+数据类型内置方法下 字典、元组、集合、字符编码理论
§一、字典的内置方法
1、字典的类型转换dict()
| |
| dict() |
| 字典的转换一般不使用关键字,而是自己手动转换 |
| |
| |
| a = [['jack', 123],['uzi', 123]] |
| res = dict(a) |
| print(res) |
| |
| 可以看出来字典的转换在格式上有很多限制,所以一般不用 |
2、字典相关操作
1.按key取值(不推荐使用)
| |
| 字典名['k值'] |
| |
| lpl = { |
| 'tes': 'jackeylove', |
| 'jdg': 369, |
| 'edg': ['viper', 'meiko', 'scout'] |
| } |
| print(lpl['tes']) |
| print(lpl['rng']) |
2.按内置方法get取值(推荐使用)
| |
| 字典+ .get('要取的values的keys') |
| |
| 1.正确取值 |
| print(lpl.get('edg')) |
| ------------------ |
| ['viper', 'meiko', 'scout'] |
| 2.要取的keys不存在 |
| print(lpl.get('rng')) |
| ------------------ |
| None |
| 3.进阶用法 |
| 字典+ .get('要取的values','当不存在对应的keys时返回这串字符') |
| print(lpl.get('edg','当不存在对应的keys时返回这串字符')) |
| print(lpl.get('rng','当不存在对应的keys时返回这串字符')) |
| ------------------ |
| ['viper', 'meiko', 'scout'] |
| 当不存在对应的keys时返回这串字符 |
3.修改数据值
| |
| 字典['要改变values的keys'] = '要改变的values' |
| |
| 当要改变的键存在 |
| |
| print(id(lpl)) |
| lpl['tes'] = 'knight' |
| print(lpl) |
| print(id(lpl)) |
| ------------------ |
| 4367933568 |
| {'tes': 'knight', 'jdg': 369, 'edg': ['viper', 'meiko', 'scout']} |
| 4367933568 |
4.新增键值对
| |
| 字典['要增加的keys'] = '要增加的values' |
| |
| |
| lpl['rng'] = 'knight' |
| print(lpl) |
| ------------------ |
| {'tes': 'jackeylove', 'jdg': 369, 'edg': ['viper', 'meiko', 'scout'], 'rng': 'knight'} |
5.删除数据del 、pop
| 1.del |
| |
| del +字典['要删除的keys'] |
| |
| del lpl['tes'] |
| print(lpl) |
| ------------------ |
| {'jdg': 369, 'edg': ['viper', 'meiko', 'scout']} |
| |
| 2.pop 弹出 |
| 字典.pop('要弹出的keys') |
| |
| a = lpl.pop('tes') |
| print(lpl) |
| print(a) |
| ------------------ |
| {'jdg': 369, 'edg': ['viper', 'meiko', 'scout']} |
| jackeylove |
| |
| 3.popitem |
| popitem() 用来随机删除一个键值对 |
| |
| print(lpl1.popitem()) |
| ----------------- |
| ('edg', ['viper', 'meiko', 'scout']) |
6.统计字典中键值对的个数 len()
| len(要统计的字典) |
| |
| print(len(lpl)) |
7.字典三剑客
| 字典.keys() |
| |
| print(lpl.keys()) |
| ------------------ |
| dict_keys(['tes', 'jdg', 'edg']) |
| 字典.values() |
| |
| print(lpl.values()) |
| ------------------ |
| dict_values(['jackeylove', 369, ['viper', 'meiko', 'scout']]) |
| 字典.items() |
| |
| print(lpl.keys()) |
| ------------------ |
| dict_items([('tes', 'jackeylove'), ('jdg', 369), ('edg', ['viper', 'meiko', 'scout'])]) |
8.补充说明
| |
| dict.fromkeys(['要生成的列表的keys'], 要生成的数据值values) |
| |
| |
| print(dict.fromkeys(['faker','chovy','ruler'],123)) |
| res = dict.fromkeys(['faker','chovy','ruler'],[]) |
| print(res) |
| ------------------ |
| {'faker': 123, 'chovy': 123, 'ruler': 123} |
| {'faker': [], 'chovy': [], 'ruler': []} |
| '''当第二个公共值是可变类型的时候 一定要注意 通过任何一个键修改都会影响所有''' |
| |
| lpl = {'tes':[],'edg':[], 'jdg':[]} |
| lpl['tes'].append('jason') |
| lpl['edg'].append(123) |
