常见共识算法简介
1、Pow工作量证明
本质是谁做的工作多,谁就更有机会获得额外奖励。就是大家熟悉的挖矿,通过与或运算,计算出一个满足规则的随机数,即获得本次记账权,发出本轮需要记录的数据,全网其它节点验证后一起存储;
优点:完全去中心化,节点自由进出;
缺点:目前bitcoin已经吸引全球大部分的算力,其它再用Pow共识机制的区块链应用很难获得相同的算力来保障自身的安全;挖矿造成大量的资源浪费;共识达成的周期较长,不适合商业应用
应用案例:比特币
2、Pos权益证明
Pow的一种升级共识机制;谁持有的币龄时间越长(币龄=持有币的数量*持有币的时间),谁更有机会获取区块的记账权。根据每个节点所占代币的比例和时间;等比例的降低挖矿难度,从而加快找随机数的速度。
优点:在一定程度上缩短了共识达成的时间
缺点:还是需要挖矿,本质上没有解决商业应用的痛点
应用案例:未来币,以太坊采用了Pow+POS的混合机制
3、DPos股份授权证明机制
委托权益证明是让每一个持有比特股的人进行投票,由此产生101位代表 , 我们可以将其理解为101个超级节点或者矿池,而这101个超级节点彼此的权利是完全相等的。持币者投出一定数量的节点,代理他们进行验证和记账。从某种角度来看,DPOS有点像是议会制度或人民代表大会制度。如果代表不能履行他们的职责(当轮到他们时,没能生成区块),他们会被除名,网络会选出新的超级节点来取代他们。
优点:大幅缩小参与验证和记账节点的数量,可以达到秒级的共识验证
缺点:整个共识机制还是依赖于代币,很多商业应用是不需要代币存在的
应用案例:比特股
4、PBFT拜占庭容错算法
这是一种基于消息传递的一致性算法,算法经过三个阶段达成一致性,这些阶段可能因为失败而重复进行。
假设节点总数为3f+1,f为拜赞庭错误节点:
1、当节点发现leader作恶时,通过算法选举其他的replica为leader。
2、leader通过pre-prepare 消息把它选择的 value广播给其他replica节点,其他的replica节点如果接受则发送 prepare,如果失败则不发送。
3、一旦2f个节点接受prepare消息,则节点发送commit消息。
4、当2f+1个节点接受commit消息后,代表该value值被确定
优点:上述共识算法都脱离不了币的存在,系统的正常运转必须有币的奖励机制,系统的安全性实际上是由系统币的持有者维护保证。当我们区块链系统实际运用到商业应用时,由其承载的资产价值可能远远超出系统发行的币的价值,如果由币的持有者保证系统的安全及稳定性将是不可靠的 。
1)系统运转可以脱离币的存在,pbft算法共识各节点由业务的参与方或者监管方组成,安全性与稳定性由业务相关方保证。
2)共识的时延大约在2~5秒钟,基本达到商用实时处理的要求。
3)共识效率高,可满足高频交易量的需求。
应用:央行的数字货币、联盟和私有区块链。
PBFT的限制:
5、Paxos算法
Paxos算法是一种两阶段算法,主要有三类角色,proposer、acceptor、learner,proposer提出议案,acceptor同意或拒绝,learner则是获取达成共识后的最终值。
准备阶段:
proposer 选择一个提案编号 n 并将 prepare 请求发送给 acceptors 中的一个多数派;
acceptor 收到 prepare 消息后,如果提案的编号大于它已经回复的所有 prepare 消息,则 acceptor 将自己上次接受的提案回复给 proposer,并承诺不再回复小于 n 的提案;
批准阶段:
当一个 proposor 收到了多数 acceptors 对 prepare 的回复后,就进入批准阶段。它要向回复 prepare 请求的 acceptors 发送 accept 请求,包括编号 n 和value(如果没有已经接受的 value,那么它可以自由决定 value)。
在不违背自己向其他 proposer 的承诺的前提下,acceptor 收到 accept 请求后即接受这个请求。
Paxos算法适用于简单容错模型,即系统中只可能存在失效或故障节点,不存在恶意节点,如果失效节点数为x,则只需要未失效节点数为x+1就能维持系统的正常工作。
6、Raft算法
Raft算法包含三种角色,分别是:跟随者(follower),候选人(candidate)和领导者(leader)。一个节点在某一时刻只能是这三种状态的其中一种,这三种角色是可以随着时间和条件的变化而互相转换的。
所有的节点初始状态都为follower,超时未收到心跳包的follower将变身candidate并广播投票请求,获得多数投票的节点将化身leader,这一轮投票的过程是谁先发出谁有利,每个节点只会给出一次投票。leader节点周期性给其他节点发送心跳包,leader节点失效将会引发新一轮的投票过程。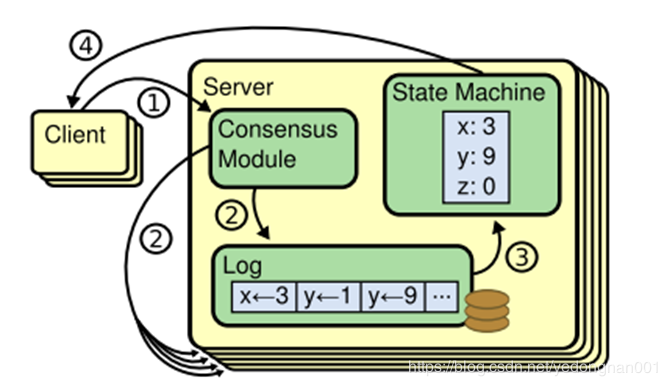
上图描述了一个Raft提案的执行过程:
leader收到客户端发来的请求,写入本地日志,但写入日志的条目在提交状态机之前需要将请求发给所有follower请求验证;
follower对收到的信息进行验证,验证成功后写入本地日志并返回leader验证成功标识;
leader收到大部分的follower节点验证信息后,就会将当前的日志提交,更新节点的值,并广播更新所有follower节点的值,从而再一次达成共识;
Raft算法从节点不会拒绝主节点的请求,并且和Paxos一样只能容错故障或失效节点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号