
面试题集合1
- python
- mysql
- 其他
- django
- drf
- web
- 项目
- redis
- 面试提问
- 1. 脏读,不可重复读,幻读 ,mysql5.7以后默认隔离级别是什么?
- 2.什么是qps,tps,并发量,pv,uv
- 3.什么是接口幂等性问题,如何解决?
- 4 jwt是什么
- 5 什么是gil锁,有什么作用
- 6 python的垃圾回收机制是什么样的
- 7 解释为什么计算密集型用多进程,io密集型用多线程
- 8 Django中的manytomany如何生成第三张表
- 9 value和valuelist
- 10 表 book.object.all 的sql语句,是select * from xxx limit 21 其实是一个生成器,每次生成21条数据,用完继续生成
- 11 python的优缺点
- 12
__getitem____setitem__用起来像字典 - 13 函数和方法的区别
- 14 并发和并行有什么区别
- 15 为什么有了gil锁还要互斥锁
- 15.1 死锁
- 16 进程,线程和协程
- 17 鸭子类型(Duck Typing)
- 18 什么是猴子补丁,有什么用途
- 19 什么是反射,python中如何使用反射
- 20 http和https的区别
- 21 从浏览器输入一个地址,到浏览器返回经历了什么
- 22 左连接,右连接,内连接,全连接:MySQL不能直接支持
- 23 union和union all的区别
- 24 tcp 三次握手和四次挥手
- 25 osi七层协议,哪七层,每层有哪些
- 26 tcp和udp的区别
- 27 wsgi uwsgi uWSGI,cgi,fastcgi 分别是什么?
- 28 如何自定制上下文管理器
- 29 Python是值传递还是引用传递
- 30 迭代器和生成器、装饰器:
- 31 django的信号用过吗?如何用,干过什么
- 32 Dockerfile用过吗?常用命令有哪些
- 33 python为什么一切皆对象
- 34 django 的 orm
- 35 django 的 生命周期
- 36 框架 - 数据库 - redis中间件做缓存 - 锁
- 37 什么是IPC,进程间通信方式有哪些
- 38 什么是正向代理,什么是反向代理
- 39 什么是粘包,如何解决
- 40 Go
- 41 http协议详情,http协议版本,http一些请求头
- 42 如何实现服务器给客户端发送消息,websocket是什么?用过吗
- 43 悲观锁和乐观锁,如何实现
- 44 信号量
- redis与mysql的区别
- redis持久化策略
- null
python
1.猴子补丁:
只有python有猴子补丁,简单来说就是动态的替换。
在不修改源代码的情况下,在运行时动态修改动态对象【一个类或者模块】的行为
虽然猴子补丁技术可以在某些情况下非常有用,但是滥用猴子补丁技术可能会导致代码难以理解和维护
import pymysql
pymysql.install_as_mysqldb() 就是猴子补丁的应用
2.深浅拷贝
在Python中,深拷贝和浅拷贝是常见的复制数据结构的方式,这两种方式在内存中创建副本,但是它们之间的副本方式不同。
① 浅拷贝
浅拷贝只复制对象的顶层数据,对于对象中的嵌套数据,只复制引用,而不是创建新的对象。
如果原始对象发生改变,则新对象也会受到影响。
在Python中,可以使用以下方式进行浅拷贝:
(1)浅拷贝:copy()
new_list = old_list.copy() # for lists
new_dict = old_dict.copy() # for dictionaries
(2)浅拷贝:列表切片
另外,也可以使用切片方式进行浅拷贝:
new_list = old_list[:] # for lists
(3)浅拷贝:list()函数
list(L)
会生成浅拷贝
② 深拷贝
深拷贝则是在内存中创建一个新的对象,包含原始对象的所有嵌套数据。
如果原始对象发生改变,新对象不会受到影响。
(1)深拷贝copy.deepcopy()
在Python中,可以使用以下方式进行深拷贝:
import copy
new_list = copy.deepcopy(old_list) # for lists
new_dict = copy.deepcopy(old_dict) # for dictionaries
需要注意的是,深拷贝会比浅拷贝更耗费内存,因为它需要复制所有的数据结构。在使用时应根据需要进行选择。
3.迭代器和生成器:
迭代器和生成器是常用的处理序列数据的方式。
① 迭代器
迭代器是一个对象,它能够遍历容器中的元素,而不需要暴露容器的内部结构。迭代器具有两个基本方法:__iter__()和__next__()。__iter__()方法返回迭代器本身,__next__()方法返回容器中的下一个元素,如果没有元素则抛出StopIteration异常。可以使用iter()函数将可迭代对象转换为迭代器,例如:
my_list = [1, 2, 3]
my_iterator = iter(my_list)
print(next(my_iterator)) # 输出1
print(next(my_iterator)) # 输出2
print(next(my_iterator)) # 输出3
② 生成器
可以用for循环
生成器是一种特殊的迭代器,它可以通过函数生成序列数据而不需要先将所有数据存储在内存中。生成器使用yield语句来返回数据,yield语句会暂停函数执行并返回一个值,然后在下一次调用时从上一次离开的地方继续执行。例如:
def my_generator():
yield 1
yield 2
yield 3
my_iterator = my_generator()
print(next(my_iterator)) # 输出1
print(next(my_iterator)) # 输出2
print(next(my_iterator)) # 输出3
生成器在处理大量数据时非常有用,因为它们只需要在需要时生成数据,而不是预先生成所有数据。这样可以节省内存,并且能够处理很大的数据集。
4.__init__和__new__有什么区别
__init__和__new__都是用于对象的创建过程,但它们的作用不同。
① __new__
__new__方法是在对象创建之前被调用,它的作用是创建并返回一个新的对象实例。
__new__方法是一个类方法,因此需要传递一个参数cls,表示要创建的类。
__new__方法返回一个新的对象实例,如果不返回,则不会调用__init__方法。
__new__方法可以用于控制对象的创建过程,例如在创建对象之前对其进行修改或验证。
② __init__
__init__方法是在对象创建之后被调用,它的作用是对对象进行初始化。
__init__方法接收一个参数self,表示要初始化的对象实例。
__init__方法通常用于设置对象的初始状态,例如为对象的属性设置默认值。
5.两个字典如何结合到一起
① 字典的update()方法
d1 = {'a': 1, 'b': 2}
d2 = {'c': 3, 'd': 4}
d1.update(d2)
print(d1)
------------
{'a': 1, 'b': 2, 'c': 3, 'd': 4}
② **打散字典,重新构建
d1 = {'a': 1, 'b': 2}
d2 = {'c': 3, 'd': 4}
d3 = {**d1,**d2}
print(d3)
③ for循环
for key, value in d1.items():
# 有相同键则更新,没有则新增键值对
d2[key] = value
print(d2)
6.字典取值 []和get的区别
[]去不到值会报错
get取不到值会返回none,并且可以设置默认值,如果取不到就返回默认值
7.python的字典与hash
字典的实现原理基于哈希表,因此字典也被称为哈希表或关联数组。
在哈希表中,每个键值对被映射到一个唯一的哈希值(即键的哈希值),该哈希值在哈希表中对应一个桶(bucket)。桶中存储了一个链表或其他数据结构,用于存储键值对。
-
所以,字典的键值必须要可哈希
-
python中
- 不可变类型都可hash
- 可变类型都不可hash
8.取不到值怎么做:1 if判断 2 try
10.魔法方法
__init__ 在类加()的时候对象进行初始化
__new__ 在类加() 产生对象 ,触发__init__ 完成独享初始化
__call__ 对象加() 触发
__getattr__ 对象点 .属性, 属性不存在的时候触发
__setattr__ 对象点 .属性=值的时候触发
__getitem__ 对象['属性'] 属性不存在的时候触发
__getitem__ 对象['属性']=值,的时候触发
只要写了__enter__和 __exit__方法,就具备上下文管理的能力
例:
with 对象 as xx:
with中写了一行代码,触发 __enter__的执行
在with下写代码,触发__exit__,做资源清理工作
11.类中的装饰器
@classmethod
@staticmethod
@propoty
12.类中如何隐藏属性
__属性、方法
13.断电续传
文件多线程下载:迅雷
断电续传:
mysql
1.utf8和utf-8 utfmb4有什么区别????
① UTF-8
UTF-8是Unicode字符集的一种编码方式,用于表示Unicode字符集中的字符。UTF-8使用1到4个字节来表示一个字符,其中ASCII字符使用一个字节表示,而其他字符使用2到4个字节。UTF-8编码的最大优势是兼容ASCII编码。
② UTF-8mb4
UTF-8mb4是UTF-8的一种扩展,它支持四个字节的Unicode字符,而UTF-8仅支持三个字节的Unicode字符。
UTF-8mb4用于存储Emoji表情符号,这些表情符号需要四个字节的编码。
UTF-8mb4通常用于MySQL数据库中,以支持存储和查询包含Emoji表情符号的文本数据。
③ MySQL的默认字符
UTF8是MySQL 5.5.3及之前的默认字符集,
UTF8mb4是MySQL 5.5.3及以后版本的默认字符集。如果你需要在MySQL数据库中存储Emoji表情符号,建议使用UTF-8mb4字符集。
2.mysql用本地和用ip地址连接有什么区别
① 本地连接
本地连接:应用程序和MySQL数据库运行在同一台计算机上
本地连接可以通过MySQL的Unix套接字来实现,这种连接方式效率很高,因为数据不需要通过网络传输。在Unix/Linux系统中,MySQL默认使用Unix套接字进行本地连接。
② IP地址连接
IP地址连接:应用程序和MySQL数据库运行在不同的计算机上,实现数据共享和协作
这种连接方式需要通过网络传输数据,因此可能会受到网络延迟和带宽等因素的影响。但是,IP地址连接可以在不同计算机之间实现数据共享和协作。
以下是使用本地连接和使用IP地址连接的一些区别:
- 效率:本地连接的效率比IP地址连接高,因为数据不需要通过网络传输。
- 安全性:本地连接比IP地址连接更安全,因为只有在同一台计算机上运行的应用程序才能访问MySQL数据库。
- 可扩展性:使用IP地址连接可以在不同计算机之间实现数据共享和协作,因此更具有可扩展性。
3.数据库三大范式是什么
数据库三大范式(Normalization)是指设计关系型数据库时需要遵守的一些规则,目的是减少数据冗余和数据更新异常,从而提高数据库的效率和数据的一致性。这三大范式分别为:
第一范式(1NF):确保每列 都是原子的,即不可再分。每个属性都应该具有原子性,不能再分解成更小的数据项。例如,一个“订单”表中的“商品”属性,应该被分解成“商品编号”、“商品名称”、“商品价格”等属性。
第二范式(2NF):确保表中的非主键列完全依赖于主键列。如果一个表的某个非主键列只依赖于主键的一部分,那么这个表就不符合第二范式。例如,一个“订单详情”表中的“商品名称”属性依赖于“商品编号”和“订单编号”,那么这个表就不符合第二范式。
第三范式(3NF):确保表中的非主键列不传递依赖于主键列。如果一个表的某个非主键列依赖于其他非主键列,那么这个表就不符合第三范式。例如,一个“商品”表中的“商品价格”属性依赖于“供应商”属性,那么这个表就不符合第三范式。应该将“商品价格”属性移动到“供应商”表中。
第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据线
每列的值具有原子性,不可再分割。
每个字段的值都只能是单一值
第二范式(2NF)是在第一范式(1NF)的基础上建立起来得,满足第二范式(2NF)必须先满足第一范式(1NF)
如果表是单主键,那么主键以外的列必须完全依赖于主键;
如果表是复合主键,那么主键以外的列必须完全依赖于主键,不能仅依赖主键的一部分。
第三范式(3NF)是在第二范式的基础上建立起来的,即满足第三范式必须要先满足第二范式
第三范式(3NF)要求:表中的非主键列必须和主键直接相关而不能间接相关;也就是说:非主键列之间不能相关依赖
不存在传递依赖
4.mysql有哪些索引类型,分别有什么作用
① 聚簇索引:聚簇索引,聚集索引,主键索引,主键,如果不存在主键,隐藏一个主键,构建聚簇索引
② 辅助索引:普通索引 index
③ 唯一索引: unique
④ 联合索引:组合索引,多列索引:unique_to
# 聚簇索引,聚集索引,主键索引,主键,如果不存在主键,隐藏一个主键,构建聚簇索引
# 辅助索引,普通索引 index
# 唯一索引 unique
# 联合索引,组合索引,多列索引:unique_to
①②③④⑤⑥⑦⑧⑨⑩ ```python
5.事务的特性和隔离级别
事务是指一组操作被当作一个单独的工作单元进行执行,这些操作要么全部完成,要么全部不完成,不会出现部分执行的情况。事务通常具有以下四个特性:
原子性(Atomicity):事务中的所有操作要么全部执行成功,要么全部失败回滚,不会出现部分执行的情况。
一致性(Consistency):事务执行前后,数据库的状态应该保持一致,即数据库在执行事务前后应该满足约束条件、触发器等规则。
隔离性(Isolation):事务执行过程中,对其他事务是隔离的,不会互相影响。
持久性(Durability):事务一旦提交,其结果就是永久性的,即使系统故障,也不会丢失。
隔离级别是指数据库为了实现事务隔离性而采用的一种机制,具体包括以下四个隔离级别:
读未提交(Read Uncommitted):一个事务可以读取另一个事务未提交的数据,容易出现脏读、不可重复读和幻读等问题。
读已提交(Read Committed):一个事务只能读取另一个事务已经提交的数据,避免了脏读问题,但仍可能出现不可重复读和幻读问题。
可重复读(Repeatable Read):一个事务在执行期间多次读取同一数据,保证多次读取的结果一致,避免了不可重复读问题,但仍可能出现幻读问题。
串行化(Serializable):所有事务串行执行,避免了以上所有问题,但会影响系统的并发性能。
不同的隔离级别具有不同的性能和数据一致性的权衡,需要根据具体业务需求进行选择。
其他
1 md5是对称加密还是非对称加密?
(1)什么是对称加密、非对称加密算法
对称加密:加密的秘钥和解密的秘钥是同一个
非对称加密:加密使用公钥加密,解密使用私钥解密,使用公钥是不能解密的
(2)md5是一个摘要算法
摘要算法:没有解密这一说
2 从浏览器输入一个地址,到浏览器返回经历了什么
① DNS解析:
浏览器首先需要解析输入的地址,将其转换为IP地址。浏览器会向DNS服务器发送一个查询请求,以查找域名对应的IP地址。如果DNS服务器有该域名的记录,它将返回对应的IP地址,否则它将向其它DNS服务器发出请求。
② 建立TCP连接:
一旦浏览器知道了IP地址,它将使用TCP协议建立到服务器的连接。浏览器会向服务器发送一个请求,以请求该地址对应的页面。
③ 发送HTTP请求:
一旦TCP连接建立,浏览器会发送一个HTTP请求到服务器,该请求包括请求的页面和请求头信息,例如浏览器类型、支持的字符集和语言等。
④ 服务器处理请求并返回页面:
一旦服务器收到请求,它将处理该请求并返回请求的页面。服务器返回的响应包括状态码、响应头信息和响应内容,例如HTML文件、图像文件或JavaScript文件。
⑤ 浏览器解析HTML:
一旦浏览器收到响应,它将解析HTML代码并构建文档对象模型(DOM)树。浏览器使用CSS和JavaScript等内容来格式化页面并添加交互性。
⑥ 页面加载完成:
一旦浏览器解析HTML、CSS和JavaScript并构建了DOM树,页面加载完成并准备好呈现给用户。
⑦ 断开TCP连接:
一旦页面加载完成,浏览器将断开与服务器的TCP连接,完成请求-响应循环。
3.内网穿透
4.缓存击穿
①②③④⑤⑥⑦⑧⑨⑩ ```python
django
drf
1.form类和modelform的区别
2.serializer和modelserializer的区别
Serializer和ModelSerializer都是用于将Python对象转换为序列化数据(例如JSON)的类。它们之间的主要区别是,ModelSerializer可以自动处理一些与模型相关的工作,从而使编写序列化器变得更加容易和快速。
下面是它们的主要区别:
- 需要手动定义字段:在
Serializer中,必须手动为每个要序列化的字段编写序列化逻辑,而在ModelSerializer中,大多数字段会自动从关联的模型中推断出来。因此,在使用ModelSerializer时,只需要手动定义那些需要定制的字段。 - 内部Meta类不同:在
Serializer中,需要在内部Meta类中指定要序列化的模型和字段。在ModelSerializer中,需要指定要序列化的模型,但大多数字段可以自动推断出来。因此,在使用ModelSerializer时,内部Meta类通常只包含模型类和需要自定义的字段。 - 可以自动创建模型实例:在
ModelSerializer中,可以使用序列化器的create()和update()方法来自动创建和更新模型实例。这些方法会自动处理验证、创建和更新逻辑,从而简化编写序列化器的过程。在Serializer中,需要手动编写这些逻辑。
总之,如果需要序列化与模型相关的数据,使用ModelSerializer可以节省大量时间和代码量,并且可以保持序列化器和模型之间的一致性。如果需要更多的控制和自定义,或者需要序列化与模型无关的数据,使用Serializer可能更合适。
web
1.同源策略
同源策略(Same-Origin Policy,缩写为 SOP)是一种 Web 安全策略,它限制了来自不同源头的文档或脚本如何交互。同源是指同协议、同域名、同端口,只有当这三者都相同时,才被认为是同一来源
同源策略的存在是为了防止恶意网站通过 JavaScript 等方式访问用户的敏感信息,或者以用户身份进行恶意操作。如果没有同源策略的限制,恶意网站可以在用户浏览器中执行任意脚本并访问其他站点的敏感数据。
同源策略的实现方式是在浏览器中设置一个沙箱环境,每个文档或脚本都只能访问自己来源的内容,无法访问其他来源的内容。在浏览器中,同源策略会限制 JavaScript 的 XMLHttpRequest 请求、Cookie 访问、DOM 访问等操作。
同源策略,它是由Netscape提出的一个著名的安全策略。
当浏览器的百度tab页执行一个脚本的时候会检查这个脚本是属于哪个页面的,
即检查是否同源,只有和百度同源的脚本才会被执行。
如果非同源,那么在请求数据时,浏览器会在控制台中报一个异常,提示拒绝访问。
同源策略是浏览器的行为,是为了保护本地数据不被JavaScript代码获取回来的数据污染,因此拦截的是客户端发出的请求回来的数据接收,即请求发送了,服务器响应了,但是无法被浏览器接收。
cors
xss
XSS攻击是一种跨站脚本攻击,它利用了网站中存在的安全漏洞,将恶意代码注入到网页中,使得攻击者可以在受害者浏览器中执行恶意代码。攻击者通常会利用这种漏洞来窃取受害者的敏感信息,例如用户名、密码、信用卡信息等,或者在用户的电脑上植入恶意软件。
XSS攻击通常分为两种类型:存储型XSS攻击和反射型XSS攻击。存储型XSS攻击是将恶意代码存储在服务器端,当用户请求相应的网页时,服务器将恶意代码返回给用户浏览器执行。反射型XSS攻击则是将恶意代码注入到URL参数中,当用户点击带有恶意代码的链接时,服务器将恶意代码返回给用户浏览器执行。
为了防止XSS攻击,网站开发者应该采取以下措施:
1过滤和验证用户输入:开发者应该对用户输入进行过滤和验证,以确保输入的数据是安全的。
2使用安全的编码方式:开发者应该使用安全的编码方式,例如HTML实体编码和JavaScript编码,来防止恶意代码被执行。
3设置HTTP响应头:开发者应该设置HTTP响应头,例如X-XSS-Protection、Content-Security-Policy和X-Content-Type-Options等,来减少XSS攻击的可能性。
4定期更新软件:开发者应该定期更新网站的软件和插件,以确保它们没有已知的漏洞。
5对于存储型XSS攻击,开发者应该采取安全的存储方式,例如使用准确的数据类型和预处理语句来防止SQL注入攻击。
可以使用beautifulsoup4删除js代码
soup = BeautifulSoup(content, 'lxml') # 第二个参数是解析器 不同的解析器功能不一样 最好用的是lxml
tags = soup.find_all()
for tag in tags:
if tag.name == 'script':
tag.decompose() # 删除script标签
csrf
CSRF(Cross-Site Request Forgery)攻击是一种常见的Web安全漏洞,它利用用户已经登录了受信任网站的凭据,通过伪造请求来执行恶意操作。攻击者通过构造伪造请求,使用户在不知情的情况下执行某些操作,比如转账、修改密码等。这些操作可能会导致用户的账户被盗、信息泄露等安全问题。
为了防止CSRF攻击,Web开发人员可以采取以下措施:
1验证来源:在服务器端验证请求的来源,如果不是受信任的来源,拒绝请求。
2验证HTTP Referer头:验证HTTP Referer头,只接受来自正确的来源的请求。
3添加CSRF Token:为每个表单或请求添加一个随机的Token,在服务器端验证Token是否正确,从而防止伪造请求。
4使用验证码:使用验证码来验证请求是否是由真正的用户发起的。
5限制敏感操作:限制敏感操作(比如转账、修改密码等)的访问,并要求用户进行二次验证。
什么是简单请求,什么是非简单请求
2.http协议版本之间的区别
3.如何保证尽量安全token安全
1字符数
http版本区别
-
0.9:底层基于tcp,每次http请求,都是建立一个tcp链接,三次握手,请求结束需要四次挥手
-
1.1 :请求头中有个参数,keep-alive,可以保证多个http请求共用一个TCP链接
-
2.x:多路复用多个请求使用同一个数据包
-
3.x
http和https协议有什么区别
HTTP(Hypertext Transfer Protocol)和HTTPS(Hypertext Transfer Protocol Secure)都是用于在客户端和服务器之间传输数据的协议,但是它们之间有一些关键的区别:
- 安全性:HTTP协议传输的数据是明文,可以被网络中的任何人截取和查看,而HTTPS使用SSL/TLS协议对传输的数据进行加密,保证数据的机密性和完整性,不容易被窃取或篡改。
- 端口号:HTTP协议使用的是80端口,而HTTPS协议使用的是443端口。
- 证书认证:HTTPS使用SSL/TLS证书进行身份验证,确保连接的双方都是可信的,而HTTP没有这个功能。
- 性能:由于加密和解密过程的存在,HTTPS比HTTP协议慢一些,需要更多的计算资源和时间。
总的来说,HTTPS比HTTP更安全,但也更耗费资源。在涉及到数据机密性和完整性比较重要的情况下,应该使用HTTPS协议。
http的get请求和post请求有什么区别
HTTP协议定义了多种请求方法,其中GET和POST是最常见的两种。它们之间的主要区别如下:
- 数据位置:GET请求将请求参数放在URL的query string中,****而POST请求将请求参数放在请求体中。因此,GET请求的数据会在URL中可见,而POST请求的数据则不会显示在URL中。
- 安全性:由于GET请求的数据可见,因此不适合传输敏感信息,例如用户名和密码。而POST请求将数据放在请求体中,因此更适合传输敏感信息。
- 缓存:GET请求可以被缓存,POST请求则不会被缓存。
- 数据长度:由于URL的长度有限制,因此GET请求的数据传输量也受到限制,而POST请求没有这个限制。
- 重复提交:由于GET请求的数据可以被缓存,因此在刷新页面或者回退时可能会出现数据重复提交的情况,而POST请求不会出现这个问题。
- 编码:get请求只可以URL编码,post支持多种编码方式。
- 字符类型:get只支持ASCLL字符,post没有字符类型限制。
- 历史记录:get请求的记录会留在历史记录中,post请求不会留在历史记录。
总的来说,GET请求适合请求数据,POST请求适合提交数据。如果需要传输敏感信息或大量数据,应该使用POST请求。
项目
1 如何提高项目的并发量
1 使用nginx转发(不是直接使用uwsgi接收http请求,使用uwsgi协议)
2 使用性能高的wsgi服务器部署项目(uwsgi,gunicorn)
3 起多个uwsgi+django服务,监听多个端口
4 nginx做负载均衡
5 多台机器上启动多个uwsgi+django服务,nginx做负载均衡
6 动静分离,uwsgi只负责处理动态请求,静态请求直接用nginx去取
7 静态资源(头像,图片),cdn,放到第三方云平台,oss,七牛云,公司自己搭建存储服务器(fastdfs,ceph)
8 页面静态化(首页,秒杀场景秒杀页面),数据同步问题,只要数据库变更了(管理员新增了一个轮播图),静态化的页面需要重新生成(celery使用场景)
9 单台nginx顶不住,高可用keepalive,nginx做集群,F5的硬件负载均衡器,dns负载均衡
2 文件存储
① 之前上传到服务器,放在media文件夹下
② 使用文件服务器托管文件
- 1 第三方托管:阿里云、腾讯云、七牛云
- 2 基于开源服务器自己搭建
- fastDSF 多用于中小型文件
redis
1.redis为什么这么快
① 纯内存操作
② 网络模型使用IO多路复用【可以使处理的请求数更多】
③ 6.x之前单进程,单线程架构,没有线程间切换,更少的资源消耗
面试提问
1. 脏读,不可重复读,幻读 ,mysql5.7以后默认隔离级别是什么?
①脏读
脏读指的是读到了其他事务未提交的数据,未提交意味着这些数据可能会回滚,也就是可能最终不会存到数据库中,也就是不存在的数据。读到了并一定最终存在的数据,这就是脏读。

脏读最大的问题就是可能会读到不存在的数据。比如在上图中,事务B的更新数据被事务A读取,但是事务B回滚了,更新数据全部还原,也就是说事务A刚刚读到的数据并没有存在于数据库中。
从宏观来看,就是事务A读出了一条不存在的数据,这个问题是很严重的。
② 不可重复读
不可重复读指的是在一个事务内,最开始读到的数据和事务结束前的任意时刻读到的同一批数据出现不一致的情况。

事务 A 多次读取同一数据,但事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致。
③ 幻读
所谓幻读指的是当某个事务在读取某个范围内的记录时另外一个事务又在该范围内插入了新的记录,当之前的事务再次读取该范围的记录会产生幻行
举例

mysql5.7以后默认隔离级别是可重复读
MySQL 5.7以后的默认隔离级别是可重复读REPEATABLE READ。在MySQL 5.7以前,默认隔离级别是已提交读READ COMMITTED。这是因为,在可重复读REPEATABLE READ隔离级别下,可以使用基于多版本并发控制(MVCC)的快照读取,从而避免了脏读、不可重复读等问题,因此更为安全和可靠。
2.什么是qps,tps,并发量,pv,uv
- QPS(Queries Per Second):每秒查询率,表示系统每秒钟能够处理的查询次数,是衡量系统性能的一个重要指标。通常用于衡量数据库系统的性能,比如MySQL的QPS指标表示每秒钟可以处理多少个查询请求。
- TPS(Transactions Per Second):每秒事务处理量,表示系统每秒钟能够处理的事务次数。与QPS类似,TPS也是衡量系统性能的重要指标,通常用于衡量事务型系统的性能,比如银行系统的TPS指标表示每秒钟可以处理多少个交易。
- 并发量:指同时在线的用户数量或同时处理的请求数量。在高并发场景中,系统需要能够支持大量的并发请求,因此并发量也是衡量系统性能的一个重要指标。
- PV(Page View):即页面浏览量,表示网站的访问量。每次用户访问网站的一个页面,就会产生一个PV。
- UV(Unique Visitor):独立访客数,表示访问网站的独立用户数量。与PV不同,UV计算的是每个用户访问网站的唯一次数,因此UV通常比PV要小。
这些指标通常用于评估系统的性能和稳定性,也可以用于优化系统的设计和实现,提高系统的吞吐量和性能。需要根据具体业务场景和系统特点来选择合适的指标进行衡量和优化。
3.什么是接口幂等性问题,如何解决?
什么是幂等性
幂等性是系统服务对外一种承诺,承诺只要调用接口成功,外部多次调用对系统的影响是一致的。声明为幂等的服务会认为外部调用失败是常态,并且失败之后必然会有重试。
接口幂等性问题指的是同一请求多次提交会导致数据重复或产生错误的问题。例如,某个接口收到重复的提交请求,可能会导致重复插入数据或重复修改数据,进而导致数据的不一致性。因此,保证接口的幂等性对于系统的正确性和稳定性非常重要。
常见的解决方案包括以下几种:
Token 方案:在每个请求中添加一个唯一的 Token,服务端会记录已经处理的 Token,如果服务端已经处理过相同 Token 的请求,那么服务端就不再重复处理该请求。
接口幂等性过期方案:服务端在处理请求时,可以记录请求处理的时间戳,如果客户端重复提交相同请求,服务端可以判断时间戳是否已过期,如果已过期,则表示该请求已经处理过,服务端不再重复处理。
基于数据库唯一索引的方案:对于需要保证幂等性的接口,可以在数据库中创建唯一索引,确保相同的请求只能被处理一次。
基于 Redis 的方案:在 Redis 中存储请求的唯一标识符,并设置过期时间,如果同样的请求在过期时间内被提交多次,则返回相同的响应结果,避免重复处理请求。
4 jwt是什么
WT(JSON Web Token)是一种基于JSON的开放式标准(RFC 7519),前后端认证的时候,代替了了session-cookies的方式。用于在各方之间安全地传输信息,通常用于身份验证和授权。JWT由三部分组成,分别是头部、载荷和签名:
- 头部(Header):由两部分组成,分别是令牌类型和使用的算法,一般情况下,都是使用HMAC SHA256或RSA算法进行签名。
- 载荷(Payload):存储实际需要传输的数据,可以自定义存储用户信息、权限等内容,需要注意的是,不要在载荷中存储敏感信息,如密码等。
- 签名(Signature):由头部、载荷和密钥生成的签名,用于验证JWT的完整性和真实性,保证JWT不被篡改或伪造。
JWT的优点是简单、轻量、可靠,可以在客户端和服务端之间传输数据,避免了使用传统的cookie或session管理身份验证所带来的跨域问题和无状态性的限制,同时也可以通过设置有效期和刷新机制,增强安全性和可控性。
需要注意的是,JWT虽然增强了安全性和可靠性,但是也需要在使用过程中注意密钥管理和签名验证,以防止信息泄漏和JWT被篡改。同时,在使用JWT时也需要遵循安全最佳实践,如避免在载荷中存储敏感信息、设置适当的过期时间和刷新机制、对JWT进行加密等。
5 什么是gil锁,有什么作用
① 为什么会有锁机制
在多线程情况下共享操作同一个变量时,会导致数据不一致,出现并发安全问题,所以通过锁机制来保证数据的准确和唯一
通过锁将可能出现问题的代码用锁对象锁起来,被锁起来的代码就叫同步代码块,同一时间只能有一个线程来访问这个同步代码块
② 各种锁
https://zhuanlan.zhihu.com/p/489305763
互斥锁:互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。
③ GIL全局解释器锁(Global Interpreter Lock
GIL全局解释器锁(Global Interpreter Lock)是一种用于保证Python线程安全的机制。在CPython解释器中,GIL是一个互斥锁,它会确保在任何时刻只有一个线程在执行Python字节码。这意味着,尽管Python的多线程模块(threading)可以启动多个线程,但这些线程无法真正地并行执行,而只是在单个CPU上轮流执行。因为每个线程都必须获取GIL才能执行Python代码,这可能会导致CPU利用率下降,从而影响Python程序的性能。
另外,在处理I/O密集型任务时,由于GIL只影响CPU密集型任务,多线程仍然可以提高程序的执行效率。
要想了解GIL,首先确定一点:每次执行python程序,都会产生一个独立的进程。例如python test.py,python aaa.py,python bbb.py会产生3个不同的python进程
(1)什么是gil(简单)
GIL本质就是一把互斥锁,是夹在解释器身上的,同一个进程内的所有线程都需要先抢到GIl锁,才能执行解释器代码
GIL锁:保护的是解释器级别的数据
python官方文档对GIL的解释
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.
(2)在CPython中,全局解释器锁(GIL)是一个互斥锁,它可以防止多个本地线程同时执行Python字节码。这个锁是必要的,主要是因为CPython的内存管理不是线程安全的。(然而,自从GIL存在以来,其他特性已经依赖于它强制执行的保证。)
(3)gil与垃圾回收机制
也就是说GIL防止了垃圾回收机制这个线程对数据的不正确回收,GIL只能够确保同进程内多线程数据不会被垃圾回收机制弄乱 ,并不能确保程序里面的数据是否安全
(4)GIL的优缺点
优点:保证Cpython解释器内存管理的线程安全
缺点:同一个进程内所有的线程同一时刻只能有一个执行,也就是说Cpython解释器的多线程无法实现并行,无法取得多核优势
可以肯定的一点是:保护不同的数据的安全,就应该加不同的锁。
6 python的垃圾回收机制是什么样的
Python中的垃圾回收机制是自动的,即Python解释器会自动检测和清理不再使用的内存对象。Python中的垃圾回收机制主要通过引用计数和循环垃圾回收两种方式实现。
① 引用计数
引用计数reference count
定义:引用计数是计算机编程语言中的一种内存管理技术,是指将资源(可以是对象、内存或磁盘空间等等)的被引用次数保存起来,当被引用次数变为零时就将其释放的过程。使用引用计数技术可以实现自动资源管理的目的。同时引用计数还可以指使用引用计数技术回收未使用资源的垃圾回收算法。
简单来说,一个数据被引用时,其引用计数则会+1,而当其引用次数变为0时,将会把这个数据值当作垃圾删除掉。
也就是说,引用计数代表了一个数据值被需要的程度,当不被需要时,该数据则自动变成"垃圾"被清理掉了
- 引用计数的缺点
1)频繁更新引用计数会降低运行效率
2)原始的引用计数无法解决 循环引用问题
② 循环垃圾回收
标记清除 ==>解决循环引用占用内存
当内存占用达到临界值的时候 程序会自动停止 然后扫描程序中所有的数据,并给只产生循环引用的数据打上标记 之后一次性清除
③ 垃圾回收机制的分代回收
由于扫描标记数据会占用cpu的性能,所以垃圾回收机制也将更多的时间聚焦于引用计数更少的老年代数据
将这些对象分为不同的代,然后针对每个代使用不同的回收策略,从而提高垃圾回收的效率。
一般将所有对象分为三代:第0代包含最新创建的对象,第1代包含一些存活时间较长的对象,第2代包含最老的对象。
7 解释为什么计算密集型用多进程,io密集型用多线程
① 计算密集型任务是指那些需要大量CPU资源的任务,如图像处理、数据分析等。这类任务需要进行大量的计算,因此往往需要使用多进程来提高并行计算能力。多进程可以充分利用多核CPU的资源,同时还可以避免全局解释器锁(GIL)的问题,从而使得程序可以在多个进程之间并行运行,提高程序的执行效率。
② IO密集型任务是指那些需要进行大量IO操作的任务,如网络请求、文件读写等。这类任务中的大部分时间都是在等待IO操作完成,因此使用多线程来同时处理多个IO操作可以提高程序的效率。由于在进行IO操作时会释放GIL,因此可以通过多线程来实现并行IO操作,从而使得程序可以更快地完成任务。
8 Django中的manytomany如何生成第三张表
9 value和valuelist
10 表 book.object.all 的sql语句,是select * from xxx limit 21 其实是一个生成器,每次生成21条数据,用完继续生成
11 python的优缺点
12 __getitem__ __setitem__用起来像字典
13 函数和方法的区别
(1)函数和方法的区别
有自动传值才是方法,不然就是普通函数
① 函数:就是普通的函数,有几个参数就会传几个参数
② 方法:绑定给对象的方法,绑定给类的方法,绑定给谁,由谁来调用,会自动将自身传入
(2)绑定给类的方法 和 绑定给对象的方法
- 类的绑定方法:会自动把类传入,对象可以调用,
- 对象的绑定方法,类可以来调用:但是就变成普通函数了,需要几个值就要传几个值
| @classmethod:绑定给类的方法 | 绑定给对象的方法:实例方法 | @staticmethod:静态方法 | |
|---|---|---|---|
| 对象是否可以调用 | 所有对象都可以调用,并将【类cls】自动传入 | 对象可以调用,并将【对象自己】自动传入,self该参数会在方法被调用时自动传递当前对象的引用 | 普通函数,需要手动传值 |
| 类是否可以调用 | 类可以调用 | 不能通过类调用,该方法变为普通函数,需要手动传值 | 普通函数,需要手动传值 |
MethodType判断是否是类的方法,FunctionType
rom types import MethodType, FunctionType
class Foo(object):
def fetch(self):
pass
def say_hello(self, word):
print(word)
@classmethod
def test(cls, a):
print(cls)
print(a)
@staticmethod
def test1():
pass
obj = Foo()
obj.test(1)
Foo.say_hello(obj,'nihao')
# obj.say_hello = lambda :print('hello')
# 1 类调用对象的方法
print(isinstance(Foo, MethodType)) #False 调用对象的绑定方法,该方法就变成了普通函数,需要手动传值
# 2 对象调用对象的方法
print(isinstance(obj.say_hello,MethodType)) # True
# 3 对象调用类的方法
print(isinstance(obj.test, MethodType)) # True
# 4 类调用类的方法
print(isinstance(Foo.test,MethodType)) # True
14 并发和并行有什么区别
① 并发(Concurrency)
并发指的是多个任务交替进行,即在同一时间段内执行多个任务,但不一定同时执行。例如,在一个单核CPU上,通过操作系统的时间片轮转调度,可以实现多个应用程序之间的并发执行。
② 并行(Parallelism)
并行则指的是多个任务同时执行,即在同一时刻,通过多个CPU或多核CPU同时处理多个任务。例如,在一个有多个核心的CPU上,可以同时运行多个线程或进程,实现多个任务的并行执行。
可以说并行是一种更高效的并发,通过利用多核CPU等硬件资源,可以实现更快的任务处理速度。但是,并发和并行都是在多个任务之间共享计算资源的方法,只是在具体实现方式上有所不同。
15 为什么有了gil锁还要互斥锁
① gil不能保证程序中的数据是否安全
全局解释器锁(Global Interpreter Lock,简称GIL)是Python解释器中的一个机制,用于保证同一时间只有一个线程能够执行Python字节码。
虽然GIL可以保证Python代码的线程安全性,防止了垃圾回收机制这个线程对数据的不正确回收,并不能确保程序里面的数据是否安全
② 互斥锁是线程同步机制
它可以保证同一时间只有一个线程能够访问共享资源,避免了多个线程同时访问同一资源时可能会出现的数据竞争(Data Race)问题,保证了线程安全。
比如:在需要对共享资源进行读写操作时,就可以使用互斥锁来保证多线程之间的并发执行,提高程序的性能。
所以在需要进行CPU密集型的任务时,为了充分利用多核CPU,就需要使用互斥锁。
15.1 死锁
死锁(Deadlock)是指多个进程或线程在等待其他进程或线程所持有的资源时,导致所有进程或线程都无法继续执行的一种情况。这种情况下,进程或线程会互相等待对方释放资源,从而导致所有进程或线程都被阻塞,无法完成其任务,进而导致系统资源的浪费和性能的降低。
死锁的产生通常需要满足四个条件,即:互斥条件、请求与保持条件、不剥夺条件和循环等待条件。其中互斥条件指同一时间只能有一个进程或线程访问共享资源;请求与保持条件指进程或线程在持有资源的同时,又请求其他进程或线程所持有的资源;不剥夺条件指进程或线程所持有的资源不能被强制剥夺;循环等待条件指多个进程或线程形成一个环形等待其他资源的序列。
为了解决死锁问题,可以采取以下措施:
-
预防死锁:通过避免或减少上述四个条件的出现,可以预防死锁的发生。
-
避免死锁:通过动态地分配资源,避免进程或线程在等待资源时产生死锁。
-
检测死锁:周期性地检测系统中是否存在死锁,并通过抢占资源或撤销进程或线程来解除死锁。
-
解除死锁:当检测到死锁时,通过抢占资源或撤销进程或线程来解除死锁,使系统恢复正常。
总之,死锁是一种非常严重的问题,需要开发人员在编写程序时充分考虑并采取相应的预防措施,以避免或减少死锁的发生。
16 进程,线程和协程
① 进程
进程是程序关于某个数据集合上的一次运行活动,是操作系统资源分配的最小单位,每个进程都有独立的内存空间和系统资源,同一台计算机上的多个进程数据上严格意义上的物理隔离(默认情况下),也就是说默认情况下进程之间无法互相传递信息,进程之间通过进程间通信(IPC)进行交互。
在Python中,可以使用multiprocessing模块来创建新的进程,示例如下:
from multiprocessing import Process
import time
def task(a, b):
print('开始', a)
time.sleep(2)
print('结束', b)
class MainProcess(Process):
def __init__(self, s_arg, e_arg):
super().__init__()
self.s_arg = s_arg
self.e_arg = e_arg
def run(self):
print('开始', self.s_arg )
time.sleep(2)
print('结束', self.e_arg)
if __name__ == '__main__':
# 多进程
# p1 = Process(target=task, args=(1111, 2222))
#
# p1.start()
#
# p2 = Process(target=task, args=(3333, 4444))
#
# p2.start()
# 子进程
sub_pro1 = MainProcess(111, 222)
sub_pro2 = MainProcess(33333, 444444)
sub_pro1.start()
sub_pro2.start()
print('主进程')
1.创建进程,用multiprocessing模块
2.子进程:使用类继承Process类,来创建子进程,传参问题:利用__init__实例化方法和super派生方法传参
3.进程的join方法:让主进程代码等待子进程代码运行结束再执行**
4.同一台计算机上的多个进程数据上严格意义上的物理隔离(默认情况下),也就是说默认情况下进程之间无法互相传递信息
② 线程
线程是进程中的一条执行路径,是操作系统调度的最小单位,多个线程可以共享进程的资源,例如内存空间、文件句柄等。
进程:进程其实是资源单位,表示一块内存空间
线程:线程才是执行单位,表示真正的代码指令
在Python中,可以使用threading模块来创建新的线程
"1 Thread直接生成线程对象,传入任务"
from threading import Thread, get_ident
import time
common_data = 99
def task(arg):
global common_data
common_data = arg
time.sleep(2)
print('线程号:%s' % get_ident(), common_data)
for i in range(10):
t = Thread(target=task, args=(i,))
t.start()
"2 继承Thread类创建线程"
class MyThread(Thread):
def run(self):
print('run is running')
time.sleep(1)
print('run is over')
obj = MyThread()
obj.start()
print('主线程')
1.多进程的速度比多线程慢很多,也就是说对于计算机来说,创建进程的资源消耗比线程大的多。
2.线程对象的其他方法
| 方法 | 作用 |
|---|---|
join() |
让主线程在子线程结束后在运行 |
| active_count | 统计当前正在活跃的线程数 |
| current_thread | 查看主线程名字 |
③ 协程
协程是一种轻量级的线程,它是用户自己调度的,不需要操作系统进行切换。
协程可以在一个线程中实现多个子任务的并发执行,使用协程可以避免线程切换和锁竞争等开销,从而提高程序的执行效率,多个协程也相对独立,但是其切换由程序自己控制。
避免了传统的多线程或多进程编程中可能遇到的线程切换、上下文切换等问题。
如通过协程实现检测io操作,这样通过协程来运行两个函数只用了2 秒
import time
from gevent import monkey, spawn
# 1 固定编写,用于检测所有的io操作,对所有的IO和耗时操作打补丁
monkey.patch_all()
# 编写io操作函数
def func1():
print('func1 running')
time.sleep(2)
print('func1 over')
def func2():
print('func2 running')
time.sleep(2)
print('func2 over')
if __name__ == '__main__':
start_t = time.time()
# 2 创建协程对象
s1 = spawn(func1)
s2 = spawn(func2)
# 3 join方法 可以使得单个协程对象执行结束
s1.join()
s2.join()
print(time.time()-start_t)
-
asyncIO
async/await 语法来进行挂起和恢复,从而实现非阻塞 IO 操作
17 鸭子类型(Duck Typing)
是python中一种接口的思想,它在运行时根据对象的属性和方法来判断对象是否符合特定的接口。
鸭子类型关注的是对象的行为,而不是对象的类型或类。不需要关心对象的具体类型或类,只需要保证对象具有指定的属性和方法即可。
因此,鸭子类型可以提高代码的灵活性,允许不同类型的对象在同一个函数或方法中使用。
可以使用鸭子类型来实现参数类型的灵活性
18 什么是猴子补丁,有什么用途
猴子补丁(Monkey Patching)是指在运行时动态修改代码的技术。****只有python有猴子补丁
① 用途1:内置的json模块替换成ujson
python内置的json模块,效率较低,而第三方模块ujson的效率高。我们可以将已经写到的程序的入口处中使用猴子补丁,将json模块替换成ujson
import ujson as json
② 用途2:django中pymysql的替换
由于django默认使用的是 sqldb,而我们使用mysql连接数据库的时候,使用pymysql模块就是使用了猴子补丁的技术
import pymysql
pymysql.install_as_mysqldb() 就是猴子补丁的应用
③ 用途3:gevent模块中,monkey.pach_all()
在使用gevent模块中,最开始的固定编写monkey.patch_all(),用于检测所有的io操作,对所有的IO和耗时操作打补丁
动态的替换了内部会阻塞的代码【io操作和阻塞】,在其内部将time、socket、os模块都进行了重写为并发版本,当检测io密集型操作等待结果的时候能够不释放gil锁。
同步代码:io操作的时候阻塞,python解释器会释放gil锁,那么这条线程就会被释放cpu的执行
异步代码:遇到io操作,不释放gil锁,而是进行任务的切换
19 什么是反射,python中如何使用反射
反射(Reflection)是指程序在运行时可以访问、检测和修改其本身状态或行为的能力。
Python中是指:在程序运行时,利用字符串操作对象的数据和方法,这就是Python中的反射。
Python中的反射主要有以下三个内置函数:
-
hasattr(object, name):检查对象是否有指定的属性或方法,返回布尔值。 -
getattr(object, name[, default]):获取对象的指定属性或方法,如果不存在则返回默认值(如果提供了默认值)或者抛出AttributeError异常。 -
setattr(object, name, value):给对象设置指定属性或方法的值。 -
delattr:删除一个实例或者类中的方法
20 http和https的区别
HTTP 协议通常承载于 TCP 协议之上,在 HTTP 和 TCP 之间添加一个安全协议层(SSL 或TLS),这个时候,就成了我们常说的 HTTPS.
HTTP:超文本传输协议和HTTPS:安全的超文本传输协议,都是用于在客户端和服务器之间传输数据的协议HTTP协议属于应用层协议
-
安全性:
- HTTP协议传输的数据是明文,可以被网络中的任何人截取和查看,
- HTTPS使用SSL/TLS协议对传输的数据进行加密,保证数据的机密性和完整性,不容易被窃取或篡改。
-
端口号:
- HTTP协议使用的是80端口
- 而HTTPS协议使用的是443端口
-
证书认证:
- HTTPS使用SSL/TLS证书进行身份验证,确保连接的双方都是可信的
- HTTP没有这个功能
-
性能:
由于加密和解密过程的存在,HTTPS比HTTP协议慢一些,需要更多的计算资源和时间。
21 从浏览器输入一个地址,到浏览器返回经历了什么
① DNS解析:
浏览器首先需要解析输入的地址,将其转换为IP地址。
浏览器会向DNS服务器发送一个查询请求,以查找域名对应的IP地址。如果DNS服务器有该域名的记录,它将返回对应的IP地址,否则它将向其它DNS服务器发出请求。
解析顺序:浏览器缓存 --> 本机缓存--> 本地host文件-->DNS服务器
② 建立TCP连接(三次挥手):
一旦浏览器知道了IP地址,它将使用TCP协议建立到服务器的连接。浏览器会向服务器发送一个请求,以请求该地址对应的页面。
③ 发送HTTP请求:
一旦TCP连接建立,浏览器会发送一个HTTP请求到服务器,该请求包括请求的页面和请求头信息,例如浏览器类型、支持的字符集和语言等。
④ 服务器处理请求并返回页面:
一旦服务器收到请求,它将处理该请求并返回请求的页面。服务器返回的响应包括状态码、响应头信息和响应内容,例如HTML文件、图像文件或JavaScript文件。
⑤ 浏览器解析HTML:
一旦浏览器收到响应,它将解析HTML代码并构建文档对象模型(DOM)树。浏览器使用CSS和JavaScript等内容来格式化页面并添加交互性。
⑥ 页面加载完成:
一旦浏览器解析HTML、CSS和JavaScript并构建了DOM树,页面加载完成并准备好呈现给用户。
⑦ 断开TCP连接(四次挥手):
一旦页面加载完成,浏览器将断开与服务器的TCP连接,完成请求-响应循环。
22 左连接,右连接,内连接,全连接:MySQL不能直接支持
inner join:只连接两张表中共有的数据
left join:以关键字left join左表数据为基准,展示左表所有数据,如果右表中没有对应的数据项,则以null填充
right join:以关键字right join右表数据为基准,展示右表所有数据,如左表没有对应的数据项,则以null填充
全连接用union来代替
23 union和union all的区别
union会过滤重复的结果
union all不过滤重复的结果用来合并 SELECT 语句的结果集,并保留其中的重复记录
24 tcp 三次握手和四次挥手
TCP与UDP协议规定通信方式(数据交互的方式),彼此之间通信要有通信的通道,双方都必须能和对方发消息
TCP 是一种面向连接的传输协议,可靠传输,TCP数据包没有长度限制,,它使用三次握手来建立连接、四次挥手关闭连接
① 三次握手建链接:
- TCP协议也称为可靠协议,数据不容易丢失,造成数据不容易丢失的原因不是因为有双向通道,根本原因是因为有反馈机制。
2.反馈机制
3.洪水攻击:同一时间有大量的客户端请求建立链接,会导致服务端一直处于SYNZ_RCVD状态(避免洪水攻击,可以在服务端前建立缓冲池,分流用户请求)
4.服务端如何区分建立链接的请求:seq = x 表示不同的客户端请求的标识,区分不同的客户端请求


② 四次挥手断链接:
1.步骤2和步骤3不能合并为一步,因为中间需要确认消息是否发完(时间等待期TIME_WAIT)

25 osi七层协议,哪七层,每层有哪些

(1) osi七层协议规定的内容概括:
1)所有的计算机在远程数据交互的时候必须经过相同的处理流程
2)计算机在制造过程中必须拥有相同的功能硬件
(2)哪七层
物理层,数据链路层,网络层,传输层,会话层,表示层,应用层
简化成五层tcp/ip

(3)常见协议
① 物理层:定义了数据传输所需的物理介质和特性
② 数据链路层:作用是将数据帧转换成而二进制位
以太网协议:规定了计算机在出厂的时候都必须有一块网卡,网卡上有一串数字MAC地址;该数字相当于上计算机的身份证号码是独一无二的不可改变的
MAC地址是物理地址,可以看成是永远无法修改的
IP地址是动态分配的,不同的局域网内IP地址是不同的
③ 网络层:
1)ip协议:规定了所有接入互联网的计算机都必须有一个IP地址
2)arp协议:查询IP地址和MAC地址的对应关系
3)路由协议:不再一个子网内,以太网会将数据包转发给本网的网关进行路由转发
④ 传输层:提供端对端的通信管理
1)PORT协议(端口协议):给应用程序分配端口号
端口号的范围:0-65535
端口号:0-1023 系统默认需要使用
端口号:1024-8000 常见软件的端口号
2)TCP与UDP协议:TCP与UDP协议规定通信方式(数据交互的方式),彼此之间通信要有通信的通道,双方都必须能和对方发消息
-
tcp协议:可靠传输,当客户和服务器彼此交换数据前,必须先在双方之间建立一个TCP连接,之后才能传输数据。
根本原因是因为有反馈机制。
-
不可靠协议,也称为数据报协议。UDP不提供可靠性,它只是把应用程序传给IP层的数据报发送出去,但是并不能保证它们能到达目的地。
早期的QQ使用的是纯生的UDP协议,现在的QQ自己添加了很多技术和功能
⑤ 会话层
会话层是用户应用程序和网络之间的接口
⑥ 表示层
处理用户信息的表示问题,如编码、数据格式转换和加密解密等
⑦ 应用层
它是计算机用户,以及各种应用程序和网络之间的接口,该层的主要功能是:直接向用户提供服务,完成用户希望在网络上完成的各种工作
http协议
26 tcp和udp的区别
TCP(Transmission Control Protocol)和UDP(User Datagram Protocol)是两种常见的传输层协议,它们之间有以下几个不同点:
① 连接性:
TCP 是面向连接的协议,UDP 是无连接的协议。TCP 在通信前需要建立连接,而 UDP 直接发送数据包。
② 可靠性:
TCP 提供可靠的传输服务,具有数据传输的完整性、有序性和可靠性,能够检测丢失、重复和损坏的数据,进行重传。
UDP 不保证数据传输的可靠性,可能存在丢失、重复或者损坏的数据,也不进行重传。
③ 延迟:
TCP 的可靠性服务需要进行数据包的确认、重传等处理【反馈机制】,导致数据传输的延迟较大,适合要求数据可靠性的应用场景。
UDP 没有数据确认和重传的机制,数据传输的延迟较小,适合对数据实时性要求高的应用场景。
④ 流量控制:
TCP 提供流量控制机制,避免数据包的丢失和拥塞,调节发送和接收数据的速度,保证网络的稳定性和可靠性。
UDP 没有流量控制机制,可能会导致数据包的拥塞和丢失。
TCP 适合:网页浏览、文件传输等,http协议就是基于tcp之上;
UDP 适合:实时视频、语音通话等
dns就用到了udp协议,早期的qq也是udp协议
27 wsgi uwsgi uWSGI,cgi,fastcgi 分别是什么?
-
CGI(Common Gateway Interface)通用网关接口:CGI描述了服务器(nginx,apache)和请求处理程序(django,flask,springboot这些web框架)之间传输数据的一种标准
所有的 bs框架软件都是遵循CGI协议的
一句话总结:一个标准,定义了客户端服务器之间如何传输数据
-
FastCGI:快速通用网关接口Fast Common Gateway Interface/FastCGI)是一种让交互程序与Web服务器通信的协议
FastCGI是早期通用网关接口(CGI)的增强版本
常见的fastcgi服务器:Apache,Nginx,Microsoft IIS
一句话总结:CGI的升级版
-
WSGI:Python Web Server Gateway Interface,缩写为WSGI,Python定义的Web服务器和Web应用程序或框架之间的一种通用的接口。
一句话总结: 为Python定义的web服务器和web框架之间的接口标准
-
uwsgi:uWSGI服务器实现的独有的协议,用于定义传输信息的类型,是用于前端服务器与 uwsgi 的通信规范
一句话总结: uWSGI自有的一个协议
- uWSGI:web服务器,等同于wsgiref
- uwsgi:uWSGI自有的协议
-
uWSGI:符合wsgi协议的web服务器,用c写的,性能比较高,咱们通常用来部署django,flask
一句话总结:一个Web Server,即一个实现了WSGI协议的服务器,处理发来的请求及返回响应。
1.1 符合WSGI协议的web服务器
- wsgiref,werkzeug(一个是符合wsgi协议的web服务器+工具包(封装了一些东西))
- uWSGI 用c语言写的,性能比较高
1.2 web服务器到底是什么?服务器中间件
① 服务器中间件
客户端(浏览器,app) 跟 服务端(web框架)之间的东西,服务器中间件
② 常见的web服务器到底是什么
-
nginx apache 是一类东西,就是做请求转发
-
uWSGI,gunicorn 只针对于python的web框架
-
tomcat,jboss,weblogic 只针对java的web框架
28 如何自定制上下文管理器
(1)作用
上下文管理器(context manager)是Python中一个很有用的特性,它允许程序员在代码块的进入和退出时执行一些特定的操作。
比如文件、网络连接、数据库连接或使用锁,数据库使用事务的编码场景等
上下文管理器通常使用with语句来调用,例如:
with open('file.txt', 'r') as f:
# do something with the file
(2)如何自定制
一个对象如果实现了__enter__和__exit__方法,那么这个对象就支持上下文管理协议,即with语句
class MyContextManager:
def __enter__(self):
# 进入上下文时执行的代码
print("进入with语句块时,执行此方法,如果有返回值,会赋值给 as 声明的变量")
self.session=session
return session
def __exit__(self, exc_type, exc_val, exc_tb):
# 退出上下文时执行的代码
print("退出with代码时,执行的代码")
self.session.close()
# 使用自定义的上下文管理器··
with MyContextManager() as session:
session.filter()...
print("上下文管理器结束时哟个")
注意,如果在with代码块中抛出了异常,Python会将异常类型、异常值和追溯信息作为参数传递给__exit__()方法。如果__exit__()方法返回True,则表示异常已被处理;否则,异常将被抛出。
29 Python是值传递还是引用传递
Python既不是纯粹的值传递(pass by value)也不是纯粹的引用传递(pass by reference),
在Python中,变量存储的是对象的引用(内存地址),而不是对象本身。
对于不可变对象(如数字、字符串、元组等),我们可以将其视为值传递。函数内部对其进行的任何修改都不会影响函数外部的变量。
对于可变对象(如列表、字典等),我们可以将其视为引用传递。因此,函数内部对该对象的任何修改都会影响函数外部的变量。
下面是一个示例:
def func(a_list):
a_list.append(4)
print(a_list)
my_list = [1, 2, 3]
func(my_list)
print(my_list)
----
[1, 2, 3, 4]
[1, 2, 3, 4]
30 迭代器和生成器、装饰器:
迭代器和生成器是常用的处理序列数据的方式。
可迭代对象:可以被for循环
迭代器对象:可迭代对象调用 iter()方法
① 迭代器
迭代器是一个对象,不依赖索引取值,通过迭代取值的方案,可以节省内存
迭代器具有两个基本方法:__iter__()和__next__()。
__iter__()方法将可迭代对象转换为迭代器
__next__()方法返回容器中的下一个元素,如果没有元素则抛出StopIteration异常。
可以使用iter()函数将可迭代对象转换为迭代器,例如:
my_list = [1, 2, 3]
my_iterator = iter(my_list)
print(next(my_iterator)) # 输出1
print(next(my_iterator)) # 输出2
print(next(my_iterator)) # 输出3
② 生成器
有yield关键字的函数,使用yield语句来返回数据,那么函数名加括号()的结果就是生成器,生成器内置有__iter__和__next__ 方法,所以生成器本身就是一个迭代器
生成器中,yield语句会暂停函数执行并返回一个值,然后在下一次调用时从上一次离开的地方继续执行。例如:
def my_generator():
yield 1
yield 2
yield 3
my_iterator = my_generator()
print(next(my_iterator)) # 输出1
print(next(my_iterator)) # 输出2
print(next(my_iterator)) # 输出3
生成器在处理大量数据时非常有用,因为它们只需要在需要时生成数据,而不是预先生成所有数据。这样可以节省内存,并且能够处理很大的数据集。
-
应用:爬虫,redis缓存
-
对比return可以返回多次值、可以挂起保存函数的运行状态
③ 装饰器
装饰器:在不改变原函数的基础上,对函数执行前后进行自定义操作。把目标函数作为参数传给装饰器函数,装饰器函数执行过程中,执行目标函数,达到在目标函数运行前后进行自定义操作的目的。
装饰器本质上是一个闭包函数,【定义在函数内部,使用了外部作用域变量的函数,叫做闭包函数】
-
应用:当我们记录日志的时候,执行某函数、给某个功能添加日志。记录函数运行时间;flask里的路由、before_request请求拓展;django中的缓存、用户登录等。
-
加载顺序自下而上,执行顺序自上而下
31 django的信号用过吗?如何用,干过什么
Django信号是一种事件触发机制,可以让应用程序中的不同部分之间进行通信。
Django中的信号可以在数据库操作、HTTP请求处理等场景下使用。
(1) django的内置信号
Model signals
pre_init # django的modal执行其构造方法前,自动触发
post_init # django的modal执行其构造方法后,自动触发
pre_save # django的modal对象保存前,自动触发
post_save # django的modal对象保存后,自动触发
pre_delete # django的modal对象删除前,自动触发
post_delete # django的modal对象删除后,自动触发
m2m_changed # django的modal中使用m2m字段操作第三张表(add,remove,clear)前后,自动触发
class_prepared # 程序启动时,检测已注册的app中modal类,对于每一个类,自动触发
Management signals
pre_migrate # 执行migrate命令前,自动触发
post_migrate # 执行migrate命令后,自动触发
Request/response signals
request_started # 请求到来前,自动触发
request_finished # 请求结束后,自动触发
got_request_exception # 请求异常后,自动触发
Database Wrappers
connection_created # 创建数据库连接时,自动触发
(2)django中使用内置信号
第1步:写一个函数,由于信号触发时,会自动传入一些参数,所以该函数的参数最好写成 *args, **kwargs
第2步:绑定内置信号
第3步:等待被触发
1 写一个函数
def callBack(*args, **kwargs):
print(args)
print(kwargs)
2 绑定信号
#方式一
post_save.connect(callBack)
# 方式二
from django.db.models.signals import pre_save
from django.dispatch import receiver
@receiver(pre_save)
def my_callback(sender, **kwargs):
print("对象创建成功")
print(sender)
print(kwargs)
3 等待触发
比如在数据库的数据创建后,可以用django内置的信号来执行一些自定义的逻辑,比如发送记录日志等等
Django的信号机制非常强大和灵活,可以应用在很多场景中,例如数据同步、缓存更新、发送邮件等。在我的实际项目中,我曾经使用信号来监听用户上传文件、更新缓存等操作,并在这些操作完成后触发相应的事件,从而实现了一些自动化的操作。
32 Dockerfile用过吗?常用命令有哪些
Dockerfile是一种用于定义Docker镜像的脚本文件,通过Dockerfile可以指定镜像的基础映像、安装软件、拷贝文件、设置环境变量等操作,最终生成一个可以运行的Docker镜像。可以用于构建各种类型的Docker镜像,从而实现应用程序的打包和部署。
以下是一些常用的Dockerfile命令:
- FROM:指定镜像的基础映像,比如
FROM ubuntu:latest。 - RUN:在容器中运行一条命令,例如安装软件、更新包等,比如
RUN apt-get update && apt-get install -y python3。 - COPY:将文件从主机拷贝到容器中,比如
COPY app.py /app/。 - ENV key value:设置环境变量 (可以写多条)
- WORKDIR:设置容器中的工作目录,比如
WORKDIR /app。 - EXPOSE:声明容器中的端口号,比如
EXPOSE 80。 - CMD:在容器启动时运行的命令,比如
CMD python3 app.py。
33 python为什么一切皆对象
"一切皆对象" 这是因为Python是一种面向对象的编程语言
它的意思是在Python中,每一个变量、函数、类、模块等都是一个对象。这些对象都有自己的属性和方法,可以像操作其他对象一样操作它们。
34 django 的 orm
35 django 的 生命周期
36 框架 - 数据库 - redis中间件做缓存 - 锁
37 什么是IPC,进程间通信方式有哪些
① 什么是IPC
IPC(Inter-Process Communication)即进程间通信,是指在多个进程之间传输数据或者消息的一种机制。进程间通信可以使不同进程之间能够共同协作,以实现更复杂的功能。
② 两种情况:
- 同一台机器上的两个进程通信
- 不同机器上的两个进程进行通信
③ 通信方式:
管道(Pipe):管道是一种半双工的通信方式,数据只能在一个方向上流动。它只能用于父子进程或者兄弟进程之间的通信。
消息队列(Message Queue):消息队列是一种进程间通信的方式,它可以用来传递消息,并且可以实现异步通信。
共享内存(Shared Memory):共享内存是一种进程间通信的方式,它可以让多个进程访问同一块物理内存,从而实现高速数据交换。
套接字(Socket):套接字是一种通用的进程间通信方式,它可以用于网络通信,也可以用于同一台主机上的进程间通信。
RPC(Remote Procedure Call):RPC是一种远程过程调用协议,它可以让进程在不同的机器上进行通信,实现分布式计算。
④ python如何实现
- python中的queue【process和threading中都有queue】,同一台机器上
- 消息队列:redis可以做消息队列,rabbitmq,kafka,
- socket套接字:1 服务和服务之间通过接口调用,2 通过RPC调用
⑤ 进程间通信和线程
线程间:共享变量、消息队列、管道
进程间:消息队列、管道
38 什么是正向代理,什么是反向代理
正向代理和反向代理都是代理服务器的应用场景,两者的主要区别在于代理的对象不同。
正向代理(Forward Proxy)是指代理服务器代理客户端,访问网络资源。
反向代理(Reverse Proxy)是指代理服务器代理服务端,提供网络服务。当客户端访问某个服务时,请求首先发送给反向代理服务器,反向代理服务器再将请求转发给实际提供服务的服务器。在这种情况下,客户端无需知道实际提供服务的服务器的地址,也无需与其直接通信,而是与反向代理服务器进行通信。反向代理服务器通常位于客户端和实际提供服务的服务器之间,可以实现负载均衡、缓存、安全等功能。
应用:
- 正向:vpn、代理池
- 反向:nginx 阿帕奇
39 什么是粘包,如何解决
① 什么是粘包
由于 TCP 是面向流的协议,没有明确的数据包边界,因此可能发生粘包现象发送方连续发送的多个数据包被接收方合并成了一个大的数据包,或者接收方接收到的数据包被拆分成了多个小的数据包。
② 如何解决
1 固定长度分包:发送方在发送数据时,按照固定的长度进行分包,接收方在接收数据时,根据固定的长度进行拆包,这样可以避免粘包问题。
2 在数据包头部中添加长度信息:发送方在每个数据包的头部添加长度信息,接收方在接收数据包时,首先读取长度信息,然后再按照该长度进行拆包,这样可以解决粘包问题。
3 使用特殊的分隔符:发送方在每个数据包的末尾添加特殊的分隔符,例如换行符、回车符等,在接收方接收数据时,按照特殊分隔符进行拆包,这样也可以解决粘包问题。比如:http就是用以\r\n结束,包和包之间使用明确的分隔
40 Go
Goroutine、Channel和GPM模型是Go语言的核心概念之一,它们为Go语言提供了高效、并发、安全的编程模型。
Goroutine是Go语言中的一种轻量级线程,由Go语言的运行时环境管理,可以在单个操作系统线程上运行成百上千个goroutine。Goroutine的创建和销毁开销很小,因此它们被广泛应用于Go语言中的并发编程。
Channel是Go语言中的一种通信机制,用于在不同的goroutine之间传递数据。Channel可以看作是一种类型安全的队列,它支持并发读写,可以避免数据竞争和死锁等问题。Channel的应用场景包括协作式多任务、并发任务分配、数据流处理等。
GPM模型是Go语言的运行时系统的核心,它是指Goroutine、Scheduler、P三个部分的组合。其中,Goroutine是Go语言中轻量级线程的实现,Scheduler是Go语言的调度器,用于管理和调度Goroutine的运行,P是Go语言中的处理器,它是操作系统线程的代理,用于管理和调度Goroutine在不同的操作系统线程上运行。通过GPM模型,Go语言实现了高效、并发、可扩展的并发编程模型,使得Go语言在网络编程、大规模分布式系统、云计算等领域有着广泛的应用。
41 http协议详情,http协议版本,http一些请求头
① http协议详情
http超文本传输协议是一种用于在Web浏览器和Web服务器之间传输数据的协议,HTTP协议的其他特点,例如支持代理、支持缓存、支持断点续传等
四大特性:
- 基于请求响应:服务端不会主动发消息,客户端发送请求,服务端才会返回响应
- 基于TCP/IP作用于应用层之上的协议
- 无状态:服务端不会保存客户端的状态
- 无连接:客户端与服务端之间不会保持连接
websocket协议可以保持客户端与服务端保持联系,并且可以让服务端给客户端发送消息
② HTTP协议版本
HTTP/0.9比较古老、HTTP/1.0、HTTP/1.1、HTTP/2、HTTP/3。其中,HTTP/1.1是目前最常用的版本,HTTP/2和HTTP/3是新一代的协议版本
- 0.9:最初的版本,仅支持get请求,且仅能访问HTML格式的资源
- 1.0:每次tcp连接只能发送一个请求【默认短连接】,服务器响应后就会关闭这次连接,下一个请求需要再次建立那tcp连接,不支持
keep-alive - 1.1:引入了持久连接,tcp连接默认不关闭,可以被多个请求复用,不用声明connection:keep-alive。服务端和客户端发现对方一段时间没有活动就可以主动关闭连接
- 2.0:加入了多路复用,1.x即使开启了长连接,请求的发送也是串行发送的,在带宽足够的情况下,带宽的利用率不足,http2.0采用多路复用,可以并行发送多个请求,提高对带宽的利用率
- 3.0:弃用了tcp采用udp
③ 请求格式和响应格式
1)请求格式
- 请求首行:请求方式、请求地址、请求http协议版本号、以
/r/n来标志结尾 - 请求头(一大堆
K:V键值对,cookie、user-agent、referer、x-forword-for) - 换行 :请求头和请求正文之间是一个空行,这个行非常重要,它表示请求头已经结束,接下来的是请求正文
- 请求体(编码方式:存放隐私敏感信息,并不是所有的请求方式都有请求体)
2)响应格式
- 响应首行:响应状态码、响应单词描述(比如200 的ok )
- 响应头(一大堆
K:V键值对) - 换行
- 响应体(存放给浏览器展示的数据,html格式浏览器中看到的,json格式【字符串】给客户端使用)
响应状态码:
- 1XX :表示服务端已经接受到了你的请求,客户端可以继续发送或者等待
- 2XX:200 OK 表示请求成功,服务端发送了对应的响应(这个响应可能是客户端想要的或者不想要的,但是响应了)
- 3XX:301表示永久移动-请求的网页已永久移动到新位置 ,302 临时重定向 ,304 永久重定向
重定向:想访问网页A,但是自动跳到了网页B
- 4XX:403访问权限不够 ,404请求资源不存在
- 5XX:服务端内部错误
④ HTTP请求方法:
常用的请求方法包括GET、POST、PUT、DELETE、HEAD、OPTIONS等。其中,GET用于获取资源,POST用于提交数据,PUT用于更新资源,DELETE用于删除资源,HEAD用于获取资源头信息,OPTIONS用于查询服务器支持的方法等。
⑤ HTTP请求头
常用的请求头包括User-Agent、Host、Referer、Accept、Cookie等。其中,User-Agent表示客户端类型和版本信息,Host表示请求的主机名和端口号,Referer表示请求的来源页面,Accept表示客户端支持的数据类型,Cookie表示客户端的Cookie信息等。
⑥ HTTP响应头
跨域请求【cors跨域资源共享】:django中如何解决?
常用的响应头包括Content-Type、Content-Length、Cache-Control、Set-Cookie等。其中,Content-Type表示响应数据的类型,Content-Length表示响应数据的长度,Cache-Control表示缓存策略,Set-Cookie表示服务器发送的Cookie信息等。
42 如何实现服务器给客户端发送消息,websocket是什么?用过吗
① 如何实现服务器给客户端发消息
- 轮询:客户端不断向服务器发送请求
- 长轮询:客户端向服务器发送请求,服务器将请求保持打开状态,直到有消息需要发送时再将响应返回给客户端。
- WebSocket:WebSocket 是一种双向通信协议,客户端与服务器之间可以建立一个持久连接,服务器可以随时向客户端发送消息。这种方法支持实时的消息推送,并且可以减少带宽和服务器资源的消耗。
② websocket简介
WebSocket是一种在单个TCP连接上提供双向通信的协议【区别与http】,它可以使服务器实时向客户端发送消息,而不需要客户端不断地发送请求。浏览器和服务器之间只要完成一次tcp连接,两者就可以简历持久性的连接,并进行双向数据传输
Web应用:在线游戏、即时通讯
③ python实现websocket
channels模块中的websocket
下面以Tornado为例,介绍WebSocket在Python项目中的应用和用法:
- 安装Tornado库:可以通过pip命令进行安装,命令为
pip install tornado - 创建WebSocket处理器:在Tornado中,可以通过继承
WebSocketHandler类来创建WebSocket处理器,例如:
import tornado.websocket
class MyWebSocketHandler(tornado.websocket.WebSocketHandler):
def open(self):
print('WebSocket连接已建立')
def on_message(self, message):
print('收到消息:{}'.format(message))
def on_close(self):
print('WebSocket连接已关闭')
在上述代码中,MyWebSocketHandler继承了WebSocketHandler类,并实现了open()、on_message()和on_close()等方法。open()方法在WebSocket连接建立时被调用,on_message()方法在收到消息时被调用,on_close()方法在WebSocket连接关闭时被调用。
- 启动WebSocket应用:可以通过创建Tornado应用并指定WebSocket处理器来启动WebSocket应用,例如:
import tornado.ioloop
import tornado.web
if __name__ == '__main__':
app = tornado.web.Application([(r'/ws', MyWebSocketHandler)])
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
在上述代码中,创建了一个Tornado应用,并通过(r'/ws', MyWebSocketHandler)指定了WebSocket处理器。然后,通过app.listen(8888)启动应用,并通过tornado.ioloop.IOLoop.current().start()启动事件循环。
- 客户端连接WebSocket服务器:在客户端可以使用JavaScript代码连接WebSocket服务器,例如:
var ws = new WebSocket('ws://localhost:8888/ws');
ws.onopen = function() {
console.log('WebSocket连接已建立');
};
ws.onmessage = function(event) {
console.log('收到消息:' + event.data);
};
ws.onclose = function() {
console.log('WebSocket连接已关闭');
};
在上述代码中,通过new WebSocket('ws://localhost:8888/ws')连接WebSocket服务器。然后,通过ws.onopen、ws.onmessage和ws.onclose等事件处理函数处理WebSocket连接建立、消息和关闭等事件。
43 悲观锁和乐观锁,如何实现
并发控制:在程序中出现并发问题,就需要保证在并发情况下数据的准确性,以此确保当前用户和其它用户一起操作时,所得到的结果二号他单独操作时的结果是一样的,该手段那就是并发控制
没做好并发控制,就可能导致脏读、幻读、不可重复读等问题
① 乐观锁
乐观锁的基本思想是假设数据不会被并发修改,只在更新数据时检查数据版本号等标识,如果版本号不一致,则认为数据已被其他线程或进程修改,操作失败;否则,更新数据并增加版本号。
通过程序实现【没有真正的一把锁】,不会出现死锁的现象
- 实现方式:
1) CAS【比较替换】
2) 版本号控制:
3) 时间戳方式:
Python 中可以使用 redis 数据库实现乐观锁,利用 watch() 方法监视数据版本号,在更新数据时先使用 watch() 方法监视数据,然后使用 multi() 方法开启一个事务,把多条数据的操作放在一个管道pipiline中,最后在事务中执行数据更新操作,并使用 exec() 方法提交事务。
- 使用场景:
- 并发量大
- 响应速度快,直接返回响应结果
- 读多写少
② 悲观锁
悲观锁的基本思想是在操作数据的时候,先加锁,防止其他线程或进程修改数据,等操作完成后再释放锁。
- 实现方式:
1) 编程语言中的线程锁,进程锁,比如:python中的互斥锁
2)关系型数据库的锁机制,行锁、表锁、读锁、写锁等等
3)分布式锁:redis实现的分布式锁
Python 中可以使用 threading.Lock() 或 multiprocessing.Lock() 实现悲观锁。这两个锁的用法类似,可以使用 acquire() 方法加锁,使用 release() 方法释放锁
-
使用场景:
-
并发量小【悲观锁会带来非常大的性能问题】
-
响应速度
-
重试代价大,由于悲观锁更新失败的概率比较低
-
秒杀场景:下单秒杀场景-- 异步+锁
44 信号量
信号量(Semaphore)是操作系统中用于进程同步的一种基本机制,它通常被用于控制同时访问某一共享资源的进程数目。信号量可以理解为一个计数器,用于记录可用资源的数量,每次使用资源时计数器减一,释放资源时计数器加一。
在 Python 中,可以使用 threading.Semaphore 或 `multiprocessing.在 Python 中,可以使用 threading.Semaphore 或 multiprocessing.Semaphore 实现信号量。这两种信号量的用法类似,都可以使用 acquire() 方法获取资源,使用 release() 方法释放资源。其中,Semaphore 对象的初始值就是计数器的初始值。
在实际项目中,信号量的应用场景有很多,例如:
控制并发请求:当有大量请求同时涌入系统时,为了防止系统被过多的请求压垮,可以使用信号量控制同时处理请求的数量。
限制资源使用:例如,在某个系统中,有一些资源只能被有限数量的进程同时使用,可以使用信号量来限制进程的数量。
控制文件访问:当多个进程同时访问同一个文件时,为了避免并发访问引起的问题,可以使用信号量控制文件的访问数量。
控制数据库访问:当多个进程同时访问同一个数据库时,为了避免并发访问引起的问题,可以使用信号量控制数据库的访问数量。 实现信号量。这两种信号量的用法类似,都可以使用 acquire() 方法获取资源,使用 release() 方法释放资源。其中,Semaphore 对象的初始值就是计数器的初始值。
在实际项目中,信号量的应用场景有很多,例如:
- 控制并发请求:当有大量请求同时涌入系统时,为了防止系统被过多的请求压垮,可以使用信号量控制同时处理请求的数量。
- 限制资源使用:例如,在某个系统中,有一些资源只能被有限数量的进程同时使用,可以使用信号量来限制进程的数量。
- 控制文件访问:当多个进程同时访问同一个文件时,为了避免并发访问引起的问题,可以使用信号量控制文件的访问数量。
- 控制数据库访问:当多个进程同时访问同一个数据库时,为了避免并发访问引起的问题,可以使用信号量控制数据库的访问数量。
redis与mysql的区别
Redis 和 MySQL 都是常用的数据库管理系统,但是它们有一些区别,包括以下几个方面:
- 数据库类型:Redis 是一种键值对数据库,而 MySQL 是一种关系型数据库。
- 数据持久化:Redis 可以将数据存储在内存中,也可以将数据写入磁盘,支持 RDB 持久化和 AOF 持久化两种方式。而 MySQL 是一种传统的基于磁盘的数据库系统,数据通常直接存储在磁盘上。
- 数据结构:Redis 支持丰富的数据结构,例如字符串、哈希、列表、集合和有序集合等。而 MySQL 主要支持表格结构,可以通过关系型模型将多个表格之间建立关联。
- 数据查询:Redis 通常用于快速读取数据,因为它可以在内存中存储数据,而 MySQL 适用于大量写操作和复杂的查询操作。
- 数据库复制:Redis 支持数据的主从复制和 Sentinel 高可用性架构,而 MySQL 支持主从复制和多节点集群。
- 应用场景:Redis 适用于高并发的场景,例如缓存、计数器和消息队列等;而 MySQL 适用于需要存储大量结构化数据的场景,例如电子商务和金融系统。
总之,Redis 和 MySQL 都是重要的数据库管理系统,各有优缺点,应根据具体应用场景选择合适的数据库。在实际开发中,可以将 Redis 作为 MySQL 的缓存层,以提高系统的性能和可靠性。
redis持久化策略
redis是内存数据库,容易发生丢失,所以redis提供的持久化机制
Redis 提供3种持久化机制 RDB(默认) 和 AOF 机制、混合持久化
① redis database
有可能丢失
② append-only file
③ 混合持久化
*nginx负载均衡是怎么判断是否应该切换的*
答案:
nginx 负载均衡的判断主要依赖于它的 upstream 机制。
在 upstream 中,一组后端服务器被称为一个 upstream 组,nginx 根据 upstream 中定义的负载均衡算法,将客户端的请求流量分发到多个 upstream 组中的服务器。其中 upstream 的配置包括:
- upstream 组的名称;
- upstream 组中的后端服务器列表;
- 负载均衡算法;
- 后端服务器的状态检测和故障转移机制。
在 nginx 中,有几种默认的负载均衡算法,如:轮询、加权轮询、IP哈希、最小连接数等。这些算法可以通过指定 upstream 中的 least_conn 等参数进行细致的配置。对于每个请求,nginx 随机选取一个后端服务器进行请求转发,同时它会记录后端服务器的状态信息。如果后端服务器在一段时间内没有响应,它会被标记为 down,并且 nginx 会将请求转发到其他正常工作的服务器。
另外,nginx还支持基于响应时间、连接数等高级负载算法,用于更加精细地调整请求流量的分发策略。
总之,nginx通过upstream机制,采用不同的负载均衡算法和状态检测机制,能够动态地判断后端服务器是否正常工作,并及时地进行故障转移和流量控制,保证了高可用性和高吞吐量。
**celery异步的流程****
答案:
-
创建一个 Celery 实例,填入关键三个参数:broker, backend, include
-
在 include 中注册 task 文件,在该文件内编写任务,使用 Celery 实例装饰(如:@app.task)
-
使用 delay() 函数,将异步任务推入 Celery 任务队列。
-
当推入队列的异步任务被处理时,Celery 会去寻找可用的 worker 来运行任务。
-
任务在 worker 上执行完成后,worker 会将结果存储到 backend(如 Redis 或数据库等)。
-
访问另一个接口,获取该结果。
总之,异步任务的执行流程如下:创建任务 -> 推入任务队列 -> 执行任务 -> 返回结果 -> 查询结果
**django runserver执行时发生了什么****
答案:
具体来说,执行runserver命令时,Django会:
- 加载整个Django项目并创建WSGI应用程序对象
- 创建一个HTTP服务器,默认绑定在127.0.0.1:8000地址上
- 监听来自客户端的HTTP请求
- 将HTTP请求传递给WSGI应用程序对象处理
- WSGI应用程序对象处理HTTP请求并生成HTTP响应
- HTTP服务器将HTTP响应发送回客户端
**字典查询10条数据与十万条数据有什么差异****
答案:
-
时间延迟:查询10条数据通常会在几毫秒内完成,而查询十万条数据可能需要几秒钟或几分钟的时间。
-
内存占用:十万条数据将比10条数据占用更多内存,特别是如果数据集非常庞大时。
-
索引维护:当数据量增加时,字典的索引维护可能会比较困难,并需要使用更复杂的算法。
-
查询精度:查询更多的数据通常会带来更高的查询精度和准确性。
-
搜索结果:当查询十万条数据时,在结果中往往包含更多的相关内容,对于用户来说更有价值。
-
加载速度:加载十万条数据通常需要更长的时间,这可能会影响用户的体验
**find 与 grep 的区别****
答案:
因此,两者主要的区别在于应用场景和功能特点。
如果你需要搜索文件系统中的文件和目录,那么使用 find 是更合适的选择。
如果你需要在文件中搜索文本,那么使用 grep 更加适合
**mysql当中的索引什么时候会失效****
答案:
1.违反最左前缀法则
如果索引有多列,要遵守最左前缀法则
即查询从索引的最左前列开始并且不跳过索引中的列
2.在索引列上做操作:计算、函数、自动手动转换类型
3.使用不等号:!= <>
4.like以通配符开头('%abc')
5.违反最左前缀法则,含非索引字段 order by 会导致文件排序、group by
- 违反最左前缀法则,含非索引字段 group by 会导致产生临时表
**判断输出结果 True、False****
答案:
47>>4
47>>2
1.Python3中是怎样管理内存的
2.Python3中,在一个function里面要改变一个全局变量的值,怎么办?
3.python3中is和运算符“==”的区别
4.Python3,写段代码,将列表[0,1,2,3,4,5,6,7,8,9]每个元素都加1
5.写一个正则表达式匹配大陆的手机号码
6.score表(如下),请写一个sql语句,查询每门课程分数都大于90的姓名,查询结果姓名不重复

docker镜像分层
镜像分层可以提高镜像的复用性和可定制性,同时也可以减少镜像的大小和构建时间
这种分层的设计有以下几个好处:
- 减少镜像的大小。由于镜像的每一层都只包含变更的文件系统,因此相比于整个文件系统,镜像的大小要小得多。
- 提高镜像的复用性。由于每一层都是相对独立的,因此可以将多个镜像共享同一个基础层,从而提高镜像的复用性。
- 可以定制化地构建镜像。由于每一层都可以包含不同的变更,因此可以在已有镜像的基础上,添加或修改一些文件,从而构建出新的镜像。
redis缓存的作用
① 高性能:一些复杂、耗时 、常用的数据可以存在redis中
② 高并发:提高并发
自定义异常
异常捕获的原理:
自定义:
-
继承excepetion类
-
重写
__init__方法,可以传入公司的状态码,和信息 -
重写
__str__方法,就可以返回状态码和message
"""
exception modul
"""
from common.result_code import CustomStatus
class MyException(Exception):
'''
@brief ct异常类,所有异常类需要继承此类
'''
def __init__(self, status: CustomStatus, message=""):
super().__init__()
self.code = status.code
if message:
self.message = message
else:
self.message = status.message
def __str__(self):
return f"code: {self.code}, message: {self.message}"
各种锁
① 各种锁
② mysql中的锁
③ redis中的锁
django 中orm操作事务
① 全局开启:配置项中配置
在配置项中配置,ATOMIC_REQUESTS=True,将每一个请求都包裹在一个事务中
当有一个请求过来时,Django会在调用视图方法前开启一个事务。如果请求却正确处理并正确返回了结果,Django就会提交该事务。否则,Django会回滚该事务。
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'mxshop',
'HOST': '127.0.0.1',
'PORT': '3306',
'USER': 'root',
'PASSWORD': '123', "ATOMIC_REQUESTS": True, #全局开启事务,绑定的是http请求响应整个过程
"AUTOCOMMIT":False, #全局取消自动提交,慎用
},
'other':{
'ENGINE': 'django.db.backends.mysql',
......
} # 还可以配置其他数据
② 局部使用事务:装饰器
@transaction.atomic 加了该装饰器的视图函数默认属于一个事务
from django.db import transaction
@transaction.atomic
def index():
# 下面的代码在一个事务中执行,一但出现异常,整个函数中所有的数据库操作全部都会回滚
③ with上下文管理
with transaction.atomic():
会将with里面的ORM语句作为一个事务
from django.db import transaction
def reg(request):
with transaction.atomic():
# 下面的代码在一个事务中执行,一但出现异常,整个with函数内部的数据库操作都会回滚 ...
vi/vim
模式:输入模式、命令模式、编辑模式
命令模式 - 输入 vi/vim 文件名 进入,输入zz退出
输入模式- 输入 i a o
编辑模式 - 按 冒号:开始编辑,回车结束运行
缓存击穿、穿透、雪崩
三种场景:【缓存穿透】、【缓存雪崩】和【缓存击穿】的发生,都是因为在某些特殊情况下,缓存失去了预期的功能所致。
当缓存失效或没有抵挡住流量,流量直接涌入到数据库,在高并发的情况下,可能直接击垮数据库,导致整个系统崩溃。
这就是我们需要知道的大前提,而缓存穿透、缓存雪崩和缓存击穿,只不过是在这个大前提下的不同场景的细分场景而已。
缓存穿透
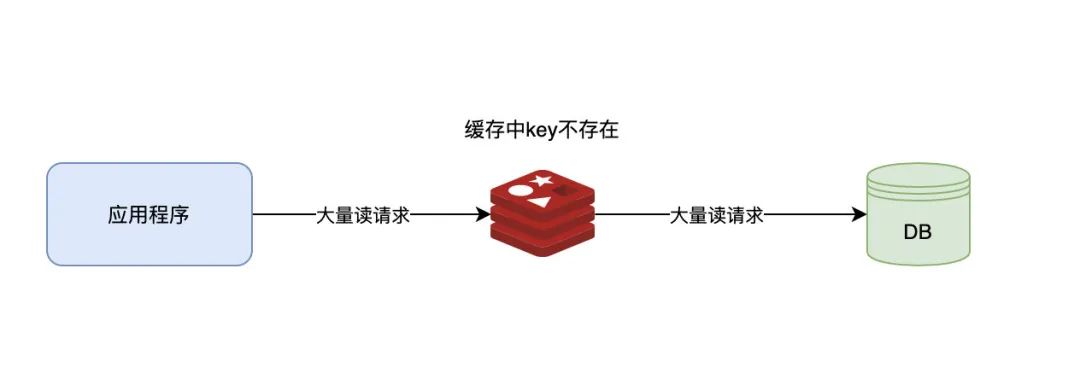
在使用缓存的情况下,访问一个不存在的数据,这个数据既不在缓存中也不在后端数据库中,这种情况下大量的请求会穿透缓存直接访问后端数据库,从而导致数据库压力增大,甚至导致宕机的情况。
为了防止缓存穿透,可以使用以下方法:
1.缓存空对象。当查询一个不存在的数据时,也将这个不存在的数据缓存起来,但是这个数据的值是空的。这样可以避免大量的请求穿透到数据库层。数据空对象
2.使用布隆过滤器。布隆过滤器是一种高效的数据结构,可以判断一个元素是否存在于集合中。在使用缓存时,可以将所有可能存在的数据都放入布隆过滤器中,在进行数据查询时,先通过布隆过滤器判断该数据是否可能存在于缓存中,如果不可能存在,则直接返回不存在,避免请求穿透到数据库层。
布隆过滤器的原理
3.做好缓存和数据库的双重校验。在缓存和数据库中都进行校验,如果缓存中没有该数据,再去查询数据库。这样可以避免缓存穿透。
4.对访问频率较高的数据进行预热。将热点数据在系统启动时或者低峰期提前加载到缓存中,避免在高峰期因请求量过大而导致缓存穿透。
缓存击穿
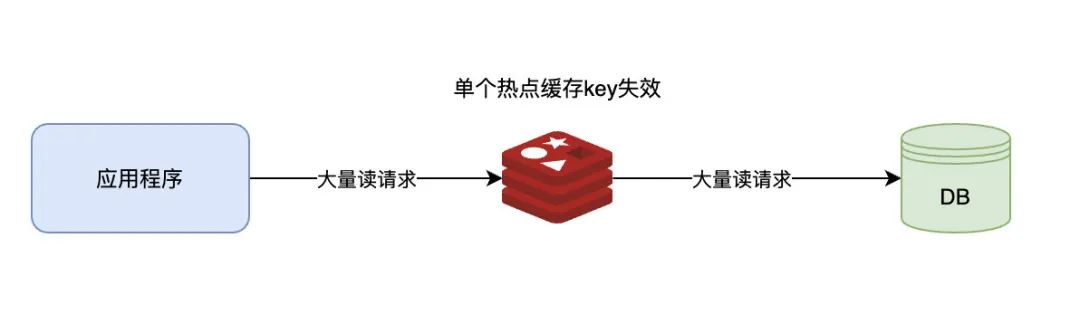
缓存击穿指的是一个存在与缓存中的key在缓存过期的同时又恰好被并发的发送大量请求,导致请求直接绕过缓存直接访问数据库 从而引起数据库压力骤增 甚至导致宕机
避免缓存击穿
1.设置热点数据永不过期 或过期时间特别的长
2.缓存中使用互斥锁机制 保证过期的时候只有一个请求
缓存雪崩
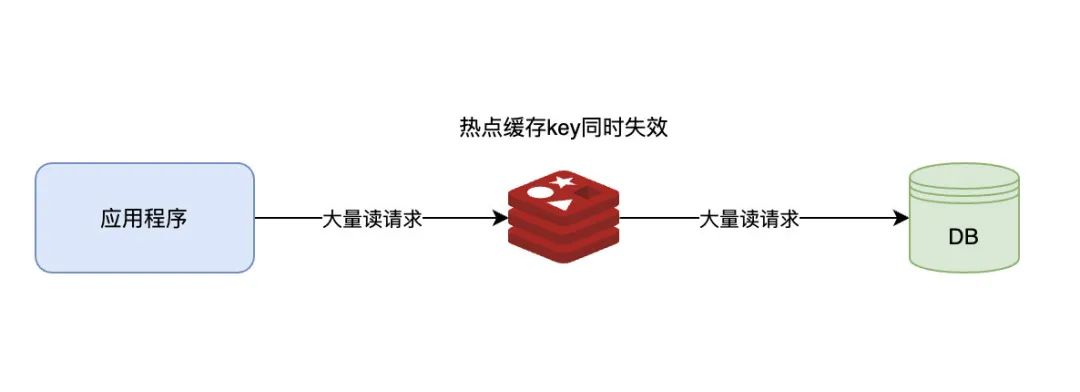
redis缓存雪崩指的是在缓存中的大量key具有相同的过期时间 并且这些key在同一时间点过期 导致大量的请求同时落到数据库上 从而导致数据库瞬时压力过大 甚至导致宕机的现象
避免缓存雪崩
1.将缓存的key过期时间随机
2.使用二级缓存,将数据分散到多个不同的缓存中
3.在服务端设置限流机制,限制并发请求量
4.缓存中设置数据预热机制 提前将热点数据加载到缓存中
5.在数据库中采用主从复制和集群化等方式
python代码防止泄露的方案
① 启动后,代码会加载到内存中间,然后源代码删除掉
② 使用pipinstaller打包成可执行文件
关于pipinstaller:https://zhuanlan.zhihu.com/p/430490285
③ 做成docker镜像,在环境变量中设置 -e password如果与环境变量中设置的不一致,则无法运行起来
flask请求流程
① 应用程序初始化
Flask 应用程序启动时,它会执行一次初始化,包括创建 Flask 实例、加载配置、注册插件等
② 请求处理
请求来了
app.run()结果就是执行app加括号--> app()--> Flask类产生对象,则执行 Flask.__call__方法--> self.wsgi_app(environ, start_response)
就会根据url和http方法,找到对应的视图函数
中间还 可以执行对应的 请求拓展 等等,包括flask自己包装了 local对象,可以兼容线程、协程等,不会使得数据在不同的线程中错乱
③ 视图函数返回响应对象
④ 客户端收到后 进行解析
python 的collections包下有哪些类型
-collections 是 python 的内置模块,提供了很多方便且高性能的关于集合的操作,掌握这些知识有助于提高代码的性能和可读性
① 具名元组 namedtuple
- 作用:生成可以使用名字来访问元素内容的元组
语法
namedtuple('名称', [属性list])
# 生成一个具名元组
nt_obj = namedtuple('元组名称坐标点', ['x', 'y', 'z'])
p1 = nt_obj(1,4,5)
print(p1) # 元组名称坐标点(x=1, y=4, z=5)
print(p1.x) # 1
print(p1.y) # 4
print(p1.z) # 5
② 双端队列 deque
作用:双端队列 deque两边都能进两边都能出
方法: .pop()和 .popleft()
l1 = [1, 4, 5, 2, 2]
# 1 传入一个可迭代对象生成 deque对象
dq = deque(l1)
print(dq) # deque([1, 4, 5, 2, 2])
# 2 pop popleft
dq.pop() # 弹出最右边的数据
print(dq) # deque([1, 4, 5, 2])
dq.popleft() # 弹出最左边的数据
print(dq) # deque([4, 5, 2])
队列、堆栈、堆:队列和堆栈都是一边只能进一边只能出
队列==> 先进先出
堆栈
==> 【操作系统】自动操作
==> 用于存放函数值、局部变量
==> 先进后出【push、pop】
堆
==> 【程序员】操作
==> 相当于链表
==> 一棵树
- multiprocessing中的队列Queue
from multiprocessing import Queue
l1 = [1, 4, 5, 2, 2]
q = Queue(4)
q.put(111)
q.put(222)
q.put(333)
q.put(l1)
print(q.get()) # 先进先出
print(q.get())
print(q.get())
print(q.get())
----
111
222
333
[1, 4, 5, 2, 2]
③ 有序字典
作用:按照插入key的顺序,进行有序排列
Dictionary that remembers insertion order
d1 = OrderedDict([('a', 1), ('b', 2), ('c', 3), (4, "d")])
print(d1) # OrderedDict([('a', 1), ('b', 2), ('c', 3), (4, 'd')])
print(d1.get(4)) # d
print(d1.values()) # odict_values([1, 2, 3, 'd'])
④ 统计 counter
跟踪值出现的次数,生成一个无序的容器类型,以字典的键值对形式存储结果,其中元素为key,计数结果为value
s1 = 'aaaabbcbbabc'
c1 = Counter(s1)
print(c1) # Counter({'a': 5, 'b': 5, 'c': 2})
SQL注入
利用特殊符合的组合产生特殊的含义 从而避开正常的业务逻辑
针对上述的SQL注入问题 核心在于手动拼接了关键数据 交给execute处理即可
sql = "select * from userinfo where name=%s and pwd=%s"
cursor.execute(sql, (username, password))
celery架构 与python开多线程
celery做异步 定时和延时可以用别的
1 解耦合
2 提高性能,worker可以放别的地方
3 快捷,结果可以自己存储起来,用多线程还需要自己写
django中事务如何开启
-原生sql如何开启事务:begin; commit;
-django中如何开事务:atomic() commit()
for_update是锁表还是锁行
如果查询条件用了索引/主键,那么select ..... for update就会进行行锁
如果是普通字段(没有索引/主键),那么select ..... for update就会进行锁表
1 sort [].sort() sorted()
2 reverse() reversed()
匿名函数lambda和普通函数def的区别
- def创建的函数是有名称的,而lambda没有函数名称,这是最明显的区别之一。
- lambda返回的结果通常是一个对象或者一个表达式,它不会将结果赋给一个变量,而def可以。
- lambda只是一个表达式,函数体比def简单很多,而def是一个语句。
- lambda表达式的冒号后面只能有一个表达式,def则可以有多个.
- 像if或for等语句不能用于lambda中, def则可以。
- lambda一般用来定义简单的函数,而def可以定义复杂的函数。
- lambda函数不能共享给别的程序调用,def可以。

