

11.28-12.2周末总结
MySQL数据库
一、多表查询
笛卡尔积这种两张表直积的方式,将两张表中的记录混乱连接的方式,所形成的虚拟表,并非我们想要的方式,所以mysql中涉及多表查询有两张方式
1.方式一:连表查询
关键字
inner join 内连接 可以简写成join left join 左连接 right join 右连接 union 全连接
-
inner join将两张表按照某种连接条件连接起来
select * from emp join dep on dep.id=emp.dep_id;
+----+--------+--------+------+--------+-----+--------------+ | id | name | sex | age | dep_id | id | name | +----+--------+--------+------+--------+-----+--------------+ | 1 | jason | male | 18 | 200 | 200 | 技术 | | 2 | dragon | female | 48 | 201 | 201 | 人力资源 | | 3 | kevin | male | 18 | 201 | 201 | 人力资源 | | 4 | nick | male | 28 | 202 | 202 | 销售 | | 5 | owen | male | 18 | 203 | 203 | 运营 | +----+--------+--------+------+--------+-----+--------------+

默认按
join左表为基准,不显示两张表没有关联的数据
-
left join
以左表为基准,左表中的数据与右表中没有关联的也会显示
select * from dep left join emp on emp.dep_id=dep.id;
+-----+--------------+------+--------+--------+------+--------+ | id | name | id | name | sex | age | dep_id | +-----+--------------+------+--------+--------+------+--------+ | 200 | 技术 | 1 | jason | male | 18 | 200 | | 201 | 人力资源 | 2 | dragon | female | 48 | 201 | | 201 | 人力资源 | 3 | kevin | male | 18 | 201 | | 202 | 销售 | 4 | nick | male | 28 | 202 | | 203 | 运营 | 5 | owen | male | 18 | 203 | | 205 | 财务 | NULL | NULL | NULL | NULL | NULL | +-----+--------------+------+--------+--------+------+--------+
-
right join以右表为基准,有表中没有的数据也会显示
select * from dep right join emp on dep.id=emp.dep_id;
+------+--------------+----+--------+--------+------+--------+ | id | name | id | name | sex | age | dep_id | +------+--------------+----+--------+--------+------+--------+ | 200 | 技术 | 1 | jason | male | 18 | 200 | | 201 | 人力资源 | 2 | dragon | female | 48 | 201 | | 201 | 人力资源 | 3 | kevin | male | 18 | 201 | | 202 | 销售 | 4 | nick | male | 28 | 202 | | 203 | 运营 | 5 | owen | male | 18 | 203 | | NULL | NULL | 6 | jerry | female | 18 | 204 | +------+--------------+----+--------+--------+------+--------+
-
union将两张表联合起来,两张表中没有连接的数据,都会显示出来
select * from dep right join emp on dep.id=emp.dep_id union select * from dep left join emp on dep.id=emp.dep_id;
+------+--------------+------+--------+--------+------+--------+ | id | name | id | name | sex | age | dep_id | +------+--------------+------+--------+--------+------+--------+ | 200 | 技术 | 1 | jason | male | 18 | 200 | | 201 | 人力资源 | 2 | dragon | female | 48 | 201 | | 201 | 人力资源 | 3 | kevin | male | 18 | 201 | | 202 | 销售 | 4 | nick | male | 28 | 202 | | 203 | 运营 | 5 | owen | male | 18 | 203 | | NULL | NULL | 6 | jerry | female | 18 | 204 | | 205 | 财务 | NULL | NULL | NULL | NULL | NULL | +------+--------------+------+--------+--------+------+--------+
2.方式二:子查询
子查询:将一条sql语句查询的结果,当成另外一条sql语句的查询条件,所需结论来自于一张表的字段,则可以使用子查询
- 例:查找名为kevin的员工的部门名称
1.查找kevin的部门编号 select dep_id from emp where name='kevin'; 2.根据部门编号查找名称 select name from dep where id in (select dep_id from emp where name='kevin');
+--------------+ | name | +--------------+ | 人力资源 | +--------------+
- 子查询中可以与运算符或者关键字连接,表示不同的含义
| 关键字 | 含义 |
|---|---|
in |
成员运算,in()后面的是结果集的虚拟表或者直接的结果 |
not in |
in 的取反结果 |
any |
用来比较与子查询数据集中的任意值的结果。any必须和其他的比较运算符共同使用,而且any必须将比较运算符放在any |
| some | 与any同义,用法一致 |
all |
与any相似,但是意思不同,all表示所有,any表示任意一个 |
exists |
exists sql 1 exists sql 2判断sql2是否有结果,有结果则执行sql1 |
二、python操作数据库
1.python操作数据库的基本操作
import pymysql # 1 连接mysql connect中进行配置 conn = pymysql.connect( host='127.0.0.1', port=3306, user='root', passwd='root123', database='day43', charset='utf8', autocommit=True ) # 2 产生游标对象,由游标对象来对数据表中的数据进行操作 cursor = conn.cursor() """ cursor = conn.cursor(pymysql.cursors.DictCursor) 中的pymysql.cursors.DictCursor参数可以将 cursor返回的数据以列表中套元组的形式,转换成列表中套字典 """ # 3 编写sql语句 sql = 'show databases' # 在python中sql语句编写 # 4 发送sql语句 # execute方法的返回值是sql语句执行后影响的行数 affect_rows = cursor.execute(sql) # 5 获取sql语句执行的结果 res = cursor.fetchall() print(res) """ (('information_schema',), ('day43',), ('db1129',), ('db3',), ('dbday43',), ('empdb',), ('kerdidb',), ('mysql',), ('performance_schema',), ('sys',)) """
2.pymysql的中方法
| 方法 | 作用 |
|---|---|
fetchall() |
获取所有的结果 |
fetchone() |
获取结果集的第一个数据 |
fetchmany() |
获取指定数量的结果集 |
三、MySQL中的理论
1.sql注入问题
通过sql语句的中输入特殊符号,从而避开正常的业务逻辑,成为漏洞
(1)现象一:输对用户名即可登录
- 当我们输入用户名
# 输入 jason' -- 234123dwsf
- 我们可以查看,待执行的sql语句
select * from register where name='jason' -- 234123dwsf' and pwd=''
- 当我们手动输入
'来补全字符的拼接,然后输入--将后面密码的输入注释掉,这种注入方式,
(2)现象二:不需要对的用户名和密码也可以登陆成功
- 当我们输入用户名
# 输入 xyz ' or 1=1 -- asdfa
- 我们可以查看,待执行的sql语句
select * from register where name='xyz ' or 1=1 -- asdfa' and pwd=''
- 当我们的输入包含
' or 1=1 --之后,where后面条件是name='xxxx' or 1=1则1=1是一定成立的,所以不需要知道用户名就可以直接登录
(3)解决SQL注入
针对上述的SQL注入问题,核心在于手动拼接了关键数据
所以,我们不应该手动拼接SQL语句,应该交给execute来处理,execute底层已经帮我们做好了过滤特殊符号组合产生的特殊含义的问题
2.视图
(1)视图:视图是我们通过查询得到的一张虚拟表,这张表存于内存中,当我们下次需要的时候,我们可以直接使用,这张表只有表结构,没有表数据。视图主要用于优化查询
(2)关于视图的操作
- 创建视图
create view 视图名 as 虚拟表操作;
视图的名称应该见名知意,表名中包含数据来源的表
- 查询视图
select * from 视图名;
- 修改视图
alter view 视图名 as 新的查询语句; -- 可以修改视图的来源表
- 删除视图
drop view 视图;
3.触发器trigger
在mysql中,针对虚拟表进行insert、删除delete、修改update的操作能够自动触发我们之前设置的sql语句,这样的情况叫做触发器
(1)触发器的语法
create trigger 触发器的名字 before/after insert/update/delete on 表名 for each row begin sql语句 end # 当sql语句的时候触发
(2)临时修改sql语句的结束符
由于有些操作中需要使用分号,这个时候就需要用关键字delimiter修改结束符分号
# 语法 delimiter 临时声明结束符
4.事务Transaction
在关系数据库中,一个事务可以是一条SQL语句,一组SQL语句或整个程序。
(1)事务的四大特性ACID
A:atomicity原子性,一个事务是一个不可分割的工作单位,要么同时成功,要么同时失败
C:consistency一致性,事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
I:isolation隔离性,一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
D:durability持久性,持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响
(2)数据库操作
mysql是完整事务,执行rollback或者commit标志着事务结束
(3)事务相关关键字
| 关键字 | 含义 |
|---|---|
start transaction |
开始事务 |
rollback |
回滚到上一个状态 |
commit |
执行commit操作,数据刷新到硬盘 |
savepoint |
节点,部分事务,类似游戏中的存档点 |
(4)隔离级别
在SQL标准中定义了四种隔离级别,每一种级别都规定了一个事务中所做的修改
InnoDB支持所有隔离级别
设置隔离级别
set transaction isolation level 级别
(1)未提交读-脏读read uncommitted
事务中的修改即使没有提交,对其他事务也都是可见的,事务可以读取未提交的数据,这一现象也称之为"脏读"
(2)提交读-不可重复度 read committed
大多数数据库系统默认的隔离级别
一个事务从开始直到提交之前所作的任何修改对其他事务都是不可见的,这种级别也叫做"不可重复读"
(3)可重复读repeatable read
MySQL默认隔离级别
能够解决"脏读"问题,但是无法解决"幻读"
所谓幻读指的是当某个事务在读取某个范围内的记录时另外一个事务又在该范围内插入了新的记录,当之前的事务再次读取该范围的记录会产生幻行,InnoDB和XtraDB通过多版本并发控制(MVCC)及间隙锁策略解决该问题。
(4)可串行读serializable
强制事务串行执行,很少使用该级别
5.存储过程procedure
存储过程包含了一系列可以执行的SQL语句,存储过程存放于MySQL中,通过调用它的名字可以执行其内部的SQL语句,可以看成是python中的自定义函数
(1)无参函数
delimiter $$ create procedure p1() begin select * from cmd; end $$ delimiter ; # 调用 call p1()
(2)有参函数
delimiter $$ create procedure p2( in m int, # in表示这个参数必须只能是传入不能被返回出去 in n int, out res int # out表示这个参数可以被返回出去,还有一个inout表示即可以传入也可以被返回出去 ) begin select * from cmd where id > m and id < n; set res=0; # 用来标志存储过程是否执行 end $$ delimiter ; # 针对res需要先提前定义 set @res=10; 定义 select @res; 查看 -- res=10 call p2(1,5,@res) 调用 -- 展示id为2,3,4的数据,并重制@res select @res 查看 -- @res=0
(3)关于存储过程的操作
- 查看存储过程具体信息
show create procedure pro1;
- 查看所有存储过程
show procedure status;
- 删除存储过程
drop procedure pro1;
6.MySQL中的内置函数
注意与存储过程的区别,mysql内置的函数只能在sql语句中使用,可以看成python中的内置函数
| 函数名 | 作用 |
|---|---|
Trim ltrim rtrim |
移除指定字符 |
lower`` upper |
大小写转换 |
Left right |
获取左右起始指定个数字符 |
soundex |
匹配发音类似的记录 |
date_format |
日期格式 |
7.流程控制
(1)if条件语句
delimiter // CREATE PROCEDURE proc_if () BEGIN declare i int default 0; if i = 1 THEN SELECT 1; ELSEIF i = 2 THEN SELECT 2; ELSE SELECT 7; END IF; END // delimiter ;
(2)while循环
delimiter // CREATE PROCEDURE proc_while () BEGIN DECLARE num INT ; SET num = 0 ; WHILE num < 10 DO SELECT num ; SET num = num + 1 ; END WHILE ; END // delimiter ;
8.索引
(1)索引的所用
1)索引就好比一本书的目录,它能让你更快的找到自己想要的内容。
2)让获取的数据更有目的性,从而提高数据库检索数据的性能。
(2)索引数据结构
索引底层其实是树结构:树是计算机底层的数据结构
(1)树的类型
- 二叉树、b树、b+树、b*树
二叉树:二叉树里面还可以细分成很多领域,
- b+树/b*树
只有叶子结点才会存放真实数据,
辅助索引的叶子结点存放的是数据的主键值,找到主键值再去聚焦索引里拿到真实数据
1)B+树

只有叶子结点存放真实数据,根和树枝节点存的仅仅是虚拟数据
查询次数由树的层级决定,层级越低次数越少
一个磁盘块儿的大小是一定的,那也就意味着能存的数据量是一定的。如何保证树的层级最低呢?一个磁盘块儿存放占用空间比较小的数据项
思考我们应该给我们一张表里面的什么字段字段建立索引能够降低树的层级高度>>> 主键id字段
2)B*树

前端
一、web前端开发三大技术组成部分
直接和用户交互的界面,都可以称为前端、页面、前端界面
而不和用户直接打交道,负责真正内部的业务逻辑的执行的,称之为后端
前端开发中的三大技术:HTML、CSS、JaveScript
| 名称 | 作用 |
|---|---|
| HTML超文本标记语言 | 网页的内容 |
| CSS层叠样式表 | 网页的样式 |
| JavaScript网页脚步语言 | 网页的动态 |
二、HTTP协议
1.http协议的四大特性
| 特性 | 描述 |
|---|---|
| 基于请求响应 | 每一次客户端发出请求,服务端才返回响应 |
| 基于TCP、IP协议 | HTTP协议是应用层协议,基于TCP传输层协议以及IP网络层协议,进行数据的传输 |
| 无连接 | 客户端和服务端之间不会保持连接 |
| 无状态 | 服务端不会保存客户端的状态 |
2.数据格式
(1)请求格式
- 请求体(包括了请求方式、协议的版本)
- 请求头(包括一大堆的K:V键值对)
- 换行符号\r\n
- 请求体(存放隐私敏感信息)
(2)响应格式
- 响应体(响应状态码、协议版本)
- 响应头(一大堆K:V键值对)
- 换行符号\r\n
- 响应体(存放给浏览器展示的数据)
3.响应状态码的含义和常见状态码
由3位数字组成,用数字来表达一些意义,第1位数字反应了响应的类别
-
1XX
表示服务端已经接收到了客户端的请求,客户端可以继续发送或者等待
-
2XX
200 OK表示成功,服务端已经发送了响应 (但是这个响应可能是客户端想要的或者是不想要的,但是发送了响应)
-
3XX
302 临时重定向 ;304 永久重定向 (重定向的含义是跳转到某个页面)
-
4XX
客户端发生了错误 403 权限不够;404 请求的资源不存在
-
5XX
服务端发生了错误
在公司中也会自定义状态响应码,一般是10000起步
三、HTML超文本标记语言
1.HTML的特点
所见即所得,没有任何逻辑,写什么就显示什么
2.HTML的操作
(1)注释语法
<!--单行注释--> /*多行注释*/
(2)html文档
<html> html的固定格式,包裹html的内容 <head>主要放给网页的配置</head> <body>主要放网页的内容</body> </html>
(3)html标签的分类
1.按照书写的形式来分
1)单标签(自闭和标签)
<img src="" alt=""> <input type="text">
2)双标签
<p></p> <div></div>
2.按照占据内容的大小类分
(1)行内标签
内部文本显示出来多大,就会占据多大,不会换行显示
(2)块级标签
一个文本占据一行,没有内容不占据内容,有内容则独占一行
3.标签的属性
(1)默认属性:标签自带
- 常见标签内的属性
1)a标签
-
href=""1)填写网址 有跳转功能 2)填写页面内id值 具备锚点功能 -
target
默认是
_self原网页跳转,改成_blank为新建网页跳转
2)img标签
- src=""
(1)图片地址(本地地址/网页地址)
(2)填写路由 - title
鼠标悬浮图片上,显示title内填写的数据 - alt
添加图片加载失败后显示的内容 - width与height
图片的尺寸 两者调整一个即可 等比例缩放
(2)自定义属性
用户自定义,编写不会有提示甚至会飘颜色
4.常见符号对应的html代码
| 代码 | 对应内容 |
|---|---|
|
空格 |
> |
> |
< |
< |
& |
& |
¥ |
¥ |
© |
版权 |
® |
注册 |
四、head内常见标签
1.title网页标题
title包裹的是网页的标题
2.meta配置信息
meta内包裹网页源信息

<meta name="keywords" content="查询关键字"> <meta name="description" content="网页简介"> <meta charset="UTF-8">
3.style支持编写css代码
style标签内部可以通过选择器来编写css代码

4.link标签引入外部css文件
 + css文件中
+ css文件中
div { font-size: 48px; color: indianred; }
- html文件中
<head> <link rel="stylesheet" href="html的css.css"> </head>

5.script标签支持写js代码
- 通过prompt制作弹窗
<script> prompt('周末休息','也要吃早饭') </script>
- 通过script的src属性外链接js文件
prompt('把学习任务完成','可以打羽毛球')


五、body内基本标签
1.标签的行内标签和块级标签的嵌套
页面的内容主要由div行内标签和span块级标签组成,标签之间的嵌套可以组合出不同的内容层级关系,从而可以划分出不同的板块组成整个网页
但是标签之间的嵌套关系是有限制的
-
块级标签内部可以嵌套块级标签和行内标签
-
行内标签内部只能嵌套行内标签
p标签是块级标签,但是p标签内部也不能嵌套块级标签
2.标题内基本标签h1至h6
<body> <h1>一级标签</h1> <h2>二级标签</h2> <h3>三级标签</h3> <h4>四级标签</h4> <h5>五级标签</h5> <h6>六级标签</h6> </body>
3.段落标签
| 标签 | 作用 |
|---|---|
<p> |
包裹段落内容 |
<body> <p>一体</p> <p>二体</p> <p>三体</p> <p>四体</p> <p>五体</p> </body>
4.其他标签
| 标签 | 内容 |
|---|---|
<u>下划线</u> |
下划线 |
<i>斜体</i> |
斜体 |
<s>删除线</s> |
删除线 |
<b>加粗</b> |
加粗 |
<body> <u>下划线</u> <i>斜体</i> <s>删除线</s> <b>加粗</b> </body>

相同的效果可能是不同的标签来实现的,标签不是固定的
5.换行与分割线
| 标签 | 内容 |
|---|---|
<br> |
换行 |
<hr> |
分割线 |
<p>一体</p> <p>二体</p> <br> <p>一体</p> <p>二体</p> <p>三体</p> <hr> <p>四体</p> <p>五体</p>

六、body内其他重要的标签
1.无序列表
页面上所有的规则排列的横向或者竖向的
- 语法:
ul套li
<body> <ul> <li>上午</li> <li>中午</li> <li>下午</li> </ul> </body>
2.有序列表
ol 套 li
<body> <ol type="A"> <li>111</li> <li>222</li> <li>333</li> </ol> </body>
3.标题列表
d1 套 dt-大标题 套 dd-小标题
<dl> <dt>大标题</dt> <dd>小标题1</dd> <dd>小标题2</dd> </dl>
4.表格标签

<table border="4"> <thead> <tr> <th>编号</th> <th>姓名</th> <th>年龄</th> </tr> </thead> <tbody> <tr> <td>1</td> <td>jason</td> <td>18</td> <tr> </tbody> </table>
5.表单标签
可以获取用户的数据,并发送给服务端
1.表单标签简介
-
form标签
action 控制数据的提交地址
method 控制数据的提交方法
-
input标签
type类型 作用 text 普通文本 password 密文展示 date 日期选项 email 邮箱格式 radio 单选 checkbox 多选 file 文件 submit 触发提交动作 reset 重置表单内容 button 自定义功能
input标签应该有name属性
这样,在接受数据的时候,name属性相当于字典的键,input标签获得到用户数据相当于字典的值。
-
select标签
option标签 一个个选项
-
textarea标签 形成大段的文本框,获取大段文本
2.基于form表单发送数据
(1)用于获取用户数据的标签应含有name属性,name属性相当于字典的键
--如 <p>用户名: <input type="text" name="username"> </p>
用户输入的的数据会保存到标签的value属性中,value相当于字典的值

(2)如果用户仅需要选择,不需要填写数据,那么我们需要自己先在选择的标签中填写value值
如果标签中没有name属性,form表单会直接忽略,不会发送
<input type="radio" name="gender" value="male">男 当用户选择性别后会保存 "gender" : "male"
(3)input标签理论上应该搭配label标签使用,但是也可以不写
如:b站的投诉表单中
- input标签放在 label标签内使用
<label for="d1">用户名: <input type="text" id="d1" placeholder="请输入用户名" maxlength="30" name="username"> </label>
- input标签紧贴着label标签使用
<label for="d1">用户名:</label> <input type="text" id="d1" placeholder="请输入用户名" maxlength="30" name="username">
(4)标签的属性如果和值相等,可以不写值
<input type="file" multiple="multiple">
等价于
<input type="file" multiple>
(5)针对选择类型的标签可以提前设置默认选项
checked <input type="checkbox" checked="checked">11 <option value="" selected="selected">22</option> selected <option value="" selected="selected">111</option> <option value="" selected>222</option>
(6)一些选择性的标签可以用multiple属性从单选改为复选
<input type="file" multiple> <select name="" id="" multiple>
前端2:css
-html标签的两大重要属性
标签的两大重要属性的作用:用来区分标签
1.class属性
- 将标签分门别类,主要用于批量查找
2.id属性
-
精确查找标签,主要用于点对点
-
每个标签都可以设置唯一一个id
一、CSS语法结构
1.语法结构
**css语法:
① 选择器 ②声明(属性:值)
选择器{ 属性1:样式值1, 属性2:样式值2, ... }
2.CSS注释语法
注释语法支持:单行、多行
/*注释语法*/
3.引入CSS的多种方式
(1)嵌入式
在html 的 head标签内 style标签内部写
<style> h { color: cornflowerblue; } </style>
(2)外链式
html内通过link标签引入外部css文件
<link rel="stylesheet" href="mycss.css">
myscss.css文件
h1 { color: cornflowerblue; }
(3)内联样式(行内式)
在标签内部通过style属性直接编写
<h1 style="color: cornflowerblue">天天开心</h1>
不推荐使用,增加了耦合,拓展性较差
二、CSS选择器
1.CSS基本选择器
| css基本选择器 | 用法 | 作用 |
|---|---|---|
| 标签选择器 | 标签名称 { 属性名:属性值 } |
直接按照标签名查找标签,进行范围查询/批量查询 |
| 类选择器 | .class值 { 属性名:属性值 } |
按照标签的class值,查找标签 |
| id选择器 | #id值 { 属性名:属性值 } |
按照标签的id值,精准查找 |
| 通用选择器 | * { 属性名:属性值 } |
直接选择页面所有的标签 |
2.CSS组合选择器
对于标签的上下层级以及嵌套关系称呼:
祖先标签、父标签、后代标签、子标签、哥哥标签、弟弟标签、...
| css基本选择器 | 用法 | 作用 |
|---|---|---|
| 后代选择器 | 父标签 后代标签{ 属性名:属性值 } |
找到 标签 的 指定的所有后代标签 |
| 子标签选择器 | 父标签>子标签 { 属性名:属性值; } |
找到指定标签所有的指定的儿子标签(只指定儿子标签,不会查找其他嵌套的标签)** |
| 毗邻选择器 | 标签1 + 标签1同级别下面紧挨着的标签 { 属性名:属性值 } |
选择同级别下面紧挨着的标签 |
| 弟弟选择器 | 标签1>标签1的所有弟弟标签 { 属性名:属性值 } |
查找同级别下面所有的弟弟标签 |
3.选择器的分组与嵌套
(1)合并查找
多个选择器合并查找
- 语法
选择器1,选择器2,选择器3 { 属性名:属性值; }
(2)混合使用
选择器混合使用
- 查找class的值为c2的 div标签
div.c2 { color: red; }
- 查找id是d1的p标签
p#d1 { color: red; }
- 查找含有c1样式值(样式类)里面p标签中含有c2样式值的标签
.c1 p .c2{ color: red; }
4.属性选择器
- 按照属性名查找
[name]
- 按照属性名=属性值查找
[name="duoduo"]
- 查找
name为duoduo的所有div标签
div[name="duoduo"]
- 查找
name以duoduo为开头的所有div标签
div[name^="duoduo"]
- 查找
name以duoduo为结尾的所有div标签
div[name$="duoduo"]
- 查找
name中包含duoduo的所有div标签
div[name*="duoduo"]
5.伪类选择器
(1)a标签
a标签中,没有跳转过网址的a标签默认是蓝色,点击过的则为紫色
| a标签 | 代表的状态 |
|---|---|
| a:link | 未被访问过的初始状态 |
| a:hover | 鼠标悬浮在该目标时的状态 |
| a:active | 鼠标按下时的状态 |
| a:visited | 以及被访问过的状态 |
(2)input标签
获取焦点、失去焦点,焦点代指鼠标
input获取焦点(被点击)之后采用的样式
6.伪元素选择器
通过css来渲染文本
before和after用于清除浮动现象
| 标签 | 作用 |
|---|---|
| p:first-letter | 选择首字母进行CSS渲染 |
| p:before | 选择在文本开头CSS渲染 |
| p:after | 在文本末尾CSS渲染 |
css添加文本,在html中无法正常选中
三、选择器优先级
1.选择器相同,导入方式不同
就近原则,那个选择器靠下,使用那个选择器
2.选择器不同,导入方式不同
内联样式 > id选择器 > 类选择器 > 标签选择器
3.打破选择器优先级
!important 提升优先级
四、CSS的属性
1.字体样式
-
调整字体
font_family多个字体,从前往后匹配,如果没有第一种字体,则使用后面的字体
font_family:"微软雅黑","仿宋"
- 字体大小
font_size
font_size:48px;
- 字体粗细
font_weight
font_weight:lighter;
- 字体颜色
color
# 直接填写 color:red; # 编号 color:#3d3d3d; # rgb编码 color:rgb(0,0,0) rgba(0,0,0,0) 最后一位填写透明度
取色器工具
- 文本位置
text-align
text-align:center;
- 文本装饰
text-decoration
text-decoration:none 主要用于取消a标签的下划线
- 文本缩进
text-indent
页边距大小
text-indent:32px;
2.背景属性
- 宽度/长度:以像素为单位
width:800px; height:800px;
- 背景颜色
background-color
background-color: orange;
-
添加背景图片
url(网页链接/本地连接)图片如果超出指定像素大小,会自动截取或者自动铺满指定范围
background-image: url("网页链接"); background-image: url("本地链接");
- 背景重复
background-repeat
background-repeat:repeat(默认):背景图片平铺排满整个网页 background-repeat:repeat-x:背景图片只在水平方向上平铺 background-repeat:repeat-y:背景图片只在垂直方向上平铺 background-repeat:no-repeat:背景图片不平铺
- 背景位置
background-position
background-position: center center
当属性名相同时,可以采用便捷写法
background: url("链接") blue no-repeat center center;
- 背景附着
background-attachment
| 属性值 | 含义 |
|---|---|
| fixed | 背景图像相对于窗体固定。任凭页面内容滚动,背景图像始终静止不动 |
| scroll | 背景图像相对于元素固定。当窗体的内容滚动时,窗体的背景图像会跟着移动;当一般元素的内容滚动时,背景图像不会跟着移动,因为背景图像总是要跟着元素本身,但会随元素的祖先元素或窗体一起移动 |
| local | 背景图像相对于元素的内容固定。当元素的内容滚动时,背景图像总是要跟着内容一起移动 |
3.边框样式
-
边框宽度
width边框颜色colorleft right top bottom指定方向
border-left-width: 5px; border-left-color: #ff0000;
- 边框样式
style
| 值 | 作用 |
|---|---|
| none | 无边框 |
| dotted | 点状虚线边框 |
| dashed | 矩形虚线边框 |
| solid | 实线边框 |
- 画圆radius
.c1{ width: 150px; height: 150px; border:4px dashed dodgerblue; border-radius: 100%; } .c2 { width: 180px; height: 40px; border:4px dotted red; border-radius: 50%; } .c3 { width: 180px; height: 36px; border: 4px solid pink; border-radius: 20px; }
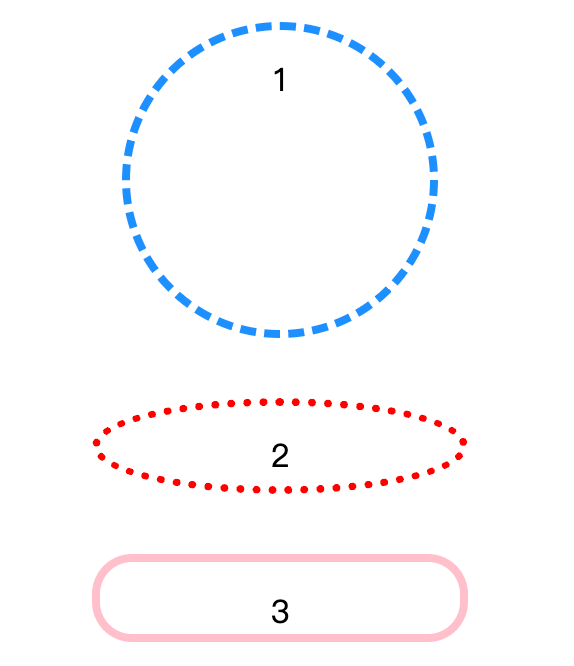
4.display属性
| 值 | 意义 |
|---|---|
| display:"none" | HTML文档中元素存在,但是在浏览器中不显示,并且不占空间。一般用于配合JavaScript代码使用。 |
| display:"block" | 设置成 块级标签默认占满整个页面宽度,如果设置了指定宽度,则会用margin填充剩下的部分。 |
| display:"inline" | 设置成 行内标签,此时再设置元素的width、height、margin-top、margin-bottom和float属性都不会有什么影响。 |
| display:"inline-block" | 设置成 行内块级标签,使元素同时具有行内元素和块级元素的特点。 |
-
将标签隐藏起来
页面上不会显示,也不会保留标签的位置
display: none
visibility属性也可以隐藏,但是会保留标签的位置
<div>1111</div> <div style="visibility: hidden">2222</div> <div>3333</div>

五、盒子模型
我们可以将标签看成是一个快递盒,主要指div标签
- 快递盒子里面有什么?
1.快递盒子中有实际物品----content内容
2.物体与内部盒子墙之间的距离----padding内边距、内填充
3.快递盒的厚度----border边框
4.两个盒子之间的距离----margin外边距
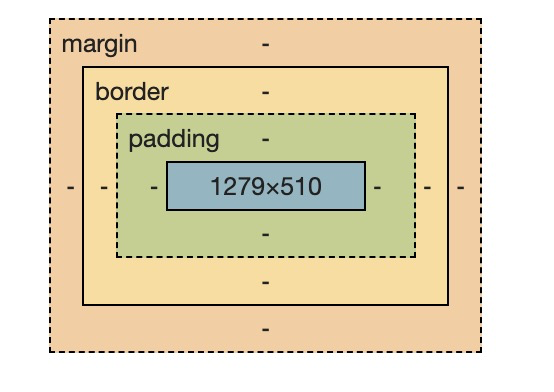
- padding
padding属性值的顺序:上 右 下 左
padding-left: 50px; padding-top: 60px; padding-right: 10px; padding-bottom: 60px;
- margin
div { border:4px solid dodgerblue; margin-top: 20px; /* margin:参数顺序 */ }
五、浮动
1.浮动简介
浮动:使得标签内容脱离了正常的平面
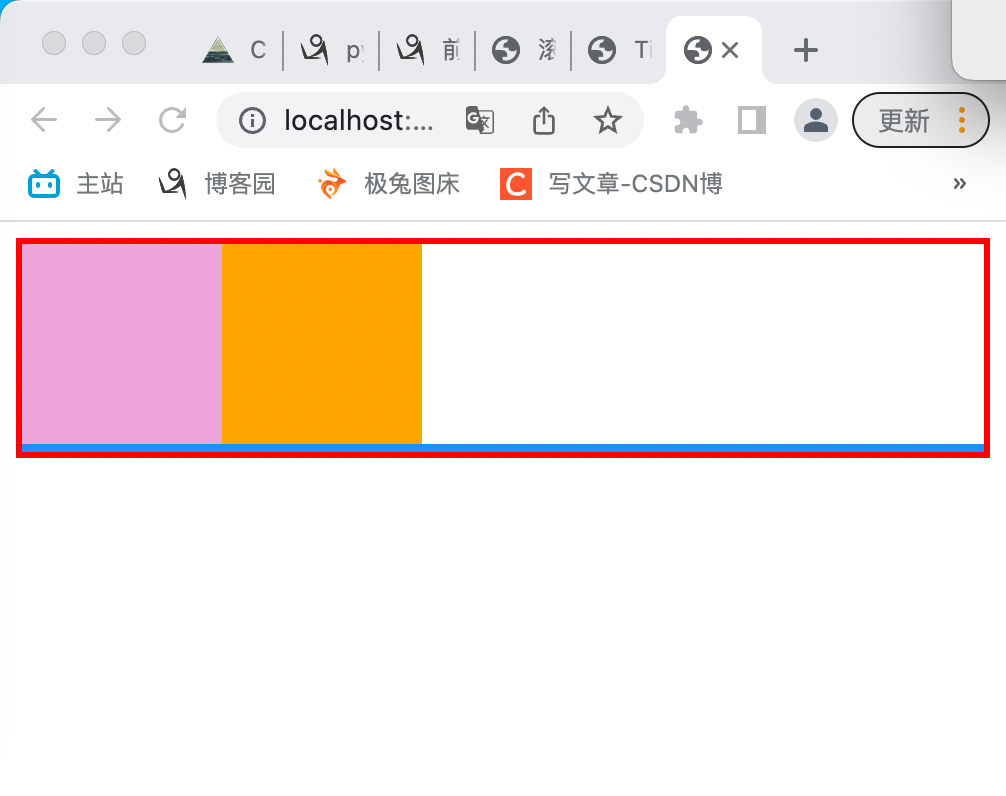
2.浮动造成的塌陷现象
浮动的元素是脱离正常文档流的,会造成父标签塌陷
让父标签不塌陷,则需要一个c4来让两个子div显示上还在父标签内
3.通过clear属性来避免浮动
- clear属性
| 值 | 描述 |
|---|---|
| left | 在左侧不允许浮动元素。 |
| right | 在右侧不允许浮动元素。 |
| both | 在左右两侧均不允许浮动元素。 |
| none | 默认值。允许浮动元素出现在两侧。 |
| inherit | 规定应该从父元素继承 clear 属性的值。 |
注意:clear属性只会对自身起作用,而不会影响其他元素。
.c4 { clear:left; border:2px solid dodgerblue; } clear:left 左侧(包含地面、天空)不允许出现浮动的元素
-
解决浮动带来的塌陷影响
可以通过clear属性和伪元素器选择器,定义一个clearfix的属性,谁塌了给谁装上这个选择器
# 新建类clearfix,并指明再标签末尾添加空白内容,并指定其为块级标签,且通过clear属性指定两边不允许出现浮动 .clearfix:after { content:''; display: block; clear: both; } # 为父标签装上classfix <div class="c1 clearfix" id="d1">
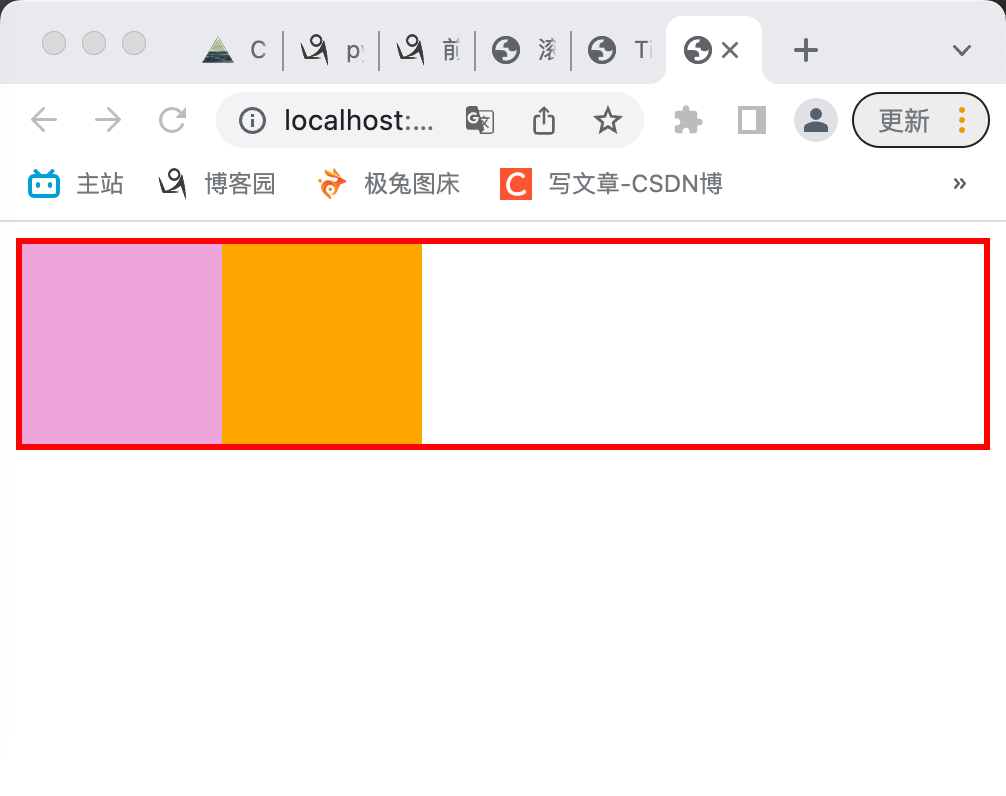
浏览器会优先展示文本内容,如果内容被挡住了会自动展示文字
六、 overflow溢出属性
- overflow(水平和垂直均设置)
- overflow-x(设置水平方向)
- overflow-y(设置垂直方向)
| 值 | 描述 |
|---|---|
| visible | 默认值,内容不会被修剪,会呈现在元素框之外。 |
| hidden | 内容会被修剪,并且其余内容是不可见的。 |
| scroll | 内容会被修剪,但是浏览器会显示滚动条以便查看其余的内容。 |
| auto | 如果内容被修剪,则浏览器会显示滚动条以便查看其余的内容。 |
| inherit | 规定应该从父元素继承 overflow 属性的值。 |
七、定位
标签在默认情况下都是static静态的,无法通过定位的参数来移动
1.定位为四种状态
| 状态 | 现象 |
|---|---|
| static静态 | 标签默认的状态 |
| relative相对定位 | 基于标签原来的位置 |
| absolute绝对定位 | 基于某个定位过的父标签做定位 |
| fixed固定定位 | 基于浏览器窗口固定不动 |
2.z-index
选择器中的z-index属性,可以控制三维坐标对z轴的距离


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY