爬虫 - 1 urllib模块与requests模块
1 爬虫简介
(1)什么是爬虫
网路爬虫,是一种按照一定规则,自动抓取互联网信息的程序或者脚本,由于互联网数据的多样性和资源的有限性,根据用户需求定向抓取相关网页并分析已成为如今主流的爬取策略
本质:模型发送http请求,获取数据,清洗数据
(2)爬虫可以做什么
只要是你能通过浏览器访问的数据都可以通过爬虫获取
(3)爬虫的本质是什么
模拟浏览器打开网页,获取网页中我们想要的那部分数据
2 网络爬虫的原理图
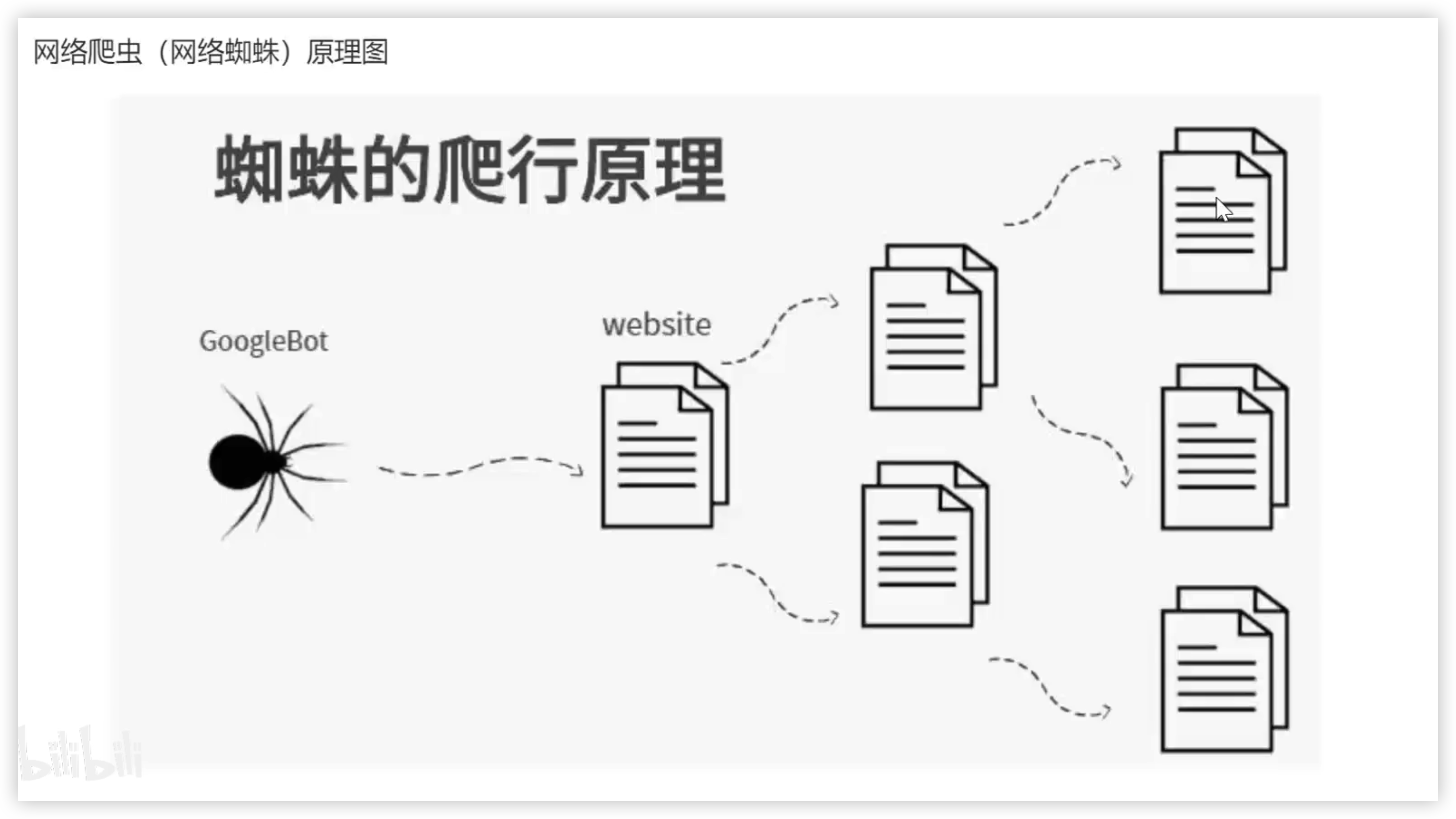
搜索引擎原理图

搜索引擎其实就是一个爬虫程序,从各个网站上,爬取数据保存到自己的数据库中
在百度搜索框中搜索关键字,百度会在自己的数据库中查询关键字,然后返回给用户
SEO:搜索引擎优化,是指通过优化网站内容、结构和链接来提高在搜索引擎结果页面上的排名。主要包括网站内容的关键字优化,网站结构的优化和建立高质量的外部链接等方式。SEO需要一定的时间和努力,但是相对于SEM,SEO可以带来更长期和稳定的流量和收益。
SEM:搜索引擎营销,是指通过付费广告在搜索引擎结果页面上展示自己的网站。主要包括搜索引擎广告,付费搜索引擎排名和购买关键字等方式。SEM可以快速地提高网站的曝光度和流量,但是需要投入大量的广告预算。
3 基本流程
- 准备工作
通过浏览器查看分析目标网页,学习编程基础规范
- 获取数据
通过HTTP库向目标站点发起请求,请求可以包含额外的header等信息,如果服务器能正常响应,会得到一个Response,便是所要获得的页面的内容
- 解析内容
得到的内容可能是HTML、json等格式,可以用页面解析库、正则表达式等解析解析
- 保存数据
保存形式多样,可以存为文本,也可以保存到数据库,或者保存特定格式的文件

1.网页network中的Headers
Headers是我们网页上发起请求里面给服务器发送的消息,服务器通过这些消息来鉴定我们的身份,无论是等候后的消息cookies、还是浏览器的消息User-Agent,

- cookie用户登录的信息
登录以后才能看到的一些信息,必须要学会操作cookie

- User-Agent浏览器的信息

编码规范
coding=utf-8
4 Urllib
1.get请求获取request对象
request对象,是网页返回的信息封装的对象
import urllib.request
response = urllib.request.urlopen("http://www.baidu.com")
print(response)
request对象的read方法
response = urllib.request.urlopen("http://www.baidu.com")
print(response.read().decode('utf-8')) # 对获取到的网页源码解析utf-8的解码

保存在html文件中,打开后就是从百度网站上获取的数据
2.获取post请求
测试网站
通过post来发送请求,必须要按照post请求格式来发送
(1)直接发送
# 获取一个post请求
response = urllib.request.urlopen("http://httpbin.org/post")
print(response.read())

(2)post需要有发送数据的要求
# 获取一个post请求
# 还需要解析器
import urllib.parse
# 需要发送二进制数据
data = bytes(urllib.parse.urlencode({"hello": "world"}), encoding="utf-8")
response = urllib.request.urlopen("http://httpbin.org/post",data=data)
print(response.read().decode('utf-8'))
{
"args": {},
"data": "",
"files": {},
"form": {
"hello": "world"
},
"headers": {
"Accept-Encoding": "identity",
"Content-Length": "11",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.9",
"X-Amzn-Trace-Id": "Root=1-63c7dacb-42be5926756b41ad5eb9b06f"
},
"json": null,
"origin": "120.208.143.33",
"url": "http://httpbin.org/post"
}

则通过urllib可以模拟浏览器来发送的请求,和测试网站发送的样例一致
3.超时异常处理
超时timeout

当没有伪装的情况下,可以设置超时的时间

try:
response = urllib.request.urlopen("http://httpbin.org/get",timeout=0.01)
print(response.read().decode('utf-8')) # 对获取到的网页源码解析utf-8的解码
except urllib.error.URLError as e:
print("time out!")
5 request模块
requests模块其实就是封装了urllib模块
使用requests可以模拟浏览器的请求(http),比起之前用到的urllib,requests模块的api更加便捷(本质就是封装了urllib3)
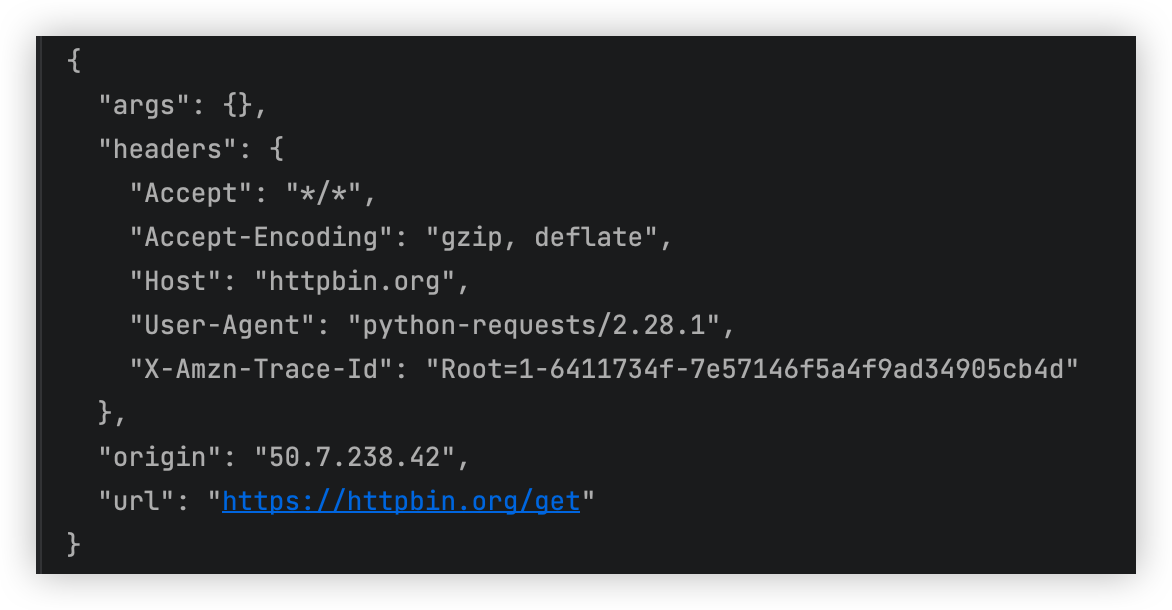
5.1 发送get请求
使用requests.get函数发送GET请求
import requests
url = "https://www.baidu.com/
response = requests.get(url)
print(response.text)
# res.text是转换成字符串模式
响应体
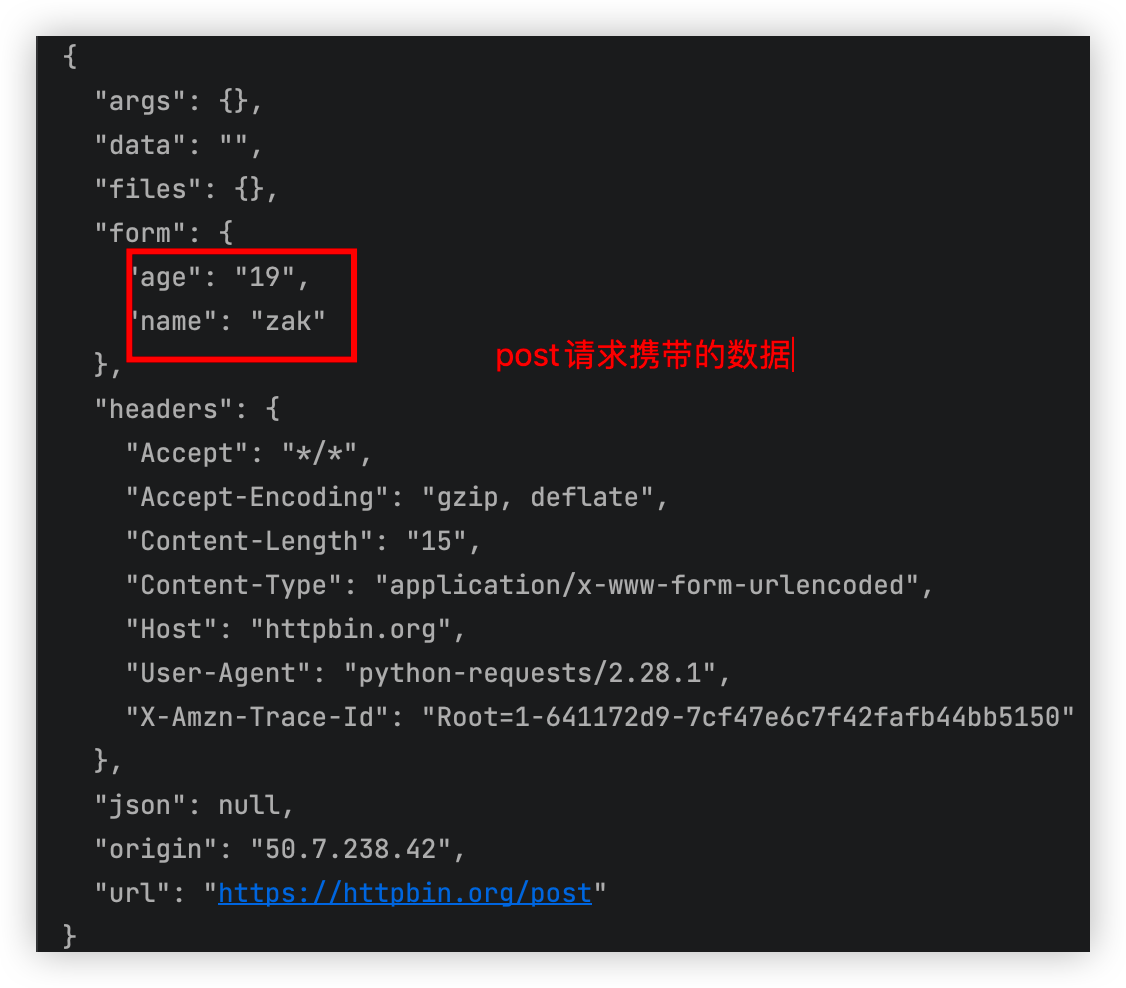
5.2 发送post请求
使用requests.post函数发送POST请求
url = 'https://httpbin.org/post'
data = {'name': 'zak', 'age': '19'}
response = requests.post(url, data)
print(response.text)
5.3 request携带参数
① 方式一:直接拼到路径中
response = requests.get('https://httpbin.org/get?name=duo&age=19')
print(response.text)

② 方式二:使用params参数
response = requests.get('https://httpbin.org/get',params={'name': 'qiuqiu', 'pet':'dog'})
print(response.text)

6 url编码解码
Python标准库中的urllib模块提供了编码和解码URL的功能。具体来说,urllib模块包含urlencode()和urldecode()函数,可以用于对URL进行编码和解码。
url:全球资源定位器(Uniform Resource Locator)
6.1 urlencode()函数、parse_qs()函数
① urlencode() - 编码
data = {'name': '陈星旭', 'age': 19}
res = urlencode(data)
print(res)
--------------
name=%E9%99%88%E6%98%9F%E6%97%AD&age=19
② parse_qs() - 解码
data = 'name=%E9%99%88%E6%98%9F%E6%97%AD&age=19'
res = parse_qs(data)
print(res)
--------------
{'name': ['陈星旭'], 'age': ['19']}
6.2 quote()和unquote()
① quote() - 编码
参数只能是字符串
strings = '玄商辣目'
res = quote(strings)
print(res)
--------------
%E7%8E%84%E5%95%86%E8%BE%A3%E7%9B%AE
② unquote() - 解码
参数只能是字符串
strings = '%E7%8E%84%E5%95%86%E8%BE%A3%E7%9B%AE'
res = unquote(strings)
print(res)
--------------
玄商辣目
7 requests携带请求头
- 反扒措施之一,就是请求头
- http请求中,请求头中有一个很重要的参数
User-Agent表明了浏览器的信息,如果没有带这个请求头,后端就该禁止访问 - http协议有版本:主流1.1、0.9、2.x
- 1.1比之前增加了:
keep-alive - 2.x比1.x增加了:
多路复用
- 1.1比之前增加了:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'
}
response = requests.get('https://httpbin.org/get',headers=headers)
print(response.text)
response = requests.get('https://httpbin.org/get')
print(response.text)


8 自动登录,携带cookie的两种方式
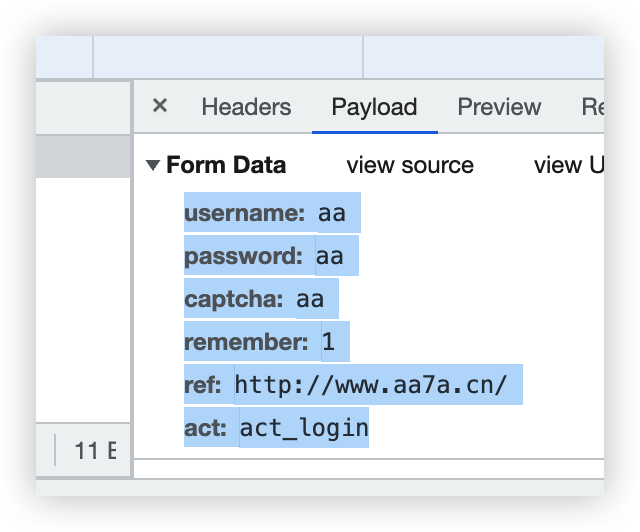
(1)方式一:通过post请求-字典或CookieJar对象
import requests
data = {
'username': username,
'password': password,
'captcha': 'aa',
'remember': 1,
'ref': 'http://www.aa7a.cn/',
'act': 'act_login'
}
response = requests.post('http://www.aa7a.cn/user.php', data=data)
print(response.text)
print(response.cookies) # RequestsCookieJar 对象
res = requests.get('http://www.aa7a.cn', cookies=response.cookies)
print(username in res.text)
(2)方式二:放到cookie参数中
9 request.session的使用
为了方便cookies的使用,以后不需要携带cookie,将cookie放到requests的session方法中,得到session对象
通过session对象去发post登录请求,如果登录成功则会自动记录cookies
import requests
data = {
'username': username,
'password': password,
'captcha': 'aa',
'remember': 1,
'ref': 'http://www.aa7a.cn/',
'act': 'act_login'
}
session = requests.session()
# 发送post请求,之后通过session对象去访问,就会记录cookies
response = session.post('http://www.aa7a.cn/user.php', data=data)
print(response.text)
print(response.cookies)
res = session.get('http://www.aa7a.cn/')
print(username in res.text)
9 补充post请求携带数据编码格式
① 普通data对应字典 - urlencoded
通过data关键字携带字典
requests.post(url='xxxxxxxx',data={'xxx':'yyy'})
② json格式
通过json关键字携带json格式
requests.post(url='xxxxxxxx',json={'xxx':'yyy'})
③ json格式
在请求头中,携带content-type声明是json格式
requests.post(url='',
data={'':''},
headers={
'content-type':'application/json'
})

 浙公网安备 33010602011771号
浙公网安备 33010602011771号