ES基础知识
ES本身也是一种数据库(nosql数据库)跟关系数据库存在如下关系
| 关系数据库 | ES |
| database数据库 | index索引库 |
| table表 | type类型 |
| row行 | document文档 |
| column列 | field字段 |
ES提供的api接口
| method | url地址 | 描述 |
| PUT | http://*9200/索引名称/类型名称/文档ID | 创建文档(指定文档id) |
| post | http://*9200/索引名称/类型名称 | 创建文档(随机文档id) |
| post | http://*9200/索引名称/类型名称/文档id/_update | 修改文档 |
| delete | http://*9200/索引名称/类型名称/文档ID | 删除文档 |
| get | http://*9200/索引名称/类型名称/文档ID | 通过文档ID查询 |
| post | http://*9200/索引名称/类型名称/_search | 查询所有数据 |
数据类型
字符串:text,keyword
数值: long,integer,short,byte,double,float,half float,scaled float
日期类型:date
布尔类型:boolean
二进制类型:binary
注意:
text会分词
keyword:也是字符串,但不会被分词
ES索引基本操作


PUT my_index #设置索引名称 { "settings": { #设置 "index": { #索引 "number_of_shards":5, #设置分片数 "number_of_replicas":1 #设置副本数 } } }
#获取指定索引的设置信息
GET my_index/_settings
#获取所有索引的设置信息
GET _all/_settings
#获取多个索引的设置信息
#GET 索引名称,索引名称/_settings
GET my_index,my_store/_settings
PUT /my_index/user/1 { "name":"张三", "age": 12 } PUT /test_find/it_job/1 { "post_name":"Java开发攻城狮", "address":"北京" }
通过设置索引规则创建索引
PUT /test
{
"mappings":{
"properties": {
"name":{
"type":"text"
},
"age":{
"type":"long"
},
"sex":{
"type":"text"
}
}
}
}
注意:索引名称
必须是小写
不能包含:\,/,*, ?, ", <, >, |, (空格),,, #
在ES7.0以前索引名可以包含冒号,但是7.0之后不支持了
不能以-,_和+开头
不能是.或..
长度不能超过255字节
#获取整个索引下的数据 GET /my_index #获取某个文档的数据 GET /my_index/_doc/1 #获取某个文档的数据的某个字段 GET /my_index/_doc/1?_source=name #只获取文档内容不要元数据 GET /my_index/_doc/1/_source #查询指定索引的全部信息 GET /my_index/_search
/_search:在所有的索引中搜索所有的类型 /my_index/_search:在 my_index 索引中搜索所有的类型 /my_index,test_find/_search:在 my_index 和test_find索引中搜索所有的类型 /m*,t*/_search:在所有以m和t开头的索引中所有所有的类型 /my_index/user/_search:在my_index索引中搜索user类型 /my_index,test_find/user,it_job/_search:在my_index和test_find索引上搜索user和it_job类型 /_all/user,it_job/_search:在所有的索引中搜索user和it_job类型
#方法一:在原有PUT创建索引时直接进行覆盖操作 PUT /my_index/user/1 { "name":"朝夕教育-123" } #缺陷:相当于再次创建没有传入的参数会为空 #方法二 POST /my_index/user/1/_update { "doc":{ "name": "朝夕教育-123" } } #没有传入的参数不会为空
6、删除索引
#根据Id删除指定文档
DELETE /my_index/user/1
#删除索引(删除整个索引库)
DELETE /my_index
7、复杂操作
7.1、批量添加数据
POST /my_index2/_doc/_bulk
{ "index": { "_id": 1 }}
{ "name" : "测试1", "age" :20,"desc":"菜鸟一个","tages":["程序猿","菜鸟","爱学习"] }
{ "index": { "_id": 2 }}
{ "name" : "测试2", "age" :5,"desc":"测试","tages":["程序猿","攻城狮","直男"] }
bulk批量操作可以在单次API调用中实现多个文档的create、index、update或delete。这可以大大提高索引速度
bulk请求体如下
{ action: { metadata }}
{ request body }
action必须是以下几种
| 行为 | 解释 |
| create | 当文档不存在时创建 |
| index | 创建新文档或者替换已有文档 |
| update | 局部更新文档 |
| delete | 删除一个文档 |
加入现在要给my_index2的_doc中新增一个文档
POST _bulk
{"create": {"_index": "my_index2", "_type": "_doc", "_id": 12}}
{"name": "test_bulk", "counter":"100"}
7.2、带条件的简单查询
GET /my_index2/_doc/_search?q=name:test_bulk
多个参数用&分开
7.3、叶子语句
叶子语句:就像match语句,被用于将查询的字符串与一个字段或多个字段进行对比(单个条件)
GET /my_index2/_doc/_search { "query": { "match": { "name": "test_bulk" } } }
7.4、复合查询
可以多个查询条件进行合并,比如一个bool语句,允许你在需要的时候组合其他语句,包括must,must_not,should和filter语句(多条件组合查询)
GET /my_index2/_doc/_search { "query": { "bool": { "must": [ { "match": { "name": "张三" } } ], "must_not": [ { "match": { "age": "5" } } ], "should": [ { "match": { "desc": "快" } } ], "filter": { "term": { "tages": "4561" } } } } }
说明:
must:表示文档一定要包含查询的内容
must_not:表示文档一定不要包含查询的内容
should:表示如果文档匹配上可以增加文档相关性得分
事实上我们可以使用两种结构化语句:
结构化查询query DSL
用于检查内容与条件是否匹配,内容查询中使用的bool和match字句,用于计算每个文档的匹配得分,元字段_score表示匹配度,查询的结构中以query参数开始来执行内容查询
结构化过滤Filter DSL
只是简单的决定文档是否匹配,内容过滤中使用的term和range字句,会过滤 调不匹配的文档,并且不影响计算文档匹配得分
使用过滤查询会被es自动缓存用来提高效
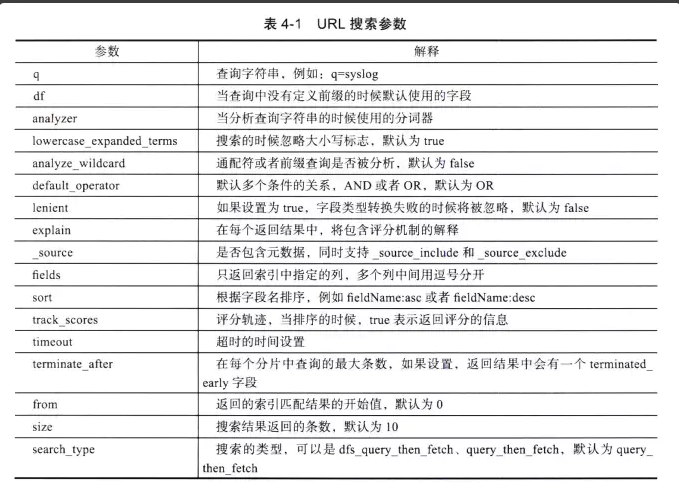
8、关键词详解
8.1、match_all查询
查询匹配所有文档
GET /my_index2/_doc/_search
{
"query": {
"match_all": {}
}
}
8.2、match查询
支持全文搜索和精确查询,取决于字段是否支持全文检索,全文检索会将查询的字符串先进行分词,然后在倒排索引中进行匹配
精确查询
GET /my_index2/_doc/_search
{
"query": {
"match": {
"age": "38"
}
}
}
对于精确值的查询,可以使用 filter 语句来取代 query,因为 filter 将会被缓存
operator操作:
match 查询还可以接受 operator 操作符作为输入参数,默认情况下该操作符是 or 。我们可以将它修改成 and 让所有指定词项都必须匹配
GET /my_index2/user/_search
{
"query": {
"match": {
"tages": {
"query": "程序猿 菜鸟",
"operator": "and"
}
}
}
}
match 查询支持 minimum_should_match 最小匹配参数, 可以指定必须匹配的词项数用来表示一个文档是否相关。我们可以将其设置为某个具体数字(指需要匹配倒排索引的词的数量),更常用的做法是将其设置为一个百分数,因为我们无法控制用户搜索时输入的单词数量
GET /my_index2/_doc/_search { "query": { "match": { "tages": { "query": "程序猿 菜鸟", "minimum_should_match": "2" } } } }
只会返回匹配上程序猿和菜鸟两个词的文档返回,如果minimum_should_match是1,则只要匹配上其中一个词,文档就会返回
8.3、multi_match查询
多字段查询,比如查询desc和tages字段包含直的文档
GET /my_index2/_doc/_search { "query": { "multi_match": { "query": "直", "fields": ["tages","desc"] } } }
8.4、range查询
范围查询,查询年龄大于6小于60的文档
GET /my_index2/_doc/_search { "query": { "range": { "age": { "gt": 6, "lt": 60 } } } }
范围查询操作符
| 字符 | 说明 |
| gt | 大于 |
| gte | 大于等于 |
| lt | 小于 |
| lte | 小于等于 |
8.5、term查询
查询age字段等于38的文档
GET /my_index2/_doc/_search { "query": { "term": { "age": { "value": "38" } } } }
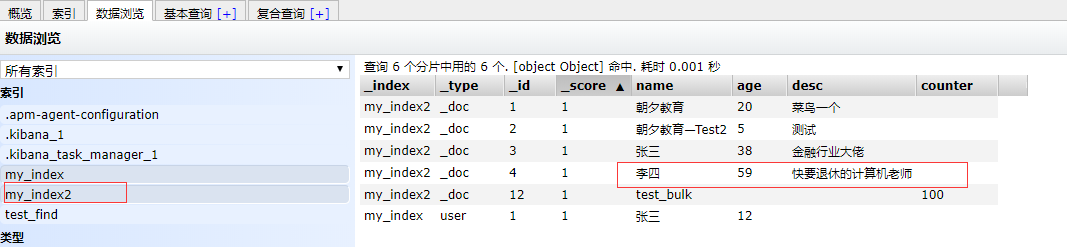
查询name字段等于“李四”的文档
查看索引文档,发现存在该文档
使用如下查询却不能查询出任何信息
GET /my_index2/_doc/_search { "query": { "term": { "name": { "value": "李四" } } } }
原因分析:term查询会去倒排索引中寻找确切的term,它并不会走分词器,只会去配倒排索引 ,而name字段的type类型是text,会进行分词,将“李四”切分,我们使用term查询“李四”时倒排索引中没有“李四”,所以没有查询到匹配的文档。
term查询与match查询的区别
term查询时,不会分词,直接匹配倒排索引
match查询时会进行分词
还有一点需要注意,因为term查询不会走分词器,但是会去匹配倒排索引,所以查询的结构就跟分词器如何分词有关系,比如新增一个/my_index2/_doc类型下的文档,name字段赋值为Oppo,这时使用term查询Oppo不会查询出文档,这时因为es默认是用的standard分词器,它在分词后会将单词转成小写输出,所以使用Oppo查不出文档,使用小写oppo可以查出来
PUT /my_index2/_doc/5 { "title":"Oppo", "price":4533.00 } GET /my_index2/_doc/_search { "query": { "term": { "name": { "value": "Oppo" //改成oppo可以查出新添加的文档 } } } }
8.6、terms查询
terms查询与term查询一样,但它允许你指定多值进行匹配,如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件
GET /my_index2/_doc/_search { "query": { "terms": { "age": ["5","38"] } } }
8.7、exists 查询
用于查找那些指定字段中有值 (exists)的文档
指定name字段有值:
GET /my_index2/_doc/_search { "query": { "bool": { "filter": { "exists": { "field": "name" } } } } }
8.8、match_phrase查询
短语查询,精确匹配,查询攻城狮会匹配tages字段包含攻城狮短语的,而不会进行分词查询,也不会查询出包含攻城xxx狮这样的文档
GET /my_index2/user/_search { "query": { "match_phrase": { "tages": "攻城狮" } } }
8.9、scroll查询
类似于分页查询,不支持跳页查询,只能一页一页往下查询,scroll查询不是针对实时用户请求,而是针对处理大量数据,例如为了将一个索引的内容重新索引到具有不同配置的新索引中
POST /my_index2/user/_search?scroll=1m { "query": { "match_all": {} }, "size": 1, "from": 0 } //返回值包含一个"_scroll_id" : DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAk-IWcnNUZFJ2cVBTNDZGRnRsRExiZ3Jsdw=="下次查询的时候使用_scroll_id就可以查询下一页的文档 POST /_search/scroll { "scroll" : "1m", "scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAk-IWcnNUZFJ2cVBTNDZGRnRsRExiZ3Jsdw==" }
8.10、fuzzy查询
模糊查询,fuzzy 查询会计算与关键词的拼写相似程度
GET /my_index2/_doc/_search { "query": { "fuzzy": { "tages":{ "value": "攻城狮", "fuzziness": 2, "prefix_length": 1 } } } }
参数设置:
- fuzziness:最大编辑距离,默认为
AUTO - prefix_length:不会“模糊化”的初始字符数。这有助于减少必须检查的术语数量,默认为
0 - max_expansions:
fuzzy查询将扩展到 的最大术语数。默认为50,设置小,有助于优化查询 - transpositions:是否支持模糊转置(
ab→ba),默认是false
8.11、wildcard查询
持通配符的模糊查询,?匹配单个字符,*匹配任何字符
为了防止极其缓慢通配符查询,*或?通配符项不应该放在通配符的开始
GET /my_index2/_doc/_search { "query": { "wildcard": { "name": "张*" } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号