

并发编程:多线程、GIL、协程
一、多进程实现TCP服务器并发
1.服务端
import socket from threading import Thread # 套字节 TCP协议 server = socket.socket() # 绑定ip与port server.bind(('127.0.0.1', 8081)) # 连接池 子线程 客户端连接 不受连接池限制所影响! server.listen(2) # 执行程序 def talk(sock): # 循环接收客户端数据 while True: # 异常捕获 try: # 固定每次接收数据, data = sock.recv(1024) # 判断接收是否为空 if len(data) == 0: break # 将接收数据解码 print(data.decode('utf8')) # 发送数据 sock.send(data + b'hello') except ConnectionResetError as e: print(e) break # 结束套字节 sock.close() # 调用执行程序 while True: # 循环 被动客户端连接 并返回(sock,addr)sock是通信,发送数据与接收数据 # addr是客户端地址 sock, addr = server.accept() print(addr) # 开设多进程或者多线程 t = Thread(target=talk, args=(sock,)) # 执行打开子线程 t.start()
2.客户端
import socket client = socket.socket() # 连接服务端ip与port端口 client.connect(('127.0.0.1', 8081)) while True: # 获取用户输入 msg = input('发送给服务端>>>') # 发送数据 并编码 client.send(msg.encode('utf8')) # 接收服务端数据 data = client.recv(1024) # 解码并打印 print(data.decode('utf8'))

可以看到建立的客户端超过了半连接池的缓冲数量,说明此时创建的客户端并不是多进程
二、线程
1.什么是线程
每个进程都有自己的地址空间,即进程空间。一个服务器通常需要接收大量并发请求,为每一个请求都创建一个进程系统开销大、请求响应效率低,因此操作系统引进线程。
进程:进程其实是资源单位,表示一块内存空间
线程:线程才是执行单位,表示真正的代码指令
我们可以将进程比喻是工厂的车间,线程是车间里面的流水线
一个进程内部至少含有一个线程

2.进程与线程的关系
(1)一个进程内可以开设多个线程
(2)同一个进程下的多个线程数据是共享的
(3)创建进程与线程的区别:创建进程的消耗要远远大于线程
3.创建线程的两种方式
在python中,为了简化进程和线程除了名字不同,操作、方法和思路都是一致的
创建进程的前提:1.重新申请一块内存空间 ;2.将所需的资源全部导入
创建线程的前提:不需要和进程一样,所以说开设线程消耗的资源远远小于开设进程
(1)Thread产生线程对象
from threading import Thread from multiprocessing import Process import time def task(name): print(f'{name} is running') time.sleep(0.1) print(f'{name} is over') if __name__ == '__main__': start_time = time.time() # p_list = [] # for i in range(100): # p = Process(target=task, args=('用户%s' % i,)) # 创建进程 # p.start() # p_list.append(p) # for p in p_list: # p.join() # print(time.time() - start_time) # 0.7946369647979736 t_list = [] for i in range(100): t = Thread(target=task, args=('用户%s' % i,)) # 创建线程 t.start() t_list.append(t) for t in t_list: t.join() print(time.time() - start_time) # 0.10670590400695801 t = Thread(target=task, args=('jason',)) t.start() print('主线程')
可以看出同样执行相同数量的task函数,
多进程用了0.7s,多线程用了0.1s;
多进程的速度比多线程慢很多,也就是说对于计算机来说,创建进程的资源消耗比线程大的多。
(2)继承Thread类创建线程
class MyThread(Thread): def run(self): print('run is running') time.sleep(1) print('run is over') obj = MyThread() obj.start() print('主线程')
4.线程对象的其他方法
| 方法 | 作用 |
|---|---|
join() |
让主线程在子线程结束后在运行 |
| active_count | 统计当前正在活跃的线程数 |
| current_thread | 查看主线程名字 |
from threading import Thread,active_count,current_thread import time import os def test(name): # 查看子线程 进程进程号 print(os.getpid()) # 查看子线程 名字 print(current_thread().name) print('%s is running' % name) time.sleep(3) print('%s is over' % name) # 创建子线程 t = Thread(target=test, args=('jason',)) # 执行子线程 t.start() print(os.getpid()) # 先执行子线程 再执行主线程 t.join() # 查看主线程名字 print(current_thread().name) # 查看主线程 进程号 print(active_count()) print('主线程')
5.同进程内多个线程数据共享
在同一个进程中的多个线程数据是可以共享的
from threading import Thread money = 100 def test(): global money money = 999 t = Thread(target=test) t.start() t.join() print(money) =======运行结果============= 999 # 线程运行则可以改变变量的值
三、互斥锁代码实操
1.互斥锁的作用
互斥锁就可以实现将并发变成串行的效果
(1)通过执行结果可以地址互斥锁能够保证多个线程访问共享数据不会出现数据错误问题
(2)操作同一份数据不能并发,并发情况下操作同一份数据,极其容易造成数据错乱
(3)互斥锁对共享数据进行锁定,保证同一时刻只能有一个线程/进程去操作。
注意:加锁处理,互斥锁不能乱加,只能在操作数据中方面

2.互斥锁代码
from threading import Thread, Lock from multiprocessing import Lock import time num = 101 # 修改数值 def test(mutex): # 局部修改全局 global num # 上锁(一次只有一个人可以通过) mutex.acquire() # 先获取num的数值 tmp = num # 模拟延迟效果 time.sleep(0.1) # 定义的变量数据 - 循环访问数量 tmp -= 1 num = tmp # 释放锁 mutex.release() # 定义空字典 t_list = [] # 创建 互斥锁 mutex = Lock() # 循环1-100 for i in range(100): # 创建子线程 t = Thread(target=test, args=(mutex,)) # 执行子线程 t.start() # 将执行子线程 添加到空列表 t_list.append(t) # 确保所有的子线程全部结束 for t in t_list: # 串行 先执行子线程 再执行主线程 t.join() print(num)
四、GIL全局解释器锁
GIL本质就是一把互斥锁,是夹在解释器身上的,同一个进程内的所有线程都需要先抢到GIl锁,才能执行解释器代码
1.python官方文档对GIL的解释
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.
在CPython中,全局解释器锁(GIL)是一个互斥锁,它可以防止多个本地线程同时执行Python字节码。这个锁是必要的,主要是因为CPython的内存管理不是线程安全的。(然而,自从GIL存在以来,其他特性已经依赖于它强制执行的保证。)
也就是说GIL防止了垃圾回收机制这个线程对数据的不正确回收,GIL只能够确保同进程内多线程数据不会被垃圾回收机制弄乱 ,并不能确保程序里面的数据是否安全
2.GIL的优缺点
优点:保证Cpython解释器内存管理的线程安全
缺点:同一个进程内所有的线程同一时刻只能有一个执行,也就是说Cpython解释器的多线程无法实现并行,无法取得多核优势
3.GIL代码体现
import time from threading import Thread,Lock num = 100 def task(mutex): global num mutex.acquire() count = num time.sleep(0.1) num = count - 1 mutex.release() mutex = Lock() t_list = [] for i in range(100): t = Thread(target=task,args=(mutex,)) t.start() t_list.append(t) for t in t_list: t.join() print(num) ====== 0
4.GIL与Lock
GIL锁:保护的是解释器级别的数据
Lock锁:保护的是用户自己的数据
五、多进程与多线程
1.多进程与多线程的应用
多线程用于IO密集型,如socket,爬虫,web
多进程用于计算密集型,如金融分析
2.单个CPU
IO密集型:
多进程:申请额外的空间,消耗更多的资源
多线程:消耗资源相对较少,通过多道技术
---->>>多线程有优势
计算密集型:
多进程:申请额外的空间,消耗更多的资源(总耗时+申请空间+拷贝代码+切换)
多线程:消耗资源相对较少,通过多道技术(总耗时+切换)
---->>>多线程有优势
3.多个CPU
IO密集型:
多进程:总耗时(单个进程的耗时+IO+申请空间+拷贝代码)
多线程:总耗时(单个进程的耗时+IO)
---->>>多线程有优势
计算密集型:
多进程:总耗时(单个进程的耗时)
多线程:总耗时(多个进程的综合)
---->>>多进程有优势
4.代码实操
(1)计算密集型
from threading import Thread from multiprocessing import Process import os import time def work(): # 计算密集型 res = 1 for i in range(1, 100000): res *= i
1)多进程
if __name__ == '__main__': # print(os.cpu_count()) # 8 查看当前计算机CPU个数 start_time = time.time() t_list = [] for i in range(12): t = Thread(target=work) t.start() t_list.append(t) for t in t_list: t.join() print('总耗时:%s' % (time.time() - start_time)) # 获取总的耗时 =================== 总耗时:8.680426120758057
2)多线程
t_list = [] for i in range(12): t = Thread(target=work) t.start() t_list.append(t) for t in t_list: t.join() print('总耗时:%s' % (time.time() - start_time)) # 获取总的耗时 =================== 总耗时:49.58696484565735
(2)IO密集型
def work(): time.sleep(2) # 模拟纯IO操作
1)多进程
if __name__ == '__main__': start_time = time.time() p_list = [] for i in range(100): p = Process(target=work) p.start() for p in p_list: p.join() print('总耗时:%s' % (time.time() - start_time)) =================== 总耗时:0.6814162731170654
2)多线程
if __name__ == '__main__': start_time = time.time() t_list = [] for i in range(100): t = Thread(target=work) t.start() for t in t_list: t.join() print('总耗时:%s' % (time.time() - start_time)) =================== 总耗时:0.0032329559326171875
总结:
计算密集型使用多进程
IO密集型使用多线程
六、死锁现象
1.死锁现象简介
(1)是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程
(2)在多道程序系统中,由于多个进程的并发执行,改善了系统资源的利用率并提高了系统的处理能力。然而,多个进程的并发执行也带来了新的问题——死锁。所谓死锁是指多个进程因竞争资源而造成的一种僵局,若无外力作用,这些进程都将无法向前推进。
from threading import Thread, Lock import time A = Lock() B = Lock() class MyThread(Thread): def run(self): self.func1() self.func2() def func1(self): A.acquire() print('%s 抢到了A锁' % self.name) # current_thread().name 获取线程名称 B.acquire() print('%s 抢到了B锁' % self.name) time.sleep(1) B.release() print('%s 释放了B锁' % self.name) A.release() print('%s 释放了A锁' % self.name) def func2(self): B.acquire() print('%s 抢到了B锁' % self.name) A.acquire() print('%s 抢到了A锁' % self.name) A.release() print('%s 释放了A锁' % self.name) B.release() print('%s 释放了B锁' % self.name) for i in range(10): obj = MyThread() obj.start()
Thread-1 先开始执行func1,先拿到A锁B锁,然后释放A锁B锁
Thread-1 先执行func2,先拿到了B锁,开始sleep
Thread-2 先拿到了A锁 这时候形成了僵局,线程2想要线程1手里的B锁,线程1想要线程2里的A锁,这时候没有其他介入的情况下,就出现了程序卡着不动了。

七、信号量
在python并发编程中信号量相当于多把互斥锁
信号量:Semaphore
from threading import Thread, Lock, Semaphore import time import random sp = Semaphore(5) # 可以看作一次性产生了5把互斥锁 class MyThread(Thread): def run(self): sp.acquire() print(self.name) time.sleep(random.randint(1, 3)) sp.release() for i in range(10): t = MyThread() t.start()

八、event事件
事件和触发器类似,都是在某些事情发生的时候启动,也就是在某些条件下自动触发
from threading import Thread, Event import time event = Event() # 类似于造了一个红绿灯 def light(): print('红灯亮着的 所有人都不能动') time.sleep(3) print('绿灯亮了 油门踩到底 给我冲!!!') event.set() def car(name): print('%s正在等红灯' % name) event.wait() print('%s加油门 飙车了' % name) t = Thread(target=light) t.start() for i in range(5): t = Thread(target=car, args=('熊猫PRO%s' % i,)) t.start()

九、进程池与线程池
1.池的概念
在保证计算机硬件不奔溃的前提下开设多进程和多线程,降低了程序的运行效率但是保证了计算机硬件的安全,池的功能是限制启动的进程数或线程数。
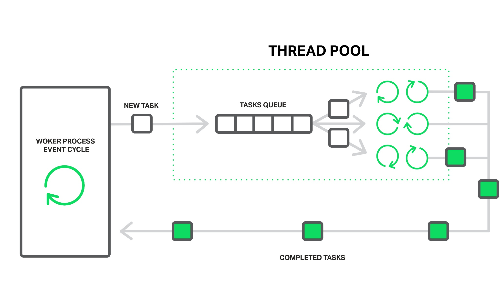
进程池:提前创建好固定数量的进程供后续程序的调用,超出则等待
线程池:提前创建好固定数量的线程供后续程序的调用,超出则等待
2.池的使用环境
当并发的任务数远远超过了计算机的承受能力时,即无法一次性开启过多的进程数或线程数时,就应该用池的概念将开启的进程数或线程数限制在计算机可承受的范围内
进程和线程能否无限制的创建?
不可以,因为硬件的发展赶不上软件,有物理极限,如果我们在编写代码的过程中无限制的创建进程或者线程可能会导致计算机奔溃
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor import os import time import random from threading import current_thread # 1.产生含有固定数量线程的线程池 # pool = ThreadPoolExecutor(10) pool = ProcessPoolExecutor(5) def task(n): print('task is running') time.sleep(random.randint(1, 3)) print('task is over', n, current_thread().name) print('task is over', os.getpid()) return '我是task函数的返回值' def func(*args, **kwargs): print('from func') if __name__ == '__main__': # 2.将任务提交给线程池即可 for i in range(20): res = pool.submit(task, 123) # 朝线程池提交任务 print(res.result()) # 不能直接获取 pool.submit(task, 123).add_done_callback(func) # 反馈机制,自动将结果返回

十、协程
1.如何理解协程
进程:可以看作是资源单位
线程:可以看作是执行单位
协程:可以在单线程下实现并发,特点是将程序的效率提高
实际做法:
在代码层面欺骗CPU 让CPU觉得我们的代码里面没有IO操作,实际上IO操作被我们自己写的代码检测,一旦有检测到有IO操作,立刻让代码执行别的代码,欺骗CPU
核心:编写代码完成多道的-->切换+保存状态
2.协程的作用
让原本是CPU切换线程 变成 程序切换线程
3.猴子补丁
猴子补丁monkey patch是指在运行时动态替换已有代码,而不需要修改原始代码。
猴子补丁主要用于在不修改已有代码的情况下修改其功能成增加对新功能的支持。例如,在使用第三方模块时,模块中的莱些方法可能无法满足我们的开发需求。此时,我们可以在不修改这些方法代码的情况下,通过猴子补丁用一些自己编写的新方法对共选行替代,从而实现一些新的功能。
4.协程代码实现检测IO操作
import time from gevent import monkey; monkey.patch_all() # 固定编写 用于检测所有的IO操作(猴子补丁) from gevent import spawn def func1(): print('func1 running') time.sleep(3) print('func1 over') def func2(): print('func2 running') time.sleep(5) print('func2 over') if __name__ == '__main__': start_time = time.time() # func1() # func2() s1 = spawn(func1) # 检测代码 一旦有IO自动切换(执行没有io的操作 变向的等待io结束) s2 = spawn(func2) s1.join() s2.join() print(time.time() - start_time)
5.协程实现并发
import socket from gevent import monkey;monkey.patch_all() # 固定编写 用于检测所有的IO操作(猴子补丁) from gevent import spawn def communication(sock): while True: data = sock.recv(1024) print(data.decode('utf8')) sock.send(data.upper()) def get_server(): server = socket.socket() server.bind(('127.0.0.1', 8080)) server.listen(5) while True: sock, addr = server.accept() # IO操作 spawn(communication, sock) s1 = spawn(get_server) s1.join()


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY