redis设计与实现(一) redis概念和数据结构
基础概念
定义
Redis(Remote Dictionary Server)是一个使用 C 语言编写的,高性能非关系型的键值对数据库。
特点
-
- 基于内存操作
- 单线程,高并发
- 支持多种数据类型
- 支持持久化
访问速度比对:
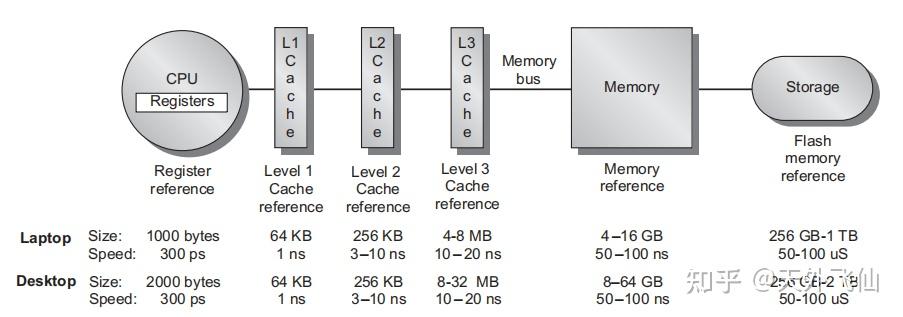
这是计算机缓存系统结构, 内存访问是比硬盘访问快上几个数量级的。
那么什么样的代码容易命中缓存? https://blog.csdn.net/Murphy_CoolCoder/article/details/89478391
IO模型
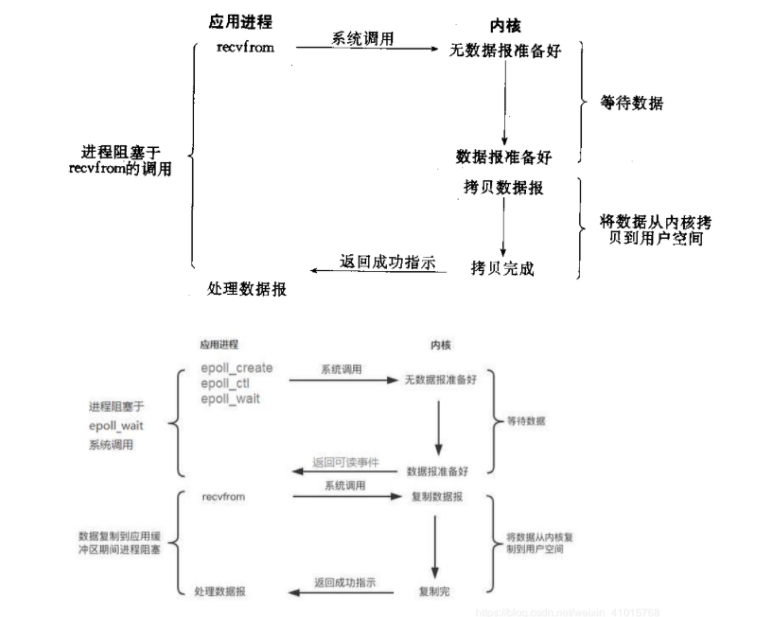
IO模型分为阻塞IO,非阻塞IO(自旋锁实现),信号IO,IO多路复用,异步IO五种。
其中socket(套接字,维护了一组网络连接,由四元组标识,主要功能是读写网络数据,读取过程大致为解析网卡通过DMA放入内存的数据帧,对数据帧按照协议栈解析为应用层数据给用户)的recv接口,默认是阻塞IO,如果想增加并发,需要额外维护线程资源。
linux内核还提供了IO多路复用接口(select,epoll等), 能够一个线程完成并发连接和数据的处理(本质是内核支持了批量处理sock事件),这也是redis服务器单线程却高性能的原因。
数据类型
redis对于数据存储是以redis object形式存储的,我这里列举了一些常见字段。
redis是键值对存储的,键的编码只有string,值的编码就很丰富,有以下五种。

接下来介绍编码涉及到的数据结构
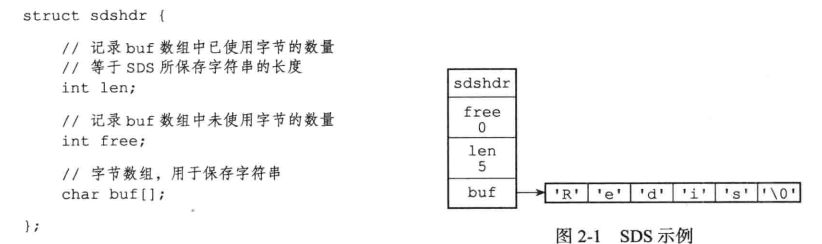
SDS:
string的编码, 字符串较短会和redis object公用一块内存(embstr),否则就是用redis object ptr指向一块新内存(raw)。
本质是封装了char*,毕竟原生c不安全,也不方便。
dict:
数据较多使用,哈希表就可以上场了(O(1)级别的访问速度)。
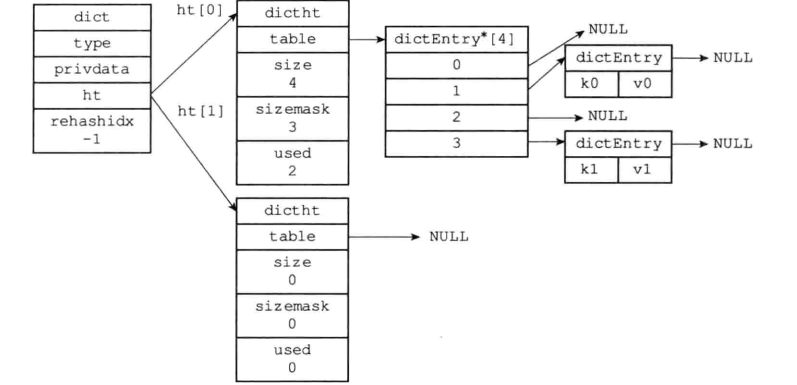
解决哈希冲突:渐进式rehash(在扩容的时候,是逐步完成的,会同时维护两张哈希表,直到扩容完成)
java的hashmap也提供了另一种思路,就是把链表变成红黑树
skiplist:
跳表可以看成多层链表,它有如下的性质:
-
- 多层的结构组成,每层是一个有序的链表
- 最底层的链表包含所有的元素
- 跳跃表的查找次数近似于层数,时间复杂度为O(logn),插入、删除也为 O(logn)
我觉得是redis最优美的实现,媲美平衡二叉树家族。下图红色是搜索路线,大致逻辑是从最高层索引开始,越高层搜索,排除的数据越多,类似二分查找的思想。

ziplist:
较小数据使用,一块连续的内存,由头信息和entry组成。
、
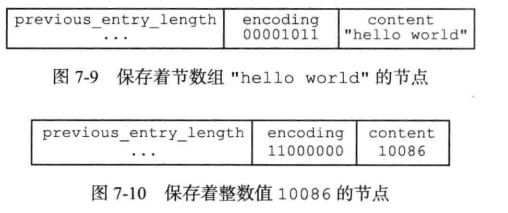
entry的实现由以下三部分组成,encoding最高位为00是字符串,11是数字。
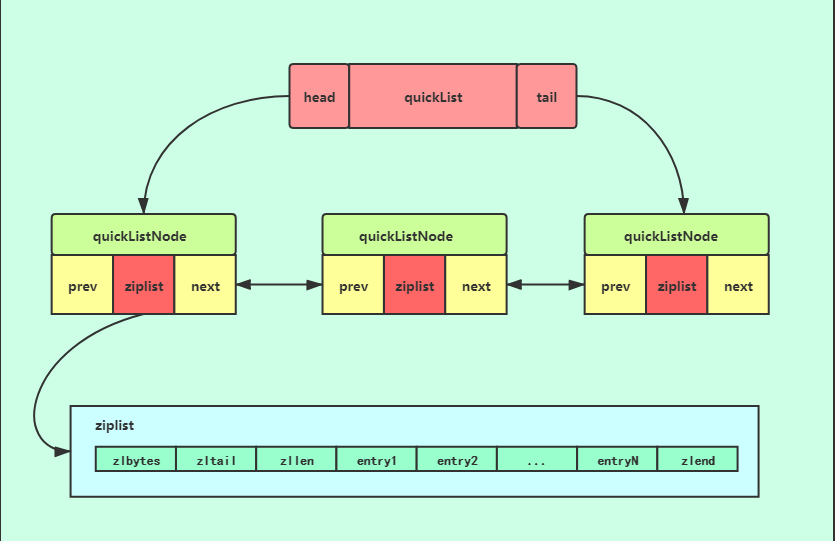
quicklist:
数据较多,使用链表和压缩列表的结合
使用场景
string:1、常规key-value缓存应用。常规计数。2、分布式锁。
hash:存放结构化数据
list:热门列表、消息队列系统。
set:1、好友关系 2、利用唯一性,统计访问网站的所有独立ip 。
zset:1、排行榜;2、优先级队列。
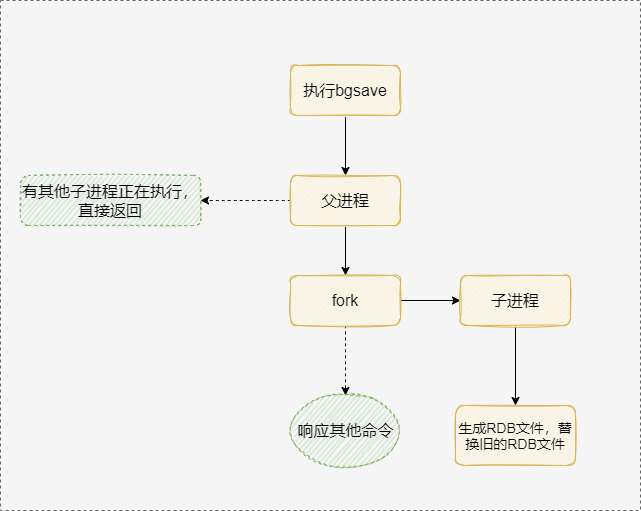
RDB:
RDB 是 Redis 默认的持久化方案。RDB持久化时会将内存中的数据写入到磁盘中,在指定目录下生成一个dump.rdb文件。Redis 重启会加载dump.rdb文件恢复数据。
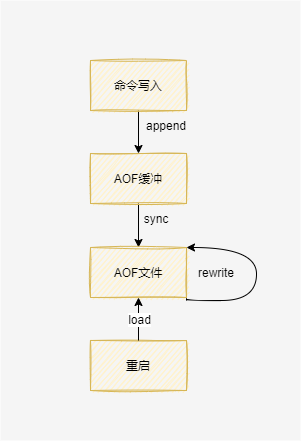
AOF:
AOF(append only file)持久化:以独立日志的方式记录每次写命令,Redis重启时会重新执行AOF文件中的命令达到恢复数据的目的。AOF的主要作用是解决了数据持久化的实时性,目前已经是Redis持久化的主流方式。
其他优点:
1.支持主从复制。从而实现读写分离,降低负载均衡
2.提供哨兵机制。达到高可用的故障转移。
3.支持集群。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号