
使用Filter接口编写过滤器解决post乱码
在使用tomcat9以及之前的版本,request-character-encoding和response-character-encoding使用的字符编码默认不是utf-8,所以导致前端发送到后台的中文乱码.如果使用的是tomcat10以及之后的版本,在apache-tomcat-10.1.25\conf\web.xml已设置好默认的字符集编码为utf-8,如果所示:
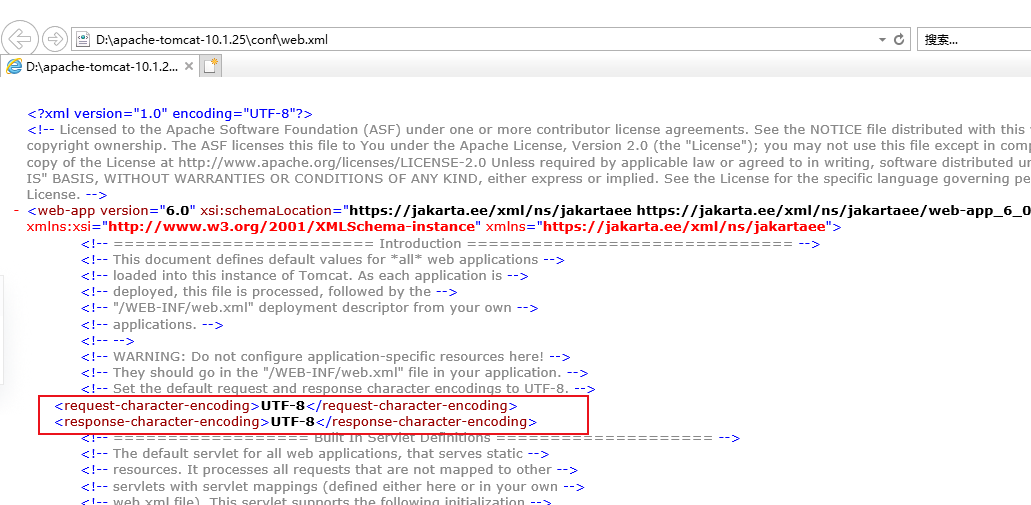
所以使用tomcat9以及之前的版本,可以手动编写过滤器来处理中文乱码:
- 首先编写实现Filter接口的实现类
package com.powernode.springmvc.filter;
import jakarta.servlet.*;
import java.io.IOException;
public class CharacterEncodingFilter implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
//设置请求体的字符集
request.setCharacterEncoding("utf-8");
//设置响应体的字符集
response.setCharacterEncoding("utf-8");
//执行下一步
chain.doFilter(request,response);
}
}
- 然后在web.xml中,定义过滤器的名称等
<!--配置字符编码过滤器-->
<filter>
<!-- 定义过滤器的名称,这个名字是唯一的,并且在整个web.xml文件中被引用 -->
<filter-name>characterEncodingFilter</filter-name>
<!-- 定义过滤器的全类名,即这个过滤器实现类的完整路径 -->
<filter-class>com.powernode.springmvc.filter.CharacterEncodingFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>characterEncodingFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
这样提交post中含有中文就不会乱码了.
第二种方法时使用使用Springmvc内置编码过滤器解决post中文乱码,这样就不用上面自定义的CharacterEncodingFilter 类和web.xml中的配置了.
- 重新在web.xml配置如下:
<!--使用Springmvc内置编码过滤器解决post中文乱码-->
<filter>
<filter-name>CharacterEncodingFilter</filter-name>
<filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>utf-8</param-value>
</init-param>
<init-param>
<param-name>forceRequestEncoding</param-name>
<param-value>true</param-value>
</init-param>
<init-param>
<param-name>forceResponseEncoding</param-name>
<param-value>true</param-value>
</init-param>
<!--等同于上面的forceRequestEncoding和forceResponseEncoding-->
<!-- <init-param>
<param-name>forceEncoding</param-name>
<param-value>true</param-value>
</init-param>-->
</filter>
<filter-mapping>
<filter-name>CharacterEncodingFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
这样也可以解决post请求中的中文乱码.
补充:
ServletRequest 接口中的 getCharacterEncoding() 方法用于获取请求中使用的字符编码。这个字符编码通常是由客户端在发送请求时通过 HTTP 头部字段 Content-Type 指定的。
具体来说,当客户端(如浏览器)发送一个包含请求体的 HTTP 请求(如 POST 请求)时,它可能会包含一个 Content-Type 头部字段来指定请求体的媒体类型(MIME 类型)和字符编码。例如:
http
POST /some-endpoint HTTP/1.1
Host: example.com
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Content-Length: ...
key1=value1&key2=value2
在这个例子中,Content-Type 头部字段指定了请求体的媒体类型为 application/x-www-form-urlencoded,并且字符编码为 UTF-8。
Servlet 容器(如 Tomcat、Jetty 等)在解析请求时,会解析 Content-Type 头部字段,并提取出字符编码信息。然后,当调用 ServletRequest 的 getCharacterEncoding() 方法时,Servlet 容器会返回这个字符编码值。
需要注意的是,如果客户端没有通过 Content-Type 头部字段指定字符编码,或者没有发送 Content-Type 头部字段,那么 getCharacterEncoding() 方法可能会返回 null 或者默认的字符编码(这取决于 Servlet 容器的实现和配置)。
如果Servlet容器也就是tomcat服务器在conf/web.xml也配置了<request-character-encoding>UTF-8</request-character-encoding>,那么如果在idea中你自己定义程序web.xml没有使用<param-name>forceRequestEncoding</param-name>为true,虽然在自己程序中的web.xml中设置了<param-name>encoding</param-name>为utf-8,但是将以tomcat中web.xml中设置的为准.除非使用forceEncoding,才会以自己程序中web.xml中的为准.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号