springboot 缓存介绍,缓存注解和常见问题
spring缓存
spring框架对缓存服务进行了抽象,提供了缓存增删查改等功能。但需要实现一个具体的数据存储实体。
缓存与缓冲区
- 缓存是无感知的,提高多次读取相同数据的性能
- 缓冲区是作用于快速和慢速实体之间的数据临时存储。相同数据块一般只会读写一次。
Reids实现spring缓存服务
spring提供了Cache和CacheManger抽象,Cache有自己的名字,存储缓存数据和提供操作。CacheManager则是维护Cache列表和提供服务。
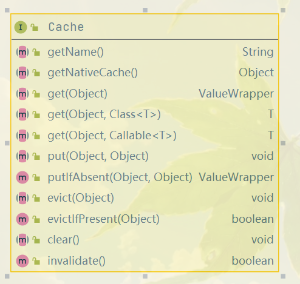
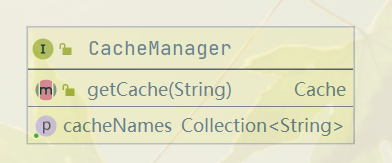
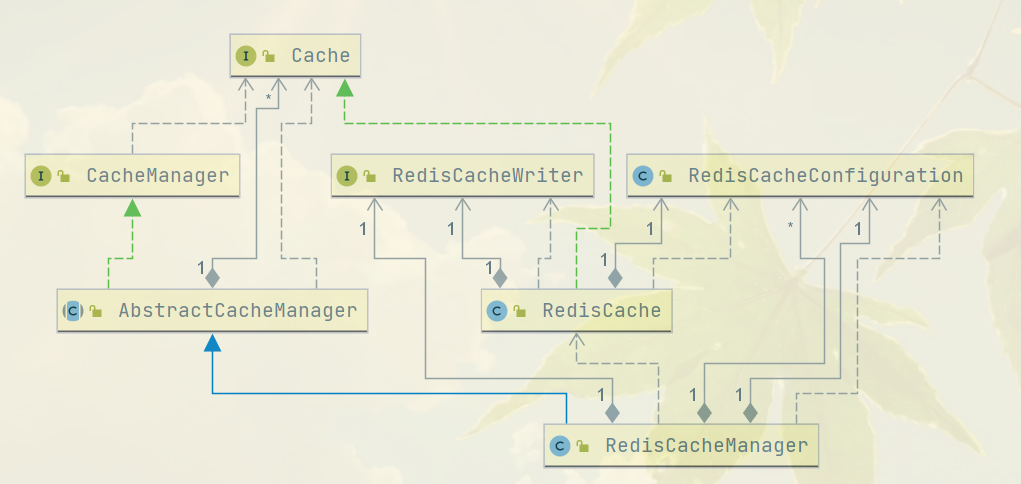
实现缓存抽象的数据实体

环境搭建
<!--spring cache-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
cache:
#设置缓存组件类型
type: redis
#设置缓存过期时间
redis:
time-to-live: 3600000
#指定默认前缀,如果此处我们指定了前缀则使用我们指定的前缀,推荐此处不指定前缀
#spring.cache.redis.key-prefix=CACHE_
#是否开始前缀,建议开启
#spring.cache.redis.use-key-prefix=true
#是否缓存空值,防止缓存穿透
#spring.cache.redis.cache-null-values=true
@EnableCaching
@Configuration
public class CacheConfig {
@Bean
public RedisCacheConfiguration redisCacheConfiguration(CacheProperties cacheProperties) {
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig();
// 设置缓存key的序列化方式
config =
config.serializeKeysWith(
RedisSerializationContext.SerializationPair.fromSerializer(
new StringRedisSerializer()));
// 设置缓存value的序列化方式(JSON格式) 这里用GenericJackson2JsonRedisSerializer(其他json方式会报错哦),从redis获取后可以进行强转。
config =
config.serializeValuesWith(
RedisSerializationContext.SerializationPair.fromSerializer(
new GenericJackson2JsonRedisSerializer()));
CacheProperties.Redis redisProperties = cacheProperties.getRedis();
if (redisProperties.getTimeToLive() != null) {
config = config.entryTtl(redisProperties.getTimeToLive());
}
if (redisProperties.getKeyPrefix() != null) {
config = config.prefixKeysWith(redisProperties.getKeyPrefix());
}
if (!redisProperties.isCacheNullValues()) {
config = config.disableCachingNullValues();
}
if (!redisProperties.isUseKeyPrefix()) {
config = config.disableKeyPrefix();
}
return config;
}
}
缓存注解
spring缓存提供了一组注解:
-
-
@Cacheable:查询缓存,查不到则增加。 -
@CacheEvict:删除缓存。 -
@CachePut:增加缓存。 -
@Caching:组合多个缓存操作。 -
@CacheConfig:在类级别共享一些与缓存相关的常见设置。
-
使用demo
// ps:使用SpEL语法 @CachePut(cacheNames = CACHE_USER, key = "#params.name") public UserInfo register(UserRequestParams params) {} // sync=true 加锁 condition="#name.length() < 32" 条件缓存 @Cacheable(cacheNames = CACHE_USER, key = "#name") public UserInfo getUser(String name){} // allEntries=true 清楚全部缓存 @CacheEvict(cacheNames = CACHE_USER, key = "#name") public void clear(String name){} // 缓存操作集合,可以抽象出来 @Caching(cacheable = @Cacheable(cacheNames = "caching", key = "#age"), evict = @CacheEvict(cacheNames = "t4", key = "#age")) public String caching(int age) {} @CacheConfig("books") public class BookRepositoryImpl{} // 自定义注解,一般用来美化@Caching注解 @Retention(RetentionPolicy.RUNTIME) @Target({ElementType.METHOD}) @Cacheable(cacheNames="books", key="#isbn") public @interface SlowService { } @SlowService public Book findBook(ISBN isbn, boolean checkWarehouse, boolean includeUsed)
缓存常见问题
-
-
缓存穿透
描述:访问一个缓存和数据库都不存在的 key,此时会直接打到数据库上,并且查不到数据,没法写缓存,所以下一次同样会打到数据库上。
解决方案:
1、接口校验。在正常业务流程中可能会存在少量访问不存在 key 的情况,但是一般不会出现大量的情况,所以这种场景最大的可能性是遭受了非法攻击。可以在最外层先做一层校验:用户鉴权、数据合法性校验等,例如商品查询中,商品的ID是正整数,则可以直接对非正整数直接过滤等等。
2、缓存空值。当访问缓存和DB都没有查询到值时,可以将空值写进缓存,但是设置较短的过期时间,该时间需要根据产品业务特性来设置。
3、布隆过滤器。使用布隆过滤器存储所有可能访问的 key,不存在的 key 直接被过滤,存在的 key 则再进一步查询缓存和数据库。
布隆过滤器
布隆过滤器的特点是判断不存在的,则一定不存在;判断存在的,大概率存在,但也有小概率不存在。并且这个概率是可控的,我们可以让这个概率变小或者变高,取决于用户本身的需求。
布隆过滤器由一个 bitSet 和 一组 Hash 函数(算法)组成,是一种空间效率极高的概率型算法和数据结构,主要用来判断一个元素是否在集合中存在。
在初始化时,bitSet 的每一位被初始化为0,同时会定义 Hash 函数,例如有3组 Hash 函数:hash1、hash2、hash3。
![]() 假设抖音刷视频,需要推荐给我们没看过的视频,那么就需要缓存我们看过的视频进行排除。假设使用四个字节存储视频id,100个视频id就需要400字节,而且一般为了查询效率,也要达到O(logN)的查询,那就需要引入占用内存更多的map之类的结构。而布隆是3个bit存储,那100个视频id最理想情况下,也只有300bit ≈ 30多字节,并且查询效率达到O(1),在大数据查找领域,不失为一种最佳方案。
假设抖音刷视频,需要推荐给我们没看过的视频,那么就需要缓存我们看过的视频进行排除。假设使用四个字节存储视频id,100个视频id就需要400字节,而且一般为了查询效率,也要达到O(logN)的查询,那就需要引入占用内存更多的map之类的结构。而布隆是3个bit存储,那100个视频id最理想情况下,也只有300bit ≈ 30多字节,并且查询效率达到O(1),在大数据查找领域,不失为一种最佳方案。
-
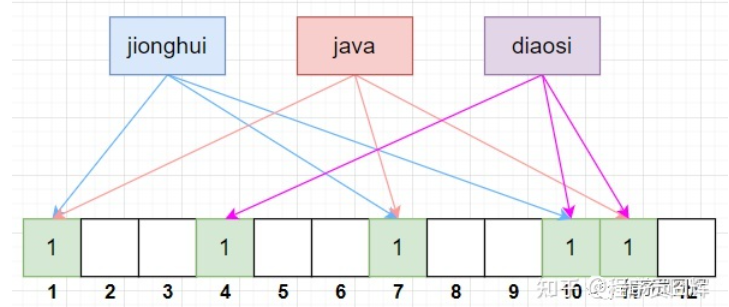 假设抖音刷视频,需要推荐给我们没看过的视频,那么就需要缓存我们看过的视频进行排除。假设使用四个字节存储视频id,100个视频id就需要400字节,而且一般为了查询效率,也要达到O(logN)的查询,那就需要引入占用内存更多的map之类的结构。而布隆是3个bit存储,那100个视频id最理想情况下,也只有300bit ≈ 30多字节,并且查询效率达到O(1),在大数据查找领域,不失为一种最佳方案。
假设抖音刷视频,需要推荐给我们没看过的视频,那么就需要缓存我们看过的视频进行排除。假设使用四个字节存储视频id,100个视频id就需要400字节,而且一般为了查询效率,也要达到O(logN)的查询,那就需要引入占用内存更多的map之类的结构。而布隆是3个bit存储,那100个视频id最理想情况下,也只有300bit ≈ 30多字节,并且查询效率达到O(1),在大数据查找领域,不失为一种最佳方案。 -
缓存击穿
描述:某一个热点 key,在缓存过期的一瞬间,同时有大量的请求打进来,由于此时缓存过期了,所以请求最终都会走到数据库,造成瞬时数据库请求量大、压力骤增,甚至可能打垮数据库。
解决方案:
1、加互斥锁。在并发的多个请求中,只有第一个请求线程能拿到锁并执行数据库查询操作,其他的线程拿不到锁就阻塞等着,等到第一个线程将数据写入缓存后,直接走缓存。
2、热点数据不过期。直接将缓存设置为不过期,然后由定时任务去异步加载数据,更新缓存。
这种方式适用于比较极端的场景,例如流量特别特别大的场景,使用时需要考虑业务能接受数据不一致的时间,还有就是异常情况的处理,不要到时候缓存刷新不上,一直是脏数据,那就凉了。
-
缓存雪崩
描述:高级版缓存击穿,大量的热点 key 设置了相同的过期时间,导在缓存在同一时刻全部失效,造成瞬时数据库请求量大、压力骤增,引起雪崩,甚至导致数据库被打挂。
解决方案:
1、过期时间打散。既然是大量缓存集中失效,那最容易想到就是让他们不集中生效。可以给缓存的过期时间时加上一个随机值时间,使得每个 key 的过期时间分布开来,不会集中在同一时刻失效。
2、热点数据不过期。该方式和缓存击穿一样,也是要着重考虑刷新的时间间隔和数据异常如何处理的情况。
3、加互斥锁。该方式和缓存击穿一样,按 key 维度加锁,对于同一个 key,只允许一个线程去计算,其他线程原地阻塞等待第一个线程的计算结果,然后直接走缓存即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号