| lpl['jdg'].append('study') |
| print(lpl) |
| ------------------ |
| {'tes': ['jason'], 'edg': [123], 'jdg': ['study']} |
| setdefault() 方法用来返回某个 key 对应的 value |
| 当指定的 key 不存在时,setdefault() 会先为这个不存在的 key 设置一个默认的 defaultvalue,然后再返回 defaultvalue。 |
| 也就是说,setdefault() 方法总能返回指定 key 对应的 value: |
| |
| 1.如果该 key 存在,那么直接返回该 key 对应的 value; |
| 2.如果该 key 不存在,那么先为该 key 设置默认的 defaultvalue,然后再返回该 key 对应的 defaultvalue。 |
| |
| a = {'数学': 95, '语文': 89, '英语': 90} |
| print(a) |
| |
| a.setdefault('物理', 94) |
| print(a) |
| |
| a.setdefault('化学') |
| print(a) |
| |
| a.setdefault('数学', 100) |
| print(a) |
| ------------------ |
| {'数学': 95, '语文': 89, '英语': 90} |
| {'数学': 95, '语文': 89, '英语': 90, '物理': 94} |
| {'数学': 95, '语文': 89, '英语': 90, '物理': 94, '化学': None} |
| {'数学': 95, '语文': 89, '英语': 90, '物理': 94, '化学': None} |
§二、元组的内置方法
1、类型转换
| |
| tuple() 支持for循环的数据类型都可以转换为元组 |
2、元组必须掌握的方法
1.索引取值、切片间隔
| 1.索引取值 |
| 元组[索引值] |
| |
| 2.切片间隔 |
| 元组[起始索引:结束索引:步长step] |
2.统计元组内数据值的个数len
| tup = (11, 22, 11, 22, 33, 44, 55, 123, 123, 321) |
| print(len(tup)) |
| ------------------ |
| 10 |
3.统计元组内某个数据值出现的次数count
| 元组.count(数据值) |
| |
| tup = (11, 22, 11, 22, 33, 44, 55, 123, 123, 321) |
| print(tup.count(11)) |
| ------------------ |
| 2 |
4.统计元组内制定数据值的索引值index
| Index访问元组中的某个元素,得到的是这个元素的索引值 |
| |
| print(tup.index(22)) |
| ------------------ |
| 1 |
5.关于元组的注意要点
- 元组内如果只要一个数据值那么逗号不能少
- 元组内索引绑定的内存地址不能被修改(注意区分 可变与不可变)
- 元组内不能新增或者删除数据
§三、集合的内置方法
1、类型转换
集合常常应于 去重和关心运算
2、set集合做交集、并集、差集运算
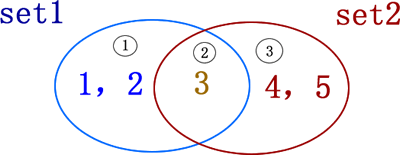
| 运算操作 |
运算符 |
含义 |
例子 |
| 交集 |
& |
取两集合公共的元素 |
set1 & set2 |
| 并集 |
| |
取两集合全部的元素 |
set1 | set2 |
| 差集 |
- |
取一个集合中另一集合没有的元素 |
set1 - set2 {1,2} set2 - set1 |
| 对称差集 |
^ |
取集合 A 和 B 中不属于 A&B 的元素 |
set1 ^ set2 |
| 1. 取交集 intersection() |
| set3 = set1.intersection() |
| 2. 判断子集 issuperset() |
| set1.issuperset(set2) 判断 set2 是否是 set1 的子集 |
| |
| |
| print(set1 > set2) |
| print(set1 < set2) |
§四、字符编码理论
1、理论了解及发展史
| 1.字符编码只针对文本数据 |
| 2.回忆计算机内部存储数据的本质 |
| 3.既然计算机内部只认识01 为什么我们却可以敲出人类各式各样的字符 |
| 肯定存在一个数字跟字符的对应关系 存储该关系的地方称为>>>:字符编码本 |
| 4.字符编码发展史 |
| 4.1.一家独大 |
| ASCII码:记录了英文字母跟数字的对应关系 |
| |
| |
| 4.2.群雄割据 |
| |
| GBK码:记录了英文、中文与数字的对应关系 |
| 用至少16bit(2字节)来表示一个中文字符,很多生僻字还需要使用更多的字节,英文还是用8bit(1字节)来表示 |
| |
| shift_JIS码:记录了英文、日文与数字的对应关系 |
| |
| Euc_kr码:记录了英文、韩文与数字的对应关系 |
| """ |
| 每个国家的计算机使用的都是自己定制的编码本,不同国家的文本数据无法直接交互 会出现"乱码" |
| """ |
| 4.3.天下一统 |
| |
| 兼容所有国家语言字符,起步就是两个字节来表示字符 |
| |
| 专门用于优化unocide存储问题,英文还是采用一个字节,中文三个字节 |
2、字符编码实操
| 1.当我们遇到乱码不要慌,切换编码试一试即可 |
| 2.编码与解码 |
| 编码:将人类的字符按照指定的编码编码成计算机能够读懂的数据 |
| |
| 解码:将计算机能够读懂的数据按照指定的编码解码成人能够读懂 |
| |
| 3.python2与python3差异 |
| python2默认的编码是ASCII |
| 1.文件头 |
| |
| 2.字符串前面加u |
| u'你好啊' |
| python3默认的编码是utf系列(unicode) |




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY