

Kubernetes
Kubernetes 是一个可移植、可扩展的开源平台,用于管理容器化的工作负载和服务,方便进行声明式配置和自动化。Kubernetes 拥有一个庞大且快速增长的生态系统,其服务、支持和工具的使用范围广泛。
小提示:
系统配置文件 Linux 系统启动后,默认从以下 系统配置文件 加载内核参数: /run/sysctl.d/*.conf /etc/sysctl.d/*.conf /usr/local/lib/sysctl.d/*.conf /usr/lib/sysctl.d/*.conf /lib/sysctl.d/*.conf /etc/sysctl.conf 因此,更推荐将内核参数设置写到这些 系统配置文件 中。 系统配置调整后,需要重启系统或者运行以下 sysctl 命令方能生效: $ sysctl --system 如果只改动 /etc/sysctl.conf ,则只需以 -p 选项运行 sysctl 命令: $ sysctl -p -p 选项未指定文件时, sysctl 命令默认加载 /etc/sysctl.conf 。 -p指定文件生效:sysctl -p /etc/sysctl.d/kubernetes.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 #禁用swap vm.swappiness = 0 https://zhuanlan.zhihu.com/p/432654656
-
安装ipvs
IPVS (IP Virtual Server)是在 Netfilter 上层构建的,并作为 Linux 内核的一部分,实现传输层负载均衡。
参考链接:https://kubernetes.io/zh-cn/blog/2018/07/09/ipvs-based-in-cluster-load-balancing-deep-dive/
yum install ipset ipvsadmin -
添加需要加载的模块写入脚本文件 /etc/sysconfig/modules/ipvs.modules
modprobe -- ip_vs modprobe -- ip_vs_rr modprobe -- ip_vs_wrr modprobe -- ip_vs_sh modprobe -- nf_conntrack_ipv4
添加执行权限并执行脚本:chmod +x /etc/sysconfig/modules/ipvs.modules && bash
-
k8s组件:
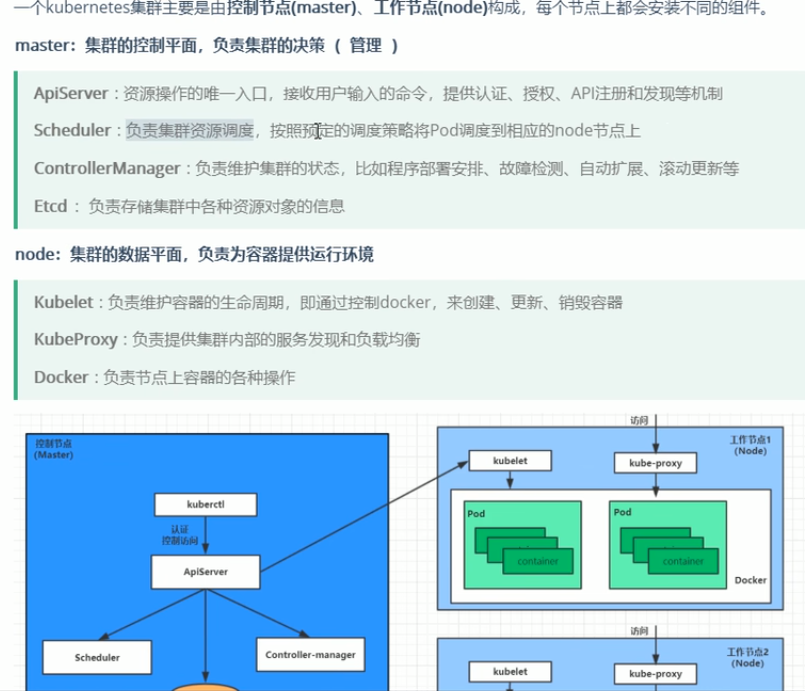
-
kubernetes概念

-
使用部署工具kubeadm安装 Kubernetes
kubeadm:用来初始化集群的指令。
kubelet:在集群中的每个节点上用来启动 Pod 和容器等。
kubectl:用来与集群通信的命令行工具。
可以通过yum install安装 -
kubeadm 要使用的镜像列表
kubeadm config images list
4.1(废弃) vim /usr/lib/systemd/system/cri-docker.service
ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd:// --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9
实际配置中删除了--pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9,官网解释已弃用.
--pod-infra-container-image string 默认值: registry.k8s.io/pause:3.9 所指定的镜像不会被镜像垃圾收集器删除。 CRI 实现有自己的配置来设置此镜像。 (已弃用:将在 1.27 中删除,镜像垃圾收集器将从 CRI 获取沙箱镜像信息。)
参考官网: 使用 kubeadm init 时的工作流程 当调用 kubeadm init 时,kubelet 的配置会被写入磁盘 /var/lib/kubelet/config.yaml, 并上传到集群 kube-system 命名空间的 kubelet-config ConfigMap。 kubelet 配置信息也被写入 /etc/kubernetes/kubelet.conf,其中包含集群内所有 kubelet 的基线配置。 此配置文件指向允许 kubelet 与 API 服务器通信的客户端证书。 这解决了将集群级配置传播到每个 kubelet 的需求。 针对为特定实例提供配置细节的第二种模式, kubeadm 的解决方法是将环境文件写入 /var/lib/kubelet/kubeadm-flags.env,其中包含了一个标志列表, 当 kubelet 启动时,该标志列表会传递给 kubelet 标志在文件中的显示方式如下: KUBELET_KUBEADM_ARGS="--flag1=value1 --flag2=value2 ..." 除了启动 kubelet 时所使用的标志外,该文件还包含动态参数,例如 cgroup 驱动程序以及是否使用其他容器运行时套接字(--cri-socket)。 将这两个文件编组到磁盘后,如果使用 systemd,则 kubeadm 尝试运行以下两个命令: systemctl daemon-reload && systemctl restart kubelet 如果重新加载和重新启动成功,则正常的 kubeadm init 工作流程将继续。
- 初始化
[root@centos7 ~]#kubeadm init --kubernetes-version=v1.26.1 --image-repository registry.aliyuncs.com/google_containers --cri-socket unix:///var/run/cri-dockerd.sock --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12 --control-plane-endpoint=master
如果不提示不需要加--cri-socket unix:///var/run/cri-dockerd.sock
[init] Using Kubernetes version: v1.26.1 [preflight] Running pre-flight checks error execution phase preflight: [preflight] Some fatal errors occurred: [ERROR CRI]: container runtime is not running: output: time="2023-02-04T01:46:26+08:00" level=fatal msg="validate service connection: CRI v1 runtime API is not implemented for endpoint \"unix:///var/run/containerd/containerd.sock\": rpc error: code = Unimplemented desc = unknown service runtime.v1.RuntimeService" , error: exit status 1 [preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
解决方法:containerd使用位于以下位置的配置文件/etc/containerd/config.toml用于指定守护进程级别选项。可以找到一个示例配置文件这里.https://github.com/containerd/containerd/blob/main/docs/man/containerd-config.toml.5.md
默认配置可以通过以下方式生成
containerd config default > /etc/containerd/config.toml
6. systemctl restart cri-docker 和systemctl restart cri-docker.service
7. kubelet配置文件位置 /etc/kubernetes/kubelet.conf
小提示:
Here is one example how you may list all running Kubernetes containers by using crictl: - 'crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock ps -a | grep kube | grep -v pause' Once you have found the failing container, you can inspect its logs with: - 'crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock logs CONTAINERID'
重置尽最大努力还原通过 'kubeadm init' 或者 'kubeadm join' 操作对主机所作的更改: kubeadm reset --cri-socket unix:///var/run/cri-dockerd.sock
额外小提示:通过which或whereis查找命令的绝对路径或配置文件
rpm -qc是查找配置文件
rpm -qf /sbin/rpc.statd是查找软件包名字
[root@iZ2zefujjas2g32dlg27giZ local]# which rpcbind /usr/sbin/rpcbind [root@iZ2zefujjas2g32dlg27giZ local]# rpm -qf /sbin/rpcbind rpcbind-0.2.0-49.el7.x86_64 [root@iZ2zefujjas2g32dlg27giZ local]# rpm -qc rpcbind |grep bind /etc/sysconfig/rpcbind
https://blog.csdn.net/Doudou_Mylove/article/details/121371159
8.初始化成功
To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of control-plane nodes by copying certificate authorities and service account keys on each node and then running the following as root: kubeadm join master:6443 --token rt1i8f.bwtgs5unlhwhp8e6 \ --discovery-token-ca-cert-hash sha256:88135d6bda94fa027e1710511c069a8f7a56c7dd2a55d791dad82f007c2a0f91 \ --control-plane #另外备注:如果加入多个主节点,复制这个命令. Then you can join any number of worker nodes by running the following on each as root: kubeadm join master:6443 --token rt1i8f.bwtgs5unlhwhp8e6 \ --discovery-token-ca-cert-hash sha256:88135d6bda94fa027e1710511c069a8f7a56c7dd2a55d791dad82f007c2a0f91
令牌的有效期是24小时,如果令牌过期可以重新生成:kubeadm token create --print-join-command
--print-join-command 不仅仅打印令牌,而是打印使用令牌加入集群所需的完整 'kubeadm join' 参数。 参考链接:https://kubernetes.io/zh-cn/docs/reference/setup-tools/kubeadm/kubeadm-token/
在 Kubernetes 1.24 之前,CNI 插件也可以由 kubelet 使用命令行参数 cni-bin-dir 和 network-plugin 管理。Kubernetes 1.24 移除了这些命令行参数, CNI 的管理不再是 kubelet 的工作。
9.网络排错命令
kubectl describe pod kube-proxy-lhtlj -n kube-system
kubectl get pods -n kube-system
- 测试创建nginx:
kubectl create deployment nginx --image=nginx:1.14-alpine
暴露端口: kubectl expose deployment nginx --port=80 --type=NodePort
官网解释NodePort:通过每个节点上的 IP 和静态端口(NodePort)暴露服务。 为了让节点端口可用,Kubernetes 设置了集群 IP 地址,这等同于你请求 type: ClusterIP 的服务。
11.资源管理的方式

- kubectl api-resources打印服务器上支持的API资源。
- 在 Kubernetes 中,名字空间(Namespace) 提供一种机制,将同一集群中的资源划分为相互隔离的组。 同一名字空间内的资源名称要唯一,但跨名字空间时没有这个要求。 名字空间作用域仅针对带有名字空间的对象,例如 Deployment、Service 等, 这种作用域对集群访问的对象不适用,例如 StorageClass、Node、PersistentVolume 等。
- kubectl get pods获取默认命名空间中的所有pod, kubectl describe pods pod -n dev获取dev命名空间中的名为pod的pod
- kubectl delete ns dev删除命名空间为dev的空间. kubectl get ns查看所有的命名空间

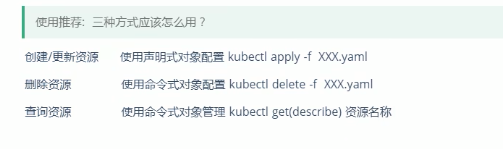
删除资源 使用声明式对象配置,图片估计文字写错了.
- kubectl describe ns default查看命名空间default的详细信息.
- kubctl create ns dev创建一个命名空间dev kubectl delete ns dev删除命名空间dev
18-1. 通过yaml创建命名空间
apiVersion: v1 kind: Namespace metadata: name: dev
kubectl create -f ns-dev.yaml
19. 在命名空间dev中创建pod:nginx
kubectl run nginx --image=nginx:1.17.1 --port=80 --namespace=dev
- kubectl get pod nginx -n dev --show-labels查看指定pod并显示label
- 给pod打标签kubectl label pod nginx -n dev version=1.0
更新label版本kubectl label pod nginx -n dev --overwrite version=2.0
22.查看指定标签:kubectl get pod -n dev --show-labels -l version=2.0
23.删除label标签tier=back: kubectl label pod nginx -n dev tier- - 1.22.1版本 下面的命令创建出来的只有pod,没有控制器
kubectl run nginx --image=nginx --port=80 --namespace dev
新版本中命令发生了一些改变,1.18版本后run没有replicas
create deployment命令中存在replicas选项
- 创建deployment:
kubectl create deployment nginx --image=nginx:1.17.1 --port=80 --replicas=3 --namespace=dev,删除deployment:kubectl delete deployment nginx -n dev - 查看dev命名空间下的deployment:
kubectl describe deployment nginx -n dev
还可以使用kubectl get pod mynginx -o yaml使用yaml格式查看pod为mynginx的信息,不仅可以查pod也可以查deployment.
27.通过yaml文件创建Deployment
apiVersion: apps/v1 kind: Deployment metadata: name: nginx1 #此处是Deployment的名字 namespace: dev spec: replicas: 3 selector: matchLabels: run: nginx template: metadata: labels: run: nginx spec: containers: - image: nginx:1.17.1 name: pod1 ports: - containerPort: 80 protocol: TCP
删除命令:kubectl delete deployment nginx1 -n dev或者使用kubectl delete -f deploy-nginx.yaml
- ClusterIP (默认) - 在集群的内部 IP 上公开 Service 。这种类型使得 Service 只能从集群内访问。
kubectl expose deploy nginx1 --name=svc-nginx --type=ClusterIP --port=80 --target-port=80 -n dev
如果不使用--name选项,那么service的名字为nginx1和deployment名字相同. - NodePort - 使用 NAT 在集群中每个选定 Node 的相同端口上公开 Service 。使用
: 从集群外部访问 Service。是 ClusterIP 的超集。
kubectl expose deploy nginx1 --name=svc-nginx2 --type=NodePort --port=80 --target-port=80 -n dev
删除service:kubectl delete service svc-nginx2 -n dev - 通过yaml配置service
apiVersion: v1 kind: Service metadata: name: svc-nginx namespace: dev spec: clusterIP: ports: - port: 80 protocol: TCP targetPort: 80 selector: run: nginx type: ClusterIP
kubectl create -f service-nginx.yaml
- 查看Pod资源文档kubectl explain pod
查看Pod资源对象的元数据: Standard object's metadata
如果想继续查看metadata资源下的managedFields资源可以使用kubectl explain pod.metadata.managedFields - 打印服务器上支持的API版本,kubectl api-versions
- yaml配置文件字段介绍:

- 查看spec命令属性kubectl explain pod.spec
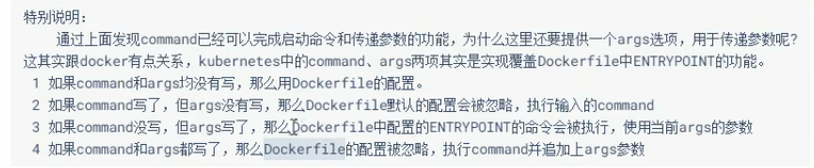
35.Pod-command命令使用
apiVersion: v1 kind: Pod metadata: name: pod-command #Pod的名字 namespace: dev labels: user: heima spec: containers: - name: nginx #容器的名字 image: nginx:1.17.1 - name: busybox image: busybox:1.30 command: ["/bin/sh","-c","touch /tmp/hello.txt;while true; do /bin/echo $(date +%T) >> /tmp/hello.txt; sleep 3; done;"]
使用kubectl进入容器内部:kubectl exec -it pod-command -n dev -c busybox -- /bin/sh其中--是固定格式,pod-command和busybox是yaml中指定的名字
如果不加--会有警告提示:
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
36.Pod-env详解
apiVersion: v1 kind: Pod metadata: name: pod-env namespace: dev labels: user: heima spec: containers: - name: busybox image: busybox:1.30 command: ["/bin/sh","-c","touch /tmp/hello.txt;while true; do /bin/echo $(date +%T) >> /tmp/hello.txt; sleep 3; done;"] env: #设置环境变量列表 - name: "username" value: "admin" - name: "password" value: "123456"
进入容器内部查看:
kubectl exec -it pod-env -n dev -- /bin/sh / # echo $username admin / # echo $password 123456 / # exit
其中如果containers中只有一个容器,那么kubectl exec -it pod-env -n dev -c busybox -- /bin/sh中可以省略-c busybox,因为只有多个容器才需要指定名字
- Pod中ports的yaml配置
apiVersion: v1 kind: Pod metadata: name: pod-ports namespace: dev labels: user: heima spec: containers: - name: nginx image: nginx:1.17.1 ports: #设置容器暴露的端口列表 - name: nginx-port #并且在pod中是唯一的。每一个pod中的命名端口必须具有唯一的名称 containerPort: 80 protocol: TCP
kubectl explain POD.spec.containers.ports可以查看命名意思.
访问nginx程序使用的是podIp:containerPort
38. 为 Pod 和容器管理资源
memory 的限制和请求以字节为单位。 你可以使用普通的整数,或者带有以下 数量后缀 的定点数字来表示内存:E、P、T、G、M、k。 你也可以使用对应的 2 的幂数:Ei、Pi、Ti、Gi、Mi、Ki。 例如,以下表达式所代表的是大致相同的值:
128974848、129e6、129M、128974848000m、123Mi
请注意后缀的大小写。如果你请求 400m 临时存储,实际上所请求的是 0.4 字节。 如果有人这样设定资源请求或限制,可能他的实际想法是申请 400Mi 字节(400Mi) 或者 400M 字节。
备注:CPU单位换算:100m CPU,100 milliCPU 和 0.1 CPU 都相同;精度不能超过 1m。1000m CPU = 1 CPU。
参考链接:https://kubernetes.io/zh-cn/docs/concepts/configuration/manage-resources-containers/
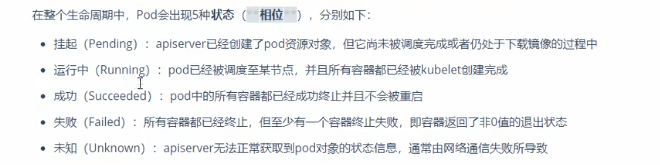
Pod的生命周期

2. 演示先启动初始化后才能启动用户容器pod-initcontainer.yaml
apiVersion: v1 kind: Pod metadata: name: pod-initcontainer namespace: dev spec: containers: - name: main-container image: nginx:1.17.1 ports: - name: nginx-port containerPort: 80 initContainers: #先加载完成初始化容器才可以加载用户容器 - name: test-mysql image: busybox:1.30 command: ["/bin/sh","-c","until ping 192.168.1.100 -c 1; do echo waiting for mysql...; sleep 2; done;" ] - name: test-redis image: busybox:1.30 command: ["/bin/sh", "-c","until ping 192.168.1.101 -c 1; do echo waiting for redis...; sleep 2; done;"]
kubectl get pod/pod-initcontainer -n dev -w,
-w 或 --watch 参数以开始监测特定对象的更新。
通过给主机网卡添加mysqlip后,ifconfig ens33:1 192.168.1.101 netmask 255.255.255.0 up ,Init:1/2,初始化会成功1个,如果再添加上redis的ip能ping通后,那么就会初始化完成2个, 然后完成用户容器(主容器)的启动,最后STATUS为running.
测试完毕删除临时IP: ifconfig ens33:1 del 192.168.1.101
3. 主容器钩子yaml配置演示


apiVersion: v1 kind: Pod metadata: name: pod-hook-exec namespace: dev spec: containers: - image: nginx:1.17.1 name: main-container ports: - containerPort: 80 name: nginx-port protocol: TCP lifecycle: postStart: exec: #在容器启动时执行一个命令,修改掉nginx的默认首页内容 command: ["/bin/sh","-c", "echo postStart...> /usr/share/nginx/html/index.html"] preStop: exec: #在容器停止之前做动作,比如停止nginx服务 command: ["/usr/sbin/nginx","-s","stop"]
容器探测

 48
48
2.通过HttpGet探测
apiVersion: v1 kind: Pod metadata: name: pod-liveness-httpget namespace: dev spec: containers: - image: nginx:1.17.1 name: nginx ports: - containerPort: 80 name: nginx-port protocol: TCP livenessProbe: #执行存活性探测 httpGet: #host: 127.0.0.1 #此处因为暂时不知道即将生成容器的IP,所以暂时注释;要连接的主机名,默认为pod IP。 scheme: HTTP port: 80 path: /
小提示:kubectl get pod/pod-liveness-httpget -n dev -o wide,表示查看更详细的pod内容器的信息
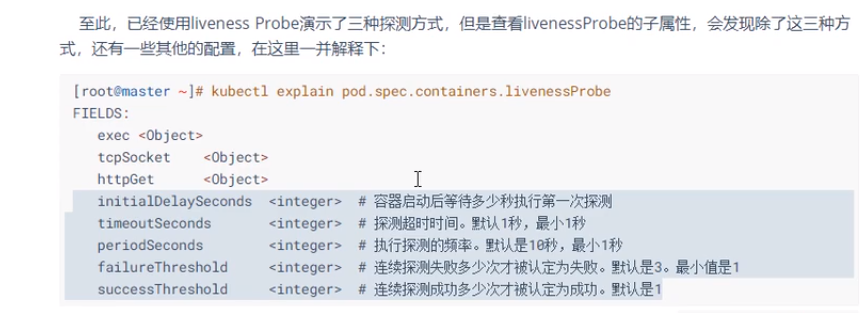
参考链接:https://kubernetes.io/zh-cn/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/
3. Kubernetes API 服务器验证并配置 API 对象的数据, 这些对象包括 pods、services、replicationcontrollers 等。 API 服务器为 REST 操作提供服务,并为集群的共享状态提供前端, 所有其他组件都通过该前端进行交互。
Pod调度
kube-scheduler 是 Kubernetes 集群的默认调度器.
1.定向调度通过node名字
pod/pod-nodename.yaml
apiVersion: v1 kind: Pod metadata: name: pod-nodename namespace: dev spec: containers: - name: nginx image: nginx:1.17.1 nodeName: node1 #指定调度到node1节点上
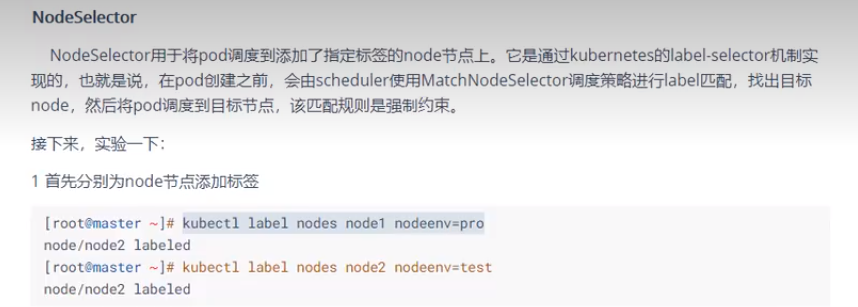
3.通过标签名字调度
[root@master~/exercise]#vim pod-nodeselector.yaml apiVersion: v1 kind: Pod metadata: name: pod-node-selector namespace: dev spec: containers: - name: nginx image: nginx:1.17.1 nodeSelector: node-env: pro #指定调度到具有nodeenv=pro标签的节点上
- node节点亲和性affinity
节点亲和性概念上类似于 nodeSelector, 它使你可以根据节点上的标签来约束 Pod 可以调度到哪些节点上。 节点亲和性有两种:
requiredDuringSchedulingIgnoredDuringExecution: 调度器只有在规则被满足的时候才能执行调度。此功能类似于 nodeSelector, 但其语法表达能力更强。
preferredDuringSchedulingIgnoredDuringExecution: 调度器会尝试寻找满足对应规则的节点。如果找不到匹配的节点,调度器仍然会调度该 Pod。
节点亲和性权重
你可以为 preferredDuringSchedulingIgnoredDuringExecution 亲和性类型的每个实例设置 weight 字段,其取值范围是 1 到 100。 当调度器找到能够满足 Pod 的其他调度请求的节点时,调度器会遍历节点满足的所有的偏好性规则, 并将对应表达式的 weight 值加和。
最终的加和值会添加到该节点的其他优先级函数的评分之上。 在调度器为 Pod 作出调度决定时,总分最高的节点的优先级也最高。
apiVersion: v1 kind: Pod metadata: name: with-affinity-anti-affinity spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/os operator: In values: - linux preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 preference: matchExpressions: - key: label-1 operator: In values: - key-1 - weight: 50 preference: matchExpressions: - key: label-2 operator: In values: - key-2 containers: - name: with-node-affinity image: registry.k8s.io/pause:2.0
如果存在两个候选节点,都满足 preferredDuringSchedulingIgnoredDuringExecution 规则, 其中一个节点具有标签 label-1:key-1,另一个节点具有标签 label-2:key-2, 调度器会考察各个节点的 weight 取值,并将该权重值添加到节点的其他得分值之上,
参考链接:https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/assign-pod-node/
5. PodAffinity规则设置的注意事项

6. PodAffinity
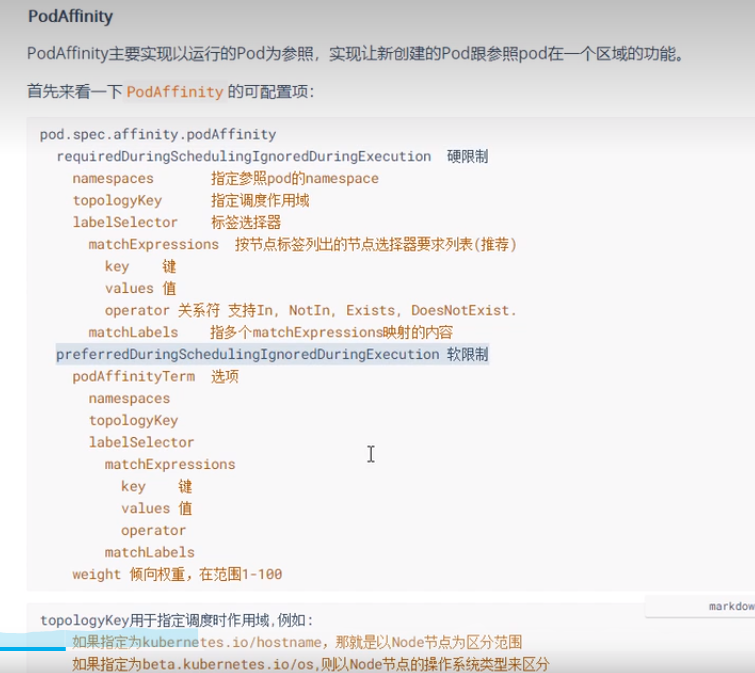
yaml示例:
[root@master~/exercise]#vim pod-pod-affinity-required.yaml apiVersion: v1 kind: Pod metadata: name: pod-affinity-required namespace: dev spec: containers: - image: nginx:1.17.1 name: nginx affinity: #亲和性设置 podAffinity: #设置pod亲和性 requiredDuringSchedulingIgnoredDuringExecution: #调度器只有在规则被满足的时候才能执行调度。此功能类似于 nodeSelector, 但其语法表达能力更强。 - labelSelector: matchExpressions: #匹配env的值在["xxx","yyy"]中的标签(当前环境没有) - key: pod-env operator: In values: ["pro","yyy"] topologyKey: kubernetes.io/hostname
通过执行查看新创建的pod会和标签为pod-env=pro在同一个node节点上
[root@master~/exercise]#kubectl get pod/pod-affinity-required -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod-affinity-required 0/1 ContainerCreating 0 5s <none> node1 <none> <none>
- podAntiAffinity Pod反亲和性
[root@master~/exercise]#vim pod-anti-affinity-required.yaml apiVersion: v1 kind: Pod metadata: name: pod-affinity-anti-required namespace: dev spec: containers: - image: nginx:1.17.1 name: nginx affinity: #亲和性设置 podAntiAffinity: #设置pod反亲和性 requiredDuringSchedulingIgnoredDuringExecution: #调度器只有在规则被满足的时候才能执行调度。此功能类似于 nodeSelector, 但其语法表达能力更强。 - labelSelector: matchExpressions: #匹配env的值在["pro"]中的标签,但是会远离env的值为pro所在的节点. - key: pod-env operator: In values: ["pro"] topologyKey: kubernetes.io/hostname
总结:

污点和容忍
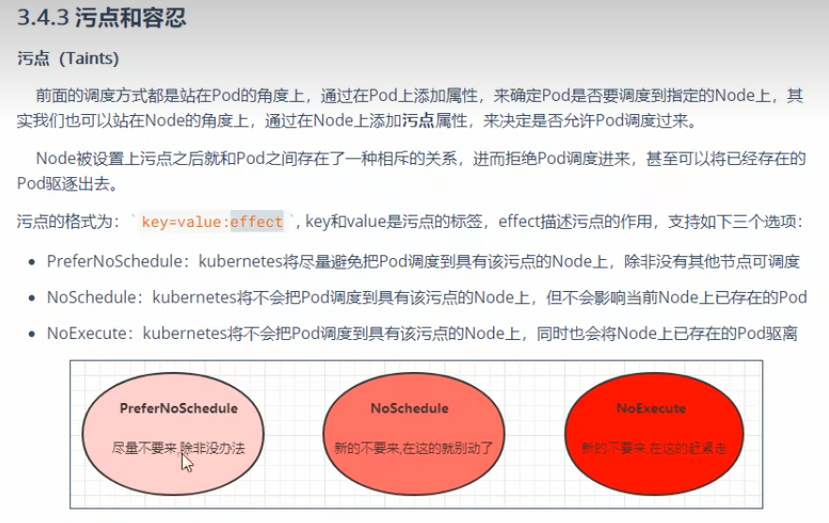
- kubectl taint nodes node1 tag=heima:PreferNoSchedule
系统会 尽量 避免将 Pod 调度到存在其不能容忍污点的节点上, 但这不是强制的。
查看污点信息:kubectl describe node/node1 -n dev
删除PreferNoSchedule信息kubectl taint nodes node1 tag=heima:PreferNoSchedule- - kubectl taint nodes node1 tag=heima:NoSchedule
effect 值为 NoSchedule 的污点, 则 Kubernetes 不会将 Pod 调度到该节点。 - kubectl taint nodes node1 tag:NoExecute
则 Kubernetes 不会将 Pod 调度到该节点, 或者将 Pod(已运行或未运行) 从该节点驱逐
4.使用kubeadm搭建的集群,默认就会给master节点添加一个污点标记,所以pod就不会调度到master节点上
Taints: node-role.kubernetes.io/control-plane:NoSchedule
5.Toleration配置案例
[root@master~/exercise]#vim pod-toleration.yaml apiVersion: v1 kind: Pod metadata: name: pod-toleration namespace: dev spec: containers: - name: nginx image: nginx:1.17.1 tolerations: #添加容忍 - key: "tag" #要容忍的污点的key operator: "Equal" #操作符 #value: "heima" #容忍的污点的value,此处注销因为前面kubectl taint nodes node1 tag:NoExecute没有加value值,所以注销 effect: "NoExecute"
命令kubectl describe pod pod-toleration -n dev可以查看pod的tag信息
结果显示仍然调度到node1上,也只有一个node1.
6.toleration的详细配置

改正:effect的默认时Equal
Exists相当于值的通配符,因此一个pod可以容忍特定类别的所有污点。
7. 原则上,topologyKey 可以是任何合法的标签键。出于性能和安全原因,topologyKey 有一些限制:
对于 Pod 亲和性而言,在 requiredDuringSchedulingIgnoredDuringExecution 和 preferredDuringSchedulingIgnoredDuringExecution 中,topologyKey 不允许为空。
对于 requiredDuringSchedulingIgnoredDuringExecution 要求的 Pod 反亲和性, 准入控制器 LimitPodHardAntiAffinityTopology 要求 topologyKey 只能是 kubernetes.io/hostname。如果你希望使用其他定制拓扑逻辑, 你可以更改准入控制器或者禁用之。
8. operator 的默认值是 Equal。
一个容忍度和一个污点相“匹配”是指它们有一样的键名和效果,并且:
如果 operator 是 Exists (此时容忍度不能指定 value),或者
如果 operator 是 Equal ,则它们的 value 应该相等
说明:
存在两种特殊情况:
如果一个容忍度的 key 为空且 operator 为 Exists, 表示这个容忍度与任意的 key、value 和 effect 都匹配,即这个容忍度能容忍任何污点。
如果 effect 为空,则可以与所有键名 key1 的效果相匹配。
当某种条件为真时,节点控制器会自动给节点添加一个污点。当前内置的污点包括: node.kubernetes.io/not-ready:节点未准备好。这相当于节点状况 Ready 的值为 "False"。 node.kubernetes.io/unreachable:节点控制器访问不到节点. 这相当于节点状况 Ready 的值为 "Unknown"。 Kubernetes 会自动给 Pod 添加针对 node.kubernetes.io/not-ready 和 node.kubernetes.io/unreachable 的容忍度,且配置 tolerationSeconds=300, 除非用户自身或者某控制器显式设置此容忍度。 这些自动添加的容忍度意味着 Pod 可以在检测到对应的问题之一时,在 5 分钟内保持绑定在该节点上。
9.Pod控制器
1.
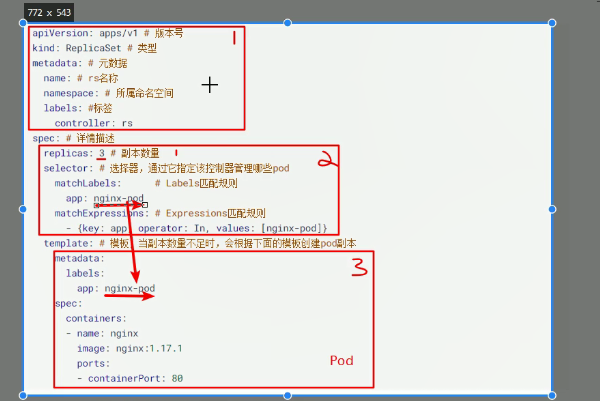
版本小提示: ReplicaSet extensions/v1beta1、apps/v1beta1 和 apps/v1beta2 API 版本的 ReplicaSet 在 v1.16 版本中不再继续提供。 迁移清单和 API 客户端使用 apps/v1 API 版本,此 API 从 v1.9 版本开始可用; 所有的已保存的对象都可以通过新的 API 来访问; 值得注意的变更: spec.selector 现在变成必需字段,并且在对象创建之后不可变更; 可以将现有模板的标签作为选择算符以实现无缝迁移。
参考链接:https://blog.csdn.net/xixihahalelehehe/article/details/112789211
2. 创建replicaset yaml文件
[root@master~/exercise]#vim pc-replicaset.yaml apiVersion: apps/v1 kind: ReplicaSet metadata: name: pc-replicaset namespace: dev spec: replicas: 3 selector: matchLabels: app: nginx-pod template: metadata: labels: app: nginx-pod spec: containers: - name: nginx image: nginx:1.17.1
查看是否创建成功
[root@master~/exercise]#kubectl create -f pc-replicaset.yaml replicaset.apps/pc-replicaset created [root@master~/exercise]#kubectl get replicaset.apps/pc-replicaset -n dev NAME DESIRED CURRENT READY AGE pc-replicaset 3 3 3 15s
还是使用完整查看命令
[root@master~/exercise]#kubectl get replicaset pc-replicaset -n dev NAME DESIRED CURRENT READY AGE pc-replicaset 3 3 3 42s
3.修改pod数量也就是扩容
kubectl edit replicaset pc-replicaset -n dev
将其中的replicas修改为6,将变成6个pod.
还可以通过kubectl命令方式修改pod数量kubectl scale replicaset pc-replicaset --replicas=2 -n dev
使用kubectl命令行方式修改镜像kubectl set image replicaset pc-replicaset nginx=nginx:1.17.1 -n dev
4.删除replicaset
如果只删除 ReplicaSet 而不影响它的各个 Pod,使用kubectl delete rs pc-replicaset -n dev --cascade=orphan
如果删除Replicaset和各个pod,使用kubectl delete -f pc-replicaset.yaml
5. deployment
配置参考

创建deployment
[root@master~/exercise]#vim pc-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: pc-deployment namespace: dev spec: replicas: 3 selector: matchLabels: app: nginx-pod template: metadata: labels: app: nginx-pod spec: containers: - name: nginx image: nginx:1.17.1
查看创建结果
[root@master~/exercise]#kubectl create -f pc-deployment.yaml deployment.apps/pc-deployment created [root@master~/exercise]#kubectl get deployment -n dev NAME READY UP-TO-DATE AVAILABLE AGE pc-deployment 3/3 3 3 34s [root@master~/exercise]#kubectl get deployment.apps/pc-deployment -n dev NAME READY UP-TO-DATE AVAILABLE AGE pc-deployment 3/3 3 3 3m8s
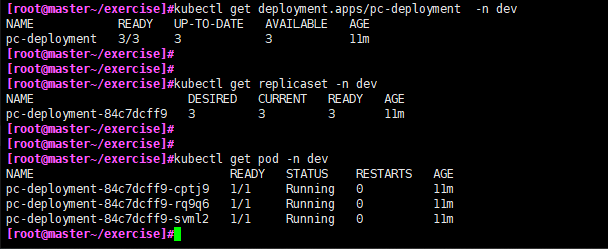
通过截图发现pod的name是在replicaset的基础上加后缀,replicaset是在deployment基础加后缀.
6. deployment扩容
[root@master~/exercise]#kubectl scale deployment pc-deployment --replicas=5 -n dev deployment.apps/pc-deployment scaled [root@master~/exercise]# [root@master~/exercise]# [root@master~/exercise]#kubectl get pod -n dev NAME READY STATUS RESTARTS AGE pc-deployment-84c7dcff9-cptj9 1/1 Running 0 21m pc-deployment-84c7dcff9-czhgc 1/1 Running 0 12s pc-deployment-84c7dcff9-rq9q6 1/1 Running 0 21m pc-deployment-84c7dcff9-svml2 1/1 Running 0 21m pc-deployment-84c7dcff9-v29bg 1/1 Running 0 12s
还可以通过编辑yaml文件实现
7. 镜像更新

RollingUPdate:滚动更新,如果有3个老版本的镜像pod,不是一次全部杀死3个pod,而是先启动新版本的镜像的pod,再杀死老版本的pod,依次类推,直到替换完所有的老版本镜像pod;如果第一个更新失败,那么后续将不会继续更新.
如果之前的的nginx是老版本,那么可以通过下面更新到指定版本号:
通过命令行方式:kubectl set image deploy pc-deployment nginx=nginx:1.17.4 -n dev
新增镜像更新策略
[root@master~/exercise]#vim pc-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: pc-deployment namespace: dev spec: strategy: #镜像更新策略 # type: Recreate #重建更新策略 rollingUpdate: maxUnavailable: 25% #系统默认 maxSurge: 25% #默认 replicas: 3 selector: matchLabels: app: nginx-pod template: metadata: labels: app: nginx-pod spec: containers: - name: nginx image: nginx:1.17.1
如果更新的yaml配置可以使用kubectl apply -f pc-deployment.yaml命令执行更新.
8. 版本回退

回滚到之前的修订版本:
kubectl rollout undo deployment/nginx-deployment
或者回退到指定版本:kubectl rollout undo deploy pc-deployment --to-revision=1 -n dev
9. 查看历史
查看上线状态:kubectl rollout status deploy pc-deployment -n dev

如果在创建时没有加--record,那么历史只显示REVISION,不显示CHANGE-CAUSE字段.
kubectl create -f pc-deployment.yaml --record
要查看修订历史的详细信息,运行:
kubectl rollout history deploy pc-deployment -n dev --revision=3
10. 金丝雀发布

kubectl set image deploy pc-deployment nginx=nginx:1.17.4 -n dev && kubectl rollout pause deployment pc-deployment -n dev
也就是更新镜像后立刻暂停,然后查看状态:
kubectl rollout status deploy pc-deployment -n dev
如果更新一部分后没有问题,那么可以继续更新剩余的:
kubectl rollout resume deploy pc-deployment -n dev
HorizontalPodAutoscaler
官方示例:https://kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
首先需要部署并配置了 Metrics Server 的集群。 Kubernetes Metrics Server 从集群中的 kubelets 收集资源指标, 并通过 Kubernetes API 公开这些指标, 使用 APIService 添加代表指标读数的新资源。
下载metrics Server-yaml文件
wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.6.2/components.yaml
[root@master~/exercise]#vim components.yaml rollingUpdate: maxUnavailable: 0 template: metadata: labels: k8s-app: metrics-server spec: containers: - args: - --cert-dir=/tmp - --secure-port=4443 - --kubelet-use-node-status-port - --metric-resolution=15s - --kubelet-insecure-tls #image: k8s.gcr.io/metrics-server/metrics-server:v0.6.2 image: registry.aliyuncs.com/google_containers/metrics-server:v0.6.2 imagePullPolicy: IfNotPresent livenessProbe: failureThreshold: 3 httpGet: path: /livez port: https scheme: HTTPS periodSeconds: 10 name: metrics-server ports: - containerPort: 4443 name: https protocol: TCP readinessProbe: failureThreshold: 3 httpGet: path: /readyz port: https scheme: HTTPS initialDelaySeconds: 20 periodSeconds: 10 readinessProbe: failureThreshold: 3 httpGet: path: /readyz port: https scheme: HTTPS initialDelaySeconds: 20 periodSeconds: 10 resources: requests: cpu: 100m memory: 200Mi securityContext: allowPrivilegeEscalation: false readOnlyRootFilesystem: true runAsNonRoot: true runAsUser: 1000 volumeMounts: - mountPath: /tmp name: tmp-dir nodeSelector: kubernetes.io/os: linux priorityClassName: system-cluster-critical serviceAccountName: metrics-server volumes: - emptyDir: {} name: tmp-dir --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: labels: k8s-app: metrics-server name: v1beta1.metrics.k8s.io spec: group: metrics.k8s.io groupPriorityMinimum: 100 insecureSkipTLSVerify: true service: name: metrics-server namespace: kube-system version: v1beta1 versionPriority: 100
其中修改了镜像改为国内镜像image: registry.aliyuncs.com/google_containers/metrics-server:v0.6.2,
新增了args:--kubelet-insecure-tls-不要验证Kubelets提供的服务证书的CA。仅用于测试目的。
2.kubectl apply -f components.yaml执行yaml文件.
查看监控kubectl top node
HorizontalPodAutoscaler 案例
1.创建deployment
kubectl create deployment nginx --image=nginx:1.17.1 -n dev
默认--replicas=1
2.资源对象中的Pod可以指定计算资源需求(CPU-单位m、内存-单位Mi),即使用的最小资源请求(Requests)
kubectl set resources deployment nginx --requests=cpu=100m -n dev
参考链接https://blog.csdn.net/wuhuayangs/article/details/125841826
3,创建HPA 配置文件
[root@master~/exercise]#vim pc-hpa.yaml apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: pc-hpa namespace: dev spec: minReplicas: 1 #最小pod数量 maxReplicas: 10 #最大pod数量 targetCPUUtilizationPercentage: 3 #CPU使用率指标 scaleTargetRef: #scaleTargetRef指向要缩放的目标资源 apiVersion: apps/v1 kind: Deployment name: nginx
额外补充,如果是通过命令创建HPA,kubectl autoscale deployment pc-hpa --cpu-percent=50 --min=1 --max=10,创建完成后如果需要修改,比如cpu的使用率改为25%,那么需要先导成yml文件,kubectl get hpa pc-hpa -o yaml > nginx-hpa.yaml,修改完后通过kubectl apply -f 执行。
查看是否创建成功.
kubectl get hpa -n dev
配置网络:
kubectl expose deployment nginx --type=NodePort --port=80 -n dev
测试削峰填谷
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://192.168.1.17:30608; done"
-i为在容器上保持stdin打开,
--tty为容器打开一个终端
--rm退出容器时删除,仅在附加到容器时有效,例如使用'——attach'或'-i/——stdin'。
-O- 直接标准输出到屏幕上.
load-generator性能的负载测试工具(https://baike.baidu.com/item/loadrunner/1926633?fr=aladdin).
通过监控deployment查看变化
kubectl get deployment -n dev -w以及kubectl get replicaset -n dev和kubectl get hpa -n dev -w和kubectl get pod -n dev
4.kubectl get hpa pc-hpa -n dev -o yaml通过yaml格式看出HPA的详细信息.
5. 将 Deployment 和 StatefulSet 迁移到水平自动扩缩
kubectl apply edit-last-applied deployment/<Deployment 名称> 在编辑器中,删除 spec.replicas。当你保存并退出编辑器时,kubectl 会应用更新。 在此步骤中不会更改 Pod 计数。 你现在可以从清单中删除 spec.replicas。如果你使用源代码管理, 还应提交你的更改或采取任何其他步骤来修改源代码,以适应你如何跟踪更新。 从这里开始,你可以运行 kubectl apply -f deployment.yaml 参考链接:https://kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale/
Job

测试案例
apiVersion: batch/v1 kind: Job metadata: name: pc-job namespace: dev spec: completions: 6 #指定job需要成功运行Pods的次数,默认值为1 parallelism: 3 #指定job在任一时刻应该并发运行Pods的数量,默认值为1 ttlSecondsAfterFinished: 1 #自动清理已完成 Job ,单位为秒. manualSelector: true selector: matchLabels: app: counter-pod template: metadata: labels: app: counter-pod spec: restartPolicy: Never containers: - name: counter image: busybox:1.30 command: ["bin/sh","-c","for i in 9 8 7 6 5 4 3 2 1; do echo $i;sleep 2; done"]
cronjob yaml文件
[root@master~/exercise]#vim pc-cronjob.yaml apiVersion: batch/v1 kind: CronJob metadata: name: pc-cronjob namespace: dev labels: controller: cronjob spec: schedule: "*/1 * * * *" jobTemplate: metadata: spec: completions: 2 #指定job需要成功运行Pods的次数,默认值为1 ttlSecondsAfterFinished: 1 #自动清理已完成的job,但是不能结束cronjob template: spec: restartPolicy: Never containers: - name: counter image: busybox:1.30 command: ["bin/sh","-c","for i in 6 5 4 3 2 1; do echo $i;sleep 2; done"]
参考链接:https://kubernetes.io/zh-cn/docs/concepts/workloads/controllers/cron-jobs/
开启ipvs
IPVS 为将流量均衡到后端 Pod 提供了更多选择:
rr:轮询
lc:最少连接(打开连接数最少)
dh:目标地址哈希
sh:源地址哈希
sed:最短预期延迟
nq:最少队列
- 然后添加需要加载的模块
[root@master~]#vim /etc/sysconfig/modules/ipvs.modules modprobe -- ip_vs modprobe -- ip_vs_rr modprobe -- ip_vs_wrr modprobe -- ip_vs_sh modprobe -- nf_conntrack_ipv4 modprobe -- ip_vs_lc modprobe -- ip_vs_dh modprobe -- ip_vs_sed modprobe -- ip_vs_nq
添加脚本文件执行权限
chmod +x /etc/sysconfig/modules/ipvs.modules
执行
/bin/bash /etc/sysconfig/modules/ipvs.modules
查看是否加载成功
lsmod | grep -e ip_vs -e nf_conntrack_ipv4
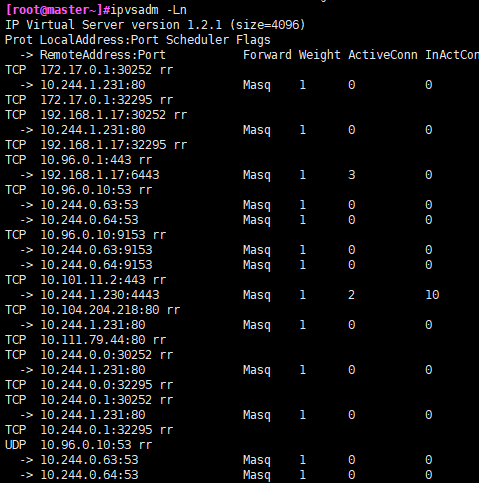
参考链接:https://kubernetes.io/zh-cn/docs/reference/networking/virtual-ips/
Service
Kubernetes 中 Service 是 将运行在一个或一组 Pod 上的网络应用程序公开为网络服务的方法。
参考链接:https://kubernetes.io/zh-cn/docs/concepts/services-networking/service/

- 创建Deployment
[root@master~/exercise/Service]#vim deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: pc-deployment namespace: dev spec: replicas: 3 selector: matchLabels: app: nginx-pod template: metadata: labels: app: nginx-pod spec: containers: - name: nginx image: nginx:1.17.1 ports: - containerPort: 80
使用kubectl进入pod容器内部:
kubectl exec -it pc-deployment-6bb9d9f778-b694z -n dev /bin/sh
由于默认的nginx容器index内容都是一样的,为了看见效果,我们将它们改成不一样的,查看下各pod的名字以及ip地址
kubectl get pod -n dev -o wide

然后登陆各个nginx容器更改下各自的index页
echo "10.244.1.232" > /usr/share/nginx/html/index.html
- 编辑service.yaml文件
[root@master~/exercise/Service]#cat service-clusterip.yaml apiVersion: v1 kind: Service metadata: name: service-clusterip namespace: dev spec: selector: app: nginx-pod clusterIP: 10.97.97.97 #service的IP地址,若不写,默认会自动生成. type: ClusterIP #默认值,上述IP只能在集群内部访问. ports: - port: 80 #Service端口 targetPort: 80 #pod端口
创建完后可以查看service详细信息
kubectl describe service/service-clusterip -n dev

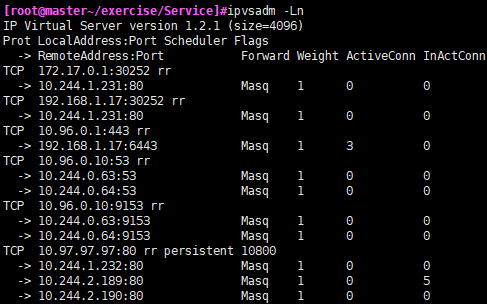
- 查看ipvs映射规则ipvsadm -Ln
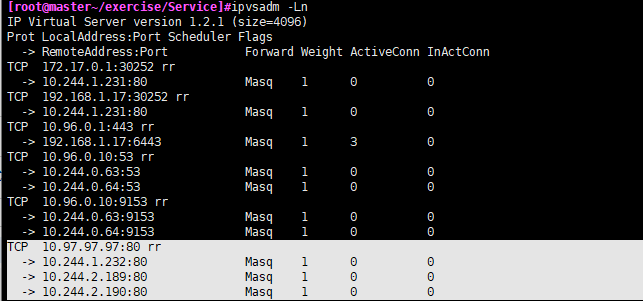
然后测试负载轮询效果:
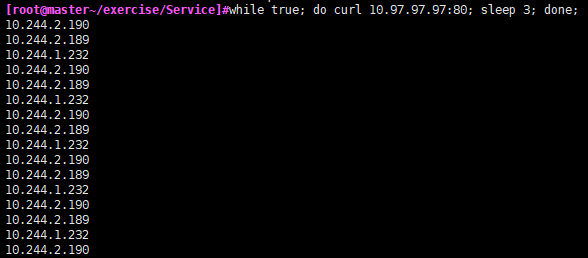
while true; do curl 10.97.97.97:80; sleep 3; done;
后续追加:另外,如果在pod容器内部10.97.97.97可以使用域名代替:服务名+所在名称空间+svc,这里应该是service-clusterip.dev.svc.
- 添加设置会话亲和性
如果要确保来自特定客户端的连接每次都传递给同一个 Pod, 你可以通过设置 Service 的 .spec.sessionAffinity 为 ClientIP 来设置基于客户端 IP 地址的会话亲和性(默认为 None).[root@master~/exercise/Service]#kubectl describe service/service-clusterip -n dev Name: service-clusterip Namespace: dev Labels: <none> Annotations: <none> Selector: app=nginx-pod Type: ClusterIP IP Family Policy: SingleStack IP Families: IPv4 IP: 10.97.97.97 IPs: 10.97.97.97 Port: <unset> 80/TCP TargetPort: 80/TCP Endpoints: 10.244.1.232:80,10.244.2.189:80,10.244.2.190:80 Session Affinity: ClientIP #表示设置成功 Events: <none>
测试:

无头服务(Headless Services)
有时不需要或不想要负载均衡,以及单独的 Service IP。 遇到这种情况,可以通过指定 Cluster IP(spec.clusterIP)的值为 "None" 来创建 Headless Service。
[root@master~/exercise/Service]#vim service-headless.yaml apiVersion: v1 kind: Service metadata: name: service-headless namespace: dev spec: selector: app: nginx-pod clusterIP: None #不需要或不想要负载均衡,以及单独的 Service IP type: ClusterIP #默认值,上述IP只能在集群内部访问. ports: - port: 80 #Service端口 targetPort: 80 #pod端口
[root@master~/exercise/Service]#kubectl create -f service-headless.yaml service/service-headless created [root@master~/exercise/Service]#kubectl get service/service-headless -n dev NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service-headless ClusterIP None <none> 80/TCP 15s
登陆其中某一个pod查看
root@pc-deployment-6bb9d9f778-b694z:/# cat /etc/resolv.conf nameserver 10.96.0.10 search dev.svc.cluster.local svc.cluster.local cluster.local options ndots:5 #ndots:[n]:不常用配置设置调用res_query()解析域名时域名至少包含的点的数量
通过dig命令查看域名节点IP信息
dig @10.96.0.10 service-headless.dev.svc.cluster.local
其中 @10.96.0.10为指定的nameserver.
参考链接:http://mrlch.cn/archives/1432
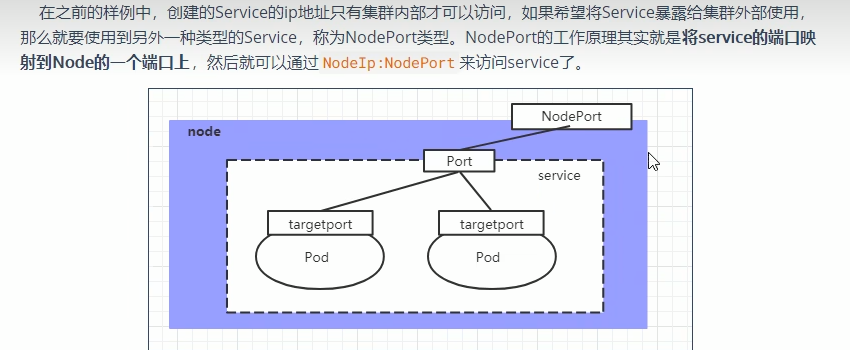
NodePort类型的service
apiVersion: v1 kind: Service metadata: name: service-nodeport namespace: dev spec: selector: app: nginx-pod type: NodePort #service类型 #clusterIP: 10.97.97.97 #service的IP地址,若不写,默认会自动生成. ports: - port: 80 #Service端口 nodePort: 30002 #指定绑定的node端口(默认取值范围:30000-32767),若不指定会自动分配. targetPort: 80 #pod端口
测试,其中192.168.1.17为服务器本机地址
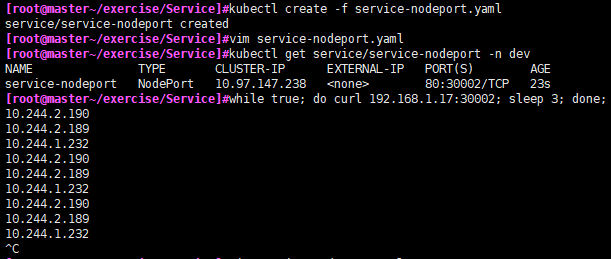
如果在集群内部可以使用cluster-ip:端口 10.97.147.238:80负载均衡访问.
参考链接:https://kubernetes.io/zh-cn/docs/concepts/services-networking/service/#externalname
Ingress
Ingress 可以提供负载均衡、SSL 终结和基于名称的虚拟托管。
nodePort可以解决这个问题,但暴露的服务端口越来越多时,就不好管理了;Ingress是一种API对象,其中定义了一些规则使得集群中的服务可以从集群外访问。
- 下载ingress-nginx的yaml清单
wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.6.4/deploy/static/provider/cloud/deploy.yaml
先修改镜像地址使其能下载nginx-ingress-controller:v1.6.4和kube-webhook-certgen:v20220916-gd32f8c343 - registry.k8s.io/ingress-nginx/kube-webhook-certgen:v20220916-gd32f8c343@sha256:39c5b2e3310dc4264d638ad28d9d1d96c4cbb2b2dcfb52368fe4e3c63f61e10f(有两处).
修改为:dyrnq/kube-webhook-certgen:v20220916-gd32f8c343
registry.k8s.io/ingress-nginx/controller:v1.6.4@sha256:15be4666c53052484dd2992efacf2f50ea77a78ae8aa21ccd91af6baaa7ea22f
修改为:registry.cn-hangzhou.aliyuncs.com/google_containers/nginx-ingress-controller:v1.6.4 - 创建deployment的pod和service
[root@master~/exercise/ingress]#vim tomcat-nginx.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment namespace: dev spec: replicas: 1 selector: matchLabels: app: nginx-pod template: metadata: labels: app: nginx-pod spec: containers: - name: nginx image: nginx:1.17.1 ports: - containerPort: 80 --- apiVersion: apps/v1 kind: Deployment metadata: name: tomcat-deployment namespace: dev spec: replicas: 1 selector: matchLabels: app: tomcat-pod template: metadata: labels: app: tomcat-pod spec: containers: - name: tomcat image: tomcat:8.5-jre10-slim ports: - containerPort: 8080 --- apiVersion: v1 kind: Service metadata: name: nginx-service namespace: dev spec: selector: app: nginx-pod type: ClusterIP clusterIP: None ports: - port: 80 targetPort: 80 --- apiVersion: v1 kind: Service metadata: name: tomcat-service namespace: dev spec: selector: app: tomcat-pod # clusterIP: 10.98.98.98 type: ClusterIP clusterIP: None ports: - port: 8080 #pod端口 targetPort: 8080 #service端口
- 创建ingress
[root@master~/exercise/ingress]#vim ingress-http.yaml apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: ingress-http namespace: dev spec: ingressClassName: nginx rules: - host: nginx.test.com http: paths: - backend: service: name: nginx-service port: number: 80 path: / pathType: Prefix - host: tomcat.test.com http: paths: - backend: service: name: tomcat-service port: number: 8080 path: / pathType: Prefix
其中ingressClassName必填而且要和下载的ingressClassName的deploy.yaml中的IngressClass的name值保持相同,还有从Deployment中也能看到"- --ingress-class=nginx"
- 查看
[root@master~/exercise/ingress]#kubectl get service -n ingress-nginx NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ingress-nginx-controller NodePort 10.110.97.83 <none> 80:30353/TCP,443:32165/TCP 79m ingress-nginx-controller-admission ClusterIP 10.109.242.164 <none> 443/TCP 79m [root@master~/exercise/ingress]#
通过本机hosts将master所在的ip和域名绑定
然后通过访问nginx.test.com:30353和tomcat.test.com:30353就能访问nginx和tomcat服务.
在 Kubernetes 1.18 版本引入 IngressClass 资源和 ingressClassName 字段之前, Ingress 类是通过 Ingress 中的一个 kubernetes.io/ingress.class 注解来指定的。 这个注解从未被正式定义过,但是得到了 Ingress 控制器的广泛支持。
Ingress 中新的 ingressClassName 字段是该注解的替代品,但并非完全等价。 该注解通常用于引用实现该 Ingress 的控制器的名称,而这个新的字段则是对一个包含额外 Ingress 配置的 IngressClass 资源的引用,包括 Ingress 控制器的名称。
要更新现有的 Ingress 以添加新的 Host,可以通过编辑资源来对其进行更新:
kubectl edit ingress test或者通过 kubectl replace -f 命令调用修改后的 Ingress yaml 文件来获得同样的结果,如果有报错那就先delete然乎create.
https://kubernetes.io/zh-cn/docs/concepts/services-networking/ingress/
https://blog.csdn.net/alwaysbefine/article/details/129201448
https://kubernetes.github.io/ingress-nginx/deploy/#local-testing
后续追加:atguigu老师的ingress yaml配置
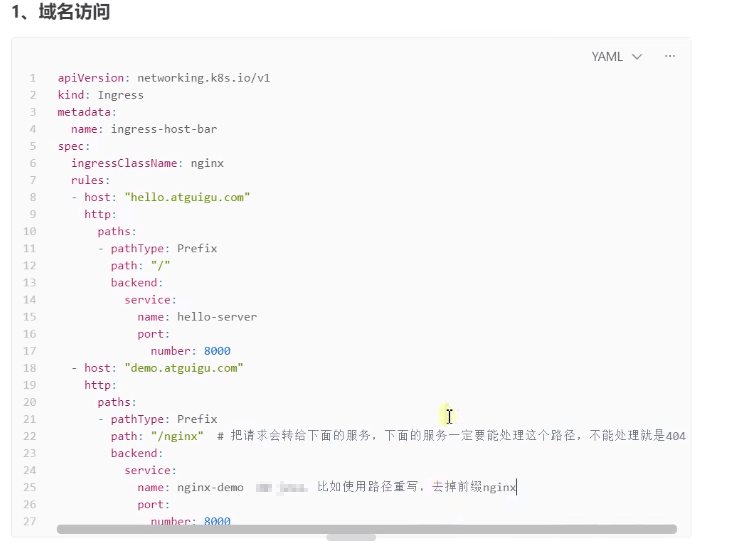
也就是配置了path具体的非根路径,比如/nginx,那么ingress-nginx服务会将/nginx转到service下的pod服务中,所以说pod中的容器服务要有提供http://****/nginx的服务才可以,否则显示404;除非配置路径重写(Rewrite)比如:
举例:
创建带有重写注释的入口规则:
$ echo ' apiVersion: networking.k8s.io/v1 kind: Ingress metadata: annotations: nginx.ingress.kubernetes.io/use-regex: "true" nginx.ingress.kubernetes.io/rewrite-target: /$2 name: rewrite namespace: default spec: ingressClassName: nginx rules: - host: rewrite.bar.com http: paths: - path: /something(/|$)(.*) pathType: Prefix backend: service: name: http-svc port: number: 80 ' | kubectl create -f -
在这个入口定义中,(/|1,由(.*)将被分配给占位符 匹配字符串结尾, 比如:abc)的意思要么就是/,要么就结束了。
例如,上述入口定义将导致以下重写:
rewrite.bar.com/something重写到rewrite.bar.com/
rewrite.bar.com/something/重写到rewrite.bar.com/
rewrite.bar.com/something/new重写到rewrite.bar.com/new
参考链接:https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/annotations/#rewrite
- 限速
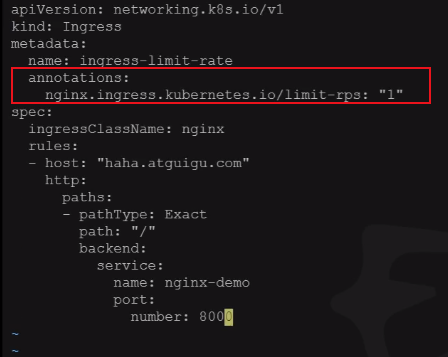
nginx.ingress.kubernetes.io/limit-rps:每秒从给定IP接受的请求数。突发限制设置为该限制乘以突发乘数,默认乘数为5。当客户端超过这个限制时,限额请求状态代码 默认值:返回503。
参考链接:https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/annotations/#global-rate-limiting
EmptyDir
EmptyDir

[root@master~/exercise/storage]#vim volume-emptydir.yaml apiVersion: v1 kind: Pod metadata: name: volume-emptydir namespace: dev spec: containers: - name: nginx image: nginx:1.14-alpine ports: - containerPort: 80 volumeMounts: #将logs-volume挂载到nginx容器中,对应的目录为/var/log/nginx - name: logs-volume mountPath: /var/log/nginx - name: busybox image: busybox:1.30 command: ["/bin/sh","-c","tail -f /logs/access.log"] #初始命令,动态读取指定文件中的内容. volumeMounts: #将logs-volume挂载到busybox容器中,对应的目录为/logs - name: logs-volume mountPath: /logs volumes: #声明volume,name为logs-volume,类型为emptyDir - name: logs-volume emptyDir: {}
实时查看busybox中的日志信息:kubectl logs -f volume-emptydir -n dev -c busybox
查看pod节点IP:
[root@master~/exercise/storage]#kubectl get pod/volume-emptydir -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES volume-emptydir 2/2 Running 0 17s 10.244.1.38 node1 <none> <none>
测试访问:curl 10.244.1.38
HostPath

[root@master~/exercise/storage]#vim volume-hostpath.yaml apiVersion: v1 kind: Pod metadata: name: volume-hostpath namespace: dev spec: containers: - name: nginx image: nginx:1.17.1 ports: - containerPort: 80 volumeMounts: #将logs-volume挂载到nginx容器中,对应的目录为/var/log/nginx - name: logs-volume mountPath: /var/log/nginx - name: busybox image: busybox:1.30 command: ["/bin/sh","-c","tail -f /logs/access.log"] #初始命令,动态读取指定文件中的内容. volumeMounts: #将logs-volume挂载到busybox容器中,对应的目录为/logs - name: logs-volume mountPath: /logs volumes: #声明volume,name为logs-volume,类型为emptyDir - name: logs-volume hostPath: path: /root/logs type: DirectoryOrCreate #目录存在就使用,不存在就创建后使用.
[root@master~/exercise/storage]#kubectl create -f volume-hostpath.yaml pod/volume-hostpath created [root@master~/exercise/storage]#kubectl get pod/volume-hostpath -n dev -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES volume-hostpath 2/2 Running 0 25s 10.244.2.3 node2 <none> <none> [root@master~/exercise/storage]#curl 10.244.2.3

此时即便删除pod,kubectl delete -f volume-hostpath.yaml,node2中的/root/logs文件夹和里面的文件依然存在.
NFS
- yum install nfs-utils
[root@master~]#vim /etc/exports no_root_squash 192.168.1.0/24(rw,no_root_squash)
no_root_squash为新建的共享目录, 192.168.1.0/24为分享的主机网段,也可以是具体的主机IP.rw表示读写,no_root_squash意思为客户端使用 NFS 文件系统的账号若为 root 时,系统该如何判断这个账号的身份?预设的情况下,客户端 root 的身份会由root_squash 的设定压缩成 nfsnobody, 如此对服务器的系统会较有保障。但如果你想要开放客户端使用 root 身份来操作服务器的文件系统,那么这里就得要开 no_root_squash 才行!
重点:如果使用root用户创建的共享目录,那么必须使用no_root_squash,否则pod将无法挂载,显示错误如下:
Warning FailedMount 3m41s (x4 over 10m) kubelet Unable to attach or mount volumes: unmounted volumes=[volume], unattached volumes=[volume kube-api-access-v4x9h]: timed out waiting for the condition Warning FailedMount 84s (x2 over 12m) kubelet Unable to attach or mount volumes: unmounted volumes=[volume], unattached volumes=[kube-api-access-v4x9h volume]: timed out waiting for the condition Warning FailedMount 21s (x15 over 14m) kubelet MountVolume.SetUp failed for volume "pv1" : mount failed: exit status 32 Mounting command: mount Mounting arguments: -t nfs 192.168.1.17:/root/data/pv1 /var/lib/kubelet/pods/8157e39a-7fb6-4c44-8b02-dafd4a46d05f/volumes/kubernetes.io~nfs/pv1 Output: mount.nfs: access denied by server while mounting 192.168.1.17:/root/data/pv1
- nfs的yaml清单
[root@master~/exercise/storage]#vim volume-nfs.yaml apiVersion: v1 kind: Pod metadata: name: volume-nfs namespace: dev spec: containers: - name: nginx image: nginx:1.17.1 ports: - containerPort: 80 volumeMounts: #将logs-volume挂载到nginx容器中,对应的目录为/var/log/nginx - name: logs-volume mountPath: /var/log/nginx - name: busybox image: busybox:1.30 command: ["/bin/sh","-c","tail -f /logs/access.log"] #初始命令,动态读取指定文件中的内容. volumeMounts: #将logs-volume挂载到busybox容器中,对应的目录为/logs - name: logs-volume mountPath: /logs volumes: #声明volume,name为logs-volume,类型为emptyDir - name: logs-volume nfs: server: 192.168.1.17 #nfs服务器地址 path: /root/data/nfs #共享目录
后续追加的其他老师的yaml配置供参考:

持久卷(Persistent Volume)
持久卷(PersistentVolume,PV) 是集群中的一块存储,可以由管理员事先制备, 或者使用存储类(Storage Class)来动态制备。 持久卷是集群资源,就像节点也是集群资源一样。PV 持久卷和普通的 Volume 一样, 也是使用卷插件来实现的,只是它们拥有独立于任何使用 PV 的 Pod 的生命周期。 此 API 对象中记述了存储的实现细节,无论其背后是 NFS、iSCSI 还是特定于云平台的存储系统。
[root@master~/exercise/storage]#vim pv.yaml --- apiVersion: v1 kind: PersistentVolume metadata: name: pv2 spec: capacity: storage: 2Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain nfs: path: /root/data/pv2 server: 192.168.1.17 --- apiVersion: v1 kind: PersistentVolume metadata: name: pv3 spec: capacity: storage: 3Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain nfs: path: /root/data/pv3 server: 192.168.1.17
配置nfs共享目录及服务器地址:
[root@master~/exercise/storage]#cat /etc/exports /root/data/nfs 192.168.1.0/24(rw,no_root_squash) /root/data/pv1 192.168.1.0/24(rw,no_root_squash) /root/data/pv2 192.168.1.0/24(rw,no_root_squash) /root/data/pv3 192.168.1.0/24(rw,no_root_squash)
[root@master~/exercise/storage]#kubectl get pv -o wide NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON pv1 1Gi RWX Retain Available pv2 2Gi RWX Retain Available pv3 3Gi RWX Retain Available ``` 在命令行接口(CLI)中,访问模式也使用以下缩写形式: RWO - ReadWriteOnce ROX - ReadOnlyMany RWX - ReadWriteMany RWOP - ReadWriteOncePod
pvc
持久卷申领(PersistentVolumeClaim,PVC) 表达的是用户对存储的请求。概念上与 Pod 类似。 Pod 会耗用节点资源,而 PVC 申领会耗用 PV 资源。Pod 可以请求特定数量的资源(CPU 和内存);同样 PVC 申领也可以请求特定的大小和访问模式 (例如,可以要求 PV 卷能够以 ReadWriteOnce、ReadOnlyMany 或 ReadWriteMany 模式之一来挂载
关于storageClassName的解释:
每个 PV 可以属于某个类(Class),通过将其 storageClassName 属性设置为某个 StorageClass 的名称来指定。 特定类的 PV 卷只能绑定到请求该类存储卷的 PVC 申领。 未设置 storageClassName 的 PV 卷没有类设定,只能绑定到那些没有指定特定存储类的 PVC 申领。
[root@master~/exercise/storage]#vim pvc.yaml apiVersion: v1 kind: PersistentVolumeClaim metadata: name: pvc1 namespace: dev spec: accessModes: - ReadWriteMany #卷可以被多个节点以读写方式挂载,此处和pv清单中的设置值要保持一致. resources: requests: storage: 1Gi --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: pvc2 namespace: dev spec: accessModes: - ReadWriteMany #卷可以被多个节点以读写方式挂载,此处和pv清单中的设置值要保持一致. resources: requests: storage: 1Gi --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: pvc3 namespace: dev spec: accessModes: - ReadWriteMany #卷可以被多个节点以读写方式挂载,此处和pv清单中的设置值要保持一致. resources: requests: storage: 5Gi
[root@master~/exercise/storage]#kubectl get pvc -n dev NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE pvc1 Bound pv1 1Gi RWX 7s pvc2 Bound pv2 2Gi RWX 7s pvc3 Pending 7s [root@master~/exercise/storage]#kubectl get pv -o wide NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE VOLUMEMODE pv1 1Gi RWX Retain Bound dev/pvc1 4h13m Filesystem pv2 2Gi RWX Retain Bound dev/pvc2 4h13m Filesystem pv3 3Gi RWX Retain Available 4h13m Filesystem
发现status为Pending原因是pvc要求容量为5G,pv中没有5G的容量空间.
- 创建pod使用pvc
[root@master~/exercise/storage]#vim pods-pvc.yaml apiVersion: v1 kind: Pod metadata: name: pod1 namespace: dev spec: containers: - name: busybox image: busybox:1.30 command: ["/bin/sh","-c","while true;do echo pod1 >> /root/out.txt; sleep 3; done;"] volumeMounts: - name: volume mountPath: /root/ volumes: - name: volume persistentVolumeClaim: claimName: pvc1 readOnly: false --- apiVersion: v1 kind: Pod metadata: name: pod2 namespace: dev spec: containers: - name: busybox image: busybox:1.30 command: ["/bin/sh","-c","while true;do echo pod2 >> /root/out.txt; sleep 3; done;"] volumeMounts: - name: volumes mountPath: /root/ volumes: - name: volumes persistentVolumeClaim: claimName: pvc2 readOnly: false
[root@master~/exercise/storage]#kubectl get pvc pvc1 -n dev -o wide NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE VOLUMEMODE pvc1 Bound pv1 1Gi RWX 110m Filesystem
pod1使用的时pvc1,那么经过查看pvc1分到的是pv1,然后查看pv1所对应的nfs共享目录/root/data/pv1下有生成的out.txt文件,pod2同理.
- 删除操作后查看状态
[root@master~/exercise/storage]#kubectl delete -f pods-pvc.yaml pod "pod1" deleted pod "pod2" deleted [root@master~/exercise/storage]#kubectl delete -f pvc.yaml persistentvolumeclaim "pvc1" deleted persistentvolumeclaim "pvc2" deleted persistentvolumeclaim "pvc3" deleted [root@master~/exercise/storage]#kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pv1 1Gi RWX Retain Released dev/pvc1 6h9m pv2 2Gi RWX Retain Released dev/pvc2 6h9m pv3 3Gi RWX Retain Available 6h9m

官网引用:
如果用户删除被某 Pod 使用的 PVC 对象,该 PVC 申领不会被立即移除。 PVC 对象的移除会被推迟,直至其不再被任何 Pod 使用。 此外,如果管理员删除已绑定到某 PVC 申领的 PV 卷,该 PV 卷也不会被立即移除。 PV 对象的移除也要推迟到该 PV 不再绑定到 PVC。
你可以看到当 PVC 的状态为 Terminating 且其 Finalizers 列表中包含 kubernetes.io/pvc-protection 时,PVC 对象是处于被保护状态的。
kubectl describe pvc hostpath Name: hostpath Namespace: default StorageClass: example-hostpath Status: Terminating Volume: Labels: <none> Annotations: volume.beta.kubernetes.io/storage-class=example-hostpath volume.beta.kubernetes.io/storage-provisioner=example.com/hostpath Finalizers: [kubernetes.io/pvc-protection] ... 你也可以看到当 PV 对象的状态为 Terminating 且其 Finalizers 列表中包含 kubernetes.io/pv-protection 时,PV 对象是处于被保护状态的。 kubectl describe pv task-pv-volume Name: task-pv-volume Labels: type=local Annotations: <none> Finalizers: [kubernetes.io/pv-protection] StorageClass: standard Status: Terminating Claim: Reclaim Policy: Delete Access Modes: RWO Capacity: 1Gi Message: Source: Type: HostPath (bare host directory volume) Path: /tmp/data HostPathType: Events: <none>
- 回收策略
目前的回收策略有:
Retain -- 手动回收
Recycle -- 基本擦除 (rm -rf /thevolume/*)
Delete -- 诸如 AWS EBS、GCE PD、Azure Disk 或 OpenStack Cinder 卷这类关联存储资产也被删除
目前,仅 NFS 和 HostPath 支持回收(Recycle)。 AWS EBS、GCE PD、Azure Disk 和 Cinder 卷都支持删除(Delete)。 - 你可以将 PV 的 claimRef 字段设置为相关的 PersistentVolumeClaim 以确保其他 PVC 不会绑定到该 PV 卷。
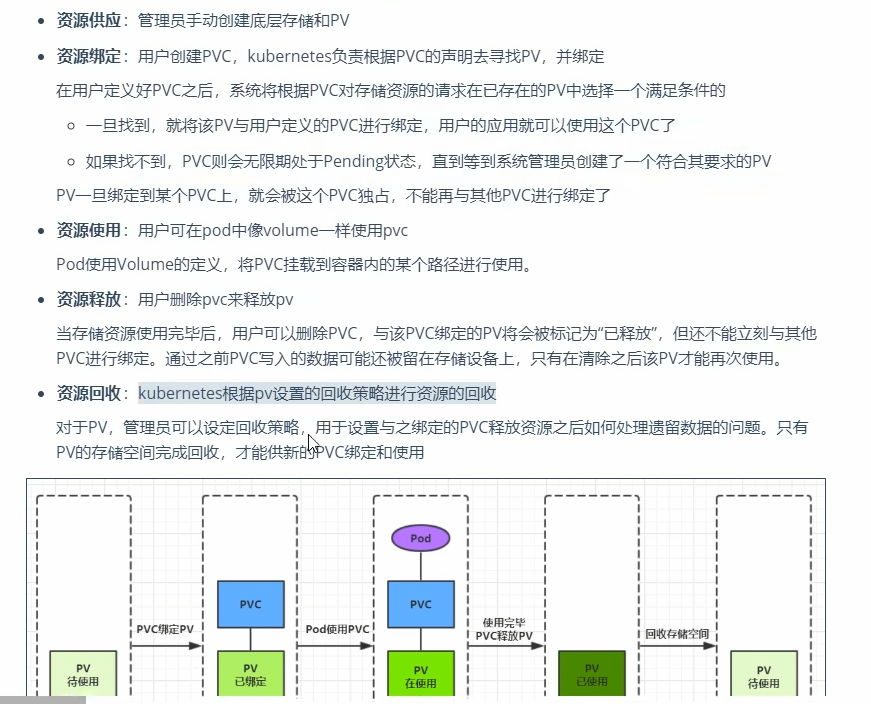
apiVersion: v1 kind: PersistentVolume metadata: name: foo-pv spec: storageClassName: "" claimRef: name: foo-pvc namespace: foo ... - pv和pvc生命周期
configmap
ConfigMap 是一种 API 对象,用来将非机密性的数据保存到键值对中。使用时, Pods 可以将其用作环境变量、命令行参数或者存储卷中的配置文件。
ConfigMap 是一个 API 对象, 让你可以存储其他对象所需要使用的配置。 和其他 Kubernetes 对象都有一个 spec 不同的是,ConfigMap 使用 data 和 binaryData 字段。这些字段能够接收键-值对作为其取值。data 和 binaryData 字段都是可选的。data 字段设计用来保存 UTF-8 字符串,而 binaryData 则被设计用来保存二进制数据作为 base64 编码的字串。
[root@master~/exercise/storage]#vim configmap.yaml apiVersion: v1 kind: ConfigMap metadata: name: configmap namespace: dev data: info: username:admin password:123456
[root@master~/exercise/storage]#vim pod-configmap.yaml apiVersion: v1 kind: Pod metadata: name: pod-configmap namespace: dev spec: containers: - name: nginx image: nginx:1.17.1 volumeMounts: #将configmap挂载到目录 - name: config mountPath: /configmap/config volumes: #引用configmap - name: config configMap: name: configmap #此处的名字要和configmap.yaml中的name保持一致.
[root@master~]#kubectl exec -it pod-configmap -n dev /bin/bash kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead. root@pod-configmap:/# root@pod-configmap:/# cd /configmap/config/ root@pod-configmap:/configmap/config# ls info root@pod-configmap:/configmap/config# more info username:admin password:123456789
还可以更新config中data中的数据,保存后自动更新
[root@master~/exercise/storage]#kubectl edit configmap configmap -n dev # Please edit the object below. Lines beginning with a '#' will be ignored, # and an empty file will abort the edit. If an error occurs while saving this file will be # reopened with the relevant failures. # apiVersion: v1 data: info: username:admin password:123456 kind: ConfigMap metadata: creationTimestamp: "2023-03-22T16:28:15Z" name: configmap namespace: dev resourceVersion: "1554951" uid: ecc8c78d-a98f-4e4e-ab9e-86345f43bca2
此时再查看info中的数据将密码变为123456
root@pod-configmap:/configmap/config# more info username:admin password:123456
configmap案例2
- 准备redis.conf文件
[root@master~/exercise/configMap]#cat redis.conf appendonly yes
- kubectl create configmap redis1.conf --from-file-redis.conf生成configmap类型的文件,名字为redis1.conf
- 编辑创建redis的yaml文件,并使用configmap类型的文件,名字为redis1.conf
[root@master~/exercise/configMap]#vim redis-configmap.yaml apiVersion: v1 kind: Pod metadata: name: redis spec: containers: - name: redis image: redis:latest command: - redis-server - "/redis-master/redis.conf" ports: - containerPort: 6379 volumeMounts: - mountPath: /data name: data - mountPath: /redis-master name: config volumes: - name: data emptyDir: {} - name: config configMap: name: redis1.conf #此处的redis1.conf为刚才创建好的. items: - key: redis.conf #此处的key是redis1.conf中的data:下的redis.conf path: redis.conf #此处的redis.conf就是"/redis-master/redis.conf"中的 redis.conf.
- 执行kubectl create -f redis-configmap.yaml
- 查看
[root@master~/exercise/configMap]#kubectl exec -it redis -- /bin/bash root@redis:/data# root@redis:/data# cd / root@redis:/# ls bin boot data dev etc home lib lib64 media mnt opt proc redis-ma root@redis:/# cat redis-master/redis.conf appendonly yes requirepass 123456
- requirepass 123456是我前面通过kubectl edit cm redis1.conf命令追加的.
- 但是新增的配置选项不能热更新到pod中redis服务,需要重启redis服务,但是前面使用的是Pod,不像Deployment删除后无法自动新建,可以使用下面的方法实现pod重启:
k8s中没有直接重启pod的命令,使用以下命令可以实现效果:
kubectl get pod redis -o yaml |kubectl replace --force -f -
参考链接:https://www.51cto.com/article/740890.html
secret
Secret 类似于 ConfigMap 但专门用于保存机密数据。
[root@master~/exercise/storage]#vim secret.yaml apiVersion: v1 kind: Secret metadata: name: secret namespace: dev type: Opaque #Secret 的类型:用户定义的任意数据 data: username: YWRtaW4= #此处为base64加密后的 password: MTIzNDU2
[root@master~/exercise/storage]#vim pod-secret.yaml apiVersion: v1 kind: Pod metadata: name: pod-secret namespace: dev spec: containers: - name: nginx image: nginx:1.17.1 volumeMounts: #将secret挂载到目录 - name: config mountPath: /secret/config volumes: - name: config secret: secretName: secret
专业术语参考链接https://kubernetes.io/zh-cn/docs/concepts/configuration/secret/
[root@master~/exercise/storage]#kubectl get pod/pod-secret -n dev NAME READY STATUS RESTARTS AGE pod-secret 1/1 Running 0 27s [root@master~/exercise/storage]#kubectl exec -it pod-secret /bin/bash -n dev kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead. root@pod-secret:/# cd /secret/config/ root@pod-secret:/secret/config# ls password username root@pod-secret:/secret/config# more username admin root@pod-secret:/secret/config# more password 123456
参考链接:https://kubernetes.io/zh-cn/docs/concepts/storage/persistent-volumes/
遇到的错误和解决办法:
kubectl get nodes E0324 22:11:51.890915 15697 memcache.go:238] couldn't get current server API group list: the E0324 22:11:51.891911 15697 memcache.go:238] couldn't get current server API group list: the E0324 22:11:51.895141 15697 memcache.go:238] couldn't get current server API group list: the E0324 22:11:51.896127 15697 memcache.go:238] couldn't get current server API group list: the E0324 22:11:51.898575 15697 memcache.go:238] couldn't get current server API group list: the Error from server (BadRequest): the server rejected our request for an unknown reason
原来是我用的http://192.168.1.17:6443
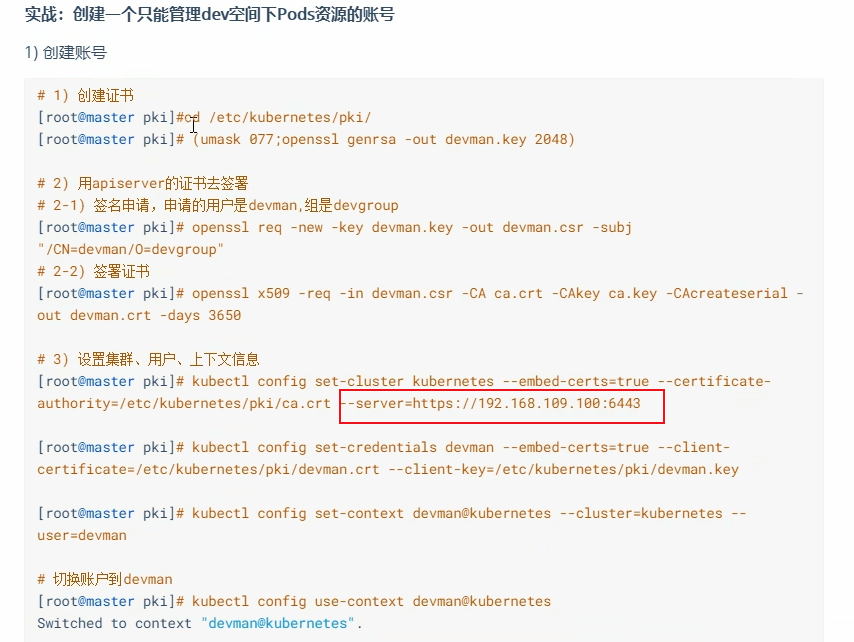
然后在kubectl config use-context kubernetes-admin@kubernetes创建devman的授权清单
[root@master~/exercise]#cat dev-role.yaml kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: namespace: dev name: dev-role rules: - apiGroups: [""] resources: ["pods"] verbs: ["get","watch","list"] --- kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: authorization-role-binding namespace: dev subjects: - kind: User name: devman apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: dev-role apiGroup: rbac.authorization.k8s.io
再切换kubectl config use-context devman@kubernetes账户,只有查看pod的权限.
实验完毕删除上下文和用户:
[root@master/etc/kubernetes/pki]#kubectl config view apiVersion: v1 clusters: - cluster: certificate-authority-data: DATA+OMITTED server: https://192.168.1.17:6443 name: kubernetes contexts: - context: cluster: kubernetes user: devman name: devman@kubernetes - context: cluster: kubernetes user: kubernetes-admin name: kubernetes-admin@kubernetes current-context: kubernetes-admin@kubernetes kind: Config preferences: {} users: - name: devman user: client-certificate-data: DATA+OMITTED client-key-data: DATA+OMITTED - name: kubernetes-admin user: client-certificate-data: DATA+OMITTED client-key-data: DATA+OMITTED
[root@master/etc/kubernetes/pki]#kubectl config unset contexts.devman@kubernetes Property "contexts.devman@kubernetes" unset. [root@master/etc/kubernetes/pki]#kubectl config unset users.devman Property "users.devman" unset.
再次通过kubectl config view查看
[root@master~]#kubectl config view apiVersion: v1 clusters: - cluster: certificate-authority-data: DATA+OMITTED server: https://192.168.1.17:6443 name: kubernetes contexts: - context: cluster: kubernetes user: kubernetes-admin name: kubernetes-admin@kubernetes current-context: kubernetes-admin@kubernetes kind: Config preferences: {} users: - name: kubernetes-admin user: client-certificate-data: DATA+OMITTED client-key-data: DATA+OMITTED
Secret案例2
- kubectl create secret docker-registry duwenjie-docker --docker-username=56877**** --docker-password=****** --docker-email=56877****@qq.com
创建名为duwenjie-docker的secret,此处的--docker-username是登陆dockerhub后右上角显示的用户名,不是登陆账户时的用户名哦. - 此处的dockerhub仓库时私有的,编辑yaml文件下载上面的nginx奖项
[root@master~/exercise/Secret]#cat nginx-secret.yaml apiVersion: v1 kind: Pod metadata: name: private-nginx spec: containers: - name: du-nginx image: 56877****/guigu:nginx_1.0 imagePullSecrets: - name: duwenjie-docker
下载成功表示此处的secret不以明文展示了.
Dashboard
- 先下载Dashboard清单:
https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml
在Service中新增的两处位置:
--- kind: Service apiVersion: v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kubernetes-dashboard spec: type: NodePort #新增 ports: - port: 443 targetPort: 8443 nodePort: 30009 #新增 selector: k8s-app: kubernetes-dashboard ---
kubectl create -f recommended.yaml
如果创建前没有更改service的type,可以使用命令kubectl edit service kubernetes-dashboard -n kubernetes-dashboard也可以更改.
- 查看:
[root@master~/exercise/dashboard]#kubectl get pod,service -n kubernetes-dashboard NAME READY STATUS RESTARTS AGE pod/dashboard-metrics-scraper-7bc864c59-tww44 1/1 Running 0 3m13s pod/kubernetes-dashboard-6c7ccbcf87-bcc92 1/1 Running 0 3m13s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/dashboard-metrics-scraper ClusterIP 10.97.31.1 <none> 8000/TCP 3m14s service/kubernetes-dashboard NodePort 10.105.25.156 <none> 443:30009/TCP 3m16s
- 创建访问账户,获取token
创建服务帐户admin-user在命名空间中kubernetes-dashboard首先。
apiVersion: v1 kind: ServiceAccount metadata: name: admin-user namespace: kubernetes-dashboard
创建ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: admin-user roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: admin-user namespace: kubernetes-dashboard
获取Bearer令牌,它应该打印出如下内容:
kubectl -n kubernetes-dashboard create token admin-user
eyJhbGciOiJSUzI1NiIsImtpZCI6Ijc0aGNSZy03ZVpiaVcxM2RucmhrSFlCT0premkxVUtJNGhFZVk5dGZ6Q1EifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxNjc5Njc4MjU3LCJpYXQiOjE2Nzk2NzQ2NTcsImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsInNlcnZpY2VhY2NvdW50Ijp7Im5hbWUiOiJhZG1pbi11c2VyIiwidWlkIjoiZDkzN2UzZWEtNmUwMi00YmVlLTg0MTctMDgwNDk5Y2ZkYTQyIn19LCJuYmYiOjE2Nzk2NzQ2NTcsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlcm5ldGVzLWRhc2hib2FyZDphZG1pbi11c2VyIn0.Sg0kyc9KG2TtZc0_cvCb2sjnutsWQdsWyNXkSzcVbi0WKNdPvUpFaBKoX0FwJKeDUTuCI8okQNtDnQuWgQyQKR9eBg_ig_vJQa3P3TqybZRkrhWOIkxQ-KfldDcBOeuZgYmYFObhRnd5Mx60QTbdfj3hMRCavTFavjNlF4Y1wl5UBD0FGx54QTZIkOWakTh_4AZ-NRnhu7J--_6Lb-qtEyDAYSTfuaz2c_RheZA0yO7peIWdmrAFR3DB4DX9v5c4d_Jll8v_gEJQR_VqJoNFeMPvCRK8yfNEnmODJ14AHAcstqQIoPIQieyb0-jToeGrHYm5ahosrPh2YoT0kDD8cQ
参考链接:https://github.com/kubernetes/dashboard/blob/master/docs/user/access-control/creating-sample-user.md
https://kubernetes.io/zh-cn/docs/tasks/access-application-cluster/web-ui-dashboard/
新增:
kubectl edit cm coredns -n kube-system编辑coredns的配置文件.
- 在名字空间 “acme” 中,将名为 view 的 ClusterRole 对象中的权限授予名字空间 “myappnamespace” 中名称为 myapp 的服务账户:kubectl create rolebinding myappnamespace-myapp-view-binding --clusterrole=view --serviceaccount=myappnamespace:myapp --namespace=acme
参考链接:https://kubernetes.io/zh-cn/docs/reference/access-authn-authz/rbac/
服务账户权限
-
在名字空间 “my-namespace” 中授予服务账户 “my-sa” 只读权限:kubectl create rolebinding my-sa-view
--clusterrole=view
--serviceaccount=my-namespace:my-sa
--namespace=my-namespace -
将角色授予某名字空间中的 “default” 服务账户
如果某应用没有指定 serviceAccountName,那么它将使用 “default” 服务账户。
说明:"default" 服务账户所具有的权限会被授予给名字空间中所有未指定 serviceAccountName 的 Pod。
例如,在名字空间 "my-namespace" 中授予服务账户 "default" 只读权限:
kubectl create rolebinding default-view
--clusterrole=view
--serviceaccount=my-namespace:default
--namespace=my-namespace
许多插件组件在 kube-system 名字空间以 “default” 服务账户运行。 要允许这些插件组件以超级用户权限运行,需要将集群的 cluster-admin 权限授予 kube-system 名字空间中的 “default” 服务账户:
kubectl create clusterrolebinding add-on-cluster-admin
--clusterrole=cluster-admin
--serviceaccount=kube-system:default -
宽松的 RBAC 权限
你可以使用 RBAC (Attribute Based Access Control)角色绑定复制宽松的 ABAC 策略。
警告:
下面的策略允许所有服务帐户充当集群管理员。 容器中运行的所有应用程序都会自动收到服务帐户的凭据,可以对 API 执行任何操作, 包括查看 Secret 和修改权限。这一策略是不被推荐的:
kubectl create clusterrolebinding permissive-binding
--clusterrole=cluster-admin
--user=admin
--user=kubelet
--group=system:serviceaccounts -
apiGroups 列出了一个或多个要匹配的 API 组。"" 是核心 API 组。"*" 匹配所有 API 组(包括核心API组)。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)