个,之后主节点就是正常节点。因此,基于以上的规则,系统可以保证活性。
5.2 PBFT算法的优化
本部分介绍PBFT算法的优化。这些优化方式应用于算法的正常操作中,可以提升算法的性能,同时可以保持系统的安全性和活性。
5.2.1 减少系统通信量
可以采用三种方法减少系统通信量:
1. 向客户端发送回复的消息摘要,而不是回复的原始内容客户端指定一个特定的副本节点,从该节点接收完整的回复内容,而只从其他所有节点处接收回复的摘要。通过判读摘要与回复的一致性以及对回复计数,可以确保接收到正确的回复。如果客户端接收不到正确结果,就会按正常流程重新请求系统,并接收不同节点的完整回复。
2. 请求在副本节点prepared后,节点即试探性地执行请求,并发送结果。客户端只要收到 2f+1 个匹配的结果,就可以确保该结果的正确性。也就是说,该请求最终会确认(至少f+1 个正常副本节点的本地确认)。如果客户端无法得到正确结果,就重新发送请求,系统执行正常流程。一个被试探性执行的请求,有可能在视图变更过程中被中断,并被替换为一个空请求。此时,已经执行过请求的节点可以通过 new-view 消息中的最新的稳定检查点或本地的检查点来更新状态(取决于哪个序号更大)。
3. 针对只读操作,客户端将请求广播到每一个副本节点。各节点判断请求确实为只读且满足条件后,直接执行请求,并发送回复到客户端。客户端收到 2f+1 个相同的回复,即为正确结果;否则客户端之前设置的重发请求定时器将触发超时,使得客
户端重发请求,系统执行正常流程。
这种优化的前提条件是,副本节点在执行请求之前,需确保之前所有请求都已确认,并且被执行。
5.2.1 加快消息验证速度
使用公钥签名的方式验证消息存在如下不足:
类似于RSA这样的签名算法,签名速度比较慢;
其他公钥密码系统,如椭圆曲线公钥密码系统,虽然签名更快,但是验签更慢。
PBFT算法实际上在正常流程中采用 MAC(Message Authentication Code,消息验证码) 认证消息,因为它具有如下优点,使得算法相对于之前的算法性能提升了一个数量级以上:
MAC 计算速度快;
通过适当优化,可以减少其长度;
通过对authenticator(vector of MAC)的使用,可以使验证时间为常量,而生成时间只随着节点数量线性增长。
具体来说,PBFT算法中使用 MAC 和公钥签名的具体场景是:
所有正常操作流程中使用 MAC 验证消息;
视图变更中的消息:view-change, new-view,以及出现错误时,使用公钥签名。这些场景的出现频率相对较低,从而对算法的性能影响较小。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号